
!pip install opendatasets
import opendatasets as od
od.download('https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud','./')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_auc_score , plot_roc_curve, confusion_matrix
from sklearn.model_selection import KFold
import mlflow
import mlflow.sklearn실습에 필요한 라이브러리들 import 해줌
opendatasets 라이브러리를 통해 웹에서 바로 데이터 끌어다 쓸 수 있음
kaggle의 creditcardfraud 데이터 사용하여 실습 진행 (신용카드 이상 탐지 데이터셋)
*opendatasets로 kaggle 데이터 다운받기 위해서는 username 과 key가 필요함(즉 아이디가 필요함)
해당 실습에서는 scikit-learn 의 LogisticRegression 모델 사용
df = pd.read_csv('./creditcardfraud/creditcard.csv')
df
df.drop(columns='Time',inplace=True)
normal = df[df.Class ==0]
anomaly = df[df.Class==1]
print(normal.shape)
print(anomaly.shape)Time 변수는 모델에 긍정적인 영향을 끼치지 않는다고 판단했기 때문에 drop처리
정상데이터(class==0)를 normal, 이상데이터(class==1)를 anomaly로 선언
normal_train , normal_test = train_test_split(normal,test_size=0.2,random_state=2022)
anomaly_train , anomaly_test = train_test_split(anomaly,test_size=0.2,random_state=2022)
normal_train , normal_validate = train_test_split(normal_train,test_size=0.25,random_state=2022)
anomaly_train , anomaly_validate = train_test_split(anomaly_train,test_size=0.25,random_state=2022)normal 데이터, anomaly 데이터 각각 train,validate,test 데이터로 나누어준다 (비율은 6-2-2)
X_train=pd.concat([normal_train,anomaly_train])
X_test=pd.concat([normal_test,anomaly_test])
X_valiadate=pd.concat([normal_validate,anomaly_validate])
y_train=X_train.Class
y_test=X_test.Class
y_validate=X_valiadate.Class
X_train.drop(columns='Class',inplace=True)
X_test.drop(columns='Class',inplace=True)
X_valiadate.drop(columns='Class',inplace=True)normal 과 anomaly 로 나누어져 있는 데이터를 X 데이터로 합쳐준다 (train,validate,test 모두)
타겟변수(class)를 y데이터로 설정해준다.
scaler = StandardScaler()
scaler.fit(pd.concat([normal,anomaly]).drop(columns='Class'))
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
X_valiadate = scaler.transform(X_valiadate)StandardScaler를 이용하여 데이터 정규화 진행
def train(model,X_train,y_train):
## 학습 진행 함수 ##
model = model.fit(X_train,y_train)
train_acc = model.score(X_train,y_train)
mlflow.log_metric('train_acc',train_acc)
print('Train_accuracy',train_acc)모델 학습 함수 선언
mlflow.log_metric() 라인에서 mlflow 모듈 적용
mlflow가 train_acc 지표를 logging 하여 mlflow가 실행했을때 이 값을 추적하도록 함
def evaluate(model,X_test,y_test):
## 모델 검증 진행 함수##
eval_acc = model.score(X_test,y_test)
preds = model.predict(X_test)
auc_score = roc_auc_score(y_test,preds)
mlflow.log_metric("eval_acc",eval_acc)
mlflow.log_metric("auc_score",auc_score)
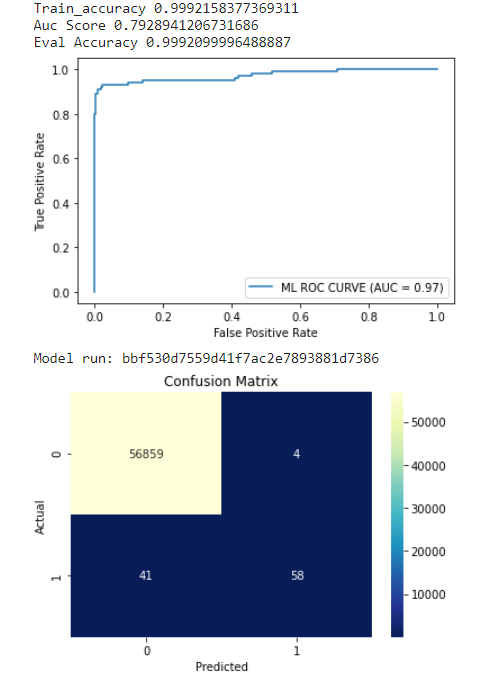
print('Auc Score',auc_score)
print('Eval Accuracy',eval_acc)
roc_plot = plot_roc_curve(model,X_test,y_test,name='ML ROC CURVE')
plt.savefig('model_roc_plot.png')
plt.show()
plt.clf()
conf_matrix = confusion_matrix(y_test,preds)
ax=sns.heatmap(conf_matrix,annot=True,fmt='g',cmap='YlGnBu_r')
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title("Confusion Matrix")
plt.savefig('model_conf_matrix.png')
mlflow.log_artifact('model_roc_plot.png')
mlflow.log_artifact('model_conf_matrix.png')모델 검증 함수 선언
train 함수와 같이 여기서도 mlflow.log_metric() 모듈을 통해 특정 지표를 logging하여 추적 가능하게 함, 또한 디렉터리에 저장된 파일을 mlfow.log_artifact() 모듈로 기록해 아티팩트로 관리함
*mlflow에서 아티팩트(artifact)란 그림파일,pkl파일,데이터 파일 등의 모든 형식의 파일을 일컫음
model = LogisticRegression(random_state=2022,max_iter=200,solver='lbfgs')
mlflow.set_experiment('model_experiment')
with mlflow.start_run():
train(model,X_train,y_train)
evaluate(model,X_test,y_test)
mlflow.sklearn.log_model(model,'log_reg_model')
print('Model run:',mlflow.active_run().info.run_uuid)
mlflow.end_run()LogisticRegression 모델을 선언한 후 mlflow.set_experiment()를 통해 mlflow실험 이름을 지정하고 실행을 준비한다
파이썬의 with 절을 통해 mlflow.start_run() 모듈이 실행됨에 따라 순차적으로 코드가 실행된다
다음 포스팅에서 진행할 것:
실험과 모델을 직접 볼 수 있는 MLFlow UI 접속하여 실습
*참고자료: MLFlow를 활용한 MLOps(Beginning MLOps with MLFlow: Deploy Models in AWS SageMaker, Google Cloud, and Microsoft Azure)
