파이토치로 시작하는 딥러닝 기초 (부스트코스) - Lab-02 Linear regression
- 입력은 x_train, 출력은 y_train
- W는 Weight, b는 bias
우리가 하고 싶은 건 y = Wx + b
W와 b는 항상 0으로 초기화함 - requires_grad = True
학습할 것임을 명시함
import torch
from torch import optim
x_train = torch.FloatTensor([1], [2], [3])
y_train = torch.FloatTensor([2], [4], [6])
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
optimizer = optim.SGD([W, b], lr=0.01) #[W, b]는 학습할 tensor들, lr은 learning rate
nb_epochs = 1000
for epoch in range(1, nb_epochs + 1):
hypothesis = x_train * W + b
cost = torch.mean((hypothesis - y_train) ** 2)
# 이 3줄은 항상 붙어다님
optimizer.zero_grad() # gradient 초기화
cost.backward() # gradient 계산
optimizer.step() # 개선Mean Squared Error (MSE)
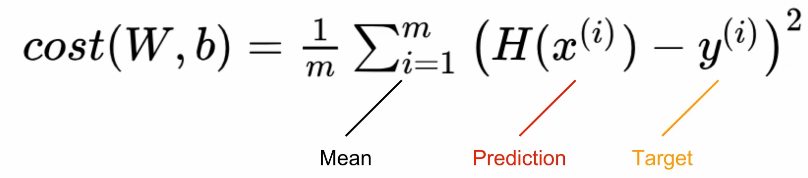
이는 torch.mean 함수를 이용하여
한 줄로 쉽게 구할 수 있음
