
기존의 강의를 들었을 때처럼 모든 코드도 같이 작성할까 생각했지만 git에도 코드가 있고
내가 이 글을 작성하는 이유는 내가 모르는 지식을 습득하고 까먹지 않기 위해 기록함에 있기에
반복되는 코드를 제외하고 설계 부분과 궁금했던 내용, 내가 찾아본 내용을 정리하기로 했다
도메인 모델과 테이블 설계
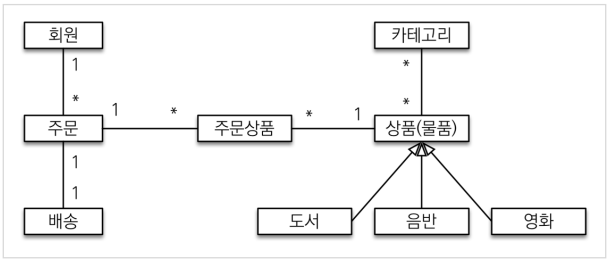
회원, 주문, 상품의 관계: 회원은 여러 상품을 주문할 수 있다. 그리고 한 번 주문할 때 여러 상품을 선택할 수 있으므로 주문과 상품은 다대다 관계다. 하지만 이런 다대다 관계는 관계형 데이터베이스는 물론이고 엔티티에서도 거의 사용하지 않는다. 따라서 그림처럼 주문상품이라는 엔티티를 추가해서 다대다 관계를 일대다, 다대일 관계로 풀어냈다.
상품 분류: 상품은 도서, 음반, 영화로 구분되는데 상품이라는 공통 속성을 사용하므로 상속 구조로 표현했다
회원 엔티티 분석
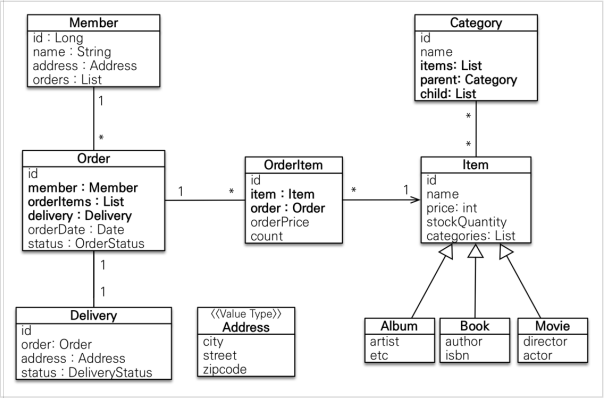
- 회원(Member): 이름과 임베디드 타입인 주소(Address), 그리고 주문(orders) 리스트를 가진다.
- 주문(Order): 한 번 주문시 여러 상품을 주문할 수 있으므로 주문과 주문상품(OrderItem)은 일대다
관계다. 주문은 상품을 주문한 회원과 배송 정보, 주문 날짜, 주문 상태(status)를 가지고 있다. 주문 상태는 열거형을 사용했는데 주문(ORDER), 취소( CANCEL )을 표현할 수 있다. - 주문상품(OrderItem): 주문한 상품 정보와 주문 금액(orderPrice), 주문 수량(count) 정보를 가지고 있다. (보통 OrderLine, LineItem 으로 많이 표현한다.)
- 상품(Item): 이름, 가격, 재고수량(stockQuantity)을 가지고 있다. 상품을 주문하면 재고수량이 줄어든다. 상품의 종류로는 도서, 음반, 영화가 있는데 각각은 사용하는 속성이 조금씩 다르다.
- 배송(Delivery): 주문시 하나의 배송 정보를 생성한다. 주문과 배송은 일대일 관계다.
- 카테고리(Category): 상품과 다대다 관계를 맺는다. parent , child 로 부모, 자식 카테고리를 연결한다.
- 주소(Address): 값 타입(임베디드 타입)이다. 회원과 배송(Delivery)에서 사용한다.4
참고: 회원이 주문을 하기 때문에, 회원이 주문리스트를 가지는 것은 얼핏 보면 잘 설계한 것 같지만, 객체 세상은 실제 세계와는 다르다. 실무에서는 회원이 주문을 참조하지 않고, 주문이 회원을 참조하는 것으로 충분하다. 여기서는 일대다, 다대일의 양방향 연관관계를 설명하기 위해서 추가했다.
회원 테이블 분석
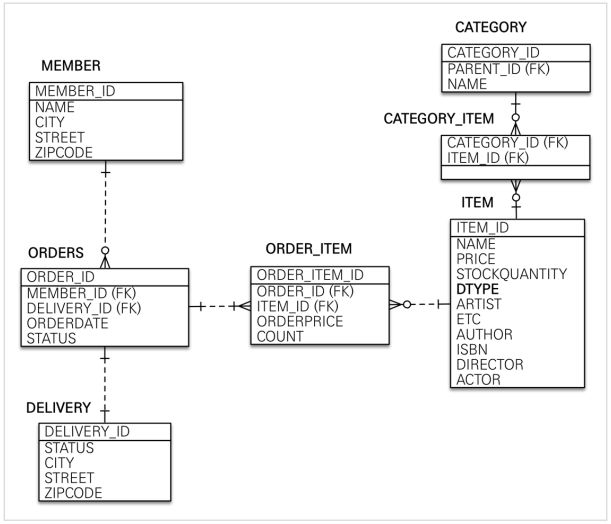
- MEMBER: 회원 엔티티의 Address 임베디드 타입 정보가 회원 테이블에 그대로 들어갔다. 이것은 DELIVERY 테이블도 마찬가지다.
- ITEM: 앨범, 도서, 영화 타입을 통합해서 하나의 테이블로 만들었다. DTYPE 컬럼으로 타입을 구분한다.
참고: 테이블명이 ORDER 가 아니라 ORDERS 인 것은 데이터베이스가 order by 때문에 예약어로 잡고 있는 경우가 많다. 그래서 관례상 ORDERS 를 많이 사용한다.
참고: 실제 코드에서는 DB에 소문자 + _(언더스코어) 스타일을 사용하겠다.
데이터베이스 테이블명, 컬럼명에 대한 관례는 회사마다 다르다. 보통은 대문자 + _(언더스코어)나 소문자 + _(언더스코어) 방식 중에 하나를 지정해서 일관성 있게 사용한다.
연관관계 매핑 분석
- 회원과 주문: 일대다, 다대일의 양방향 관계다. 따라서 연관관계의 주인을 정해야 하는데, 외래 키가 있는 주문을 연관관계의 주인으로 정하는 것이 좋다. 그러므로
Order.member를 ORDERS.MEMBER_ID 외래키와 매핑한다. - 주문상품과 주문: 다대일 양방향 관계다. 외래 키가 주문상품에 있으므로 주문상품이 연관관계의 주인이다. 그러므로
OrderItem.order를ORDER_ITEM.ORDER_ID외래 키와 매핑한다. - 주문상품과 상품: 다대일 단방향 관계다.
OrderItem.item을ORDER_ITEM.ITEM_ID외래 키와 매핑한다. - 주문과 배송: 일대일 양방향 관계다.
Order.delivery를ORDERS.DELIVERY_ID외래 키와 매핑한다. - 카테고리와 상품:
@ManyToMany를 사용해서 매핑한다.(실무에서 @ManyToMany는 사용하지 말자.- @ManyToMany 는 편리한 것 같지만, 중간 테이블( CATEGORY_ITEM )에 컬럼을 추가할 수 없고, 세밀하게 쿼리를 실행하기 어렵기 때문에 실무에서 사용하기에는 한계가 있다. 중간 엔티티( CategoryItem를 만들고 @ManyToOne, @OneToMany 로 매핑해서 사용하는게 좋다.
참고: 외래 키가 있는 곳을 연관관계의 주인으로 정해라.
연관관계의 주인은 단순히 외래 키를 누가 관리하냐의 문제이지 비즈니스상 우위에 있다고 주인으로 정하면 안된다.. 예를 들어서 자동차와 바퀴가 있으면, 일대다 관계에서 항상 다쪽에 외래 키가 있으므로 외래 키가 있는 바퀴를 연관관계의 주인으로 정하면 된다. 물론 자동차를 연관관계의 주인으로 정하는 것이 불가능 한 것은 아니지만, 자동차를 연관관계의 주인으로 정하면 자동차가 관리하지 않는 바퀴 테이블의 외래 키 값이 업데이트 되므로 관리와 유지보수가 어렵고, 추가적으로 별도의 업데이트 쿼리가 발생하는 성능 문제도 있다.
엔티티 설계시 주의점
1. 엔티티에는 가급적 Setter를 사용하지 말자
Setter가 모두 열려있다. 변경 포인트가 너무 많아서, 유지보수가 어렵다. 나중에 리펙토링으로 Setter 제거
Setter를 호출하면 데이터가 변한다.
Setter를 막 열어두면 가까운 미래에 엔티티에가 도대체 왜 변경되는지 추적하기 점점 힘들어진다.
그래서 엔티티를 변경할 때는 Setter 대신에 변경 지점이 명확하도록 변경을 위한 비즈니스 메서드를 별도로 제공해야 한다.
주소 값 타입
참고: 값 타입은 변경 불가능하게 설계해야 한다.
@Setter 를 제거하고, 생성자에서 값을 모두 초기화해서 변경 불가능한 클래스를 만들자. JPA 스펙상 엔티티나 임베디드 타입( @Embeddable )은 자바 기본 생성자(default constructor)를 public 또는 protected 로 설정해야 한다. public 으로 두는 것 보다는 protected 로 설정하는 것이 그나마 더 안전하다.
JPA가 이런 제약을 두는 이유는 JPA 구현 라이브러리가 객체를 생성할 때 리플랙션 같은 기술을 사용할 수 있도록 지원해야 하기 때문이
2. 모든 연관관계는 지연로딩으로 설정
즉시로딩( EAGER )은 예측이 어렵고, 어떤 SQL이 실행될지 추적하기 어렵다. 특히 JPQL을 실행할 때 N+1 문제가 자주 발생한다.
실무에서 모든 연관관계는 지연로딩( LAZY )으로 설정해야 한다.
연관된 엔티티를 함께 DB에서 조회해야 하면, fetch join 또는 엔티티 그래프 기능을 사용한다.
@XToOne(OneToOne, ManyToOne) 관계는 기본이 즉시로딩이므로 직접 지연로딩으로 설정해야
한다.
3. 컬렉션은 필드에서 초기화 하자.
컬렉션은 필드에서 바로 초기화 하는 것이 안전하다.
null 문제에서 안전하다.
하이버네이트는 엔티티를 영속화 할 때, 컬랙션을 감싸서 하이버네이트가 제공하는 내장 컬렉션으로 변경한다.
만약 getOrders() 처럼 임의의 메서드에서 컬력션을 잘못 생성하면 하이버네이트 내부 메커니즘에 문제가 발생할 수 있다. 따라서 필드레벨에서 생성하는 것이 가장 안전하고, 코드도 간결하다.
테이블, 컬럼명 생성 전략
스프링 부트에서 하이버네이트 기본 매핑 전략을 변경해서 실제 테이블 필드명은 다름
하이버네이트 기존 구현: 엔티티의 필드명을 그대로 테이블의 컬럼명으로 사용
(SpringPhysicalNamingStrategy)
스프링 부트 신규 설정 (엔티티(필드) 테이블(컬럼))
1. 카멜 케이스 언더스코어(memberPoint -> memberpoint)
2. .(점) -> (언더스코어)
3. 대문자 -> 소문자
적용 2 단계
1. 논리명 생성: 명시적으로 컬럼, 테이블명을 직접 적지 않으면 ImplicitNamingStrategy 사용
spring.jpa.hibernate.naming.implicit-strategy : 테이블이나, 컬럼명을 명시하지 않을 때 논리명
적용,
2. 물리명 적용:
spring.jpa.hibernate.naming.physical-strategy : 모든 논리명에 적용됨, 실제 테이블에 적용(username usernm 등으로 회사 룰로 바꿀 수 있음)
애플리케이션 구현 준비
애플리케이션 아키텍쳐
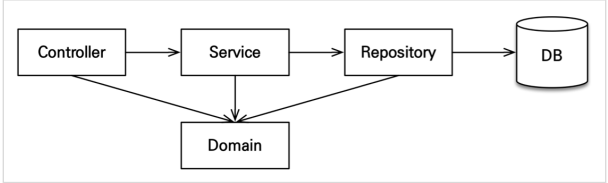
계층형 구조 사용
- controller, web: 웹 계층
- service: 비즈니스 로직, 트랜잭션 처리
repository: JPA를 직접 사용하는 계층, 엔티티 매니저 사용 - domain: 엔티티가 모여 있는 계층, 모든 계층에서 사용
실무에서는 검증 로직이 있어도 멀티 쓰레드 상황을 고려해서 회원 테이블의 회원명 컬럼에 유니크 제약 조건을 추가하는 것이 안전하다.
변경 감지와 병합(merge)
준영속 엔티티
영속성 컨텍스트가 더는 관리하지 않는 엔티티를 말한다.
(여기서는 itemService.saveItem(book) 에서 수정을 시도하는 Book 객체다. Book 객체는 이미 DB에 한번 저장되어서 식별자가 존재한다. 이렇게 임의로 만들어낸 엔티티도 기존 식별자를 가지고 있으면 준영속 엔티티로 볼 수 있다.)
준영속 엔티티를 수정하는 2가지 방법
-
변경 감지 기능 사용
- 영속성 컨텍스트에서 엔티티를 다시 조회한 후에 데이터를 수정하는 방법
- 트랜잭션 안에서 엔티티를 다시 조회, 변경할 값 선택 트랜잭션 커밋 시점에 변경 감지(Dirty Checking)이 동작해서 데이터베이스에 UPDATE SQL 실행
-
병합( merge ) 사용
- 준영속 상태의 엔티티를 영속 상태로 변경할 때 사용하는 기능
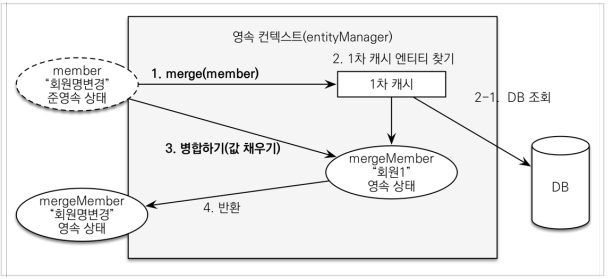
- 병합시 동작 방식을 간단히 정리
-1. 준영속 엔티티의 식별자 값으로 영속 엔티티를 조회한다.
-2. 영속 엔티티의 값을 준영속 엔티티의 값으로 모두 교체한다.(병합한다.)
-3. 트랜잭션 커밋 시점에 변경 감지 기능이 동작해서 데이터베이스에 UPDATE SQL이 실행
- 준영속 상태의 엔티티를 영속 상태로 변경할 때 사용하는 기능
주의: 변경 감지 기능을 사용하면 원하는 속성만 선택해서 변경할 수 있지만, 병합을 사용하면 모든 속성이 변경된다. 병합시 값이 없으면 null 로 업데이트 할 위험도 있다. (병합은 모든 필드를 교체한다.)
따라서 엔티티를 변경할 때는 항상 변경 감지를 사용하는게 좋다
지연 로딩과 조회 성능 최적화
엔티티를 DTO로 변환하거나, DTO로 바로 조회하는 두가지 방법은 각각 장단점이 있다. 둘중 상황에따라서 더 나은 방법을 선택하면 된다. 엔티티로 조회하면 리포지토리 재사용성도 좋고, 개발도 단순해진다.
권장하는 방법
1. 우선 엔티티를 DTO로 변환하는 방법을 선택한다.
2. 필요하면 페치 조인으로 성능을 최적화 한다. 대부분의 성능 이슈가 해결된다.
3. 그래도 안되면 DTO로 직접 조회하는 방법을 사용한다.
4. 최후의 방법은 JPA가 제공하는 네이티브 SQL이나 스프링 JDBC Template을 사용해서 SQL을 직접
사용한다
컬렉션 조회 최적화
V1. 엔티티 직접 노출
- 엔티티를 조회해서 그대로 반환
- 엔티티가 변하면 API 스펙이 변한다.
- 트랜잭션 안에서 지연 로딩 필요
- 양방향 연관관계 문제
V2. 엔티티를 조회해서 DTO로 변환(fetch join 사용X)
- 엔티티 조회 후 DTO로 변환
- 트랜잭션 안에서 지연 로딩 필요
- 지연 로딩으로 너무 많은 SQL 실행
- SQL 실행 수
- order 1번
- member , address N번(order 조회 수 만큼)
- orderItem N번(order 조회 수 만큼)
- item N번(orderItem 조회 수 만큼)
참고: 지연 로딩은 영속성 컨텍스트에 있으면 영속성 컨텍스트에 있는 엔티티를 사용하고 없으면 SQL을 실행한다. 따라서 같은 영속성 컨텍스트에서 이미 로딩한 회원 엔티티를 추가로 조회하면 SQL을 실행하지 않는다.
V3. 엔티티를 조회해서 DTO로 변환(fetch join 사용O)
- 페치 조인으로 쿼리 수 최적화
- 페치 조인으로 SQL이 1번만 실행됨
- distinct 를 사용한 이유는 1대다 조인이 있으므로 데이터베이스 row가 증가한다. 그 결과 같은 order 엔티티의 조회 수도 증가하게 된다.
- JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러준다. 이 예에서 order가 컬렉션 페치 조인 때문에 중복 조회 되는 것을 막아준다.
- 페이징 불가능
참고: 컬렉션 페치 조인을 사용하면 페이징이 불가능하다. 하이버네이트는 경고 로그를 남기면서 모든데이터를 DB에서 읽어오고, 메모리에서 페이징 해버린다(매우 위험하다).
주문 조회 V3.1: 엔티티를 DTO로 변환 - 페이징과 한계 돌파
-
페이징 가능
-
쿼리 호출 수가 1 + N 1 + 1 로 최적화 된다.
-
보다 DB 데이터 전송량이 최적화 된다. (Order와 OrderItem을 조인하면 Order가
OrderItem 만큼 중복해서 조회된다. 이 방법은 각각 조회하므로 전송해야할 중복 데이터가 없다.) -
조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 데이터 전송량이 감소한다.
-
방법
-
먼저 ToOne(OneToOne, ManyToOne) 관계를 모두 페치조인 한다.
ToOne 관계는 row수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다. -
컬렉션은 지연 로딩으로 조회한다.
-
지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size , @BatchSize 를 적용한다.
- hibernate.default_batch_fetch_size: 글로벌 설정
- @BatchSize: 개별 최적화
- 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
-
참고: default_batch_fetch_size 의 크기는 적당한 사이즈를 골라야 하는데, 100~1000 사이를 선택하는 것을 권장한다. 이 전략을 SQL IN 절을 사용하는데, 데이터베이스에 따라 IN 절 파라미터를 1000으로 제한하기도 한다.
1000으로 잡으면 한번에 1000개를 DB에서 애플리케이션에 불러오므로 DB 에 순간 부하가 증가할 수 있다. 하지만 애플리케이션은 100이든 1000이든 결국 전체 데이터를 로딩해야 하므로 메모리 사용량이 같다.
1000으로 설정하는 것이 성능상 가장 좋지만, 결국 DB든 애플리케이션이든 순간 부하를 어디까지 견딜 수 있는지로 결정하면 된다.
V4. JPA에서 DTO로 바로 조회, 컬렉션 N 조회 (1 + N Query)
- JPA에서 DTO를 직접 조회
- 단건 조회에서 많이 사용하는 방식
- 컬렉션은 별도로 조회
- Query: 루트 1번, 컬렉션 N 번 실행
- ToOne(N:1, 1:1) 관계들을 먼저 조회하고, ToMany(1:N) 관계는 각각 별도로 처리한다.
- 이런 방식을 선택한 이유는 다음과 같다.
- ToOne 관계는 조인해도 데이터 row 수가 증가하지 않는다.
- ToMany(1:N) 관계는 조인하면 row 수가 증가한다.
- row 수가 증가하지 않는 ToOne 관계는 조인으로 최적화 하기 쉬우므로 한번에 조회하고, ToMany 관계는 최적화 하기 어려우므로 findOrderItems() 같은 별도의 메서드로 조회한다
- 페이징 가능
V5. JPA에서 DTO로 바로 조회, 컬렉션 1 조회 최적화 버전 (1 + 1 Query)
- 컬렉션 조회 최적화
- 일대다 관계인 컬렉션은 IN 절을 활용해서 메모리에 미리 조회해서 최적화
- Query: 루트 1번, 컬렉션 1번
- 데이터를 한꺼번에 처리할 때 많이 사용하는 방식
- ToOne 관계들을 먼저 조회하고, 여기서 얻은 식별자 orderId로 ToMany 관계인
OrderItem 을 한꺼번에 조회 - MAP을 사용해서 매칭 성능 향상(O(1))
- 페이징 가능
V6. JPA에서 DTO로 바로 조회, 플랫 데이터(1Query) (1 Query)
- 플랫 데이터 최적화
- JOIN 결과를 그대로 조회 후 애플리케이션에서 원하는 모양으로 직접 변환
- Query: 1번
- 단점
- 쿼리는 한번이지만 조인으로 인해 DB에서 애플리케이션에 전달하는 데이터에 중복 데이터가
추가되므로 상황에 따라 V5 보다 더 느릴 수 도 있다. - 애플리케이션에서 추가 작업이 크다.
- 페이징 불가능
- 쿼리는 한번이지만 조인으로 인해 DB에서 애플리케이션에 전달하는 데이터에 중복 데이터가
권장 순서
1. 엔티티 조회 방식으로 우선 접근
1. 페치조인으로 쿼리 수를 최적화
2. 컬렉션 최적화
1. 페이징 필요 hibernate.default_batch_fetch_size , @BatchSize 로 최적화
2. 페이징 필요X 페치 조인 사용-
엔티티 조회 방식으로 해결이 안되면 DTO 조회 방식 사용
-
DTO 조회 방식으로 해결이 안되면 NativeSQL or 스프링 JdbcTemplate
참고: 엔티티 조회 방식은 페치 조인이나, hibernate.default_batch_fetch_size , @BatchSize 같이 코드를 거의 수정하지 않고, 옵션만 약간 변경해서, 다양한 성능 최적화를 시도할 수 있다.
반면에 DTO를 직접 조회하는 방식은 성능을 최적화 하거나 성능 최적화 방식을 변경할 때 많은 코드를 변경해야 한다.
참고: 개발자는 성능 최적화와 코드 복잡도 사이에서 줄타기를 해야 한다. 항상 그런 것은 아니지만, 보통 성능 최적화는 단순한 코드를 복잡한 코드로 몰고간다.
엔티티 조회 방식은 JPA가 많은 부분을 최적화 해주기 때문에, 단순한 코드를 유지하면서, 성능을 최적화 할 수 있다.
반면에 DTO 조회 방식은 SQL을 직접 다루는 것과 유사하기 때문에, 둘 사이에 줄타기를 해야 한다.
DTO 조회 방식의 선택지
DTO로 조회하는 방법도 각각 장단이 있다.
- V4
- 코드가 단순하다.
- 특정 주문 한건만 조회하면 이 방식을 사용해도 성능이 잘 나옴
- 예를 들어서 조회한 Order 데이터가 1건이면 OrderItem을 찾기 위한 쿼리도 1번만 실행하면 된다.
- V5
- 코드가 복잡하다.
- 여러 주문을 한꺼번에 조회하는 경우에는 V4 대신에 이것을 최적화한 V5 방식을 사용해야 한다.
- 예를 들어서 조회한 Order 데이터가 1000건 이면 , V4 방식은 쿼리가 총 1 + 1000번 실행
- V5 방식으로 최적화 하면 쿼리가 총 1 + 1번만 실행된다. 상황에 따라 다르겠지만 운영 환경에서 100배 이상의 성능 차이가 날 수 있다.
- V6
- 완전히 다른 접근방식이다.
- 쿼리 한번으로 최적화 되어서 상당히 좋아보이지만, Order를 기준으로
페이징이 불가능하다. 실무에서는 이정도 데이터면 수백이나, 수천건 단위로 페이징 처리가 꼭 필요하므로, 이 경우 선택하기 어려운 방법이다. - 데이터가 많으면 중복 전송이 증가해서 V5와 비교해서 성능 차이도 미비하다.
OSIV와 성능 최적화
- Open Session In View: 하이버네이트
- Open EntityManager In View: JPA
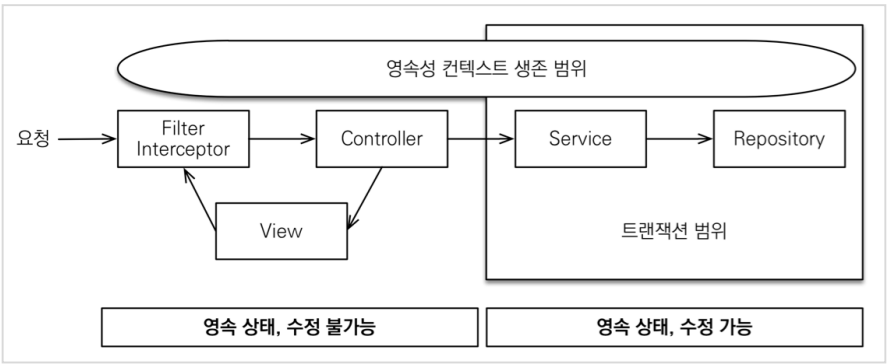
OSIV ON
-
spring.jpa.open-in-view : true 기본값
-
장점
- 트랜잭션 시작처럼 최초 데이터베이스 커넥션 시작 시점부터 API 응답이 끝날 때 까지 영속성 컨텍스트와 데이터베이스 커넥션을 유지한다.
- 그래서 지금까지 View Template이나 API 컨트롤러에서 지연 로딩이 가능했다.
- 지연 로딩은 영속성 컨텍스트가 살아있어야 가능하고, 영속성 컨텍스트는 기본적으로 데이터베이스 커넥션을 유지한다.
-
단점
- 이 전략은 너무 오랜시간동안 데이터베이스 커넥션 리소스를 사용하기 때문에, 실시간 트래픽이 중요한 애플리케이션에서는 커넥션이 모자랄 수 있다. 이것은 결국 장애로 이어진다.
OSIV OFF
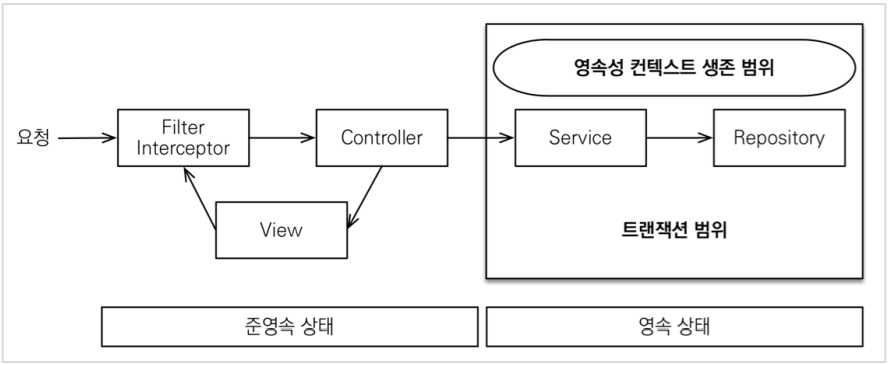
-
spring.jpa.open-in-view: false OSIV 종료
-
장점
- OSIV를 끄면 트랜잭션을 종료할 때 영속성 컨텍스트를 닫고, 데이터베이스 커넥션도 반환한다. 따라서 커넥션 리소스를 낭비하지 않는다.
- OSIV를 끄면 모든 지연로딩을 트랜잭션 안에서 처리해야 한다. 따라서 지금까지 작성한 많은 지연 로딩 코드를 트랜잭션 안으로 넣어야 하는 단점이 있다.
- view template에서 지연로딩이 동작하지 않는다. 결론적으로 트랜잭션이 끝나기 전에 지연 로딩을 강제로 호출해 두어야 한다.
커맨드와 쿼리 분리
실무에서 OSIV를 끈 상태로 복잡성을 관리하는 좋은 방법은 Command와 Query를 분리하는 것이다.
보통 비즈니스 로직은 특정 엔티티 몇 개를 등록하거나 수정하는 것이므로 성능이 크게 문제가 되지 않는다.
그런데 복잡한 화면을 출력하기 위한 쿼리는 화면에 맞추어 성능을 최적화 하는 것이 중요하다. 하지만 그 복잡성에 비해 핵심 비즈니스에 큰 영향을 주는 것은 아니다.
그래서 크고 복잡한 애플리케이션을 개발한다면, 이 둘의 관심사를 명확하게 분리하는 선택은 유지보수 관점에서 충분히 의미 있다.
예시로
- OrderService
- OrderService: 핵심 비즈니스 로직
- OrderQueryService: 화면이나 API에 맞춘 서비스 (주로 읽기 전용 트랜잭션 사용
보통 서비스 계층에서 트랜잭션을 유지한다. 두 서비스 모두 트랜잭션을 유지하면서 지연 로딩을 사용할 수 있다.
참고: 고객 서비스의 실시간 API는 OSIV를 끄고, ADMIN 처럼 커넥션을 많이 사용하지 않는 곳에서는 OSIV를 키는 것을 추천
노트
강의를 들으면서 내가 따로 찾아봤던 내용들을 간략하게 정리해봤다.
내용이 방대한 것은 추가적으로 따로 정리할 생각이다.
- @Entity: JPA를 사용해 테이블과 매핑할 클래스에 붙여주는 어노테이션
- 주의 사항
- 기본 생성자가 꼭 필요
- final, enum, interface, innter class에서는 사용 불가
- 필드(변수)를 final로 선언 불가
- 주의 사항
- Entity 설계 규칙
- 업무에 유용한 정보를 제공해야 함
- 명확한 속성 유형이 하나 이상 존재해야 함
- 각각의 인스턴스를 구분할 수 있어야 함
- 엔티티는 최소한 하나 이상의 다른 엔티티와 관계를 가져야함
- EntityManger
- 엔티티를 저장하고, 수정하고, 삭제하고 조회하는 등 엔티티와 관련된 모든 일을 처리한다. 또한 영속성 컨텍스트를 통해 데이터의 상태 변화를 감지하고 필요한 쿼리를 자동으로 수행
- Spring Data JPA에서는 EntityManager를 자동으로 Bean이 등록되기때문에 직접 사용하지는 않는다.
- 영속성 컨텍스트
- 엔티티를 영구 저장하는 환경이라는 뜻
- 엔티티 매니저(EntityManager)를 통해 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리
- JPQL
- 엔티티 객체를 조회하는 객체지향 쿼리다.
- SQL을 추상화 했기 때문에 특정 벤더에 종속적이지 않음
- JPA는 JPQL을 분석하여 SQL을 생성한 후 DB에서 조회
-
@Repository : 스프링 빈으로 등록, JPA 예외를 스프링 기반 예외로 예외 변환
-
@PersistenceContext : 엔티티 메니저( EntityManager ) 주입
-
@PersistenceUnit : 엔티티 메니터 팩토리( EntityManagerFactory ) 주입
-
@Service : 스프링 컴포넌트이며 기능적으로는 비즈니스 로직을 수행하는 서비스 레이어임을 알려주는 어노테이션
- @Transactional : 트랜잭션, 영속성 컨텍스트
- readOnly=true : 데이터의 변경이 없는 읽기 전용 메서드에 사용, 영속성 컨텍스트를 플러시 하지않으므로 약간의 성능 향상(읽기 전용에는 다 적용)
- 데이터베이스 드라이버가 지원하면 DB에서 성능 향상
- devtools
- Spring Boot에서 개발 편의를 위해 제공하는 라이브러리
- 기능
- Diagnosing Classloading Issues : 클래스 로딩 문제 진단
- Property Defaults: 속성 기본값
- Automatic Restart: 자동 재시작
- LiveRelad: 라이브 리로드
- Global Settings: 전역 설정
- Remote Applications: 원격 애플리케이션
- p6spy
- 쿼리 파라미터를 로그에 남겨주고 추가적인 기능을 제공하는 외부 라이브러리
- 사실 이 외부 라이브러리 없이도 application.yml에 다음과 같은 설정을 통해 쿼리 파라미터의 값들을 찍을 수 있다.
- 임베디드 타입
- 합 값 타입으로 불리며 새로운 값 타입을 직접 정의해서 사용하는 JPA의 방법을 의미
- 임베디드 타입을 사용하면 더욱더 객체지향적인 코드를 만들 수 있다.
@Embeddable: 값 타입을 정의하는 곳에 표시@Embedded: 값 타입을 사용하는 곳에 표시
- 상속관계 매핑 전략
- 객체의 상속관계를 관계형 데이터베이스의 슈퍼타입, 서브타입 관계를 매핑하는것
@Inheritance(strategy=InheritanceType.전략)- default 전략은 SINGLE_TABLE(단일테이블 전략)이다.
- SINGLE_TABLE: 단일 테이블에 한번에 모든 정보를 다 담는 전략
- JOINED: 각각의 테이블별로 정규화된 방법
- TTABLE_PER_CLASS: 엔티티 별로 각 테이블별로 분리하여 담는 전략
DiscriminatorColumn(name="DTYPE")- 하위 클래스에 선언하며, 슈퍼타입의 구분컬럼에 저장할 값을 지정하여 사용
- 어노테이션을 사용하지 않으면 기본값으로 클래스이름이 설정
@DiscriminatorValue("value")- 하위 클래스에 선언하며, 슈퍼타입의 구분컬럼에 저장할 값을 지정하여 사용한다
- 어노테이션을 사용하지 않으면 기본값으로 클래스이름이 설정된다.
- DAO(Data Access Object)
- 데이터베이스의 data에 접근하기 위한 객체
- DataBase에 접근 하기 위한 로직 & 비지니스 로직을 분리하기 위해 사용
- DAO의 경우는 DB와 연결할 Connection 까지 설정되어 있는 경우가 많다.
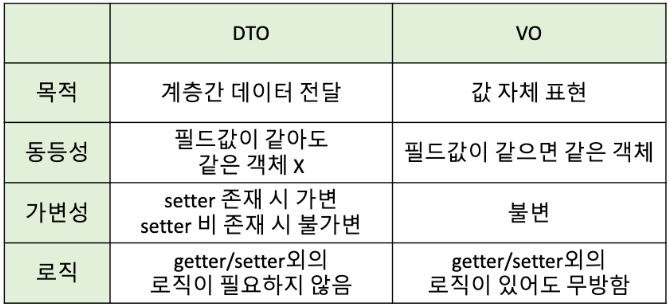
- VO(valueObject)
- 도메인에서 한 개 또는 그 이상의 속성들을 묶어서 특정 값을 나타내는 객체
- Immutability(불변성) - 수정자가(setter) 없다
- value equality(값 동등성) - 내부 값 동등성 검사
- self validation(자가 유효성 검사) - 생성자에서 validate
- DTO(Data Transfer object)
- 계층 간 데이터 교환을 하기 위해 사용하는 객체로, DTO는 로직을 가지지 않는 순수한 데이터 객체(getter & setter 만 가진 클래스)
- DB의 데이터가 Presentation Logic Tier로 넘어올때는 DTO로 변환되어 오고가는 것
- Controller Layer에서 Response DTO 형태로 Client에 전달
- 도메인 모델 패턴
- Domain 부분에서 비즈니스 로직을 가지고 객체 지향의 특성을 적극 활용
- 객체 지향에 기반한 재사용성,확장성, 그리고 유지 보수의 편리함
- 필요에 따라 약간의 수정이 필요하겠지만 언제든지 재사용할 수 있다.
- 하나의 도메인 모델을 구축하는데 많은 노력이 필요
- 객체를 판별하고 객체들 간의 관계를 정립 & 데이터베이스 사이의 매핑에 대한 고민
- 도메인 모델에 능숙한 개발자가 없을 경우 구축 자체가 힘들수도 있다.
- 트랜잭션 스크립트 패턴 (Transaction Script Pattern)
- 하나의 트랜잭션으로 구성된 로직을 단일 함수 또는 단일 스크립트에서 처리하는 구조
- 엔티티에는 비즈니스 로직이 거의 없고, 서비스 계층에서 대부분의 비즈니스를 처리하는 것
- 구현 방법의 단순함
- 높은 효율
- 비즈니스 로직이 복잡해질수록 난잡한 코드를 만들게 된다.
- 도메인에 대한 분석/설계 개념이 약하기 때문에 코드의 중복 발생을 막기 어려워진다.
@Enumerated(EnumType.ORDINAL): enum 순서 값을 DB에 저장@Enumerated(EnumType.STRING): enum 이름을 DB에 저장
@JoinTable- 조인테이블은 외래키를 사용 하는 연관 관계와는 다르게 조인테이블이라는 별도의 테이블을 만들어서 각 테이블의 외래키를 가지고 연관관계를 관리
- 속성
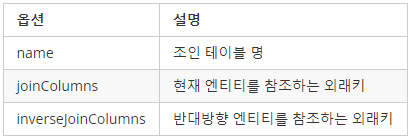
cascade = CascadeType.ALL- 모든 Cascade 를 적용
- N+1 문제
- 연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하는 문제
- 해결 방안은 위의 조회 방식 설명에서 서술
- 연관 관계 편의 메소드
- 하나의 메소드에서 양측에 관계를 설정하게 해주는 것
- 디비에 flush 되기전에 양방향으로 묶여있는 자료의 일관성을 지켜주기 위해 만든다.
- 무한루프에 빠지지않게 체크해주는 로직을 반드시 추가
@Transactional(readOnly = true)- 어노테이션으로 트랜잭션을 읽기 전용 모드로 설정할 수 있다.
- 예상치 못한 엔티티의 등록, 변경, 삭제를 예방할 수 있고 또한 성능을 최적화할 수 있다.
- 점점점(...) 문법
- varargs 또는 가변인자라고 하며 0개부터 n개 까지 매개변수로 올수있는걸 뜻함- 가변인자는 컴파일시 배열로 처리
mapToInt- 스트림을 IntStream으로 변환해주는 메서드
- IntStream을 제외한 모든 스트림에서 동일하게 제공하는 메서드
@valid- 빈 검증기(Bean Validator)를 이용해 객체의 제약 조건을 검증하도록 지시하는 어노테이션
- 검증 애노테이션 종류
- @NotBlack
- null이 아닌 값
- 공백이 아닌 문자를 하나 이상 포함해야한다.
- 반드시 값이 존재하고 공백 문자를 제외한 길이가 0보다 커야한다.
- @NotEmpty
- null 이거나 empty(빈 문자열)가 아니어야 한다.
- 반드시 값이 있어야하며 길이가 0보다 커야아한다.
- @NotNull
- null이 아닌 값은 어떤 타입이든 상관없다.
- 반드시 값이 있어야함
- @Null
- 타입은 상관없으며 null값 허용
BindingResult- 스프링이 제공하는 검증 오류를 보관하는 객체
- BindingResult bindingResult 파라미터의 위치는 항상 @ModelAttribute {객체} {변수} 다음에 와야 한다.
- 더티채킹
- 프레임워크에서 메모리의 엔터티에 대한 변경 사항을 추적하고 데이터베이스와 동기화하는 데 사용되는 기술
- 영속성 컨텍스트가 관리하는 엔티티에만 적용
- 트랜잭션이 끝나는 시점에 이 스냅샷과 비교해서 변경이 있으면 Update query를 발생
- @Data
- @Getter / @Setter, @ToString, @EqualsAndHashCode와 @RequiredArgsConstructor 를 합쳐놓은 종합 선물 세트
- POJO(Plain Old Java Objects)와 bean과 관련된 모든 보일러플레이트(boilerplate =재사용 가능한 코드)를 생성
- default_batch_fetch_size
- 복잡한 조회쿼리 작성시, 지연로딩으로 발생해야 하는 쿼리를 IN절로 한번에 모아보내는 기능
- 위의 코드를 사용하면 애플리케이션 전체에 기본으로
@BatchSize적용 한다
- @EqualsAndHashCode
- 자바 bean에서 동등성 비교를 위해 equals와 hashcode 메소드를 오버라이딩해서 사용하는데, @EqualsAndHashCode어노테이션을 사용하면 자동으로 이 메소드를 생성할 수 있다.
- callSuper 속성을 통해 eqauls와 hashCode 메소드 자동 생성 시 부모 클래스의 필드까지 감안할지의 여부를 설정할 수 있다.
