Amazon Athena
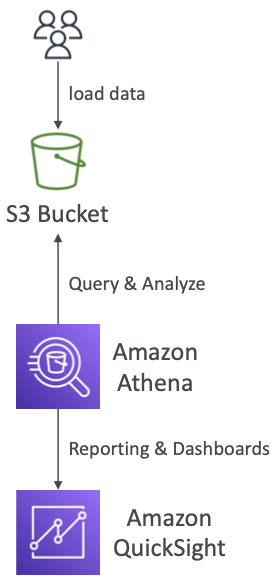
- Amazon S3에 저장된 데이터를 분석하기 위한 서버리스 쿼리 서비스
- 표준 SQL 언어를 사용하여 파일을 쿼리함 (Presto 엔진에 빌드)
- CSV, JSON, ORC, Avro, Parquet 등 다양한 형식을 지원
- 가격: 검색된 데이터 1 TB 당 $ 5.00
- 보고서 및 대시보드를 위해 주로 Amazon Quicksight와 함께 사용됨
- 사용 사례: 비즈니스 인텔리전스, 분석, 보고서 작성, VPC Flow Logs, ELB Logs, CloudTrail 추적 등의 AWS 서비스에서 발생하는 모든 로그를 쿼리하고 분석할 수 있음
- 시험 팁: 서버리스 SQL 엔진을 사용한 Amazon S3 데이터 분석이 나오면 Athena를 떠올리면 됨
Performance Improvement
- 비용 절감을 위해 컬럼(열) 기반 데이터를 사용 (스캔이 적어짐)
- Apache Parquet 또는 ORC를 권장
- 성능이 크게 향상됨
- Glue를 사용하여 데이터를 Parquet 또는 ORC로 변환
- 데이터를 압축하여 더 적은 검색 (bzip2, gzip, lz4, snappy, zlib, zstd...)
- 특정 열을 항상 쿼리한다면 데이터 세트를 분할(파티션)
- S3 버킷에 있는 전체 경로를 슬래시로 분할 - 각 슬래시에 다른 열 이름을 붙여 열별로 특정 값을 저장

- 예시: s3://athena-examples/flight/parquet/year=1991/month=1/day=1/
- S3 버킷에 있는 전체 경로를 슬래시로 분할 - 각 슬래시에 다른 열 이름을 붙여 열별로 특정 값을 저장
- 오버헤드를 최소화하기 위해 큰 파일 (> 128MB)을 사용
Federated Query
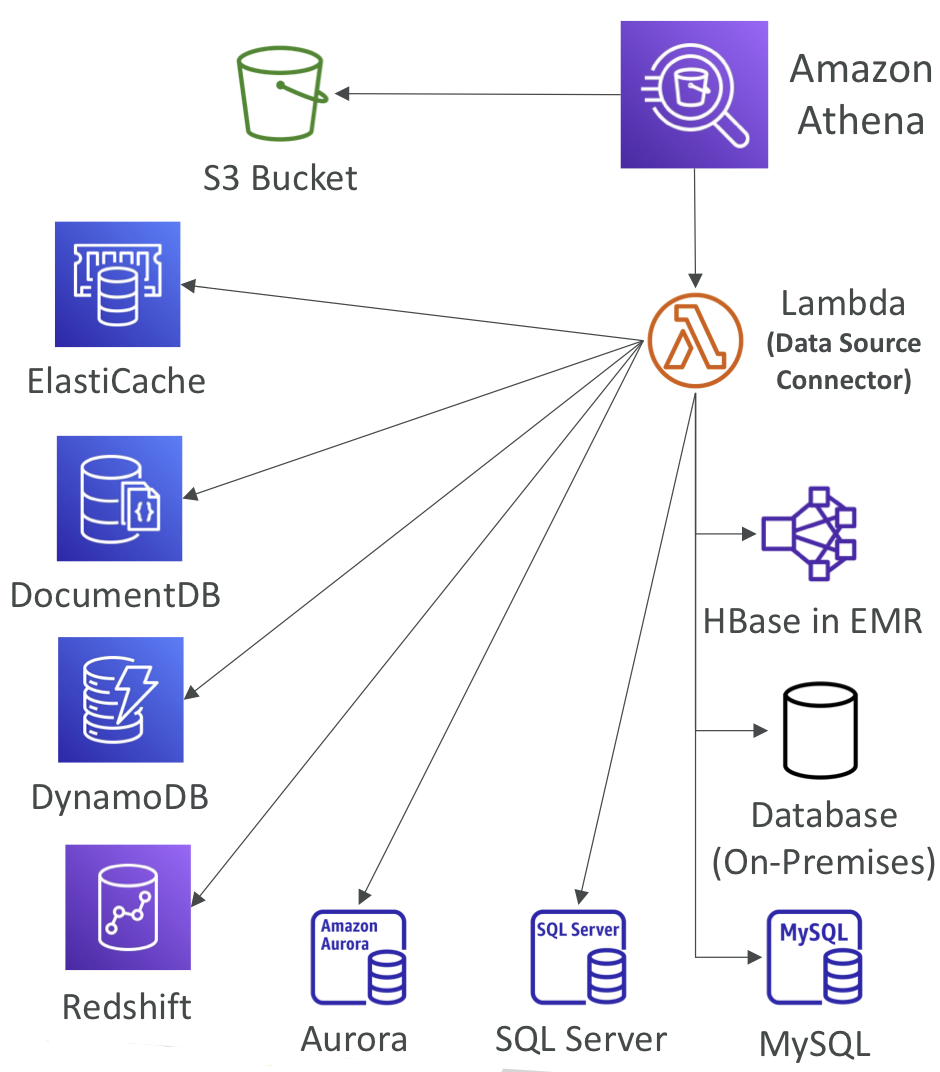
- 관계형, 비관계형, 객체, 사용자 지정 데이터 소스 (AWS 또는 온프레미스)에 저장된 데이터를 대상으로 SQL 쿼리를 실행할 수 있도록 함
- 연합 쿼리를 실행하기 위해 AWS Lambda에서 실행되는 데이터 소스 커넥터를 사용 (예: CloudWatch Logs, DynamoDB, RDS 등)
- 쿼리 결과를 Amazon S3에 저장
Redshift
- Redshift는 PostgreSQL을 기반으로 하지만 OLTP(온라인 트랜잭션 처리)에는 사용되지 않는다.
- 온라인 분석 처리 OLAP(Online Analytical Processing) 유형의 데이터베이스 - 분석 및 데이터 웨어하우징에 사용
- 다른 데이터 웨어하우스에 비해 10배 빠른 성능을 제공하며 PB 단위의 데이터까지 확장 가능
- 데이터를 컬럼(열) 기반으로 저장 (행 기반이 아님!) 하고 병렬 쿼리 엔진을 사용
- 프로비저닝된 인스턴스에 따라 요금을 지불
- 쿼리를 수행하기 위해 SQL 인터페이스를 제공
- Amazon Quicksight나 Tableau와 같은 BI 도구와 통합될 수 있음
- Athena와 비교했을 때, 인덱스를 통해 빠른 쿼리/조인/집계가 가능합
Redshift Cluster
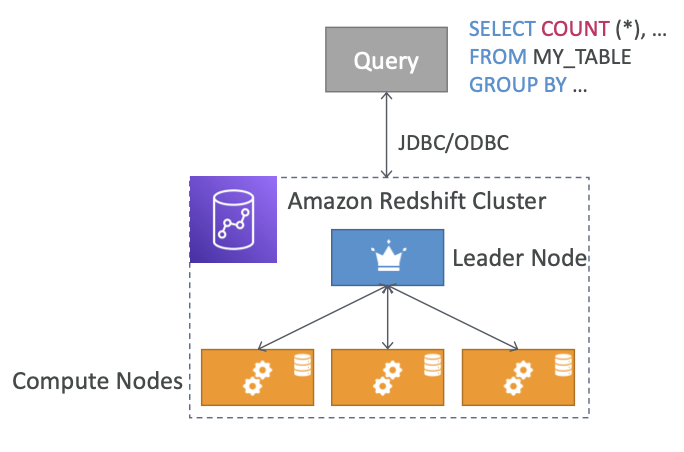
- 리더 노드(Leader Node): 쿼리 계획 및 결과 집계를 위한 노드
- 컴퓨트 노드(Compute Node): 쿼리 실행 및 결과를 리더 노드로 전송하는 노드
- 노드 크기는 미리 프로비저닝해야 함
- 예약 인스턴스(Reserved Instances)를 사용하여 비용을 절감할 수 있음
Snapshots & DR
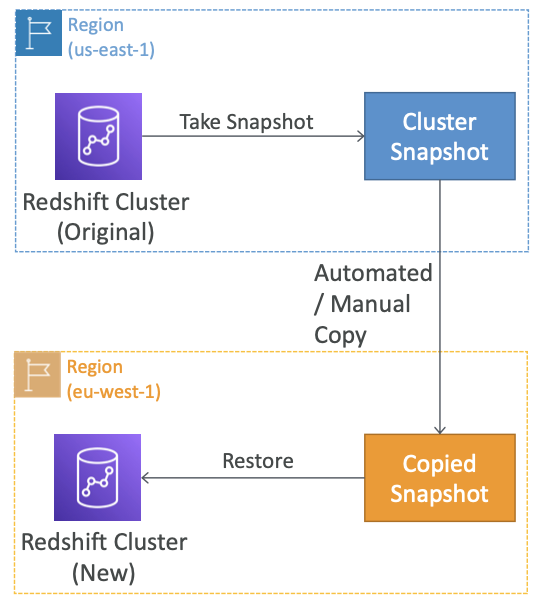
- Redshift에는 다중 AZ 모드가 없음
- 스냅샷은 클러스터의 지정 시간 백업이며 S3 내부에 저장된다.
- 스냅샷은 증분(incremental)한다. (변경 사항만 저장함)
- 스냅샷을 사용하여 새로운 클러스터로 복원할 수 있다.
- 자동화: 매 8시간마다, 5GB마다 또는 일정에 따라 스냅샷을 생성한다. 보존 기간은 1일부터 35일까지 설정할 수 있다.
- 수동: 스냅샷은 삭제할 때까지 보존된다.
- 클러스터의 스냅샷(자동화된 또는 수동 스냅샷)을 다른 AWS 리전으로 자동으로 복사하도록 Redshift를 구성하여 재해 복구 전략을 사용할 수 있다.
Loading data into Redshift: Large inserts are MUCH better

Redshift Spectrum
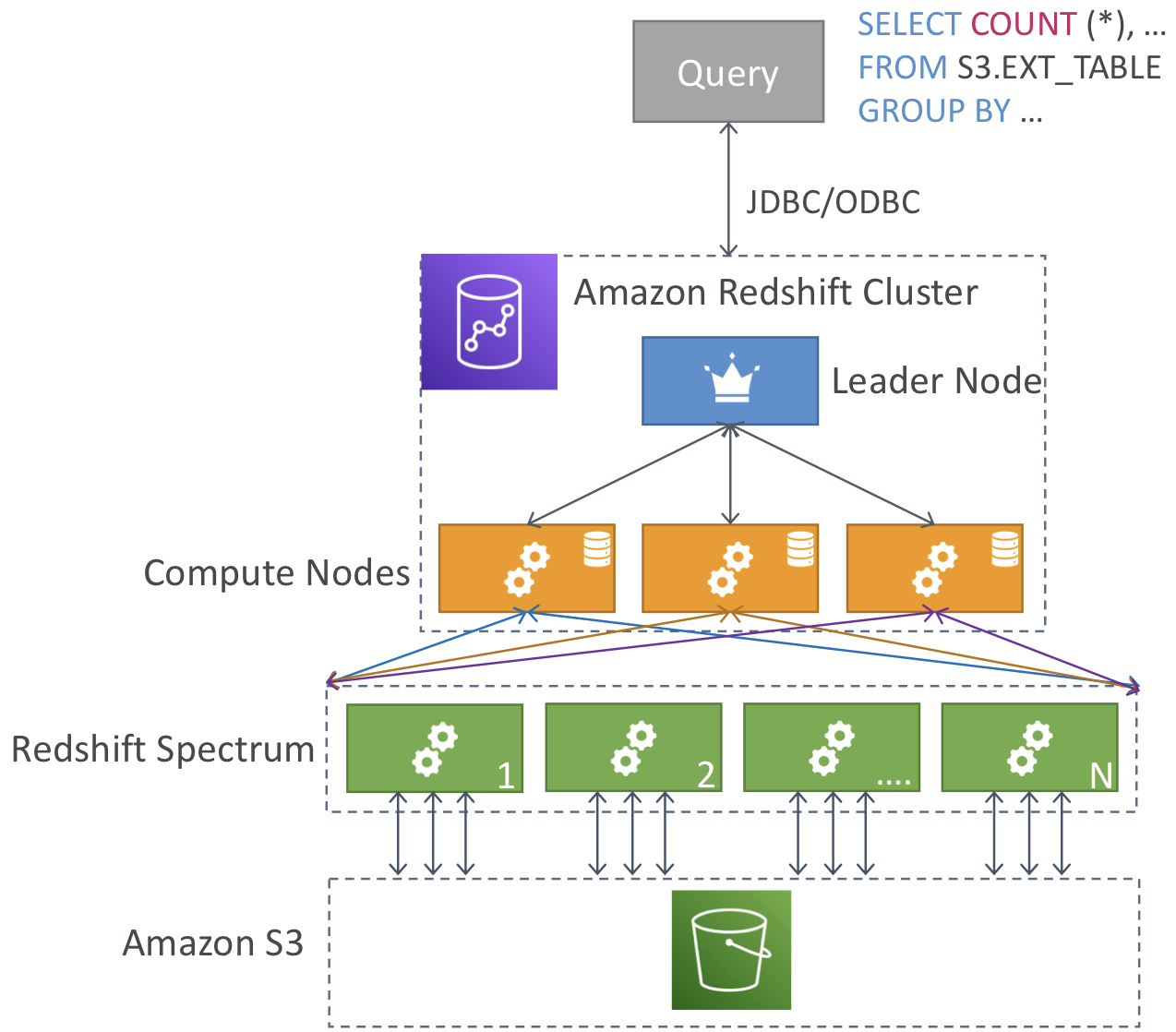
- Amazon S3에 저장된 데이터를 Redshift를 사용해 분석은 하지만 Redshift에 로드하지는 않는다.
- 쿼리를 시작하려면 Redshift 클러스터가 있어야 한다.
- 쿼리는 수천 개의 Redshift Spectrum 노드로 제출된다.
Amazon OpenSearch Service
- Amazon OpenSearch Service는 Amazon ElasticSearch의 후속 서비스이다. (라이선스 문제로 이름이 변경됨)
- DynamoDB에서는 기본 키나 데이터베이스의 인덱스로만 데이터를 쿼리할 수 있지만 OpenSearch에서는 부분적으로 일치하는 필드를 포함해 모든 필드를 검색할 수 있다.
- 일반적으로 OpenSearch는 다른 데이터베이스를 보완하기 위해 사용된다.
- OpenSearch를 생성하고 사용하기 위해서는 인스턴스의 클러스터를 생성해야 한다. (서버리스 서비스가 아님)
- 자체 쿼리 언어가 있어 SQL을 지원하지 않는다.
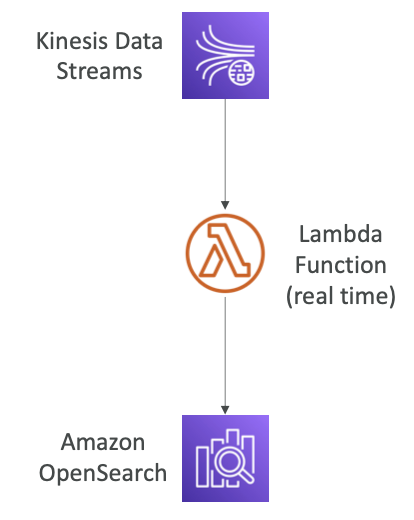
- Kinesis Data Firehose, AWS IoT, and CloudWatch Logs, 사용자 지정 애플리케이션의 데이터를 주입할 수 있다.
- Cognito, IAM과 통합해 제공하는 보안을 통해 저장 데이터 암호화와 전송 중 암호화가 가능하다.
- OpenSearch에는 OpenSearch 대시보드 (시각화 도구)가 함께 제공된다.
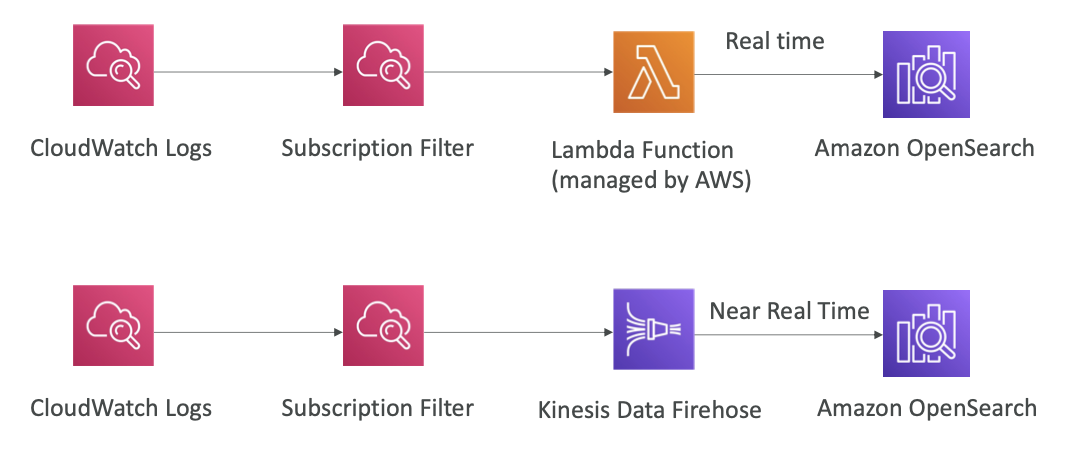
OpenSearch patterns
DynamoDB
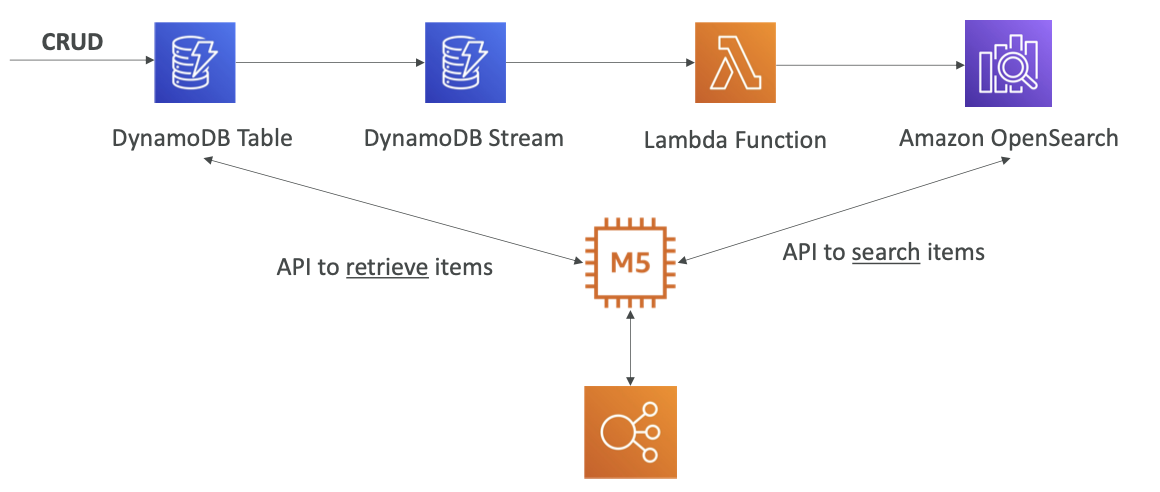
CloudWatch Logs
Kinesis Data Streams
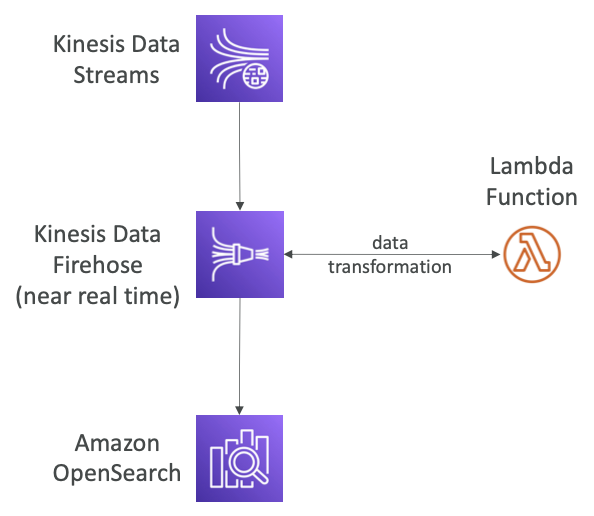
Kinesis Data Firehose
Amazon EMR
- EMR = Elastic MapReduce
- AWS에서 빅데이터 작업을 위한 하둡(Hadoop) 클러스터 생성하는데 사용됨
- 클러스터는 수백 개의 EC2 인스턴스로 구성될 수 있다.
- EMR은 Apache Spark, HBase, Presto, Flink 등과 함께 사용된다.
- EMR은 상기 서비스에 관한 프로비저닝과 구성을 대신 처리해준다.
- 클러스터를 자동으로 확장할 수 있고 Spot 인스턴스와 통합되므로 가격 할인 혜택을 받을 수도 있다.
- 사용 사례: 데이터 처리, 머신러닝, 웹 인덱싱, 빅 데이터 등
Node types & purchasing
- 마스터 노드: 클러스터를 관리하고 다른 모든 노드의 상태를 조정하며 클러스터의 상태를 모니터링 - 지속적으로 실행되는 노드
- 코어 노드: 태스크를 실행하고 데이터를 저장하는 역할 - 지속적으로 실행되는 노드
- 구매 옵션:
- On-demand: 신뢰성 있고 예측 가능하며 절대 종료되지 않음
- Reserved (최소 1년): 비용 절감, 가능한 경우에 EMR이 자동으로 예약 인스턴스를 사용함 - 장기 실행해야하는 마스터 노드와 코어 노드에 적합함
- Spot Instances: 저렴하지만 중지될 수 있으므로 신뢰성이 낮음 - 태스크 노드에 적합함
- EMR에서 배포할 때는 장기 실행 클러스터에서 예약 인스턴스를 사용하거나 임시 클러스터를 사용해 특정 작업을 수행하고 분석 완료 후에 삭제할 수 있다.
Amazon QuickSight
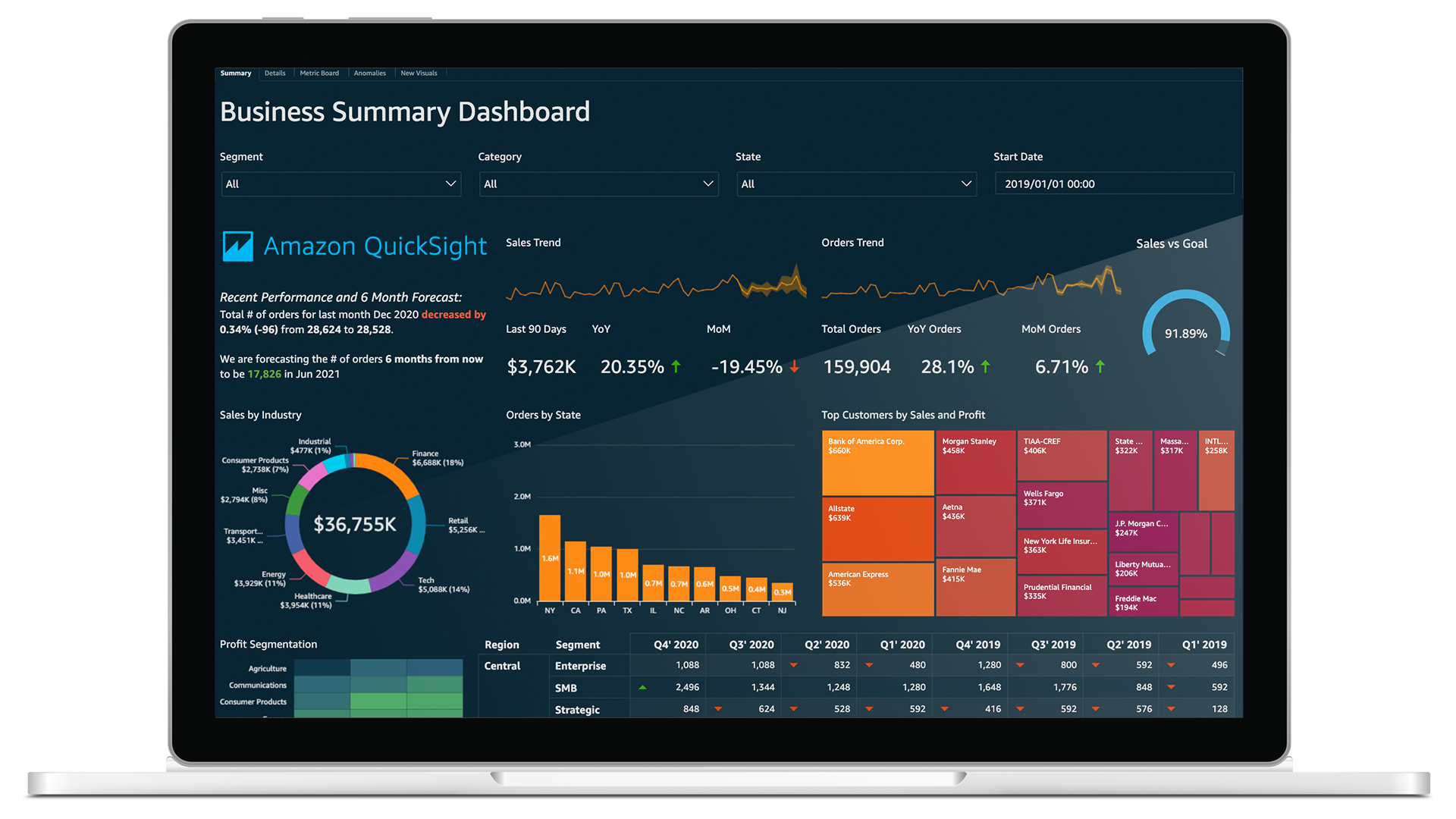
- 서버리스 머신 러닝 기반 비즈니스 인텔리전스 서비스로, 대화형 대시보드를 생성할 수 있다.
- 빠르고 오토 스케일링이 가능하며 세션별 가격 책정이 가능하다.
- 사용 사례:
- 비즈니스 분석
- 시각화 구축
- 임시 분석 수행
- 비즈니스 인사이트 획득
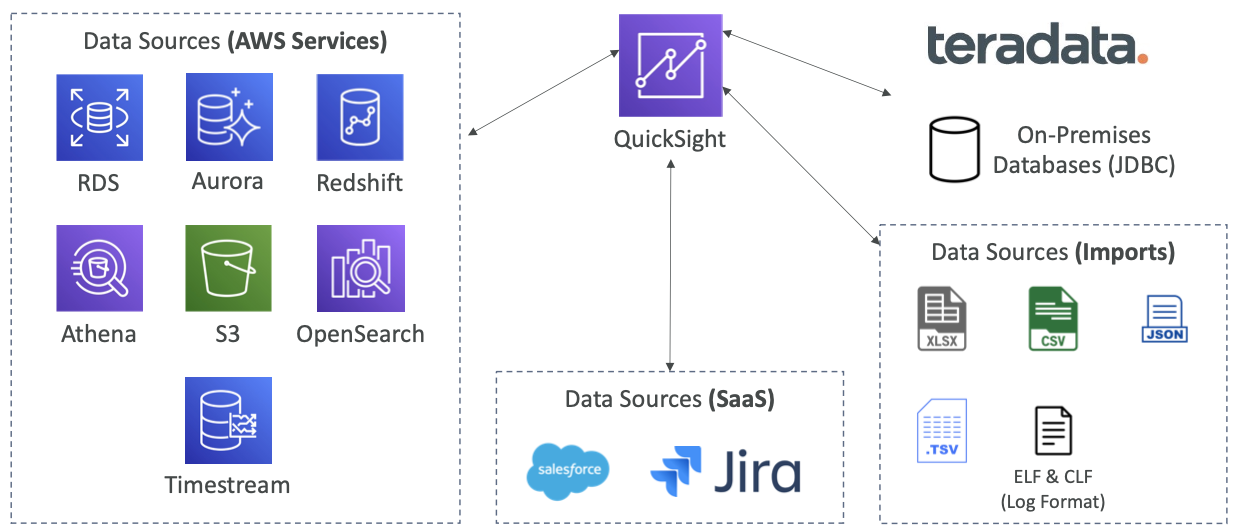
- RDS, Aurora, Athena, Redshift, S3 등 다양한 데이터 소스에 연결 가능
- QuickSight로 데이터를 가져온 경우 SPICE 엔진을 사용하여 인메모리 계산이 가능
- 엔터프라이즈 에디션: 컬럼 수준 보안 (Column-Level security, CLS) 가능
QuickSight Integrations
Dashboard & Analysis
QuickSight에는 세 가지 개념이 있다: 대시보드, 분석, 사용자
- 사용자
- Standard versions - 사용자 정의, Enterprise versions - 그룹 정의
- QuickSight의 사용자와 그룹은 QuickSight 서비스 전용이며, IAM 사용자와는 다르다.
- Standard versions - 사용자 정의, Enterprise versions - 그룹 정의
- 대시보드
- 대시보드는 공유할 수 있는 읽기 전용 스냅샷이며 분석 결과를 공유할 수 있다.
- 분석의 구성(필터링, 매개변수, 제어, 정렬 옵션 등)을 보존한다.
- 분석 결과나 대시보드를 사용자 또는 그룹과 공유할 수 있다.
- 대시보드를 공유하기 위해선 일단 대시보드부터 게시(publish)해야 한다.
- 대시보드에 액세스 권한이 있는 사용자는 기본 데이터를 볼 수 있다.
AWS Glue

- Glue는 추출(extract), 변환(transform), 로드(load) 서비스 를 관리한다. ETL 서비스라고도 한다.
- 분석을 위해 데이터를 준비하고 변환하는 데 유용하다.
- 완전 서버리스 서비스이다.
Convert data into Parquet format
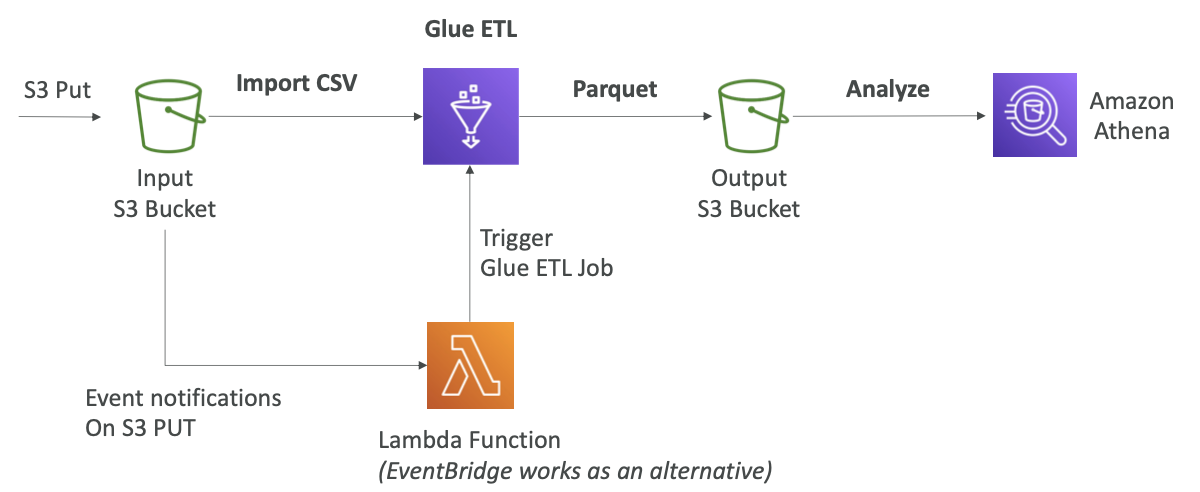
Glue Data Catalog: catalog of datasets
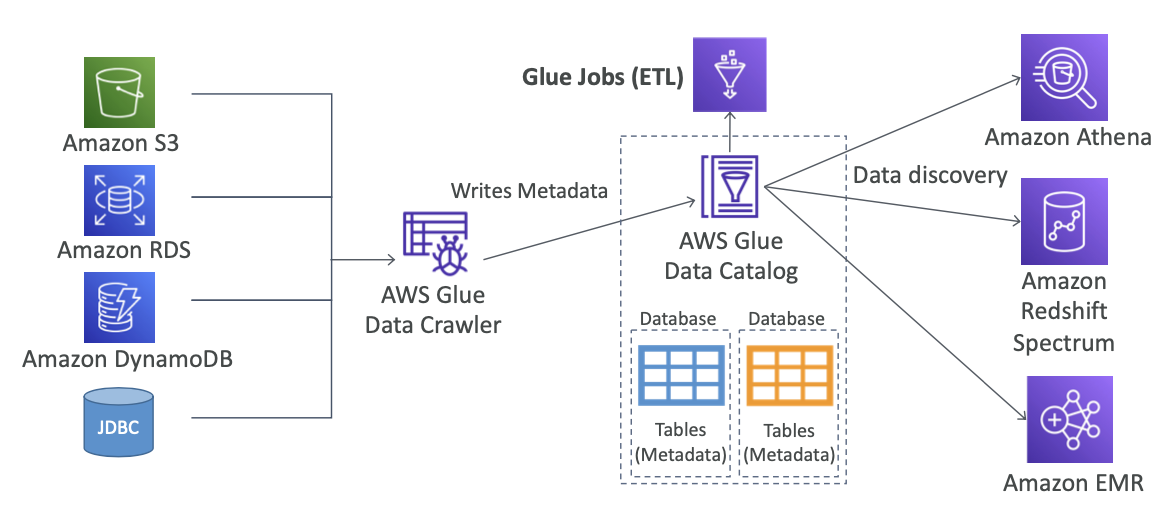
things to know at a high-level
- Glue 작업 북마크: 이전 데이터의 재처리 방지
- Glue Elastic Views:
- SQL을 사용하여 여러 데이터 저장소에서 데이터를 결합하고 복제
- 커스텀 코드를 지원하지 않으며, Glue가 원본 데이터의 변경 사항을 모니터링 함. 서버리스 서비스
- "가상 테이블" (materialized view)을 활용
- Glue DataBrew: 사전에 빌드된 변환을 사용하여 데이터 정리 및 정규화
- Glue Studio: Glue에서 ETL 작업을 생성, 실행 및 모니터링하기 위한 GUI
- Glue 스트리밍 ETL (Apache Spark Structured Streaming 기반): inesis Data Streaming, Kafka, MSK (관리형 Kafka)와 호환 가능
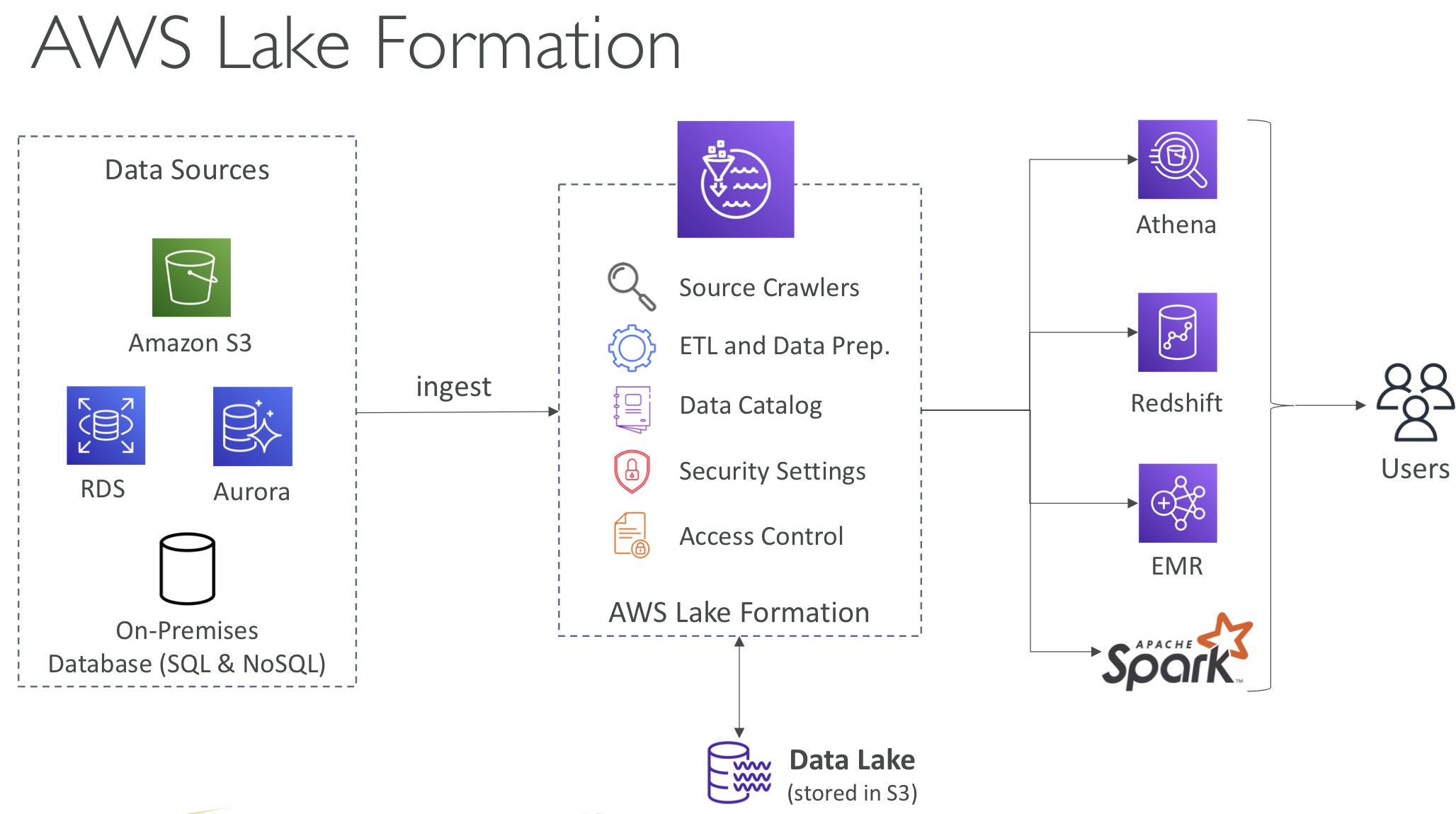
AWS Lake Formation
- 데이터 레이크(Data lake) = 분석 목적을 위해 모든 데이터를 한곳으로 모아주는 중앙 집중식 저장소
- Lake Formation은 데이터 레이크 생성을 수월하게 해주는 완전 관리형 서비스 - 보통 수개월씩 걸리는 작업을 며칠 만에 완료할 수 있음
- 데이터 검색, 정제, 변환, 주입을 위한 데이터 레이크 구성
- 데이터 수집, 정제, 이동, 카탈로깅, 복제 등의 복잡한 수동 단계를 자동화하고 기계 학습(ML) 변환을 사용하여 중복 데이터를 제거함
- 데이터 레이크에서 정형 데이터와 비정형 데이터를 결합할 수 있음
- 사전 구성된 소스 블루프린트: S3, RDS, 관계형 및 NoSQL DB 등에서 지원됨
- 애플리케이션에서 행, 열 수준의 세분화된 액세스 제어 가능
- AWS Glue 위에 빌드되는 계층이긴 하지만 Glue와 직접 상호 작용하지는 않음
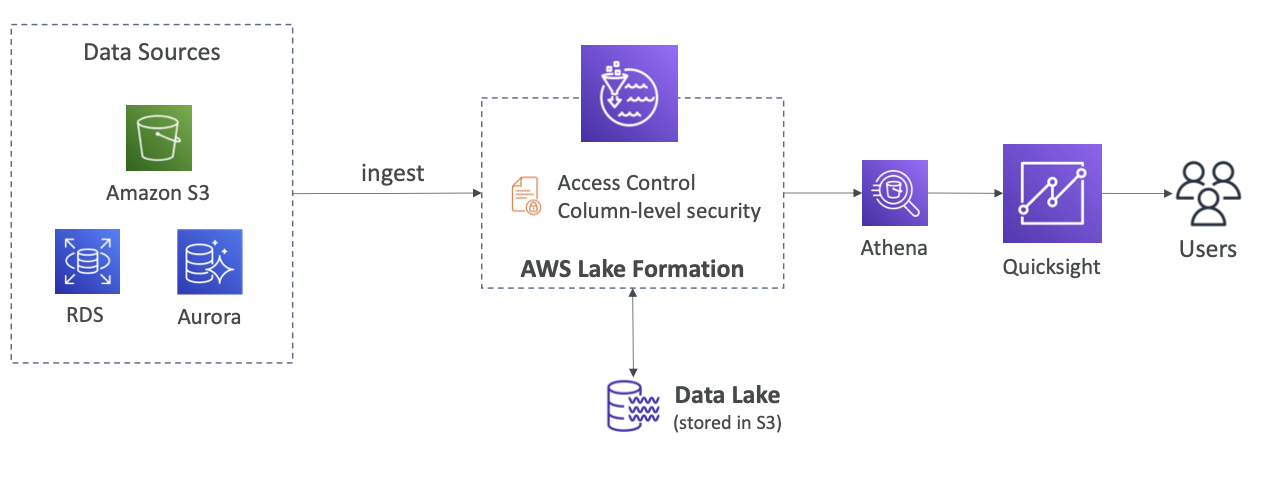
Centralized Permissions Example
Kinesis Data Analytics
SQL 애플리케이션 용과 Apache Flick용이 있다.
Kinesis Data Analytics for SQL application
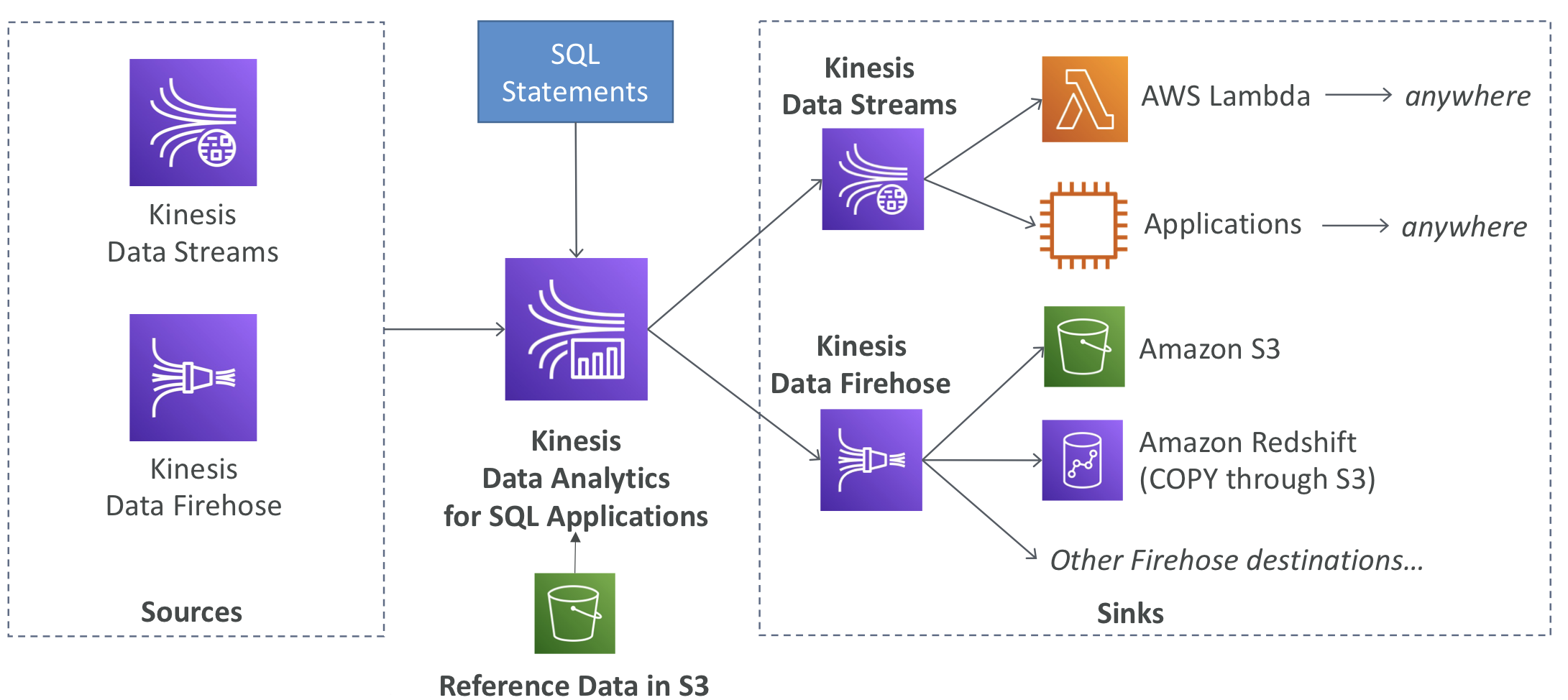
- Kinesis Data Analytics는 SQL을 사용하여 Kinesis Data Streams 및 Firehose의 실시간 분석을 수행한다.
- Amazon S3의 참조 데이터를 추가하여 스트리밍 데이터를 보강할 수 있다.
- 완전 관리형 서비스이므로 서버를 프로비저닝할 필요가 없다.
- 오토 스케일링이 가능하다.
- Kinesis Data Analytics에 전송된 데이터만큼 비용을 지불한다.
- Output:
- Kinesis Data Streams: 실시간 분석 쿼리에서 스트림을 생성
- Kinesis Data Firehose: 분석 쿼리 결과를 대상으로 전송
- 사용 사례:
- 시계열 분석
- 실시간 대시보드
- 실시간 지표
Kinesis Data Analytics for Apache Flink
- Flink (Java, Scala 또는 SQL)을 사용하여 스트리밍 데이터를 처리하고 분석
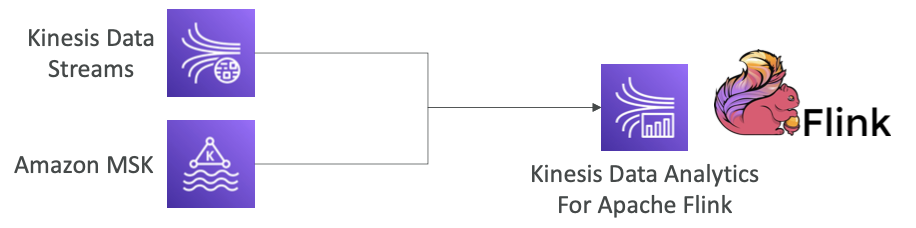
- AWS의 관리형 클러스터에서 Apache Flink 애플리케이션을 실행할 수 있다.
- 컴퓨터 리소스를 자동으로 프로비저닝할 수 있고, 병렬 연산과 오토 스케일링이 가능하다.
- 애플리케이션 백업은 체크포인트와 스냅샷으로 구현된다.
- Apache Flink 프로그래밍 기능을 사용할 수 있다.
- Flink는 Firehose의 데이터는 읽지 못한다. (Firehose에서 데이터를 읽고 실시간 분석하려면 SQL 애플리케이션 용 Kinesis Data Analytics를 사용해야 함)
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Kafka는 Amazon Kinesis의 대안 - 두 서비스 모두 데이터를 스트리밍한다.
- MSK는 AWS의 완전 관리형 Kafka 클러스터 서비스
- 클러스터 생성, 업데이트, 삭제 가능
- MSK는 클러스터 내 Kafka 브로커 노드와 Zookeeper 노드를 자동으로 생성하고 관리
- 고가용성을 위해 VPC의 클러스터를 최대 세 개의 다중 AZ 전역에 배포
- 일반적인 Apache Kafka 장애로부터 자동 복구 기능
- EBS 볼륨에 데이터를 원하는 기간 동안 저장할 수 있음
- MSK Serverless
- 용량 관리없이 MSK에서 Apache Kafka를 실행할 수 있음
- MSK가 자동으로 리소스를 프로비저닝하고 컴퓨팅 및 스토리지를 확장함
Apache Kafka at a high level
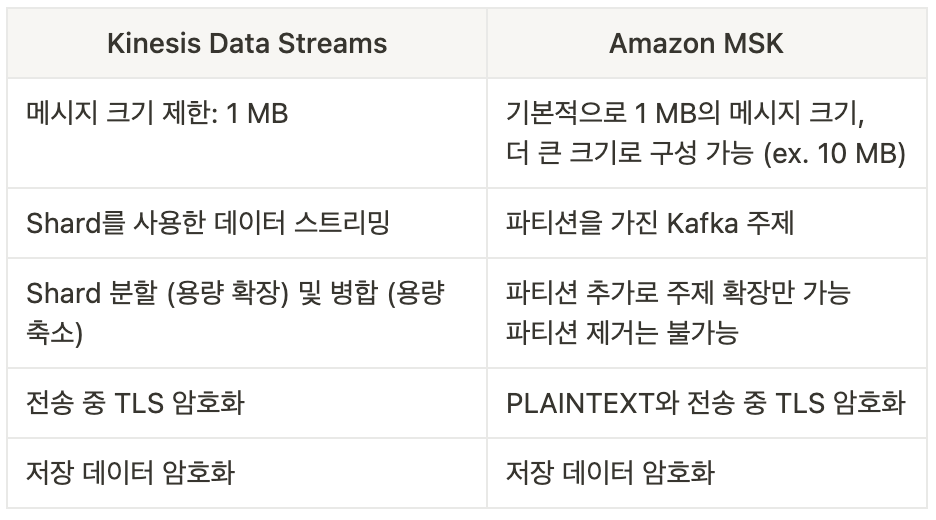
Kinesis Data Streams vs. Amazon MSK
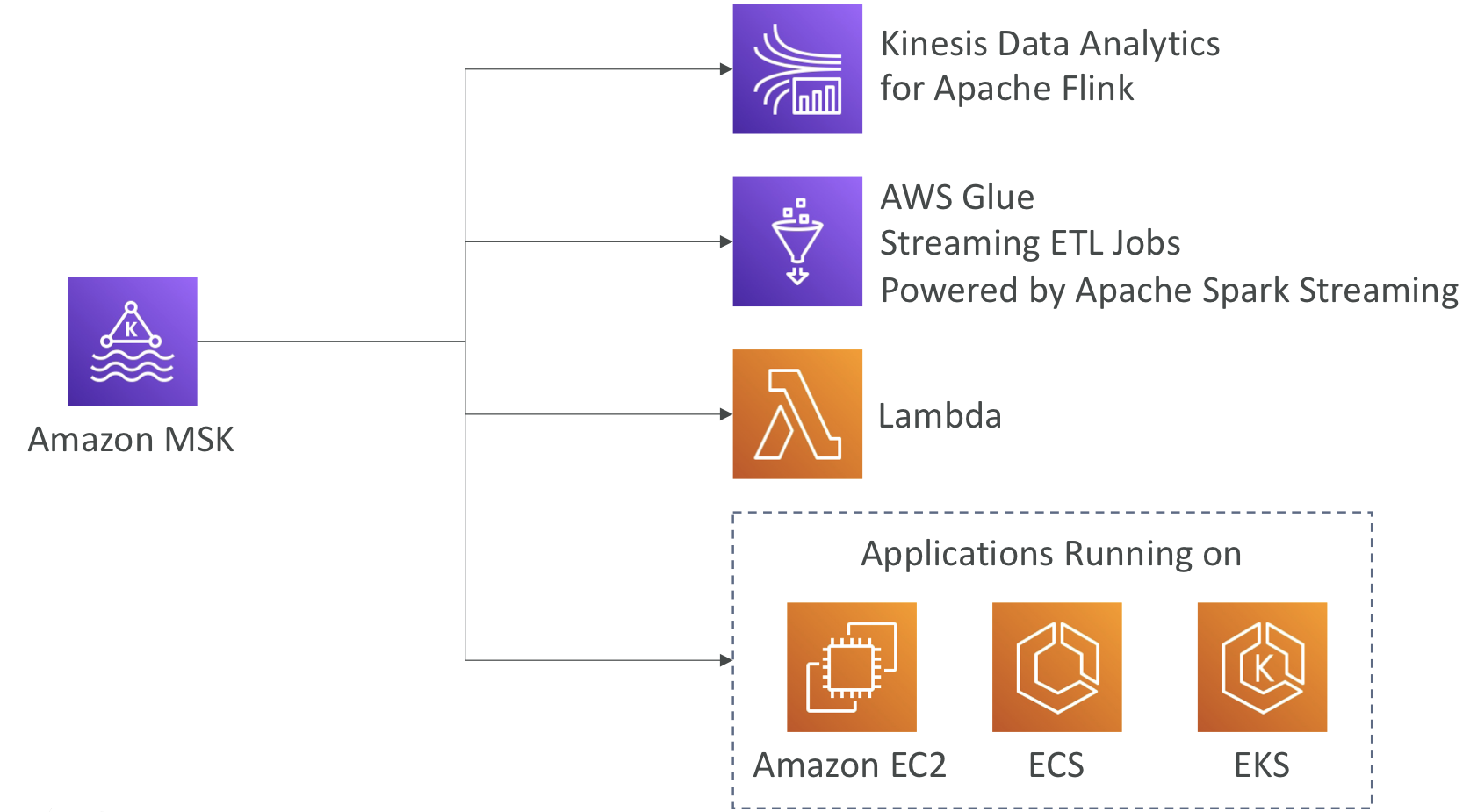
Amazon MSK Consumers
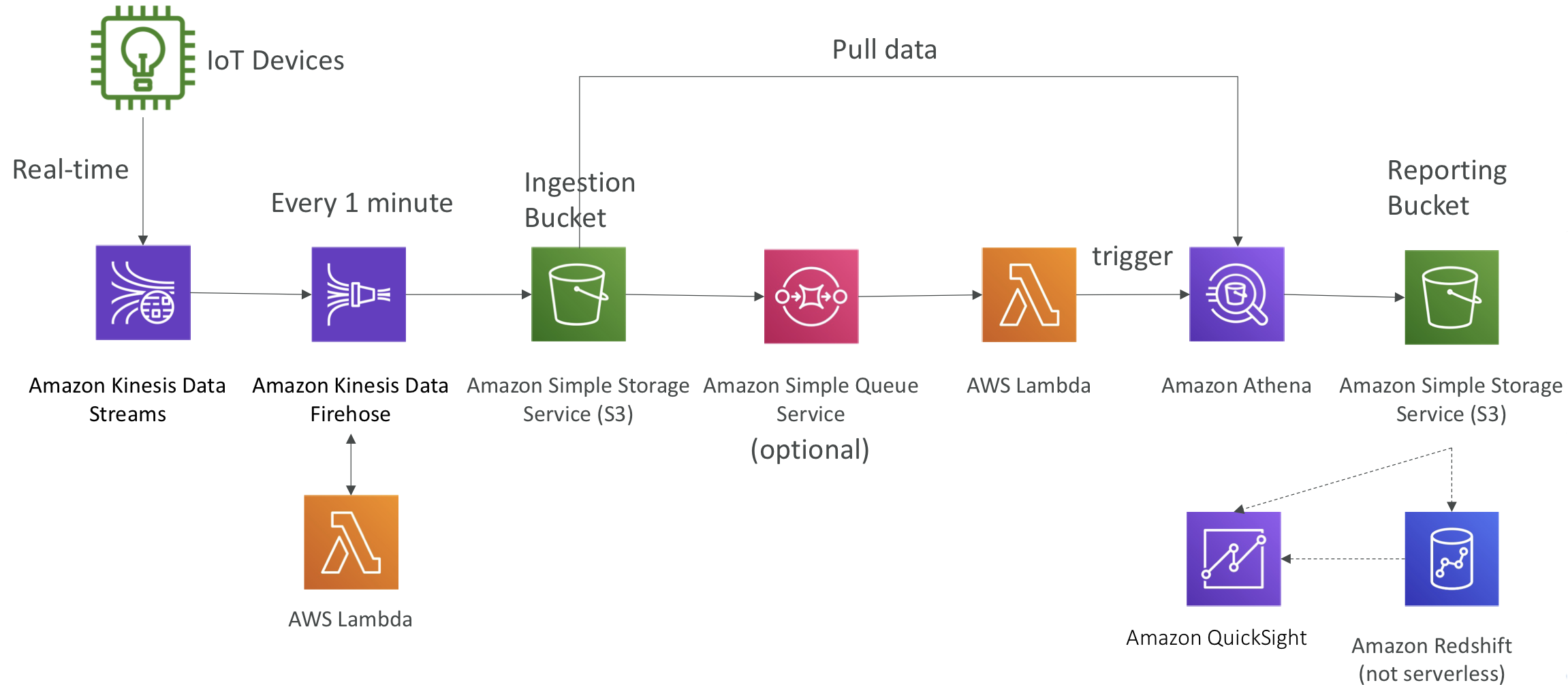
Big Data Ingestion Pipeline
완전한 서버리스 방식의 대규모 데이터 수집 파이프라인을 구축하고 실시간 데이터 수집, 데이터 변환, SQL 쿼리, 보고서 생성을 수행하며, 생성된 보고서는 S3에 저장하고 데이터 웨어하우스로 로드하여 대시보드를 생성하고자 한다.
대체로 수집이나 회수, 변형, 혹은 쿼리 및 분석 과정에서 흔히 발생하는 빅데이터 문제는 어떻게 처리하면 좋을까?
- IoT Core를 사용하면 IoT 장치에서 데이터를 수집할 수 있다.
- Kinesis는 실시간 데이터 수집에 효과적이다.
- Firehose는 데이터를 거의 실시간으로 S3로 전달하는 데 도움이 된다. (선택 가능한 최저 간격: 1분)
- Lambda는 Firehose를 도와 데이터를 변형한다.
- Amazon S3는 SQS로 알림을 트리거한다.
- Lambda는 SQS에 구독할 수 있다. (위의 예에서는 S3를 Lambda에 연결할 수 있었다).
- Athena는 서버리스 SQL 서비스이며 결과는 S3에 저장된다.
- 보고 버킷에는 분석된 데이터가 포함되어 있으며 AWS QuickSight, Redshift 등의 보고 도구에서 사용할 수 있다.

안녕하세요