임의로 정한 Batch 단위로 학습을 진행하면 Internal Covariant Shift 문제가 발생한다.
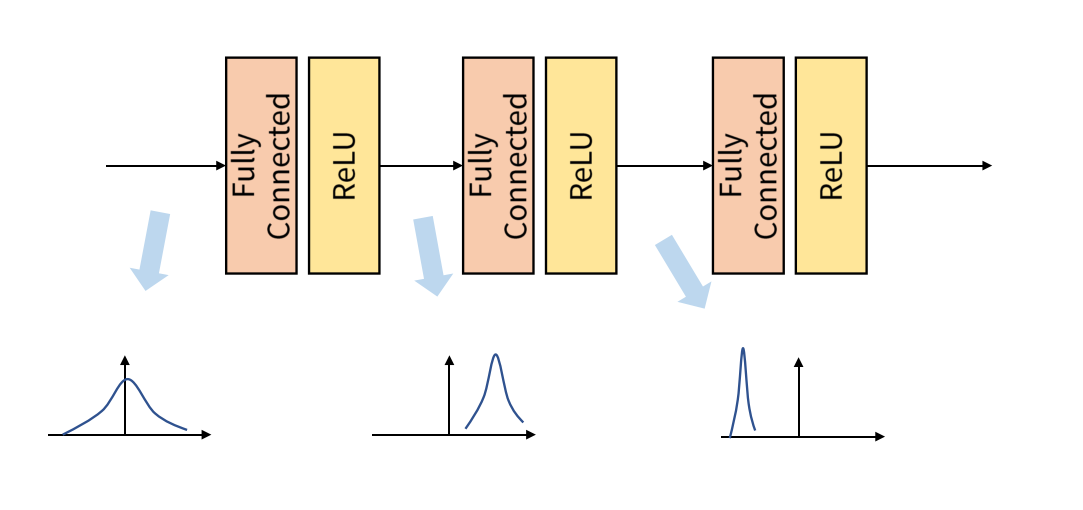
위 그림은 Internal Covariant Shift의 예시를 나타내고 있는데 이처럼 학습 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상을 의미한다.
이러한 현상을 개선하기 위해 사용하는 것이 Batch Normalization이다. Batch Normalization은 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별 평균과 분산을 이용해 정규화하는 것을 의미한다.

위 그림을 확인하면 기존에는 batch마다 다른 분포를 보였지만 평균은 0, 표준 편차는 1로 표준화 함으로써 표준 정규분포를 따르도록 조정해줍니다.
Batch Normalization을 적용했을 때, 이점
Batch 마다 균일한 분포를 가지게 되어 learning rate에 따른 학습 민감도가 줄어들고 이는 grandient exploding, vanishing을 예방할 수 있다.
Internal Covariate Shift로 인해 Batch의 순서에 따라 학습 결과가 완전히 다르게 나오게 되고 이 편차로 인해 원하는 학습 결과를 내지 못하는 경우가 생길 수 있다. -> 적절한 초기 가중치 선정: 어려움, 낮은 학습률 설정: 느리고 local minimum 위험이 있음 -> Batch Normalization
Batch Normalization을 통해 비교적 학습률을 높게 설정할 수 있고 빠르게 학습을 진행할 수 있다.
잘못된 초기 가중치 선정으로 인해 gradient exploding, vanishing이 발생할 확률이 줄어들어 부담이 적다.
Batch Normalization을 적용할 때, 주의할 점
activation function 앞에 적용해야 한다. 일반적으로 Hidden Layer - Batch Normalization - Activiation Function 순서
Batch Normalization 적용 후 ReLU와 같은 활성화 함수를 적용하면 데이터의 절반(음수)이 의미 없는 값을 가지게 될 수 있다.
ReLU의 경우 γ와 β 값을 잘 조절해 편차가 작은 부분이 삭제되지 않도록 해야 한다.
Referenced: https://gaussian37.github.io/dl-concept-batchnorm/
