TensorRT-Based Framework and Optimization Methodology for Deep Learning Inference on Jetson Boards 논문 읽기

딥러닝 가속을 위한 최적화 파라미터
- 전처리 병렬화
- 중간 버퍼
- 부분적 네트워크 복제
- 내부 네트워크 파이프라이닝
- 내부 PE 병렬화
- 후처리 병렬화
공유 메모리의 장점(Jetson Xavier)
- 처리 요소들 간의 입력 데이터 전달이 불필요(zero copy)
- 출력 데이터를 바로 버퍼에 씌울 수 있음
스레드를 이용한 전후처리 병렬화
- 예를 들어 Yolo를 이용한 이미지 전처리를 수행할 경우, 해당 프로세스를 멀티 스레딩을 통해 병렬화하는 것이 좋다.
- 최근에는 가벼운 모델들이 많이 나오기 때문에 여러 사진을 동시에 처리할 수 있는 멀티 스레딩 프로세스가 필수적이다.
내부 PE 병렬화

- 전후처리 스레드와 같은 수의 스트림을 이용해 추론하는 기법을 내부 PE 병렬화라고 한다.
- 위 그림과 같이 전후처리 뿐만이 아니라 추론까지 병렬로 수행하고 있는데 이렇게 되면 컴퓨팅 자원을 더욱 효율적으로 사용할 수 있지만 스트림의 개수가 일정 수준을 초과하게 되면 오히려 성능 악화의 원인이 될 수 있다고 지적한다.
내부 네트워크 파이프라이닝
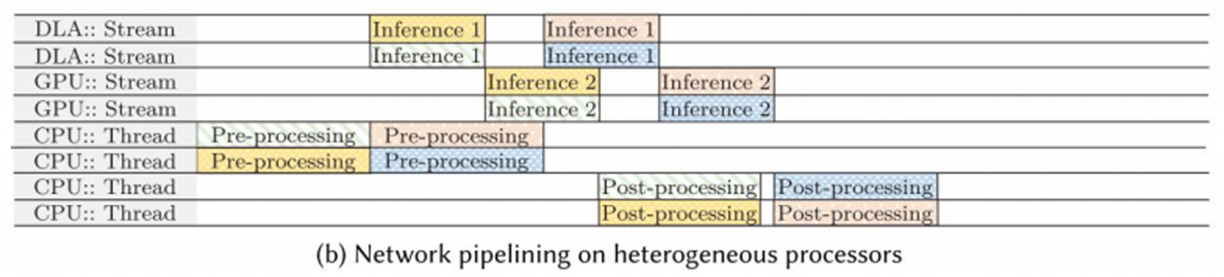
- 위 그림에서는 Inference1 + Inference2로 2개의 stage를 통해 작업을 병렬적으로 빠르게 수행한다.
- 이처럼 여러 개의 stage로 프로세스를 분할 병렬 작업을 수행하면 실행 시간에서 이득을 볼 수 있다.
- 하지만 환경에 따라 다른 최적 stage의 개수를 어떻게 계산할 수 있을까?
부분적 네트워크 복제
- Jetson은 2개의 DLA(Deep Learning Accelerator)를 가지고 있기 때문에 네트워크 복제를 통해 동시에(같은 stage에) 각기 다른 DLA 유닛을 활용하는 것을 부분적 네트워크 복제라고 한다.
- 첫 번째 stage에서는 각각의 DLA가 동작하고 두 번째 stage에서는 GPU를 사용하기 때문에 두 stage 간의 밸런스를 맞추는 것이 중요하다고 할 수 있다.
다른 최적화 파라미터
-
Quantization
연산 값들을 32bit 크기로 표현하면 좋겠지만 그보다 작은 16bit 혹은 8bit로 표현하여 정확도를 조금 손해보더라도 연산량을 줄이는 방법이 있다.
-
batch processing
multiple batch input에 대해 queue를 이용해 여러 프로세스에서 동시에 처리하는 방법, queue access 동기화 때문에 latency가 발생할 수 있지만 여러 프로세스를 이용해 처리하는 것에서 충분히 시간적 이득을 볼 수 있다.

continuous programming