
Week 9
Day 01
강의 복습 내용
[Object Detection]
Classification : 사진이 무엇인지 예측하는 태스크
Object Detection : 이미지에서 객체의 위치를 찾고 무엇인지 식별하는 태스크
Semantic Segmentation : 객체의 영역을 구분
Instance Segmentation : Semantic + 객체 구분
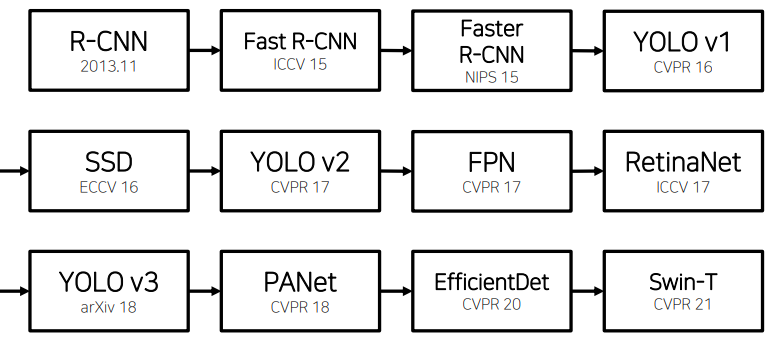
Evaluation Method
성능 측정
- mAP(mean average precision) : 각 클래스당 AP의 평균
- Confusion matrix
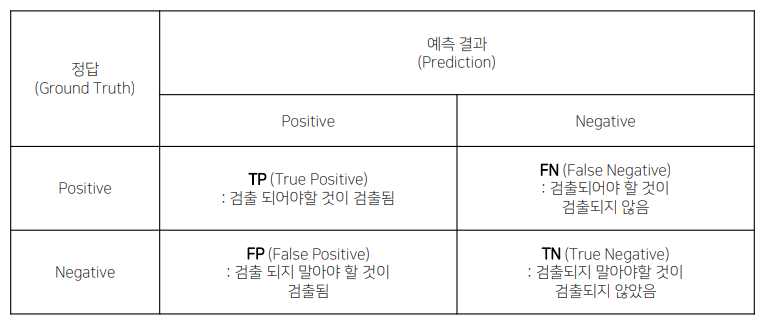
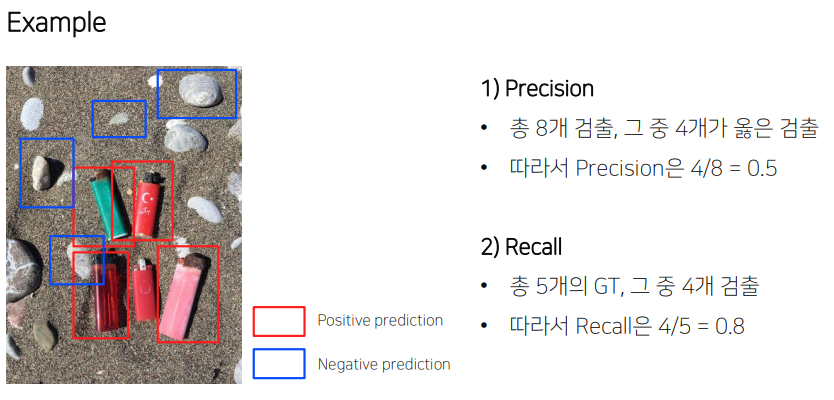
- Precision : 모델의 예측 관점에서 정의한 matrix
모든 검출 결과 중 옳게 검출한 비율
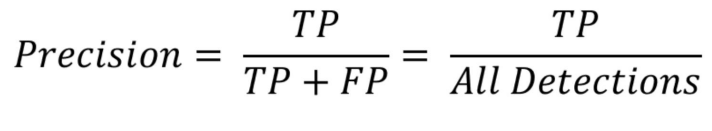
- Recall : 정답 관점에서 보는 matrix
실제 정답 중에서 옳게 예측한 경우 / 마땅히 검출해내야하는 물체들 중에서 제대로 검출된것의 비율
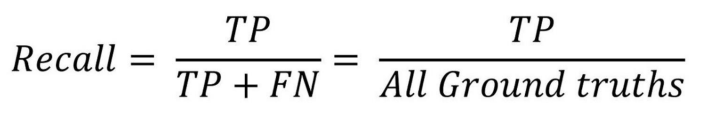
- PR Curve : confidence 기준으로 정렬해서 Precision과 Recall을 구해서 그래프로 표현
- Average Precision (AP) : 하나의 숫자로 성능을 평가하기 위해 나온 것. PR 그래프의 선 아래쪽의 면적
- mAP : mean average precision , IOU를 같이 정해줘야됨
- Confusion matrix
속도 측정
- FPS
- Flops(Floating Point Operations) : 연산량 횟수
Library
- MMDetection
- Detectron2
- YOLOv5
- EfficientDet
Day 02
강의 복습 내용
[2 Stage Obeject Detectors]
객체가 있을 법한 위치를 찾고, 해당 객체가 무엇인지 예측하는 2 단계로 이루어져있다.
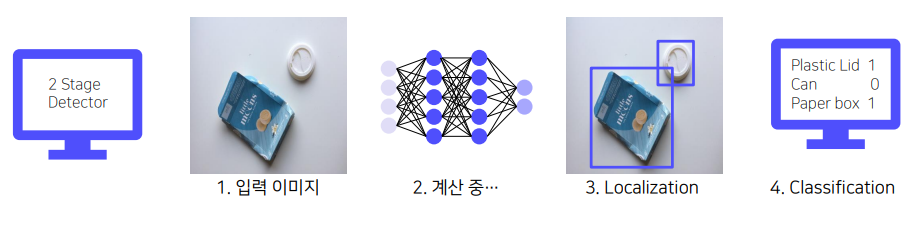
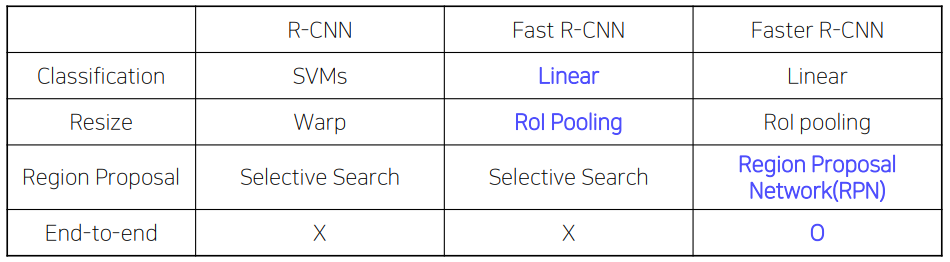
R-CNN
1. 해당 이미지로 부터 객체가 있을 법한 위치를 예측 (ROI 2000개)
2. 고정된 사이즈로 warping
3. CNN
4. Classify / Bounding box 예측
위치 예측하기
- Sliding Window : 무수히 많은 후보들이 나옴
- Selective Search : 이미지의 색, 질감, 모양 특성들을 무수히 많은 영역으로 분할 후 비슷한거 끼리 통합해서 후보영역을 줄어나감
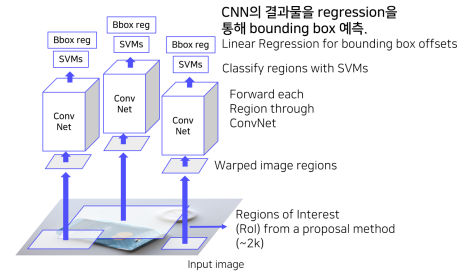
SPPNet
1. CNN을 1번만 실행시켜
2. 2000개의 ROI를 뽑아
3. Spatial pyramid pooling으로 고정된 사이즈로 변환
4. FC Layers
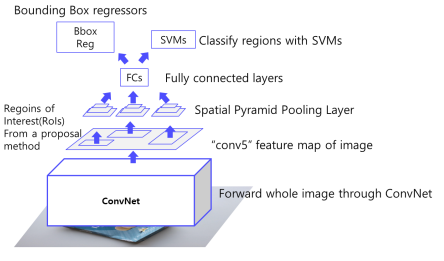
Fast R-CNN
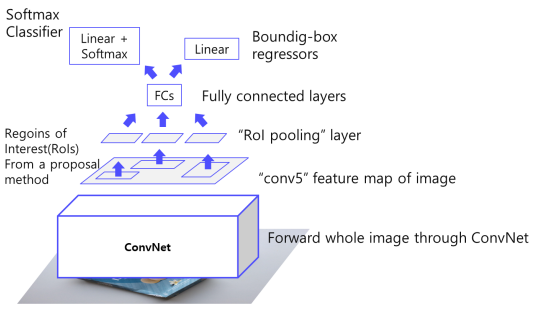
1. 이미지를 CNN에 넣어 feature 추출
2. ROI Projection을 통해 feature map 상에서 ROI 계산
원본 이미지에서 Selective search를 통해 2000개의 ROI를 뽑아내고 feature map상에 projection을 한다
3. ROI pooling을 통해 일정한 크기의 feature 추출
4. FC layer이후 Softmax classifier, Bounding Box regressor
multi task loss 사용
- Classification : Cross entropy
- BB regressor : Smooth L1
Faster R-CNN
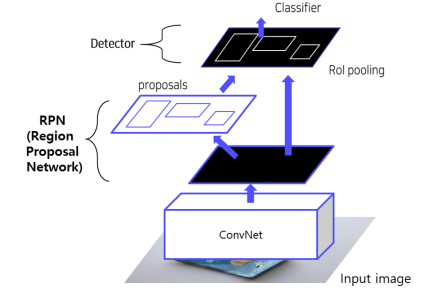
Selective Search를 RPN으로 대체해서 End to End
1. CNN에 넣어 feature map 추출
2. RPN을 통해 RoI 계산 (Anchor Box)
Anchor box가 개체를 포함하고 있는지 확인하고, BBox의 위치를 미세 조정함
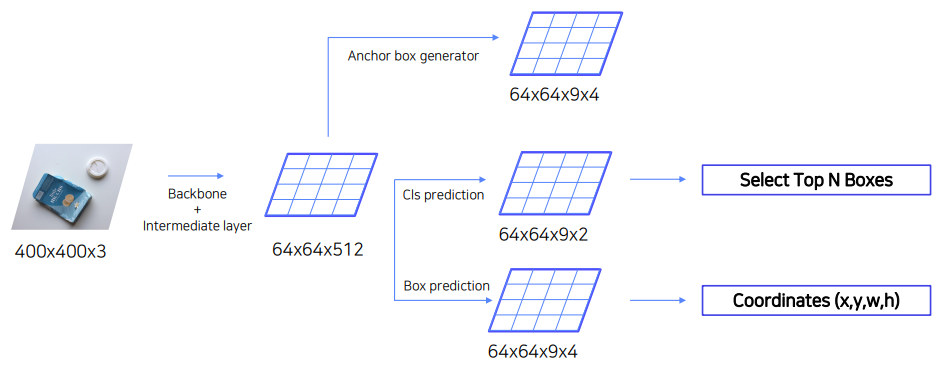
NMS : 분류된 영역이 겹치면 제거하는 과정. IoU가 0.7이상인 proposals영역들은 중복된 영역으로 판단하여 제거
Day 03
강의 복습 내용
[]
과제 정리
피어세션 정리 및 학습 회고
Day 04
강의 복습 내용
[]
과제 정리
피어세션 정리 및 학습 회고
Day 05
강의 복습 내용
[]
과제 정리
피어세션 정리 및 학습 회고
