
탐색
주어진 데이터에서 자신이 원하는 데이터를 찾아내는 알고리즘
주어진 데이터의 성질(정렬 데이터 또는 비정렬 데이터)에 따라 적절한 탐색 알고리즘을 선택하는 것이 중요하다.
그래프
사전 지식으로 그래프에 대해 알아보자
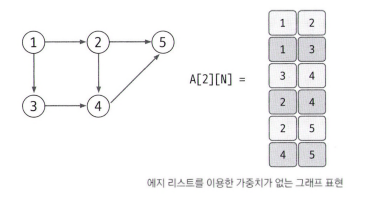
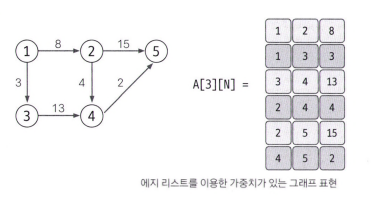
에지 리스트
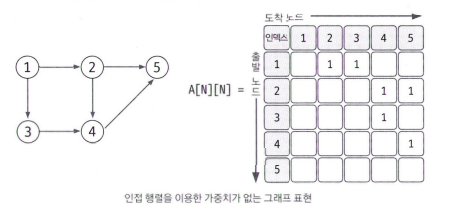
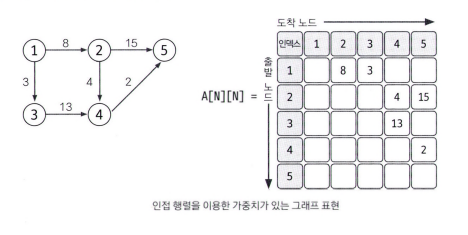
인접 행렬
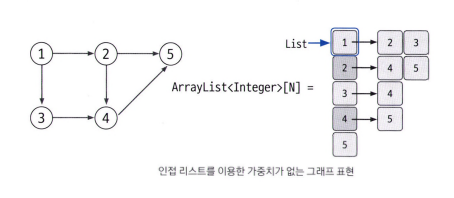
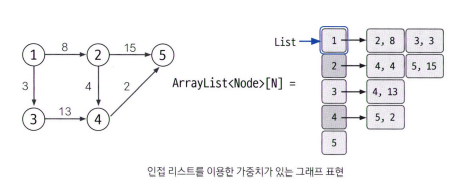
인접 리스트
깊이 우선 탐색(DFS, depth-first search)
그래프 완전 탐색 기법 중 하나
그래프의 시작 노드에서 출발하여 탐색할 한 쪽 분기를 정하여 최대 깊이까지 탐색을 마친 후 다른 쪽 분기로 이동하여 다시 탐색을 수행하는 알고리즘

재귀 함수를 이용하므로 스택 오버플로(stack overflow)에 유의해야
응용하여 풀 수 있는 문제 : 단절점 찾기, 단절선 찾기, 사이클 찾기 , 위상 정렬 등
깊이 우선 탐색의 핵심 이론
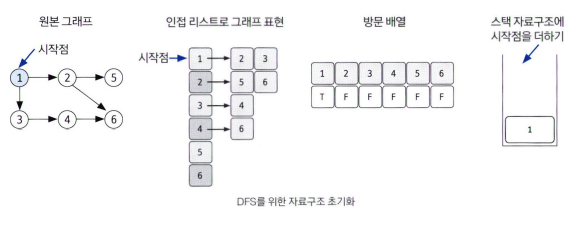
DFS는 한 번 방문한 노드를 다시 방문하면 안 되므로 노드 방문 여부를 체크할 배열이 필요하며, 그래프는 인접 리스트로 표현하겠다. 그리고 DFS의 탐색 방식은 후입선출 특성을 가지므로 스택을 사용하여 설명하겠다(편의를 위해 스택을 사용. DFS 구현은 스택보다는 스택 성질을 갖는 재귀 함수로 많이 구현함).
-
DFS를 시작할 노드를 정한 후 사용할 자료구조 초기화
-
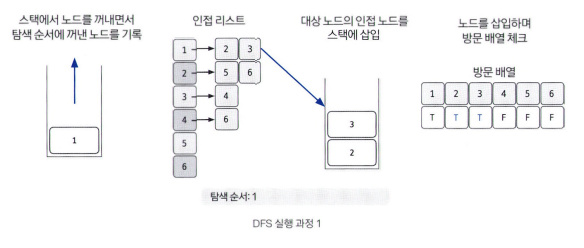
스택에서 노드를 꺼낸 후 꺼낸 노드의 인접 노드를 다시 스택에 삽입
-
스택 자료구조에 값이 없을 때까지 반복
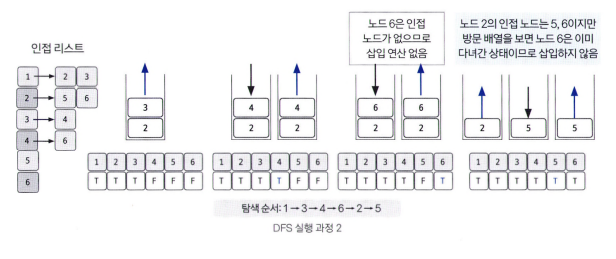
스택에 노드를 삽입할 때 방문 배열을 체크하고, 스택에서 노드를 뺄 때 탐색 순서에 기록하며 인접 노드를 방문 배열과 대조하여 살펴본다.
예제
너비 우선 탐색 (BFS, breadth-first search)
시작 노드에서 출발해 시작 노드를 기준으로 가까운 노드를 먼저 방문하면서 탐색하는 알고리즘

너비 우선 탐색은 선입선출 방식으로 탐색하므로 큐를 이용해 구현한다. 또한 너비 우선 탐색은 탐색 시작 노드와 가까운 노드를 우선하여 탐색하므로 목표 노드에 도착하는 경로가 여러개 일 때 최단 경로를 보장한다.
너비 우선 탐색의 핵심 이론
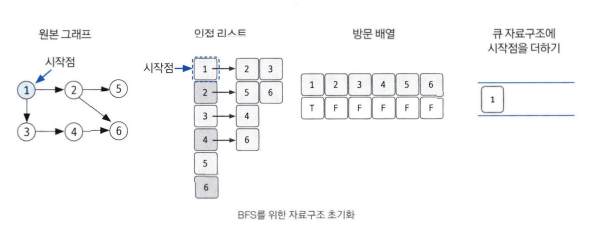
- BFS를 시작할 노드를 정한 후 사용할 자료구조 초기화하기
- 큐에서 노드를 꺼낸 후 꺼낸 노드의 인접 노드를 다시 큐에 삽입하기
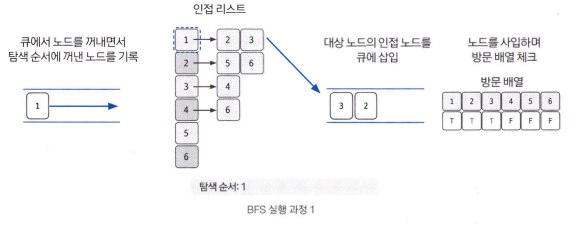
- 큐 자료구조에 값이 없을 때까지 반복하기
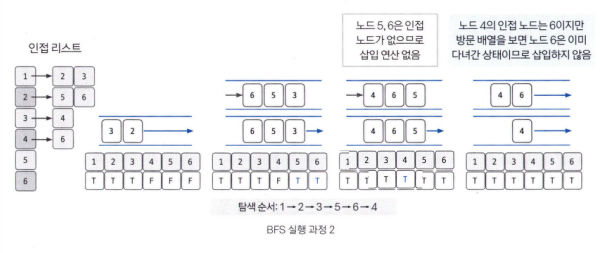
예제
이진 탐색(binary search)
데이터가 정렬돼 있는 상태에서 원하는 값을 찾아내는 알고리즘
대상 데이터의 중앙값과 찾고자 하는 값을 비교해 데이터의 크기를 절반씩 줄이면서 대상을 찾는다.

이진 탐색은 정렬 데이터에서 원하는 데이터를 탐색할 때 사용하는 가장 일반적인 알고리즘이다.
log(N)번의 연산
이진 탐색의 핵심 이론
이진 탐색은 오름차순으로 정렬된 데이터에서 다음 4가지 과정을 반복한다.
1. 현재 데이터셋의 중앙값(median)을 선택한다.
2. 중앙값 〉타깃 데이터(targetdata)일 때 중앙값 기준으로 왼쪽 데이터셋을 선택한다.
3. 중앙값 < 타깃 데이터일 때 중앙값 기준으로 오른쪽 데이터셋을 선택한다.
4. 과정 1~3을 반복하다가 중앙값 == 타깃 데이터일 때 탐색을 종료한다.