
📌 K-평균(K-Means) 알고리즘
K-평균(K-Means)은 비지도 학습(Unsupervised Learning) 알고리즘으로, 데이터를 유사한 특성끼리 K개의 군집(Cluster)으로 나누는 군집화(Clustering) 기법입니다.
데이터를 K개의 중심(centroid)을 기준으로 묶고, 중심이 군집의 평균이 되도록 반복적으로 업데이트합니다.
알고리즘 작동 방식
1. 군집 수 K 선택
- 사용자가 K값을 직접 지정
- 일반적으로 엘보우 방법을 사용하여 적절한 K값 선택
2. 초기 중심점 무작위 선택
3. 각 데이터 포인트를 가장 가까운 중심점에 할당
- 유클리드 거리로 가장 가까운 중심점에 할당
4. 중심점 업데이트
5. 중심이 더 이상 변하지 않을 때까지 반복
시각 자료
✅ K-평균 수렴 과정

중심점이 반복적으로 이동하며 수렴하는 모습
✅ 엘보우 기법 (Elbow Method)
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import numpy as np
# Load Iris dataset
iris = load_iris()
X = iris.data
# Run KMeans for a range of cluster numbers
wcss = []
K_range = range(1, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(X)
wcss.append(kmeans.inertia_) # Sum of squared distances to closest cluster center
# Plot the Elbow Graph
plt.figure(figsize=(8, 5))
plt.plot(K_range, wcss, marker='o')
plt.title('Elbow Method using Iris Dataset')
plt.xlabel('Number of Clusters (K)')
plt.ylabel('WCSS (Inertia)')
plt.grid(True)
plt.xticks(K_range)
plt.tight_layout()
plt.show()
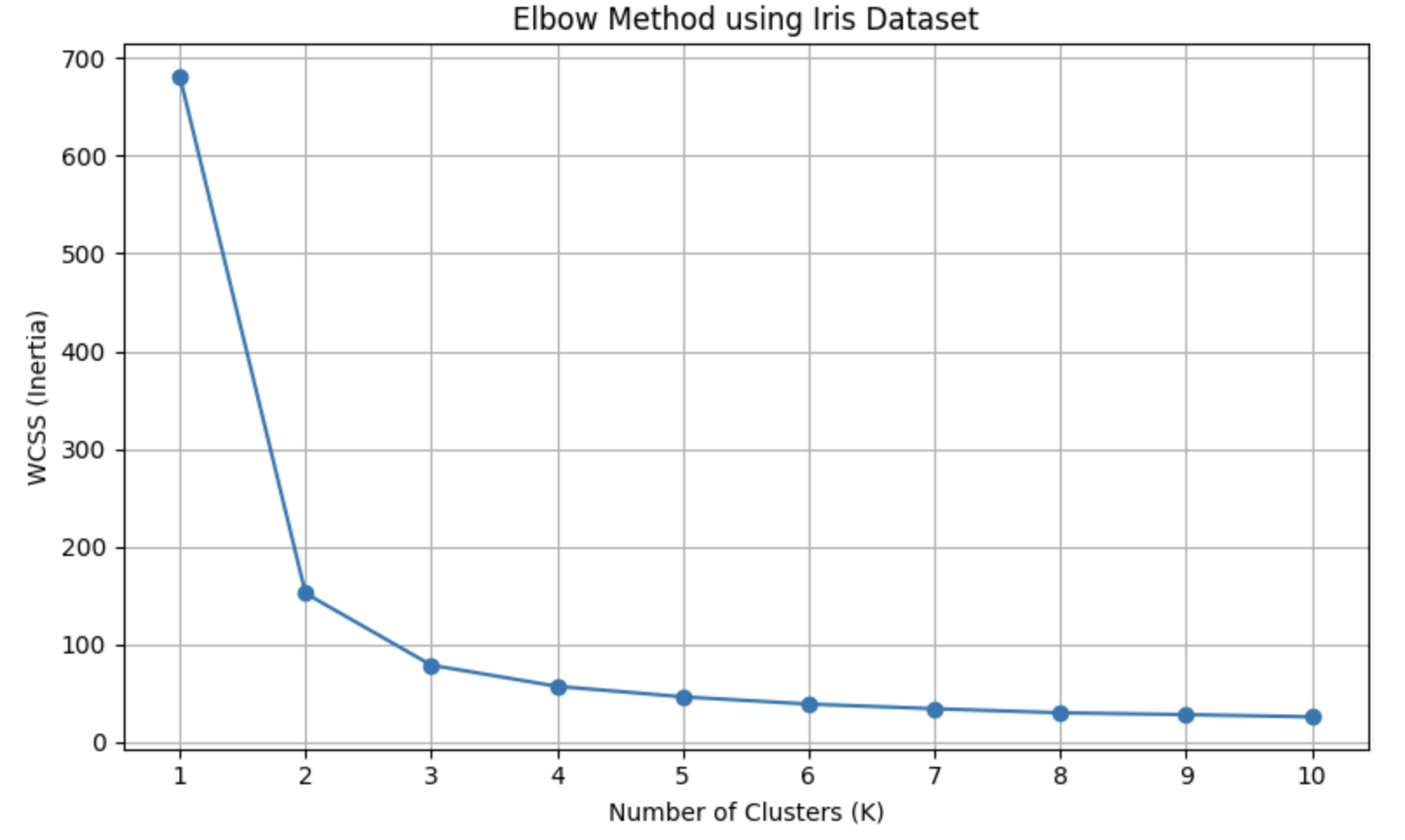
결론
- 엘보우 기법은 최적의 K를 찾기 위한 시각적 도구입니다.
- 아이리스 데이터셋처럼 레이블이 3개(Setosa, Versicolor, Virginica)인 경우, 엘보우 지점 역시 3에 가까운 것을 확인할 수 있습니다.
- 하지만 실제 문제에서는 엘보우가 명확하지 않을 수도 있으므로, 실루엣 분석(silhouette score) 같은 보완 기법과 함께 사용하면 더 좋습니다.
WCSS 값이 급격히 감소하다 완만해지는 지점이 최적의 K
📍 유클리드 거리
📍 군집 중심 업데이트
📍 비용 함수 (WCSS, Within-Cluster Sum of Squares)
PCA (주성분 분석, Principal Component Analysis)
PCA는 고차원 데이터를 저차원으로 축소하면서도 정보(분산)를 최대한 보존하는 비지도 학습 기반의 차원 축소 기법입니다.
📌 목적: 데이터 압축, 시각화, 노이즈 제거, 학습 효율 향상
주요 목적
- 차원 축소 (Dimensionality Reduction)
- 노이즈 제거 및 정제
- 2D/3D 시각화
- 모델 학습 속도 향상
- 특성 간 상관관계 제거 및 주요 Feature 선택
PCA 알고리즘 단계
1️⃣ 데이터 정규화
- 평균 정규화:
- 표준화 (스케일링):
2️⃣ 공분산 행렬 계산
- ( \Sigma ): 공분산 행렬
- ( X ): 정규화된 입력 행렬
- ( m ): 샘플 수
3️⃣ 고유벡터 및 고유값 계산 (Eigenvectors, Eigenvalues)
- ( U ): 고유벡터 행렬 (주성분 방향)
- ( S ): 고유값 대각행렬 (각 방향의 분산 크기)
4️⃣ 주성분 선택 및 투영
- 고유값이 큰 순서대로 상위 (k)개 선택:
- 데이터 투영:
- ( Z ): 차원 축소된 데이터 (PC Score)
복원 (Reconstruction from Z)
주성분 수 선택 방법
-
Explained Variance 비율 확인
→pca.explained_variance_ratio_값 사용 -
Elbow Method
→ 그래프에서 꺾이는 지점 선택 -
도메인 지식 활용
→ 예: 유전자 분석에서는 보통 10개 사용
전체 흐름 요약
1. 원본 데이터 X
↓ 정규화
2. X_normalized
↓ 공분산 계산
3. Σ
↓ 고유값 분해
4. U, S
↓ 주성분 선택
5. Z = X_norm · U_reduce
↓
6. 복원: X_approx = Z · U_reduce^T| 항목 | 내용 |
|---|---|
| 목적 | 데이터 압축, 시각화, 계산 효율 향상 |
| 핵심 단계 | 공분산 → 고유벡터 → 투영 |
| 주의사항 | 정보 손실 가능, 불필요한 축소 방지 |
| 활용 분야 | 전처리, 특성 선택, 차원 축소 등 |
