지도학습에서 모델을 얼마나 fitting시킬 것인지는 중요한 문제이다. 에러를 무조건 줄이는 것이 능사가 아니다. Overfitting, Underfitting 모두 피하고 적당한 fit을 시켜야 한다. 이것과 관련한 개념이 bias and variance인데 두개는 trade-off 관계가 있다.
이 개념이 이해하려고 블로그를 여러군데 다녔는데 정말 잘 정리되고 명확하게 설명해높은 블로그를 발견했다!
아래 내용은 참고한 Chris albon님의 글에서 가져온 내용이다. (아래에 링크 있음)
Bias
"Bias is the expected error created by using a model to approximate a real world function / relationship."
수식:
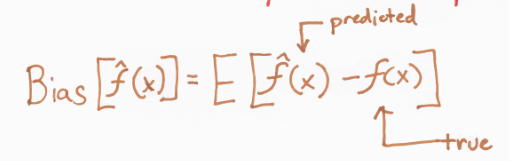
즉, bias는 모델을 통해 얻은 예측값과 실제 정답과의 차이의 평균이다. 즉, 예측값이 실제 정답값과 얼마나 떨어져 있는지 나타낸다. 만약 bias가 높다고 하면 그만큼 예측값과 정답값 간의 차이가 크다고 할 수 있다.
Variance
Variance is the amount out predicted values would change if we had a diffrent traing dataset.
수식:
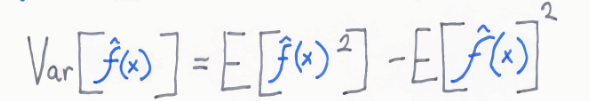
즉, variance는 다양한 데이터 셋에 대하여 예측값이 얼만큼 변화할 수 있는 지에 대한 양(Quantity)의 개념이다. 이는 모델이 얼만큼 flexibility를 가지는 지에 대한 의미로도 사용되며 분산의 본래 의미와 같이 얼만큼 예측값이 퍼져서 다양하게 출력될 수 있는 정도로 해석할 수 있습니다.
참고 글 출처:
https://gaussian37.github.io/machine-learning-concept-bias_and_variance/
