배경
자신만의 맛집 리스트를 공유할 수 있는 어플의 백엔드를 개발하고 있다.
데이터베이스는 MySQL을 사용했다.
지금부터 작성할 이야기는 검색 API의 성능 개선에 대한 고민을 기록할 것이다.
데이터베이스의 구조는 아래와 같으며, 한 멤버에 여러 가게 리스트들이 있고 가게 리스트 안에는 여러 가게가 등록된다.
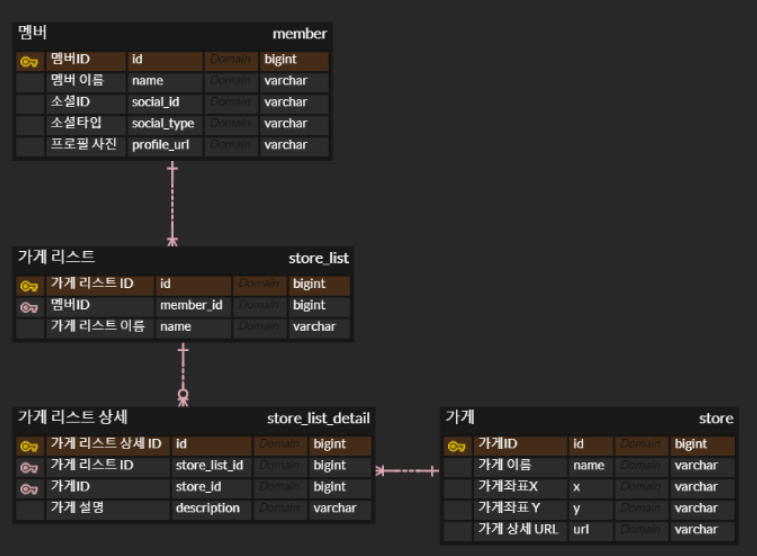
해당 어플의 검색 기능은 맛집 리스트 이름, 맛집 리스트의 주인 이름, 가게 이름, 맛집 리스트 설명 에서 키워드가 포함되어 있는 맛집 리스트들을 리턴해주는 기능이다.

처음에는 위와 같이 like를 이용해서 데이터베이스에서 해당 키워드를 검색했다.
http://localhost:8080/storelists/search?keyword=병준
위와 같은 요청을 보내면 아래와 같은 쿼리문이 나가게된다.
select
s1_0.id,
s1_0.member_id,
s1_0.name
from
store_list s1_0
join
store_list_detail s2_0
on s1_0.id=s2_0.store_list_id
join
store s4_0
on s4_0.id=s2_0.store_id
join
member m1_0
on m1_0.id=s1_0.member_id
where
s1_0.name like ?
or m1_0.name like ?
or s4_0.name like ?
or s2_0.description like ?결과는 아래와 같다.

인덱스 사용
검색 성능을 개선하기 위해 인덱스를 활용했다.
검색 쿼리문의 조건절로 사용되는 멤버 이름, 가게 이름, 맛집 리스트 이름, 맛집 리스트 상세 설명 열에 인덱스를 생성해줬다.

요청을 다시 보내보면 결과는 아래와 같다.

하지만 생각했던 것만큼 성능이 개선되지 않았다. 이를 자세히 확인해보기 위해 직접 MySQL에서 explain명령을 통해 실행 계획을 확인해보자.

실행 계획을 확인해봤을 때 인덱스를 사용하지 않는 다는 것을 확인할 수 있었다.
알아본 결과, like 이용시 like%와 같이 like연산자는 첫 번째 와일드카드가 등장하기 전까지의 문자열로만 스캔할 인덱스 범위를 결정하므로, 그 이후에 제공된 문자열은 겉보기와는 달리 인덱스를 간추리는 데 아무런 도움이 되지 않는다.
이를 해결하기 위해 MySQL의 Match ~ Against를 활용한 전문 검색(Full-Text Search)으로 변경할 것이다.
Match ~ Against를 활용한 전문 검색(Full-Text Search)
Full-Text Search는 단어 또는 구문에 대한 검색을 의미한다.
MATCH (col1,col2,...) AGAINST (expr [search_modifier]) 구문을 사용하여 수행된다.
MATCH는 쉼표로 구분되며 검색할 열을 지정하며,
AGAINST는 검색할 문자열과 수행할 검색 유형을 나타내는 search modifier를 사용한다.
ex) SELECT * FROM member WHERE MATCH(name) AGAINST('병준');
FULLTEXT INDEX
Full-text index는 MySQL에서 에서 FULLTEXT 타입의 인덱스이다.
예를 들어 Parser 중 ngram을 사용한다고 한다면, 아래와 같은 형식으로 생성할 수 있습니다.
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;
CREATE FULLTEXT INDEX ft_index ON articles (title,body) WITH PARSER ngram;Condition
Full-text 인덱스는 InnoDB나 MyISAM 엔진에서만 사용할 수 있으며,
CHAR, VARCHAR 혹은 TEXT 타입의 컬럼에서만 생성할 수 있다.
Parser
MySQL은 빌트인(내장) parser와 ngram parser를 지원하며, 중국어와 일본어 그리고 한글(CJK)를 지원한다.
또한, 일본어를 위한 플러그인 파서인 MeCab을 설치할 수도 있다.
ngram parser는 다음 글에서 더 자세히 알아보자.
Natural Language Searches
자연어 검색은 검색 문자열을 단어 단위(token_size)로 분리한 후, 해당 단어 중 하나라도 포함되는 행을 찾는다.
자연어 검색 기본 검색 타입으로,MATCH ... AGAINST 구문에 별도의 옵션을 지칭하지 않으면 자연어 검색 모드로 검색하게 된다.
혹은 아래와 같이 AGAINST에 명시적으로 표시할 수 있다.
SELECT * FROM member WHERE MATCH(name) AGAINST('병준' IN NATURAL LANGUAGE MODE);
매치율
입력된 검색어의 키워드가 얼마나 더 많이 포함되어 있는지에 따라 매치율(유사성 측정값)이 결정 되는데 전체 테이블의 50% 이상의 레코드가 검색된 키워드를 가지고 있다면, 검색어로서 의미가 없다고 판단하고 검색 결과에서 배제 시킨다.
위에서 설명하고 있는 50% 이상 관련된 내용은 MyISAM 에서의 제약사항으로 InnoDB 에서 search indexes 생성할 경우에는 이와 같은 제약사항은 없게 됩니다.
이 때 매치율이 계산될 때는row내의 고유 단어 수, 총 단어 수, 특정 단어를 포함하는 row 수 등을 기준으로 계산된다.
무시되는 검색어
길이가 기준보다 짧거나, 특정 단어(Stopword)는 풀텍스트 검색에서 무시한다.
단어의 기본 길이로 지정된 길이보다 짧을 경우 무시된다. 기본 길이는 아래의 명령어로 확인할 수 있다.
show variables like '%ft_min%';
Stopword는 a, the, some 과 같은 의미가 없는 단어들을 지정하여 무시한다.
built-in stopword가 있으며 아래의 명령어로 확인할 수 있다.
select * from INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;
Boolean Searches
불린 모드 검색은 문자열을 단어 단위로 분리한 후, 추가적인 검색 규칙을 적용되어서 단어가 포함되는 행을 찾는다.
아래와 같이 사용하며
SELECT * FROM member WHERE MATCH (name) AGAINST ('+박 -병준' IN BOOLEAN MODE);
위의 검색은 "박"은 추가하되, "병준"은 포함하지 않는 검색 규칙을 적용해서 검색하는 구문이다.
Full-text search 적용
MySQL 설정
my.cnf 설정에 아래 내용을 추가 또는 변경한다.
최소 인덱싱 글자수 설정
[mysqld]
ft_min_word_len = 2
innodb_ft_min_token_size = 2full-text index 생성

full-text 검색
자연어 모드로 할 경우, "케이크"를 검색하면 "스테이크"도 같이 나오는 문제가 발생하여 Boolean 모드를 선택했다.
select
s1_0.id,
s1_0.member_id,
s1_0.name
from store_list s1_0
join store_list_detail s2_0 on s1_0.id = s2_0.store_list_id
join store s4_0 on s4_0.id = s2_0.store_id
join member m1_0 on m1_0.id = s1_0.member_id
where match(s1_0.name) against('병준' in boolean mode)
or match(s2_0.description) against('병준' in boolean mode)
or match(s4_0.name) against('병준' in boolean mode)
or match(m1_0.name) against('병준' in boolean mode);처음에는 위와 같이 SQL문을 작성했었다. 하지만 Explain을 해보니 다음과 같이 인덱스를 사용하지 않는 것을 알 수 있었다.


이유를 생각해보면,
full-text index가 생성되면 MySQL은 해당 열 내에서 텍스트를 효율적으로 검색할 수 있는 특수 데이터 구조를 생성하는데, 이 구조는 한 번에 하나의 열을 검색하는 데 최적화되어 있다.
MATCH AGAINST 문을 OR 연산자와 함께 사용하여 여러 검색 조건을 결합하는 경우, MySQL은 각 조건을 개별적으로 평가한 다음 결과를 결합해야 하므로 느리고 비효율적일 수 있을 것 같다.
SELECT sl.id, sl.member_id, sl.name
FROM store_list sl
WHERE MATCH(sl.name) AGAINST('병준' in boolean mode)
UNION
SELECT sl.id, sl.member_id, sl.name
FROM store_list sl
WHERE sl.member_id IN (
SELECT m.id
FROM member m
WHERE MATCH(m.name) AGAINST('병준' in boolean mode)
)
UNION
SELECT sl.id, sl.member_id, sl.name
FROM store_list sl
WHERE sl.id IN (
SELECT sld.store_list_id
FROM store_list_detail sld
WHERE MATCH(sld.description) AGAINST('병준' in boolean mode)
UNION
select sld.store_list_id
FROM store_list_detail sld
JOIN store s ON s.id = sld.store_id
WHERE MATCH(s.name) AGAINST('병준' in boolean mode)
);그래서 위와 같이 별도의 MATCH AGAINST문을 사용한 후 조회하여 UNION으로 합쳤다.
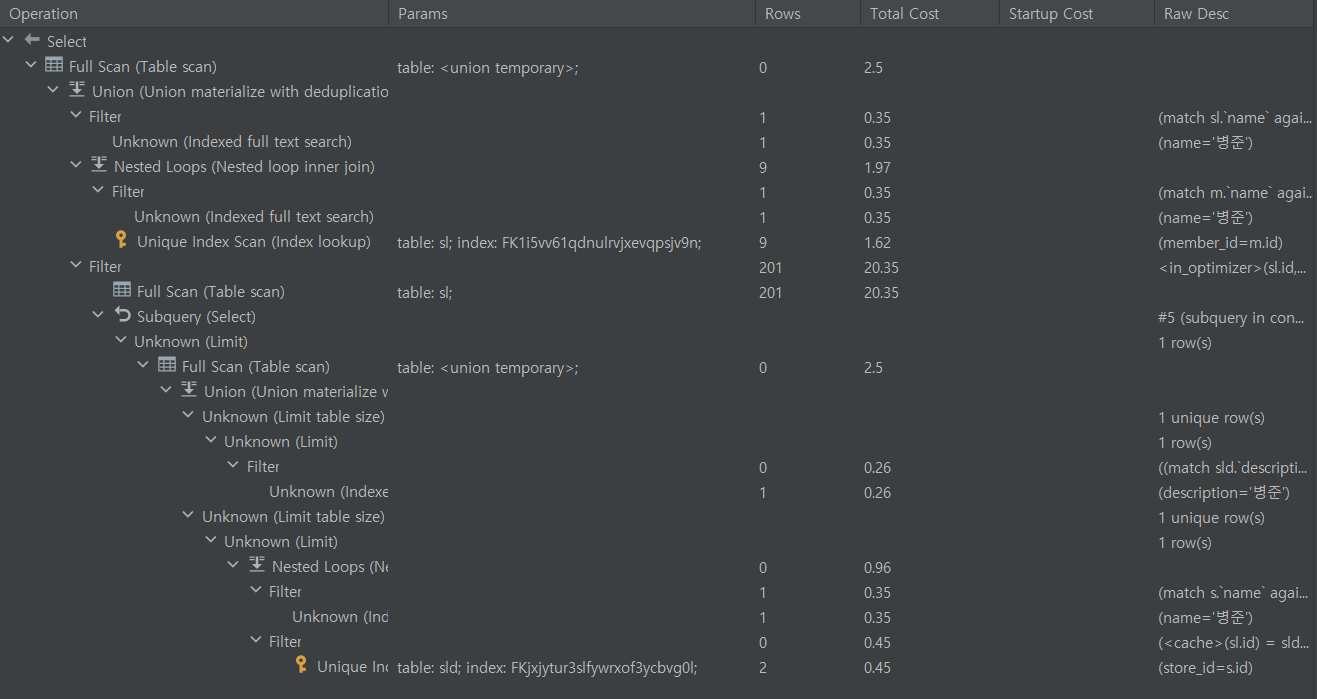

첫번째의 SQL문과 비교했을 때 꽤 복잡해졌지만 인덱스를 사용하고 조회하는 Row수와 Cost가 감소한 것을 확인할 수 있었다.
