
1️⃣ 모델 진단 (Model Diagnosis)
모델 진단은 머신러닝 모델의 성능 저하 원인을 분석하고, 적절한 개선 방향을 찾기 위한 과정입니다.
주요 목적
- 모델이 과적합인지 과소적합인지 판단
- 데이터 추가 또는 모델 구조 변경 여부 결정
주요 지표
-
훈련 오류 (Training Error)
-
검증 오류 (Validation Error)
진단 해석
- 훈련 오류와 검증 오류 모두 높음 → 과소적합 (Underfitting)
- 훈련 오류는 낮고 검증 오류는 높음 → 과적합 (Overfitting)
2️⃣ Bias / Variance
머신러닝 모델의 예측 오류는 크게 Bias(편향) 와 Variance(분산) 의 합으로 설명할 수 있습니다.
총 오차 구성
| 구분 | 설명 | 증상 | 해결 방법 |
|---|---|---|---|
| Bias (편향) | 모델이 너무 단순하여 패턴을 포착 못함 | 훈련/검증 오류 모두 큼 | 모델 복잡도 ↑ |
| Variance (분산) | 모델이 데이터에 너무 민감 | 훈련 오류 ↓, 검증 오류 ↑ | 데이터 증가, 정규화, Dropout 등 |
Bias-Variance 타겟 다이어그램
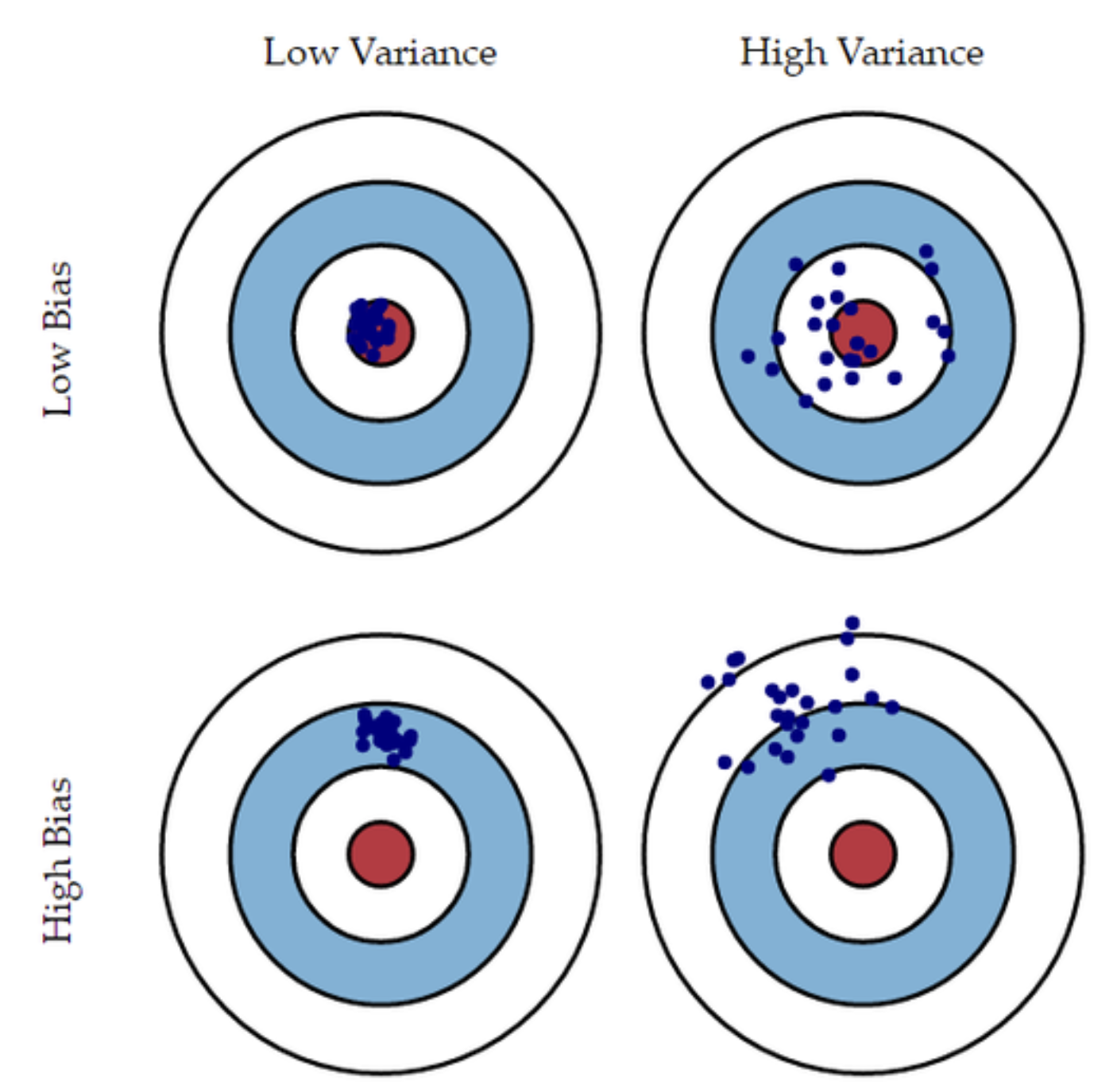
| Low Variance | High Variance | |
|---|---|---|
| Low Bias | 🎯 중앙에 집중: 정확하고 안정적인 예측 | 🎯 중앙 주변 분산: 정확하지만 불안정한 예측 |
| High Bias | 🎯 멀리 있지만 집중: 부정확하나 일관됨 | 🎯 멀리서 흩어짐: 부정확하고 불안정한 예측 |
Bias와 Variance의 영향
| 상태 | Bias | Variance | 결과 |
|---|---|---|---|
| Low Bias, Low Variance | ↓ | ↓ | 🎯 최적 |
| High Bias, Low Variance | ↑ | ↓ | 과소적합 |
| Low Bias, High Variance | ↓ | ↑ | 과적합 |
| High Bias, High Variance | ↑ | ↑ | 성능 저하 |
3️⃣ 학습 곡선 (Learning Curve)
학습 곡선은 훈련 데이터의 양에 따른 모델의 훈련 및 검증 성능을 시각화한 것입니다.
- X축: 훈련 데이터 개수
- Y축: 오류 값 (Training/Validation Error)
일반적 패턴
| 상황 | Training Error | Validation Error | 개선 방안 |
|---|---|---|---|
| 과소적합 | 둘 다 높음 | 둘 다 높음 | 모델 복잡도 증가 |
| 과적합 | 낮음 | 높음 | 데이터 증가, 정규화 적용 |
수식 표현
- 과소적합: 두 에러 모두 높은 위치에서 수렴
- 과적합: 두 에러 사이 간격이 큼
4️⃣ 서포트 벡터 머신 (SVM: Support Vector Machine)
SVM은 두 클래스 사이의 마진(Margin) 을 최대화하여 최적의 결정 경계를 학습하는 분류 알고리즘입니다.
핵심 개념
- Margin: 결정 경계와 가장 가까운 데이터 포인트(서포트 벡터) 간의 거리
- Support Vectors: 마진에 위치한 데이터 포인트들
목적 함수 (Hard Margin)
- ( \mathbf{w} ): 결정 경계의 방향 벡터
- ( b ): 절편
Soft Margin
- 실제 데이터는 완벽하게 분리되지 않기 때문에 일부 오차 허용
- 슬랙 변수(ξ)를 도입하여 제한된 오류 허용
커널 트릭 (Kernel Trick)
SVM은 커널 함수를 사용하여 비선형 데이터도 선형적으로 분리 가능한 고차원 공간으로 사상합니다.
대표 커널 함수
-
Polynomial Kernel
-
RBF (Gaussian) Kernel
-
Sigmoid Kernel
✅ 전체 요약
| 항목 | 설명 | 해결 방법 |
|---|---|---|
| 모델 진단 | 에러를 통해 과적합/과소적합 판단 | 학습 곡선, 에러 비교 |
| Bias / Variance | 예측 오류의 원인 분석 | 모델 복잡도 및 데이터 조절 |
| 학습 곡선 | 데이터 크기에 따른 에러 시각화 | 모델의 일반화 여부 분석 |
| SVM | 최대 마진 분류기 | 커널로 비선형 문제 해결 |
