
Week 3 [P Stage. 이미지 분류]
Day 01
강의 복습 내용
[1. Competition with AI stages!]
Kaggle과 같은 competition을 시작할 때에는 Overview (개요)를 먼저 확인하는 것이 굉장히 중요하다! 개요를 확인하면 이 문제의 방향성을 정할 수 있다. 또한 개요를 통해 풀어야 할 문제가 무엇인지, Input과 Output이 무엇인지 그리고 솔루션이 어디서 어떻게 사용되는지를 고민하면서 문제 정의(Problem Definition)를 진행해야된다.
그 다음 단계로 Data Description(데이터 스펙 요약본)을 확인해야된다.
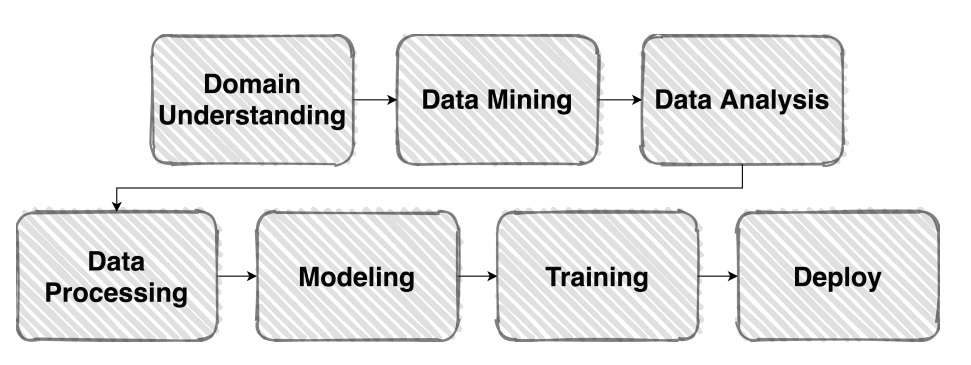
위 사진은 Machine Learning의 파이프라인이다. 문제를 이해하고, 데이터를 수집, 분석, 처리 과정을 거쳐 모델을 정해 학습을하는 과정이다. 반면 Competiton의 경우 Data Mining과 Deploy 과정이 빠진다.
[2. Image Classification & EDA]
EDA(Exploratory Data Analysis)란?
수집한 데이터를 다양한 각도에서 관찰하고 이해하는 과정, 데이터를 이해하기 위한 노력이다. 데이터를 분석하기 전에 그래프나 통계적인 방법으로 자료를 직관적으로 바라보는 과정이다.
피어세션 정리 및 학습 회고
피어세션을 진행하면서 프로젝트를 어떻게 진행할지에 대한 얘기를 나눴다. 데이터 라벨링, 클래스 불균형 등에 대해 얘기를 나눴으며 모델을 3개로 나눠 앙상블을 하면 괜찮을거 같다는 얘기를 했다.
Day 02
강의 복습 내용
[3. Dataset]
Dataset 작업은 주어진 Vanilla Data를 모델이 좋아하는 형태의 Dataset으로 바꾸는 작업을 의미한다.
- Pre-processing (전처리 작업) : 모델의 학습 능력, 효율을 끌어 올리기 위함
- Bounding Box- Resize
- Generalization (일반화) : train 결과와 inference 결과의 차이를 줄이기 위함
- Bias & Variance- Train / Validation
- Data Augmentation (Albumentations)
[4. Data Generation]
Data Feeding은 모델 처리량 만큼 데이터를 feeding 할 수 있을까?
-
Datasets
-
DataLoader : Dataset을 효율적으로 사용할 수 있도록 관련 기능 추가
피어세션 정리 및 학습 회고
Day 03
강의 복습 내용
[5. Model]
Pytorch 모델의 모든 레이어는 nn.Module 클래스를 따른다.
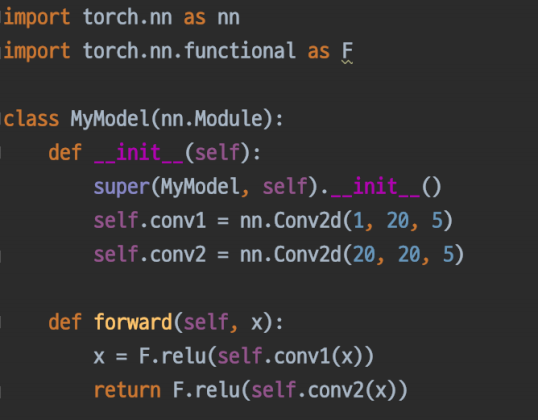
Pretrained Model은 좋은 품질, 대용량의 데이터로 미리 학습한 모델로, 내 목적에 맞게 다듬어서 사용하는 것이다. torchvision.models에서 가져 올 수 있다.
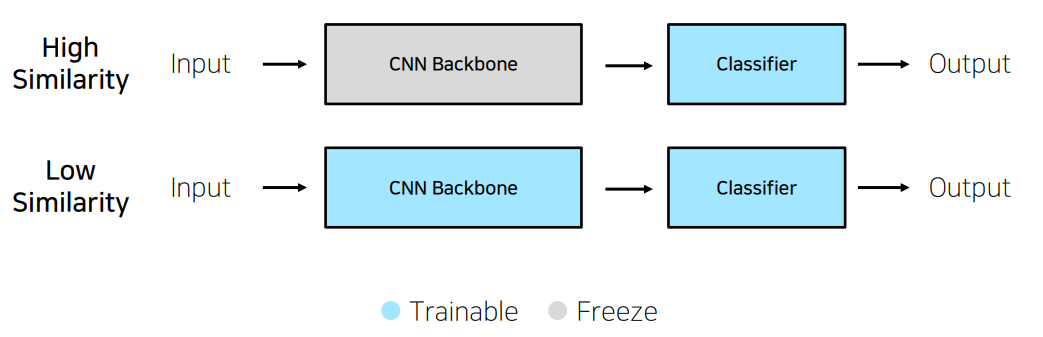
Transfer Learning은 CNN의 backbone을 가져오고, 나만의 classifier를 만들어서 output을 만드는 것이다.
Day 04
강의 복습 내용
[7. Training & Inference]
Training 과정에서 중요한 요소들은 loss, optimizer, metric이다.
loss.backward()를 통해 모델의 파라미터의 grad 값이 업데이트 된다.
Optimizer는 loss function의 결과 값을 최소화하는 모델의 파라미터를 찾는 것이다.
Metric은 학습에 직접적인 영향은 없지만 모델의 객관적인 지표이기 때문에 중요하다
모델을 train하기 전에 model.train()을 선언해서 model을 train모드로 설정한다.
optimizer.zero_grad()를 통해 직전 배치에서의 gradient 값을0으로 초기화해준다.
loss를 구하고 loss.backward를 통해 파라미터의 gradient값을 구하고 optimizer.step()을 통해 파라미터를 변경한다.

Inference 과정에서는 model.eval()을 선언해서 eval모드로 바꿔준다. with torch.no_grad를 통해 gradient 계산을 안하게 해 속도 및 메모리 향상에 도움을 준다. 마지막으로 torch.save()를 통해 해당 모델을 저장한다.
P stage의 코드를 보고 공부하자!
Day 05
강의 복습 내용
[9. Ensemble]
- 여러 모델로 만들어진 여러 결과를 앙상블하자
- 현업에서는 많이 쓰이진 않는다
- Model Averaging (Voting)
- Hard vote : 투표해 가장 많이 받은 투표를 결과값으로 함- Soft vote : 확률을 전부 더해 가장 큰 값을 결과값으로 함
- Cross Validation
- train set 내에서 train과 validate로 나눈다- K fold
- Test Time Augmentation(TTA)
- test image를 augmentation 후 모델 추론, 출력된 여러가지 결과를 앙상블
[10. Visualization Tool]
- tesnsorboard, wandb
피어세션 정리 및 학습 회고
베이스라인코드를 보고 주말에 공부를 좀 하자!
Project 1. Image Classification
-
대회의 목적, 방향성?
사람의 얼굴 이미지 만으로 사람이 마스크를 착용 여부와 성별, 연령대를 판별하는 것이다. 마스크 착용 여부(3가지), 성별(2가지), 나이(3가지)를 기준으로 입력 데이터인 이미지를 받고 총 18가지 클래스로 분류하는 작업이다.(이미지 분류) -
데이터
총 4500명의 사진으로, 한 사람당 사진의 개수는 7개 (마스크 착용 5장, 이상하게 착용 1장, 미착용 1장). 총 31500장으로, 이 중 18900장이 학습 데이터, 12600장이 테스트 데이터다. 사진의 크기는 (384, 512)이다.
