s = sys.stdin.readline().strip()
n = len(s)
sa = [i for i in range(n)]
g = [0] * (n + 1) #순위
ng = [0] * (n + 1) #새로운 순위(순위를 갱신할 때 이용할 배열)
for i in range(n):
g[i] = ord(s[i])
g[n] = -1
ng[sa[0]] = 0
ng[n] = -1
t = 1
while t < n:
sa.sort(key=lambda x:(g[x], g[min(x + t, n)]))
for i in range(1, n):
p, q = sa[i - 1], sa[i]
if g[p] != g[q] or g[min(p + t, n)] != g[min(q + t, n)]:
ng[q] = ng[p] + 1
else:
ng[q] = ng[p]
if ng[n - 1] == n - 1:
break
t = t * 2
g = ng[:]
백준 9249 - 최장 공통 부분 문자열 를 몇일동안 잡고 있으면서 많은 것을 배웠지만 내가 모두 완벽히 이해했다고 말하기는 어려운 것 같아 그나마 이해한 suffix array만 따로 포스팅하게 되었다.
suffix array 만들기
백준 9248 - Suffix Array
위 문제에서 Suffix Array의 개념을 확인할 수 있는데 suffix array란 문자열의 모든 접미사들을 사전순으로 정렬한 배열을 뜻한다.
예를 들어 banana의 Suffix Array는 아래와 같다.

Suffix Array를 구하는 방법은 다음과 같다.
먼저 각 접미사 제일 앞글자를 기준으로 사전순으로 순서를 세운다.
이후 순서가 같은 접미사가 있다면 앞에서 2번째 글자, 4, 8, 16... 2만큼씩 곱한 글자만으로 순서를 다시 세워준다.
(왜 2씩 곱하는지는 뒤에서 설명하겠다.)
이를 모든 접미사의 순서가 달라질 때까지 진행한다.
ababba로 suffix array를 만드는 과정은 아래와 같다.
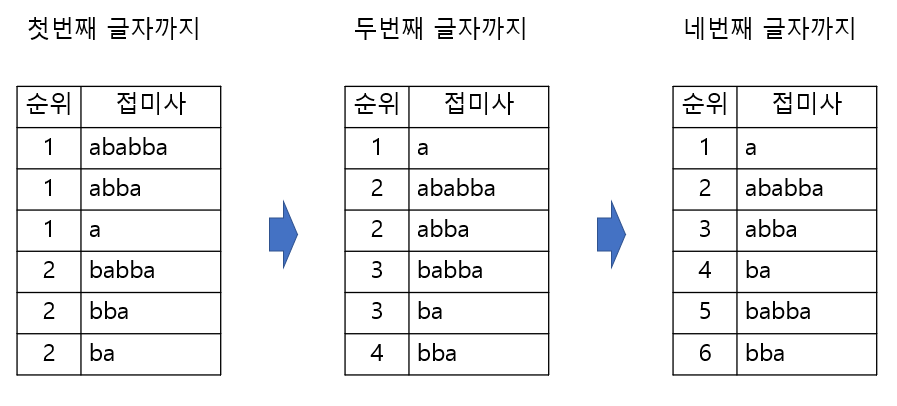
이때 정렬을 더 빠르게 할 수 있는 방법이 있다.
두번째 글자까지 정렬을 마쳤을 때 같은 순위에 있는 ababba와 abba를 예로 들어 보겠다.
ababba와 abba는 앞 두 글자가 ab로 같아 2순위에 속해있다.
ababba[2:] = abba, abba[2:] = ab
이때 각 접미사의 앞에서 세번째 글자부터 마지막 글자까지인 abba, ba도 접미사이기에 두번째 글자까지를 기준으로 순위가 부여되어있다는 점을 이용하면 바로 순위를 나눌 수 있다.
abba는 2순위, ba는 3순위에 속해있기에 ababba가 abba보다 빠른 순위여야 한다는 것을 바로 알 수 있다.
또한 이때 각 접미사가 네번째 글자까지 같다면 다음에도 같은 순위에 속한다는 것을 알 수 있다. (각 접미사의 두번째 글자까지만으로 정렬을 했기 때문에 -> 2+2 = 4) 따라서 세번째 글자까지를 기준으로 정렬을 할 필요가 없는 것이다. 이것이 2만큼씩 곱한 글자까지를 기준으로 정렬을 하는 이유이다.
이를 코드로 표현하면 다음과 같다.
for i in range(n):
g[i] = ord(s[i])
먼저 i번째 문자부터 시작하는 접미사들의 순위를 i번째(첫번째) 문자의 아스키코드로 설정한다.
while t < n:
sa.sort(key=lambda x:(g[x], g[min(x + t, n)]))1부터 시작한 t가 문자열의 길이보다 작은 동안 suffix array를 순위가 낮은 순서대로 정렬한다.
이때 순위가 같다면 x+t번째 접미사의 순위로 비교한다.
x + t가 문자열의 길이보다 커진다면 사전순으로 가장 빠르다고 할 수 있기에 가장 빠른 순위를 부여해야한다.
그래서 x + t가 문자열을 넘어갔을 때 g[n]을 반환하도록 하고 g[n]에는 가장 빠른 순위를 저장한다.
g[n] = -1
for i in range(1, n):
p, q = sa[i - 1], sa[i]
if g[p] != g[q] or g[min(p + t, n)] != g[min(q + t, n)]:
ng[q] = ng[p] + 1
else:
ng[q] = ng[p]
if ng[n - 1] == n - 1:
break
t = t * 2
g = ng[:]이제 순위를 갱신해주기 위해 suffix array를 순회하며 앞뒤로 각 접미사의 순위를 비교한다.
앞서 suffix array를 g(x), g(x + t)를 기준으로 정렬했기에 앞, 뒤 원소를 비교했을 때 순위가 같지 않다면 뒷 원소의 순위가 더 낮다는 것을 알 수 있다. 이 과정을 통해 ng에 새로운 순위를 저장한다.
이때 모든 원소당 하나의 순위가 빠짐없이 배정되었다면 while문을 나가주도록 한다.
if ng[n - 1] == n - 1: break
그렇지 않다면 t에 2만큼 곱해주고 순위를 새롭게 갱신해 다시 while문을 실행한다.
배운 것
- 입력값을 고려하지 않고 단순 시간복잡도만 보면 안된다.
suffix array를 구현할 때 지금처럼 시간복잡도 O(N log N)의 sort를 사용하는 방법과 O(N)의 시간복잡도를 갖는 counting sort를 이용한 방법이 있다.
당연히 시간복잡도는 작을 수록 좋다고 생각해 처음에는 counting sort로 구현을 했는데 시간초과가 나왔고, sort를 이용한 지금의 방식으로는 통과할 수 있었다.
왜 그런가 고민을 해보았는데 counting sort 방식에서는 N만큼 반복하는 for문을 적어도 5번 이상 돌려야했기에 반복횟수와 for문 내에서의 연산까지 고려해보면 N의 최댓값이 500000 이었던 이 케이스에 적절하지 않았던 것 같다.
-> 시간복잡도를 알았으면 이제 N에 어떤 값이 들어가는 지를 생각해보자.
