nginx 문서를 보면 upstream module 에 여러 개의 server 가 있을 때 down 된 서버가 available 해지면 이걸 언제 어떻게 인지하는지 설명이 시원치 않다. 그래서 이왕 테스트하는김에 이것저것 문서대로 잘 작동하는지 확인해보기로 했다.
궁금증 1. 여러 개의 서버에 대해 load balancing 이 잘 되는가?
upstream backend {
server 127.0.0.1:43671;
server 127.0.0.1:43672;
}
server {
listen 43670;
server_name _;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_redirect off;
location / {
proxy_pass http://backend;
}
}요런 형태로 upstream 이 정의되어 있다고 하자. 일반적인 상황이라면 request 들은 server-43671 과 server-43672 로 round-robin 되어 proxy 될 것이다.
import asyncio
import datetime
import httpx
async def main() -> None:
cnt = 0
async with httpx.AsyncClient() as client:
while True:
cnt += 1
now = datetime.datetime.now().astimezone()
try:
r = await client.get(f'http://127.0.0.1:43670?cnt={cnt}')
if r.status_code != 200:
print(now, r.status_code)
except Exception:
print(now, "socket failure")
await asyncio.sleep(0.01)
asyncio.run(main())요런 python 스크립트를 통해 각 request 에 구분 가능한 query parameter 를 붙이고 확인해보자. HTTP status code 가 200이 아닌 response (e.g. 503) 을 받으면 출력하게 해두었다.
# 로드 밸런싱 서버 (server-lb)
exec docker run --rm -it --network host -v $(pwd)/nginx_lb.conf:/etc/nginx/nginx.conf nginx:alpine
# 업스트림 서버 1 (server-43671)
exec docker run --rm -it -p 43671:80 --stop-signal SIGQUIT nginx:alpine
# 업스트림 서버 2 (server-43672)
exec docker run --rm -it -p 43672:80 --stop-signal SIGQUIT nginx:alpine간단하게 실험하기 위해 docker 로 nginx 이미지를 실행시키고 역할을 지정해준다.
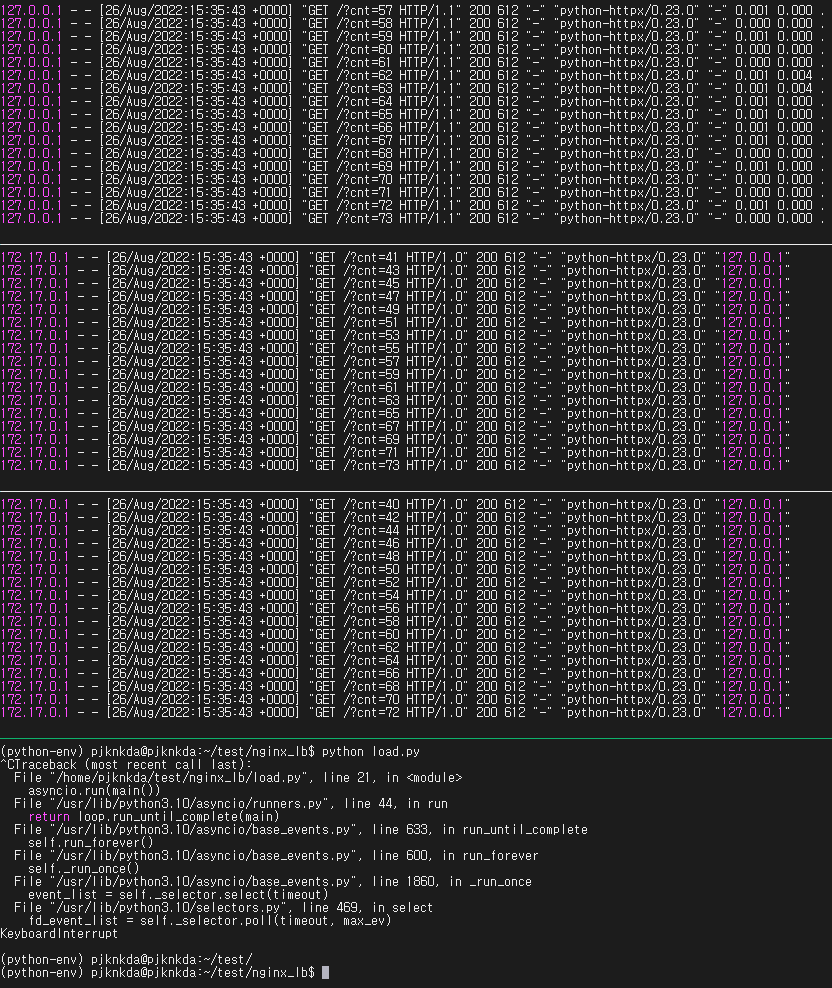
실험 결과, 예상대로 upstream server 로 request 가 round-robin 으로 잘 간다.
궁금증 2. 중간에 하나의 server 가 down 되면 어떻게 되는가?
모듈 upstream의 문서에 따르면, 특정 에러 상황에 대해 next upstream server 로 request 를 넘기는 기능이 있다. 기본적으로 (1) TCP connect 에 에러가 발생하거나, (2) proxy_connect_timeout 에 지정된 시간 동안 TCP connect 가 complete 되지 않으면 작동하며, L7 레벨에서 HTTP status code 를 기반으로도 작동하게 설정이 가능하다. 잘 될까?
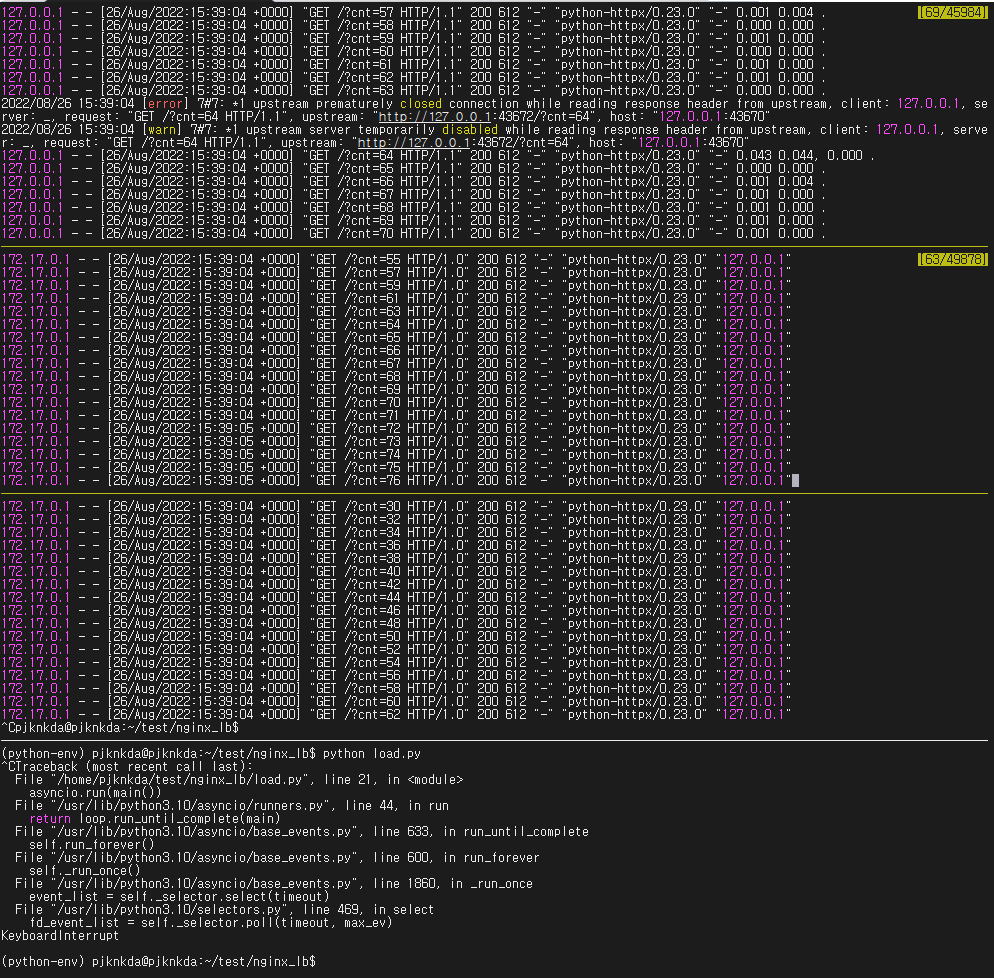
server-43672 에 중간에 SIGQUIT 을 줘서 graceful shutdown 하게 해보았다. 불안하게 server-lb 로그에 다음과 같은 로그가 눈에 띈다.
127.0.0.1 - - [26/Aug/2022:15:39:04 +0000] "GET /?cnt=63 HTTP/1.1" 200 612 "-" "python-httpx/0.23.0" "-" 0.000 0.000 .
2022/08/26 15:39:04 [error] 7#7: *1 upstream prematurely closed connection while reading response header from upstream, client: 127.0.0.1, server: _, request: "GET /?cnt=64 HTTP/1.1", upstream: "http://127.0.0.1:43672/?cnt=64", host: "127.0.0.1:43670"
2022/08/26 15:39:04 [warn] 7#7: *1 upstream server temporarily disabled while reading response header from upstream, client: 127.0.0.1, server: _, request: "GET /?cnt=64 HTTP/1.1", upstream: "http://127.0.0.1:43672/?cnt=64", host: "127.0.0.1:43670"
127.0.0.1 - - [26/Aug/2022:15:39:04 +0000] "GET /?cnt=64 HTTP/1.1" 200 612 "-" "python-httpx/0.23.0" "-" 0.043 0.044, 0.000 .그러나 결과를 보면,
server-lb로그를 보면, 64번째 request 에 대해 error & warn 로그가 발생했지만, 그 이후 로그를 보면 200 response 로그가 보인다.server-43671서버 로그에 64번째 request 가 들어온 로그가 보인다.- python script 에서는 non-200 response 를 받은 적이 없다.
따라서 정상적으로 upstream server 의 down 을 감지하고, client 에게는 투명하게 request 를 next upstream server 로 넘긴 것으로 보인다.
궁금증 3. server 의 부활을 언제 반영해주는가?
nginx 공식 문서에는 health check 에 대한 정보가 상당히 부실한 편이다. 로드밸런서로 자주 쓰이는 다른 오픈 소스 프로젝트인 haproxy 가 health check 에 대한 다양한 설정 을 지원하는 것이 비하면 아쉬운 편이다.
nginx 가 죽은 upstream server 를 매끄럽게 처리해주는건 확인했으니, 죽은 서버가 다시 부활했을 때 이걸 얼마나 빠르게 인식하는지를 테스트해보자.
우선, nginx 공식 문서를 살펴보면, upstream 모듈의 server 문법에서 fail_timeout 라는 설정값의 기본값이 10초라는 것을 볼 수 있다.
fail_timeout=time
sets
- the time during which the specified number of unsuccessful attempts to communicate with the server should happen to consider the server unavailable;
- and the period of time the server will be considered unavailable.
By default, the parameter is set to 10 seconds.해석해보면,
(1) fail_timeout 시간 동안 max_fails 번의 실패가 발생하면 서버가 unavailable 한 것으로 여겨진다.
(2) 그리고 fail_timeout 시간 동안 서버가 unavailable 한 것으로 여겨진다.
즉, upstream server 의 죽음을 결정하는 파라메터가 부활을 결정하는데에도 동일하게 사용되고 있다.
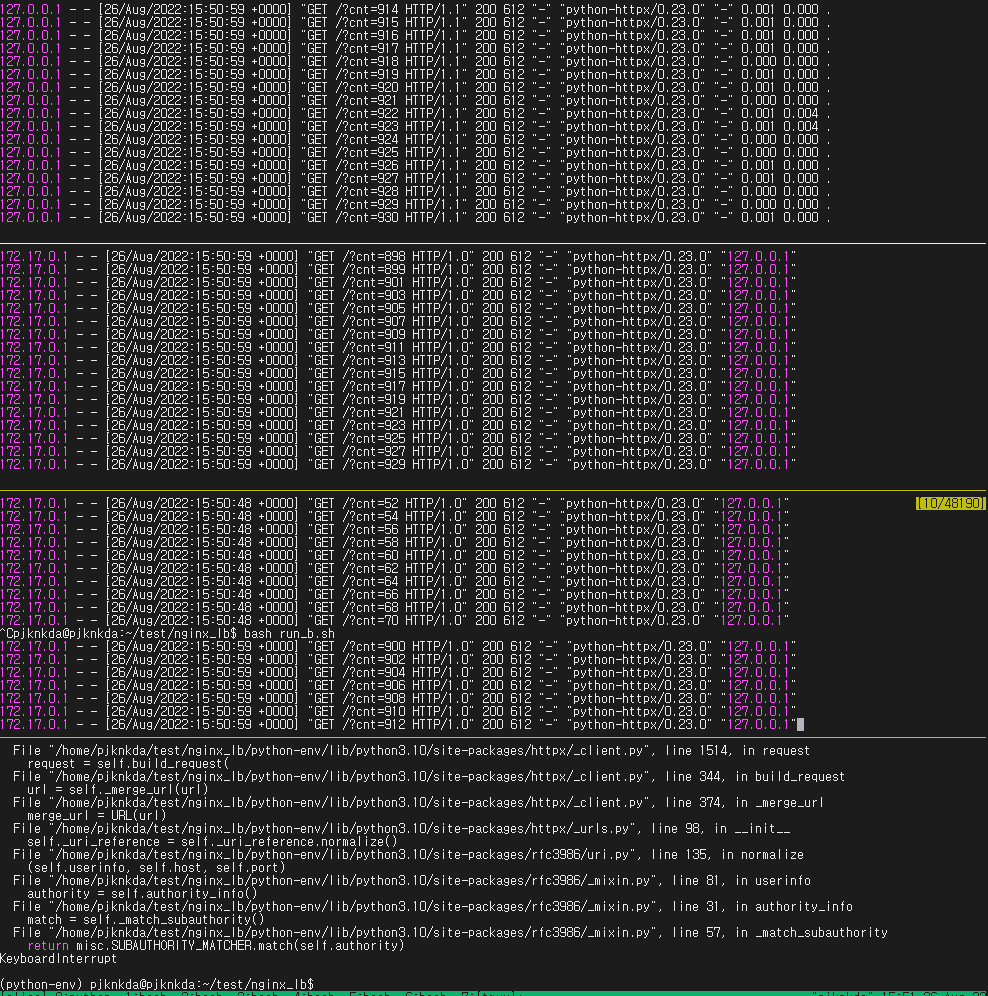
실험해보면, server-43672 를 종료한 후 곧바로 다시 실행했을 때, 약 10초가 지난 이후부터 다시 request 가 들어오기 시작한다. 문서의 설명과 일치하는 바이다.
만약 fail_timeout 의 값이 0 이 되면 어떻게 될까?
upstream backend {
server 127.0.0.1:43671 fail_timeout=0;
server 127.0.0.1:43672 fail_timeout=0;
}문서에 따르면, 서버는 죽은 이후 0초 동안 unavailable 한 것으로 여겨진다. 그렇다면, 둘 중 하나가 가능할 것 같다.
(예상-1) 매 request 마다 죽은 서버가 곧바로 다시 부활한 걸로 인식하고, 해당 서버가 TCP connect 가 안 되니 "궁금증 2" 실험에서 발생한 에러 로그가 계속 발생하거나
(예상-2) 성공하는 request 가 나올 때 까지는 계속 unavailable 한 것으로 여겨지거나
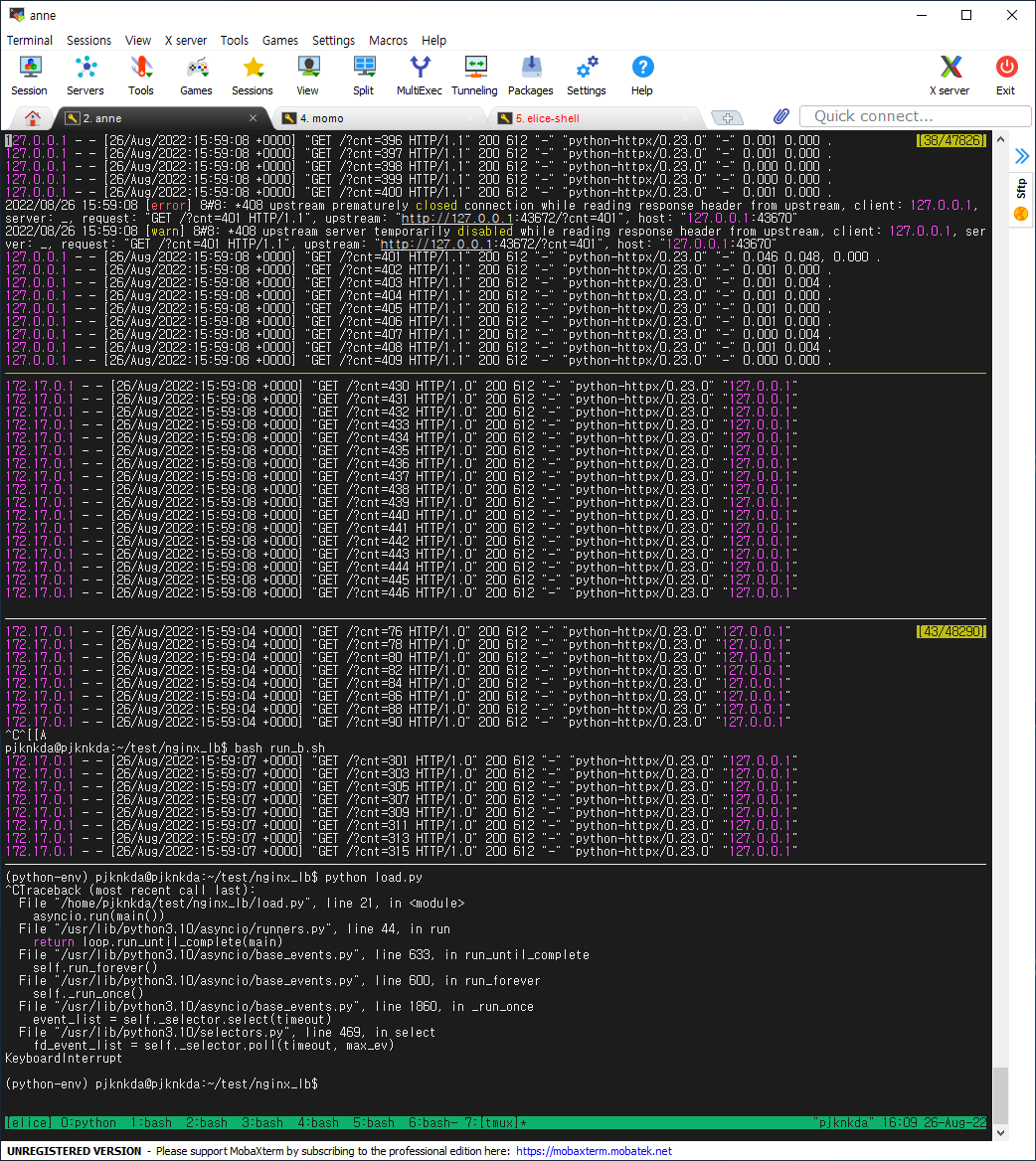
실험 결과, (예상-2)의 방식으로 작동한다. 즉 로직이 다음과 같다.
(1) request 가 들어옴
(2) up server, 또는 `fail_timeout` 이 지난 down server 로 TCP connect
(3-A) TCP connect 성공 to up-server => good
(3-B) TCP connect 성공 to down-server => server is now up
(3-C) TCP connect 실패 to down-server => try next server
(3-D) TCP connect 실패 to up-server && 많은에러* 이전 => try next srever
(3-E) TCP connect 실패 to up-server && 많은에러* 이후 => server is now down and try next srever
* 많은 에러 기준 : 해당 server 에 `fail_timeout` 시간동안 `max_fails` 의 에러가 발생fail_timeout 을 0 으로 설정하면, round robin 에 의한 차례만 넘어가면 부활한 서버를 바로 인지할 수 있다. 다만, 서버가 부활하기까지 실제로 시간이 좀 걸리는 상황이라면, 매 번 try & catch error & try next server 상황으로 갈테고, 그러면 response latency 측면에서 손해가 있을 것 같으니 (특히, TCP 가 half-closed 상태거나 하면 proxy_connect_timeout 시간동안 쭉 기다릴 수도..?) 적절한 값을 사용하자.
결론, 역시 많은 사람들이 쓰는 프로그램인 만큼 매끄럽게 잘 되어있다.

upstream만 이용하는거라면 haproxy를 사용하는게 많이 나아보이군요