파이토치로 시작하는 딥러닝 기초
1.Tensor Manipulation 1

기본 setting에서의 2D Tensor 크기 = (batch size, dim) Computer Vision에서의 3D Tensor 크기 = (batch size, width, height) 자연어 처리에서의 3D Tensor 크기 = (batch size, le
2.Tensor Manipulation 2
차원을 변형한다\-1을 넣으면이 차원이 몇인진 잘 모르겠고 알아서 차원 좀 넣어 줘 ㅎㅎ같은 의미View 함수를 사용한 것과 같은데, 자동으로 1인 차원을 없앰만약에 squeeze(dim=i)를 하면, i번째 dimension이 1인 경우에 squeeze해 준다.위의
3.Linear regression
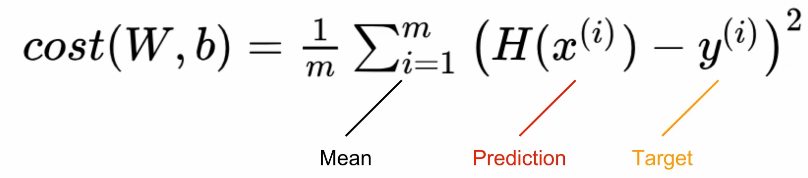
입력은 x_train, 출력은 y_trainW는 Weight, b는 bias우리가 하고 싶은 건 y = Wx + bW와 b는 항상 0으로 초기화함requires_grad = True학습할 것임을 명시함
4.Deeper Look at GD
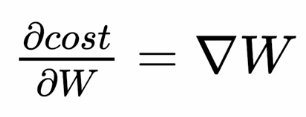
어떠한 모델이 주어졌을 때, 그 모델의 좋고 나쁨은 어떻게 평가할까?\-> cost function을 정의해서 평가cost function: 해당 모델이 실제 데이터와 얼마나 다른지를 나타냄잘 학습된 모델일수록 낮은 cost를 가짐선형 회귀에서의 cost functio
5.Multivariable Linear regression
선형 회귀에서, x가 여러 개인 경우 (다항 선형 회귀인 경우) 어떻게 해야 할까?=> matmul 이용!더 간결하고, x의 길이가 바뀌어도 코드를 바꿀 필요가 없으며, 속도도 빠름Cost 함수와 Gradient Descent 모두 동일nn.Module을 상속해서 모델
6.Loading Data
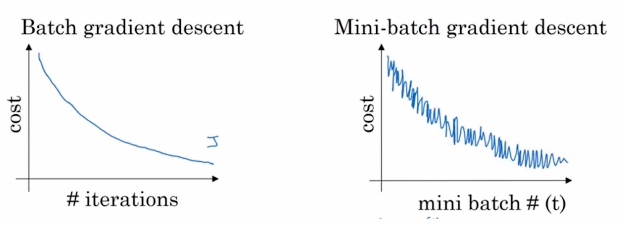
복잡한 머신러닝 모델을 학습하려면 엄청난 양의 데이터가 필요함그러나 이를 한 번에 학습시킬 순 없음. 너무 느리기도 하고, 하드웨어적으로도 불가능=> 일부분의 데이터로만 학습! 미니배치 (전체 데이터를 균일하게 나눠서 학습)Minibatch Gradient Descen
7.Logistic Regression
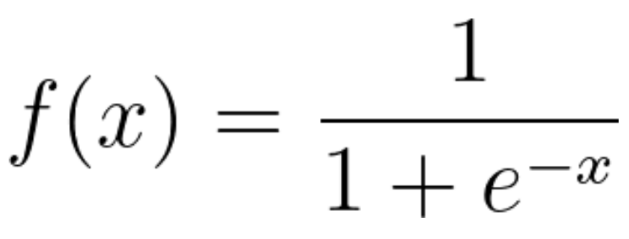
GitHub 주소로지스틱 회귀: 두 데이터 요인 간의 관계를 찾는 데이터 분석 기법예측값은 일반적으로 예(1) 또는 아니요(0)와 같은 유한한 수의 결과를 가짐로지스틱 회귀 함수는 -inf, inf의 값을 갖게 되는데이후 sigmoid 함수에 의해 -1, 1의 값을 갖
8.Softmax Classification
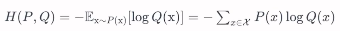
3개 이상의 선택지 중에서 1개를 고르는 다중 클래스 분류 문제이산적인 확률분포이며, 모든 확률을 다 더하면 1이 됨어쨌거나 확률이 가장 큰 값을 뽑아 낼 수가 있음실제 분포 P에 대해 알지 못하는 상태에서, 모델링을 통해 예측한 Q를 통하여 P를 예측실제값과 예측값이
9.Tips
깃허브Likelihood: 우리말로 하면 가능도 또는 우도이며, 확률의 반대 개념확률: 확률분포가 주어졌을 때, 해당 관측값이 나올 확률고정값은 확률분포가능도: 관측값이 주어졌을 때, 이 관측값이 어떤 확률분포로부터 나왔는지에 대한 확률고정값은 관측값 X최대 가능도 추
10.MNIST introduction
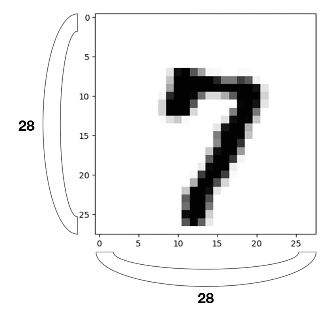
손으로 쓰여진 숫자 데이터우편물에 쓰여진 숫자를 자동으로 인식하고 싶어서 만들었다고 한다 (오... 신기)링크는 여기28x28, 1 channel gray 이미지따라서 입력으로 들어가는 X의 크기가 28x28=784파이토치에서는 view 함수를 이용하여 이미지를 784