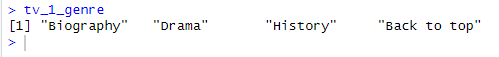Data Scraping(데이터 긁어오기)
인터넷 상에 공개된 웹 페이지에서 필요한 정보를 추출하여 구조화된 데이터로 만드는 것.(Web crawling & Data Structuring)
Data "sets" in R
*"set" is in quotation marks because it is not a formal data class.(즉, set이란 키워드는 공식적인 data class가 아닌 인용구이다. tibble,data.frame,vector,matrix..처럼 공식적인 data class가 아니다.)
->하지만, 이건 R에서 이런거지, python에서는 내장된 자료구조 중 하나이다. 즉, 파이썬에서는 테이터 타입 중 하나이다.
*A tidy data "set"(정돈된 데이터셋) can be one of the following types:
->tibble
->data.frame
Data frames & tibbles
*A 'data.frame' is the most commonly used data structure in R, they are just a list of equal length vectors. Each vector is treated as a column and elements of the vectors as rows.
->여기서 vector는 각 열에 저장된 데이터를 담고 있는 벡터를 의미한다.
*A tibble is a type of data frame that... makes the data easier.
->티블은 데이터 프레임보다 더 데이터를 다루기 쉽게 해주는 데이터 타입(클래스)라고 보면 된다. 티블도 데이터 프레임과 같이 2차원 행렬의 구조를 가진다.
->여기서 더 다루기 쉽다는 의미는 티블이 데이터 프레임보다 더 사용자 친화적이고, 직관적인 함수와 메서드를 제공하며, 데이터의 타입이나 구조를 보다 명확하게 정의할 수 있도록 도와준다는 의미이다.
*Most often a data frame will be constructed by reading in from a file, but we can also create them from scratch.
->'readr' package(e.g. read_csv function) loads data as a 'tibble' by default.
->여기서 e.g.는 '예를 들어'라는 뜻이다.->'tibble's are part of the tidyverse, so they work well with other packages we are using.
->티블은 tidyverse의 다른 패키지와도 작동이 잘 된다는 의미이다.
->tidyverse는 티블을 포함한 여러개의 패키지로 이루어져있다. tidyverse는 데이터 분석에 유용한 여러 패키지들의 집합이다.->they make minimal assumptions about your data, so are less likely to cause hard to track bugs in your code.
->tibble이 데이터에 대해 최소한의 가정을 하기 때문에, 코드에서 추적하기 어려운 버그를 유발할 가능성이 적다는 의미이다.
Creating data frames



Features of data frames
->attributes(df)는 말 그대로 df의 속성들을 알려주는 것이다.

Scraping the Web: What? Why?
*Increasing amount of data is available on the web.
*These data are provided in an unstructed format: you can always copy&paste, but it's time-consuming and prone to errors.
->cf.)prone to errors: 에러가 발생할 수 있는*Web scarping is the process of extracting this information automatically and transform it into structed dataset.
*Two different scenarios:
->'Screen scraping': extract data from source code of website, with html parser(easy) or regular expression matching(less easy)->cf.)html parser(html 구문분석기), regular expression matching(정규 표현식 매칭)
->html parser: rvest 패키지에 있다. html_nodes(),html_text(),read_html(),...
->regular expression matching: stringr 패키지에 있다. str_extract() 함수가 있다.
->read_html()을 통해 웹페이지 주소를 불러들이고, html_nodes()를 통해, 첫번째 인자에는 주소를, 두번째 인자에는 css 선택자를 이용해 선택하려는 html 요소를 지정한다. 즉, 여기서는 'div'를 불러들인 걸 알 수 있다.->cf.) html parser는 정적 웹 크롤링에서만 가능하다.
->str_extract() 함수는 정규표현식을 사용해서 문자열에서 패턴을 추출하는 함수이다.->'Web APIs(application programming interface)': website offers a set of structed http requests that return JSON or XML files.
->API는 동적 웹 크롤링에 사용된다. 즉, javascript처럼 동적인 웹 페이지에서 크롤링할 때 사용된다. 예를들어 'tbody'의 요소가 있으면, 이는 동적 웹 크롤링을 사용해서 추출해야한다. API 사용법은 추후에 알려주도록 하겠다.
->cf.)API 외에 r selenium을 이용하여 동적 웹 크롤링을 하는 법도 있다.


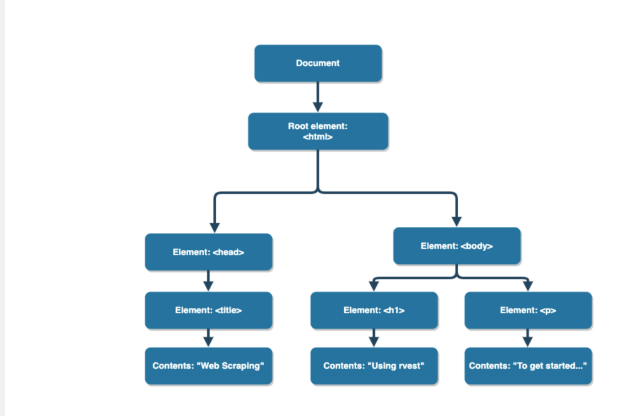
Hypertext Markkup Language(HTML)
*Most of the data on the web is still largely available as HTML - while it is structed (hierarichical/tree based),it often is not available in a form useful for analysis(flat/tidy).
->html의 구조는 계층적/트리 구조로 되어 있지만, 분석에 용이한 평면 형태로 쉽게 변환되지 않는 경유가 많다. 이를 분석하기 위해서는 데이터를 추출하고 구조화하는 작업이 필요하며, 이러한 데이터를 다루기 위해 tidyverse 패키지를 사용하는 것이 좋다. 즉, 추출된 데이터들이 구조화 과정을 통해 평면화된 데이터가 되는 것이다.
->cf.)동적 웹페이지도 계층적 구조이지만, 이러한 구조가 동적으로 변화하기도 하며, 초기 로딩 후에 추가적으로 로드되는 데이터도 있기 때문에, 크롤링하는데 추가적인 어려움이 있을 수 있다.
->html 형식(format)

Hypertext Markkup Language(HTML)(2)
*HTML describes the structure of a web page; your browser interprets the structure and contents and displays the results.
->여기서 'displays the results'는 우리 사용자에게 시작적으로 보여주는 것을 의미한다. 즉, 웹페이지를 보여준다고 생각하면 된다.
*The basic building blocks include elements, tags, and attributes.
->an element is a component of an HTML document
->elements contain tags(start and end tag)
->attributes provide additional information about HTML elements.
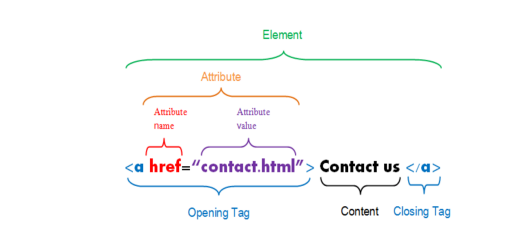
HTML tree-like structue
*If we have access to an HTML document, then how can we easily extract information?
->앞에서도 말했다시피, HTML document에 접근할 수 있으면, html parser를 통해 정보를 추출할 수 있다.
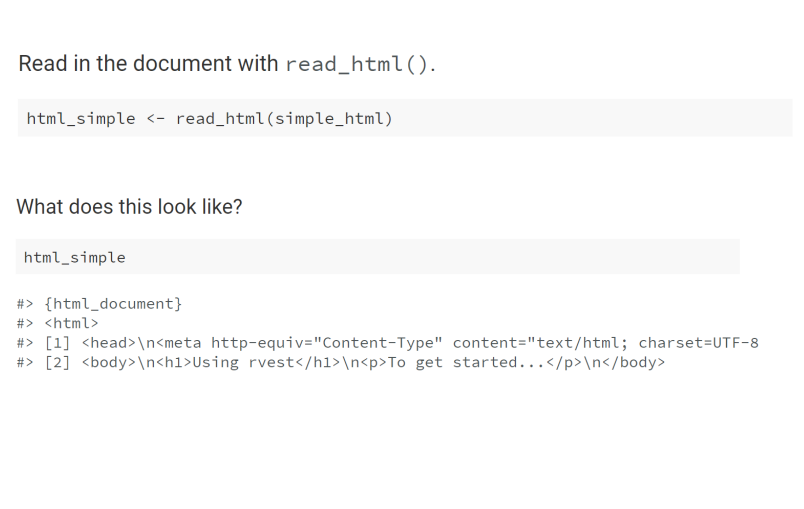
HTML in R
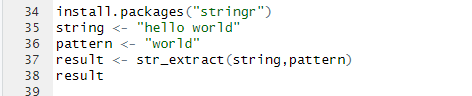
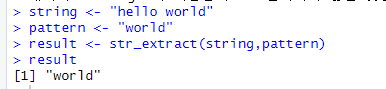
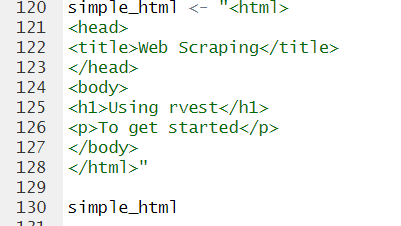
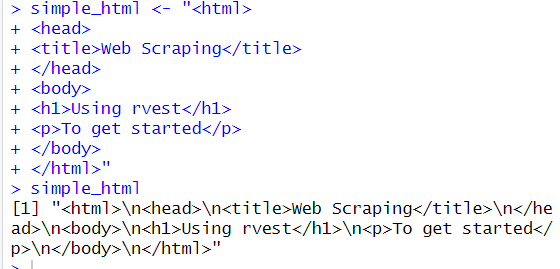
*We'll create a simple HTML document as a string to demonstrate some of these functions.
cf.) html을 만들때는 ""을 사용하면 되는 것을 알았다.


rvest
*'rvest' is a package that makes basic processing and manipulation of HTML data straight forward.
*It's designed to work with pipelines built with '%>%'.
->'%>%'을 통해 코드를 이어줄 수 있다.(이어나갈 수 있다.)
-> ctrl+shift+m을 하면 바로 쓸 수 있다.
Core functions in rvest:
앞에서 잠깐 맛 본 함수들이 나온다.
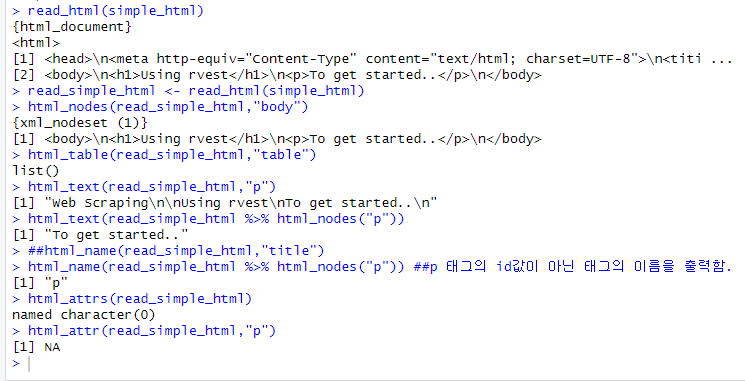
*read_html: read HTML data from a url or character string.
*html_nodes: select specified nodes from the HTML document using CSS selectors.
*html_table: parse an HTML table into a data frame.
->parse: 추출하다. 분석하다. 해석하다.*html_text: extract tag pairs' content.
->cf.) tag pairs'(태그쌍), 즉, 태그로 감싸인 내용을 추출하는 코드이다.*html_name: extract tags' names.
*html_attrs: extract all of each tag's attributes.
*html_attr: extract tags' attribute value by name.
*추가설명을 하자면, 굳이 html_text에서 일부 내용을 추출하고 싶으면, 저렇게 해도 되지만, html_nodes()를 쓰는게 더 합리적이다.
*또한, html_table()은 표를 추출하는 함수이고, html_name() 함수는 태그의 id값(태그의 이름)이 아닌 태그 그 자체의 이름을 출력해준다.
*html_attrs/html_attr은 태그 내의 속성값들을 출력해주는 함수인데, 속성값들은 다음과 같다.
cf.)attributes(속성값)
html에서 속성값은 이런 것들을 말한다.
->id: html 요소의 고유 식별자 지정.(이름 지정)
->class: html 요소에 대한 클래스(그룹) 지정
->href: 앵커(a tag) 요소에서 링크 대상 url 지정
->src: 이미지 요소에서 이미지 소스 url 지정
->alt: 이미지 요소의 대체 텍스트를 지정.
->title: 요소에 대한 추가 정보를 제공하는 툴팁 텍스트 지정등등이 있다.

HTML in R
앞에서 본 내용들이다.
Web crawling example 1
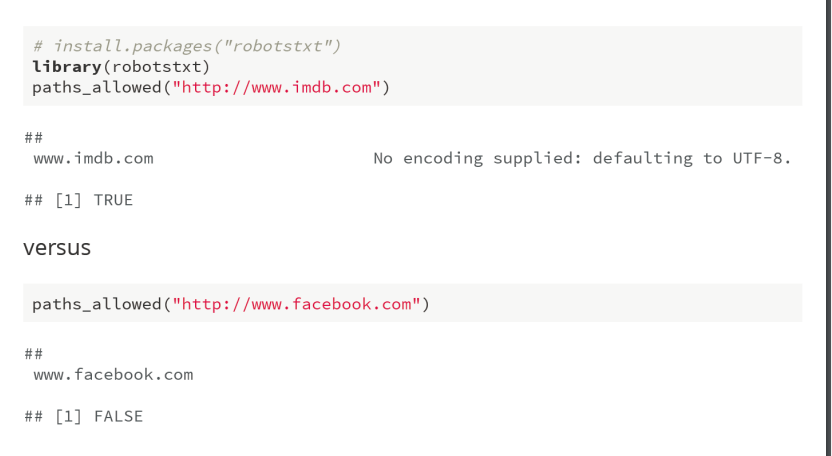
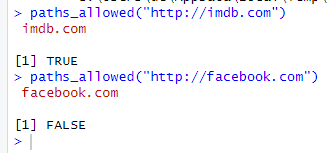
First check to make sure you're allowed!
이 과정은 회사 사이트의 정보 추출에 접근할 수 있는지에 대한 여부를 확인하는 과정이다. 보안 상의 이슈로 개인 정보들이 추출될 수 있으므로, 정보 추출을 허용하지 않는 곳들도 많다.
Select and format pieces
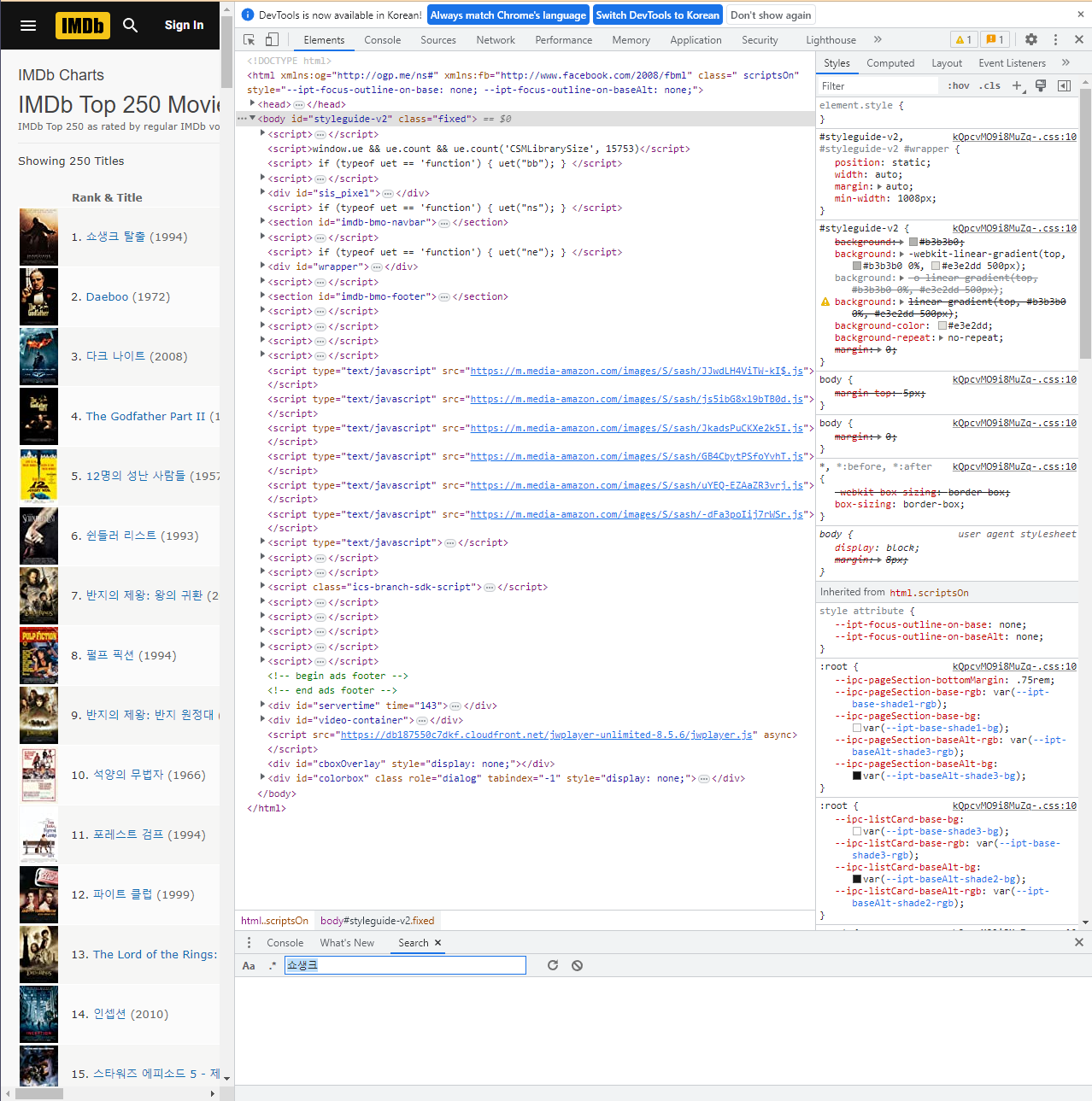
먼저 홈페이지 접속을 한다.
크롬의 경우 F12를 누르면 개발자 도구 탭이 뜬다.
여기서 추출하고자 하는 부분을 찾는 과정이 필요한데, 대표적으로 크게 두가지로 나눌 수 있다.
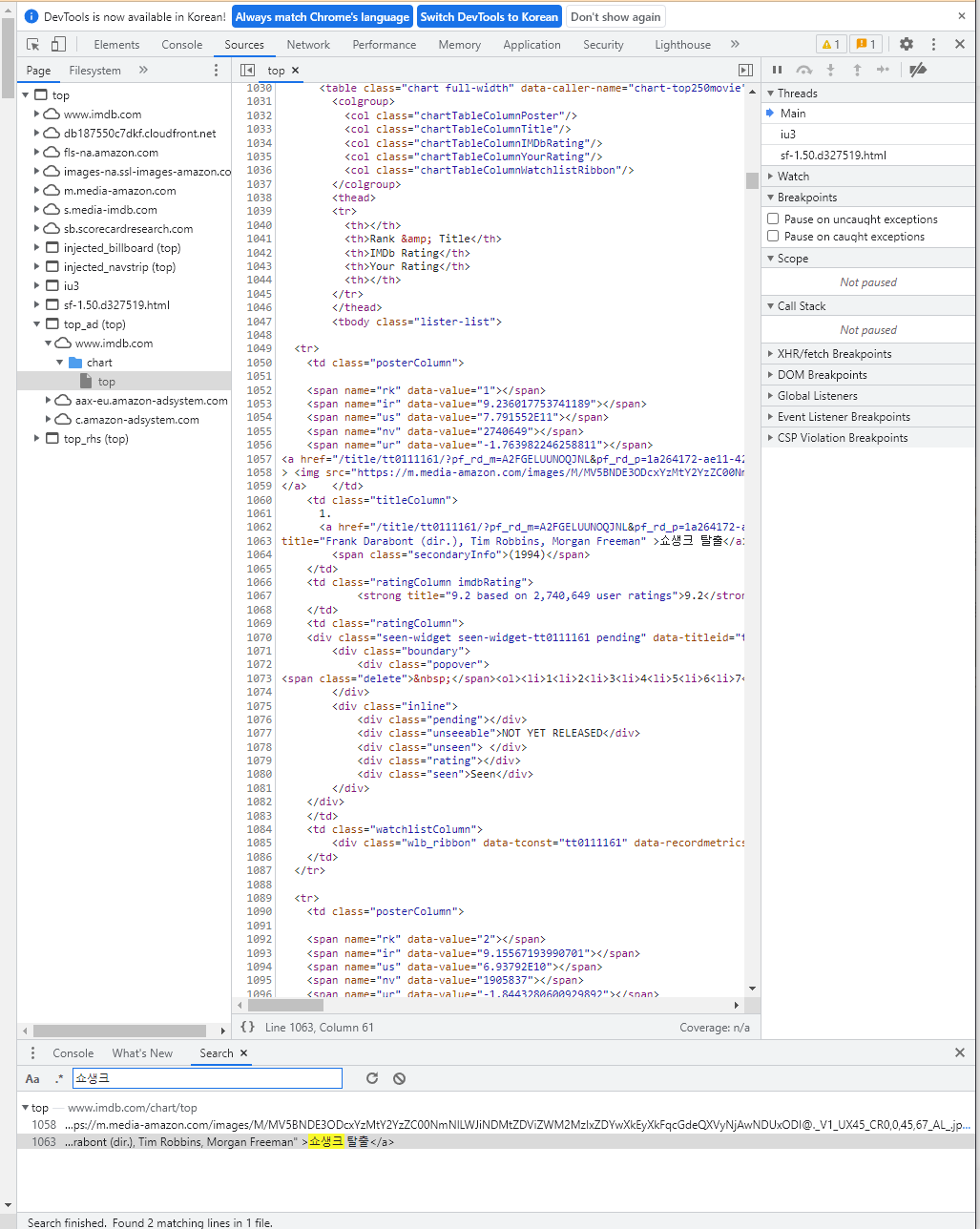
->1. search를 통해 키워드로 찾기: ctrl+shift+F를 하면, search 창이 나오고, 여기에 영화 이름을 넣는 등의 키워드를 입력하면, 해당 키워드에 대한 코드 줄이 나온다.
->2. 왼쪽 상단에 있는 화살표 모양같은 것을 누르고 페이지를 탐방하면, 해당 페이지에 대한 페이지 구조 정보가 뜬다.
필자는, search로 해보도록 하겠다.
일단, 기본적인 html 구조를 알고 있다는 가정하에 설명을 하겠다.
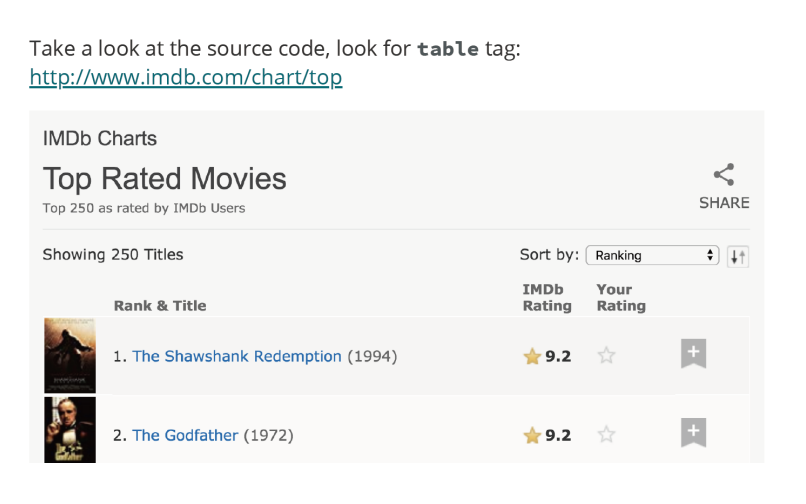
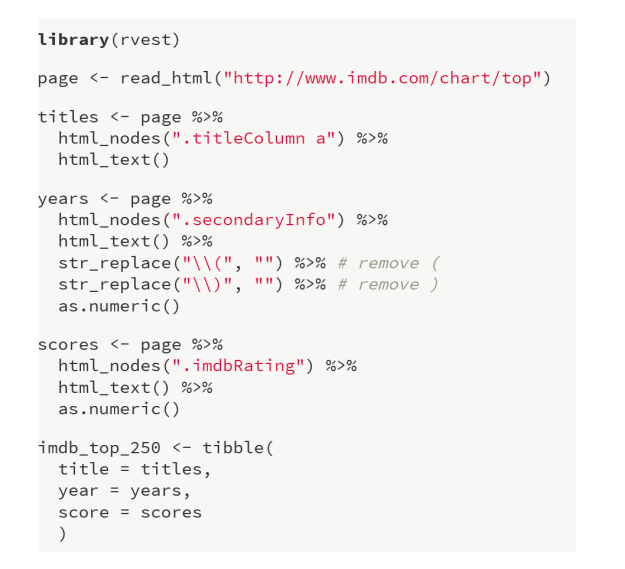
이 둘을 한번 보도록 해보자. 뭔가 공통적인 구조임을 알 수 있을 것이다. td class="titleColumn"인 것과 제목 부분이 a 태그 형식으로 이루어진 것임을 알 수 있다. Daeboo 역시도 마찬가지이다.
따라서, html_nodes()에 html_nodes(".titleColumn a")라고 적은 이유이다. 여기서 .은 CSS 선택자로 클래스 선택자를 의미한다. 필자는 titleColumn이라는 td class(td는 테이블의 각 행에서의 데이터 셀을 의미한다.)를 선택한 것이고, 그 클래스의 a 태그를 선택했다는 의미이다.
그리고, html_text()를 통해 태그로 감싸진 내용물들을 추출했고, 이를 titles라는 변수에 담은 것이다.
그 다음 두번째 부분 코드를 알아봐보자.
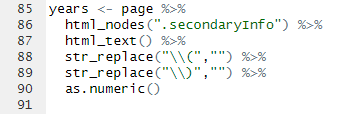
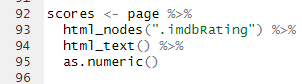
이 코드는 년도를 추출하는 코드이다.
마찬가지로, span class의 secondaryInfo를 선택한 것이고, 대신 여기는 태그 선택은 없다.
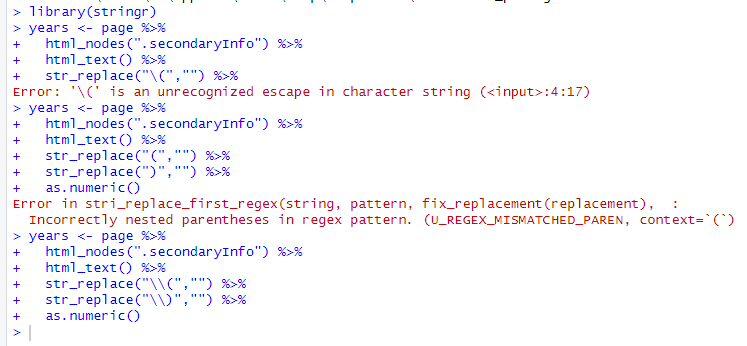
하지만, 여기서 알아볼 부분은 str_replace()인데, 이 함수는 말 그대로 문자열을 어떤 것으로 대체하는 함수이다. 그럼 왜 역슬래시를 쓰는 것일까?
먼저, 이스케이프 문자인 역슬래시에 대해 알아야 한다.(역슬래시 기호를 쓰면 \이렇게 나와서 그냥 한글로 말하겠다.)
이스케이프 문자인 역슬래시는 특수 기호(문자)를 문자열에 그대로 출력하게 해주는 문자이다. 예를 들어, \"는 문자열 내에서 "을 문자로 출력해준다.
원래 "와 같은 특수 문자는 r에서 특수 기능을 실현하게 해주는 역할을 하기 때문에, 이를 역할 수행이 아닌 단순 문자열 내에 문자로 출력해주기 위해서 이스케이프 문자를 쓴다.
즉, 역슬래시x2는 역슬래시를 문자로 나타나겠다는 의미이다.
그러면, 역슬래시x2( 의 의미는 무엇일까? 필자도 이 부분이 헷갈려서 chatGPT한테 물어봤는데, 답변은 다음과 같았다.
->A. 역슬래시x2(을 통해, 첫번째 역슬래시를 통해 두번째 역슬래시를 문자로 인식하게 해준다. 그럼 역슬래시(가 되는데, 이를 통해 (를 문자로 인식하게 해준다.
->근데, 그냥 역슬래시( 를 통해서 바로 (를 문자로 인식시켜주면 안되는 것일까? 그냥 r의 문법인거 같다.
다음은 역슬래시를 한번 썼을때와 안 썼을때의 오류 코드를 보여주도록 하겠다.
->즉, 이렇듯 역슬래시 2번을 사용해야지 정상 작동됨을ㅇ 알 수 있다.그 다음, as.numeric()으로 문자형을 숫자형으로 변환시켜준다.
다음은 세번째 코드 부분이다.
위와 같이 똑같은 과정을 거치면 된다.
마지막 코드 부분이다.
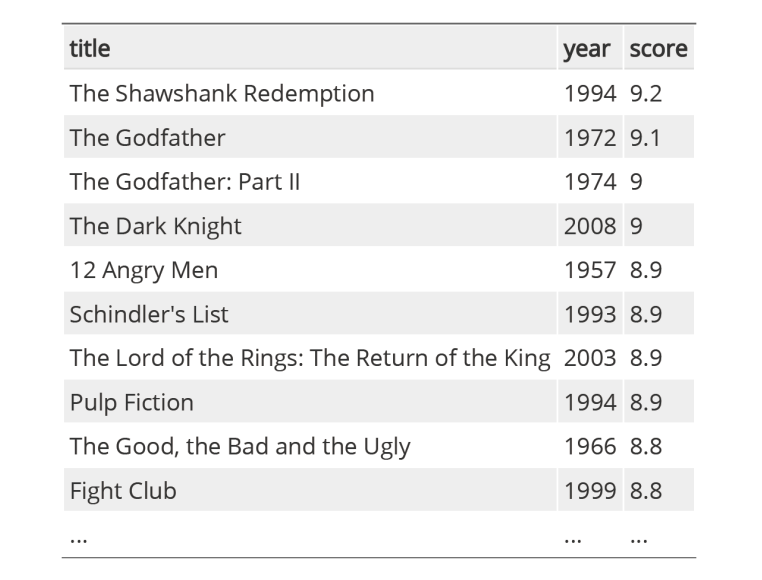
티블 형식으로 데이터 구조를 만드는 것이다. titles에 있는 내용들을 열 이름이 title이라는 열에 나열을 하고, years는 열 이름이 year에, scores는 열 이름이 score에 나열되도록 한다.
view함수를 통해 가공된 테이블을 볼 수 있다.






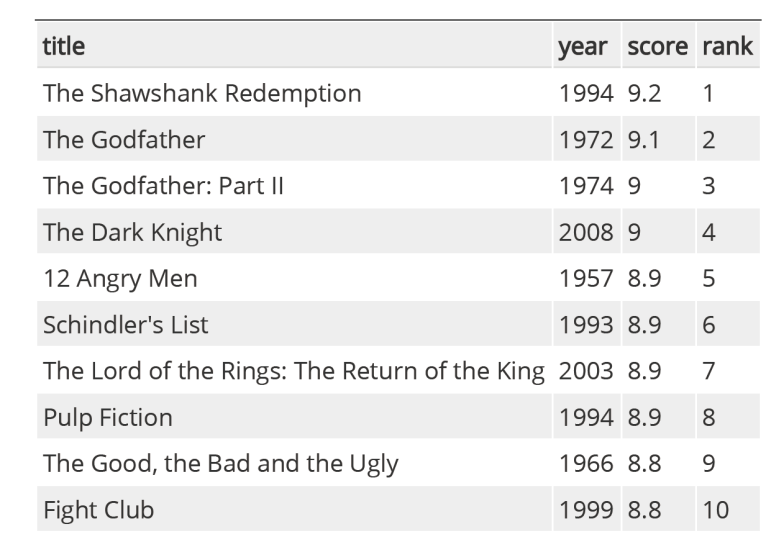
Expected Result
Clean up and enhance
*May or may not be a lot of work depending on how messy that data are
->데이터 정돈 여부에 따라 작업량이 많을 수도 있고, 많지 않을 수도 있다.*See if you like what you got:
*Add a variable for rank
mutate() 함수는 말 그대로 변형시킨다라는 뜻이다. mutate()안에 내용물을 보면, rank=1:nrow(imdb_top_250)인데, 이는 1부터 행의 갯수 만큼 순차적으로 rank를 덧붙이겠다라는 뜻이다.

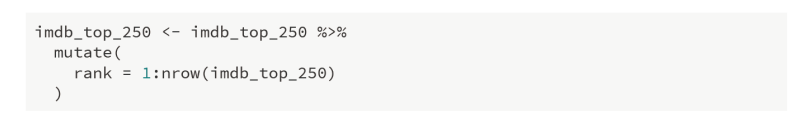

Expected Result
Analyze
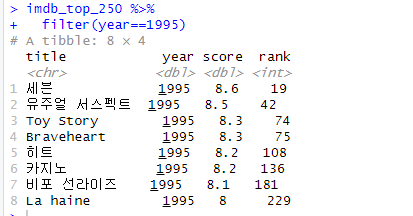
*How would you go about answering this question: Which 1995 movies made the list?
Answer
filter() 함수는 말 그대로 필터링, 걸러주는 것이다. year=1995인 내용들로 걸러주는 역할이다. 따라서, 앞에서 as.numeric()을 하는 이유는 이런 이유에서도 있다.
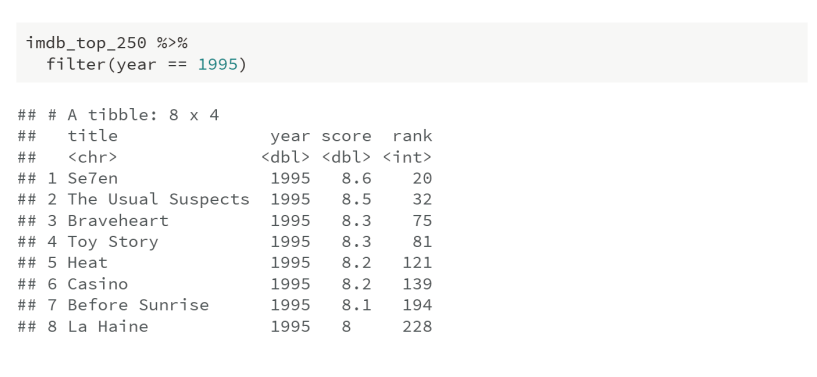
Analyze(2)
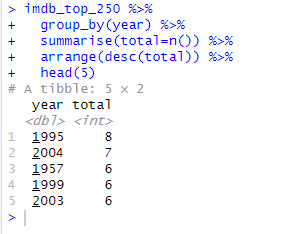
How would you go about answering ths question: Which year have the most movies on the list?
Answer(2)
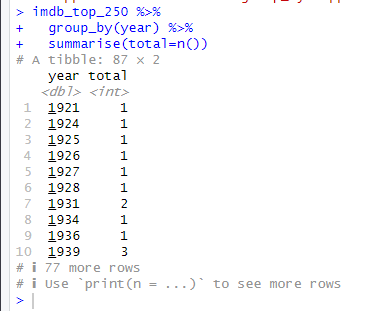
코드 해석을 하자면, group_by(year), 즉, year를 기준으로 그룹으로 나눈뒤, summarise()를 한다.
cf.) summarise() 함수는 dplyr 패키지에 있는 함수로, 데이터의 집계 또는 요약 작업을 수행하는데 사용된다. 주어진 데이터셋을 그룹별로 요약하거나 전체 데이터를 단일 행으로 요약하는데 유용한다.
summarise(total=n())의 의미는, n()은 dplyr에서 제공하는 함수로, 데이터셋의 행의 개수를 반환하고, 이를 total이라는 변수에 저장한다. 이때, total은 새로운 열이다.
여기서도 보면 알 수 있듯이, n()은 그룹화 된 년도별의 데이터 셋의 행의 개수들을 출력해줌을 알 수 있다.
또한, use 'print(n=...)' to see more rows.를 보면 알 듯이, print(n=20)이라고 코드를 추가하면, 20개까지 나열해준다.
arrange(desc(total))이라는 함수를 통해, 내림차순으로 total을 정렬해준다.
head(5)을 통해 앞에 5개만 출력해준다.


Visualization
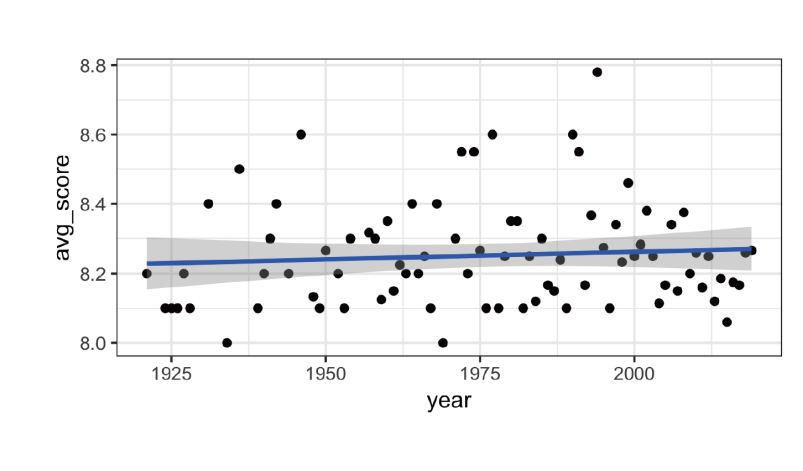
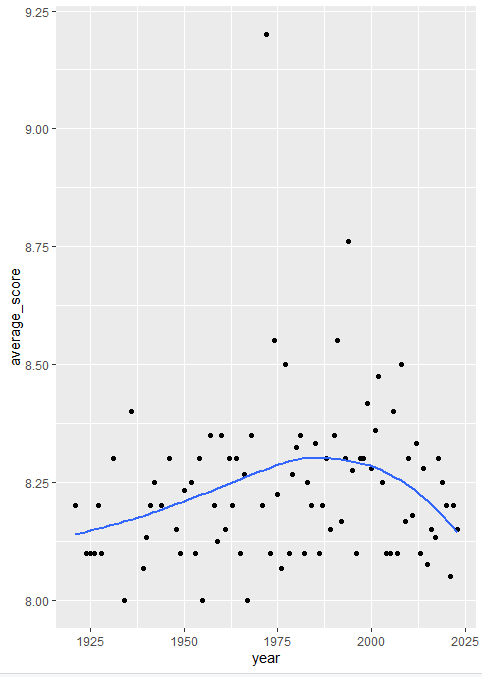
How would you go about creating this visualization: Visualize the average yearly score for movies that made it on the top 250 list over time.
Answer
꼭 이게 정답이라는 의미는 아니다. visualization을 나타내는 방법은 다양하니, 다양한 방법으로 접근해보길 바란다.
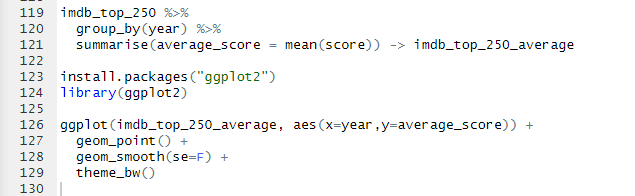
코드 분석을 해보자. summarise()를 통해서, year별로 그룹화된 그룹들의 점수(rating)의 평균을 먼저 구하고, 이를 imdb_top_250_average라는 새로운 변수에 저장한다.
visualization의 대표적인 패키지로, ggplot2가 있다. 먼저 패키지를 설치하도록 한다.
ggplot() 함수 부분을 살펴보면, aes는 축의 정보를 나타낸다. x는 year 정보가, y는 average_score 정보가 들어간다.
geom_point()는 말 그대로 데이터를 점 포인트로 나타낸다는 의미이다.
geom_smooth()는 부드러운 곡선을 그리는 레이어이고, 데이터의 추세를 나타내는 선을 그린다. se=F는 추세 선 주변의 표준 오차 범위를 표시하지 않도록 하는 설정이다.
theme_bw()는 배경과 테두리 등의 테마를 흑백 스타일로 설정하는 코드이다.
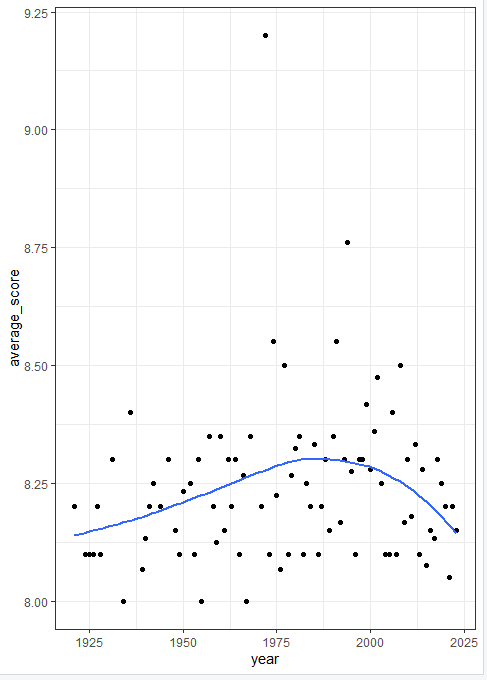
theme_bw()를 추가하지 않는다면,
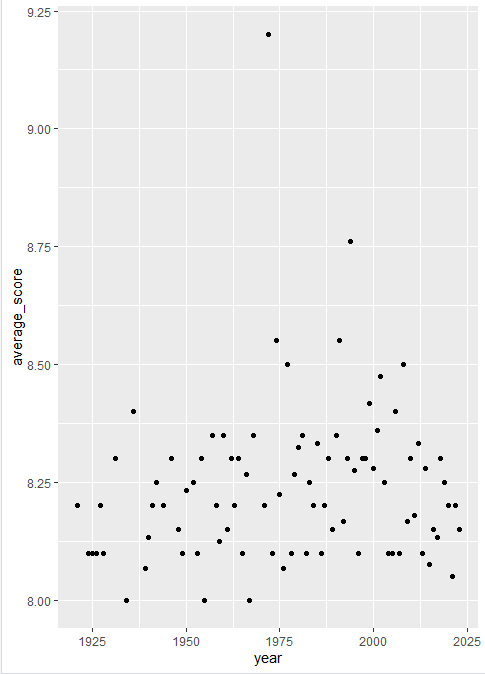
geom_point()만 추가했을 때,
Self-Checking Quiz
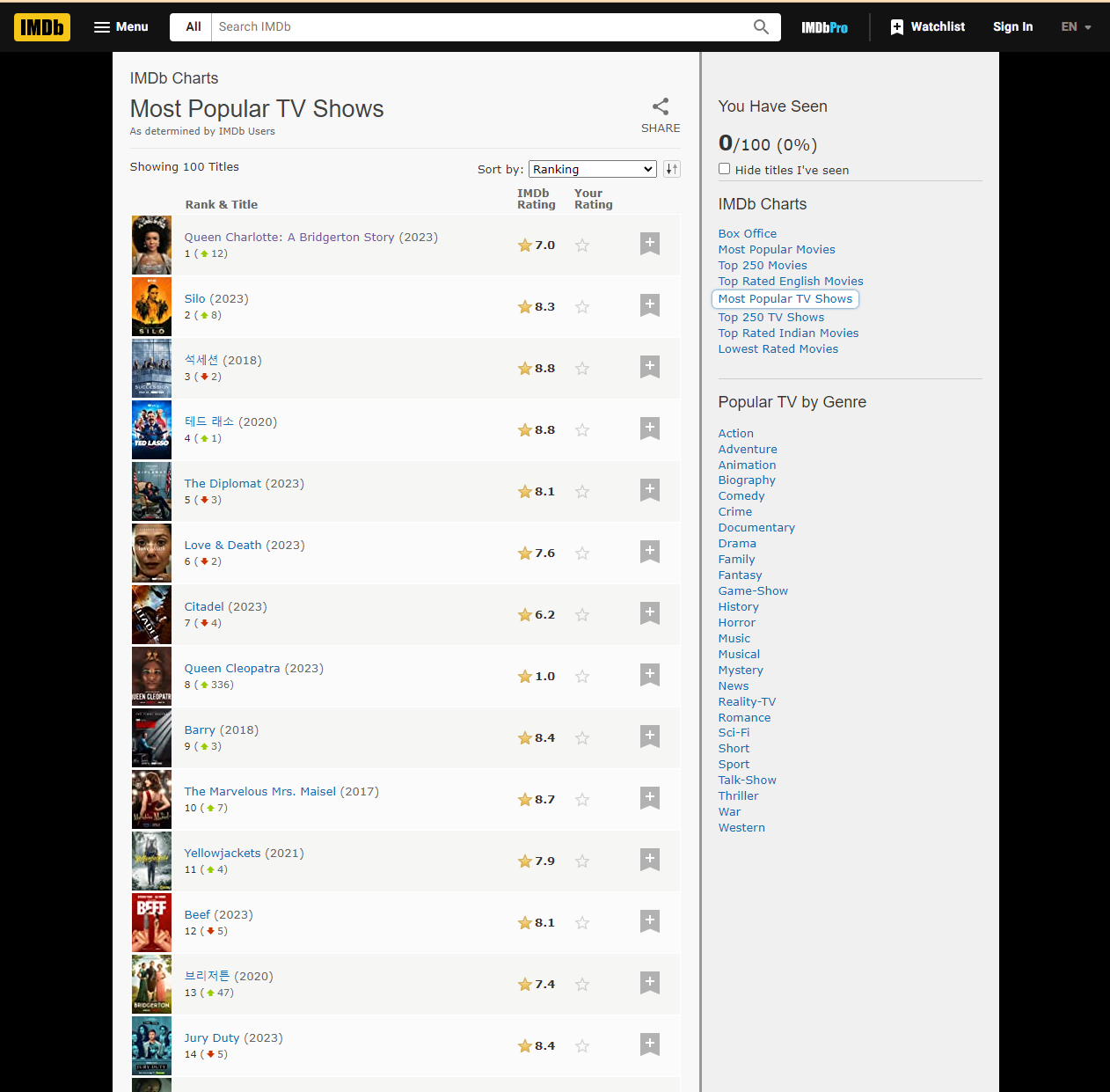
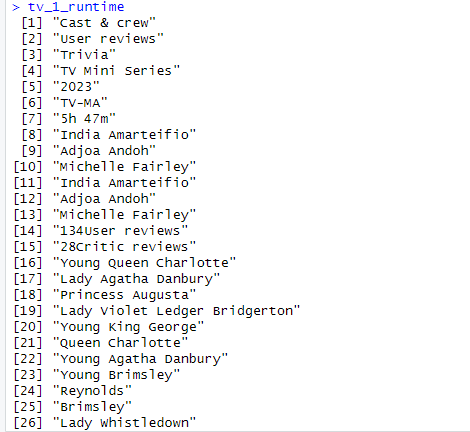
*1. Scrape the list of most popular TV shows on IMDB: http://www.imdb.com/chart/tvmeter
*2. Examine each of the first three(or however many you can get through) tv show subpage to also gain genre and runtime.
*3. Time permitting, also try to get the following:
->How many episodes so far
->Certificate
->First five plot keywords
->Country
->Language다음 링크의 사이트를 접속하면 이런 페이지가 뜬다.
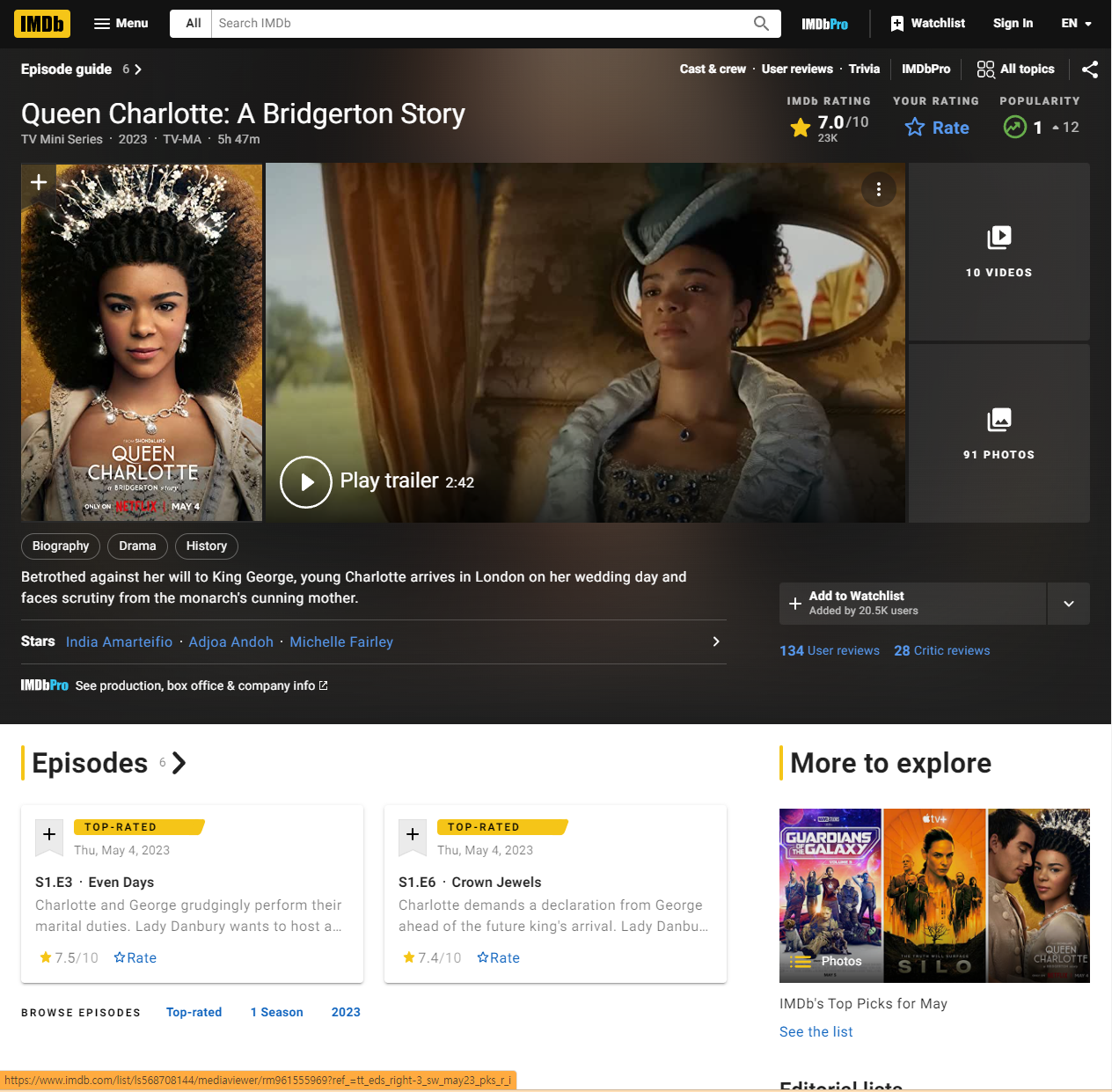
첫번째 Queen Charlotte을 눌러 그 하위페이지에 들어가도록 한다.
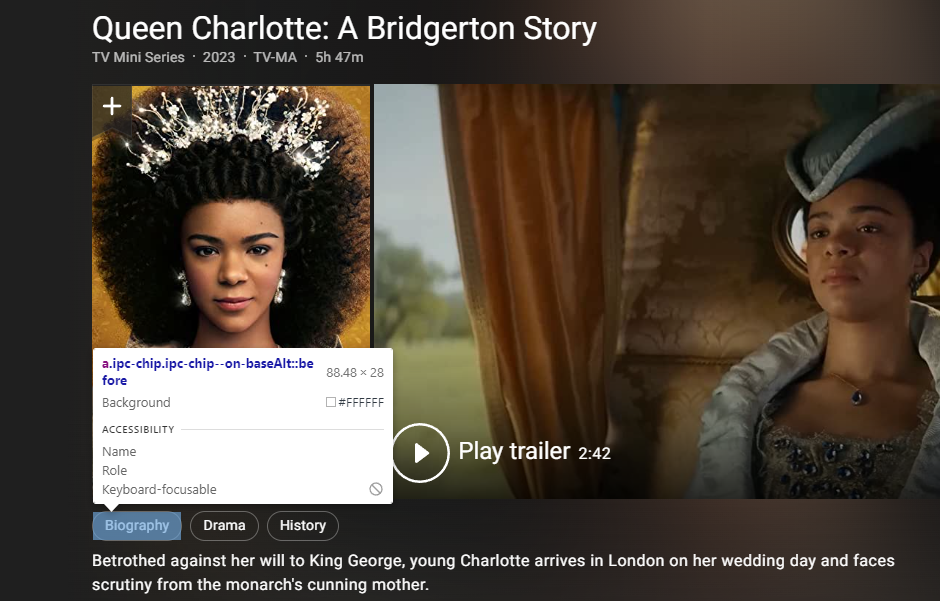
여기서 크롬 개발자 도구 탭을 띄우고, 장르와 런타임 부분을 찾아본다.
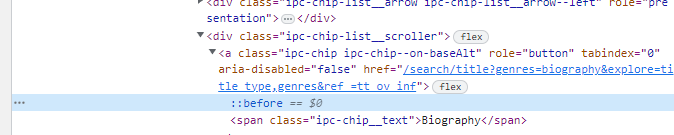
개발자 도구 탭에서 보면, span class="ipc-chip__text"를 찾을 수 있을 것이다.
여기서 주의할 점은, read_html의 주소는 하위페이지의 주소이다.
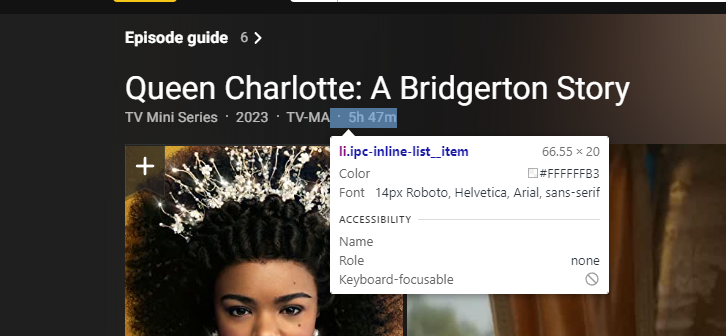
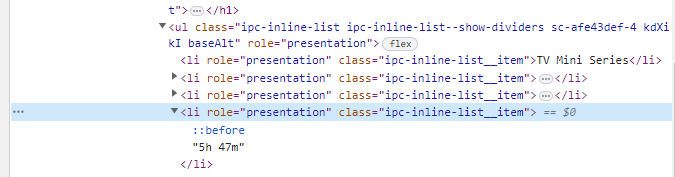
다음은, 런타임을 찾아봐야한다.
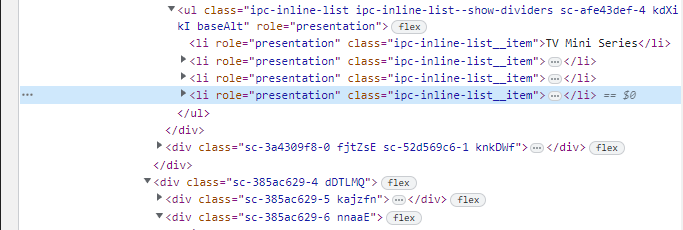
근데, 여기서 개발자 도구를 살펴보면, 같은 클래스 이름을 공유하는 것을 알 수 있을 것이다. 일단, 똑같이 추출해보기로 한다.
예상대로, 많은 내용들이 포함된 것을 알 수 있었다. 여기서 보면, 런타임은 7번째에 있는데, 다음과 같이 정보를 추출할 수 있다.
이런 식으로 나머지 하위 페이지들에서 장르와 런타임 정보를 얻어올 수 있다.
3번 질문도 이와 같이 한번 해보도록 한다.