
Week 7
Day 01
강의 복습 내용
[CNN Visualization]
CNN은 어떤 원리로 동작할까? 어떻게 학습이 이뤄어질까?
CNN은 여러 단계를 걸쳐 학습을 통해 weight들의 조합으로 복잡하게 연결 되어있기 때문에 Black Box 시스템이다. 이걸 확인하기 위해 CNN Visualization을 진행한다.
Filter weight visualization
필터를 시각화한다. 간단한 시각화를 통해 CNN의 첫 레이어가 어떤 것을 보고있는지, 어떤 행동을 하고 있는지 이해할 수 있다. 하이 레벨의 레이어은 차원 수가 높고 앞쪽 필터와 합성이 되서 시각화가 어렵다.
모델 이해하기 VS 데이터 결과를 분석하기
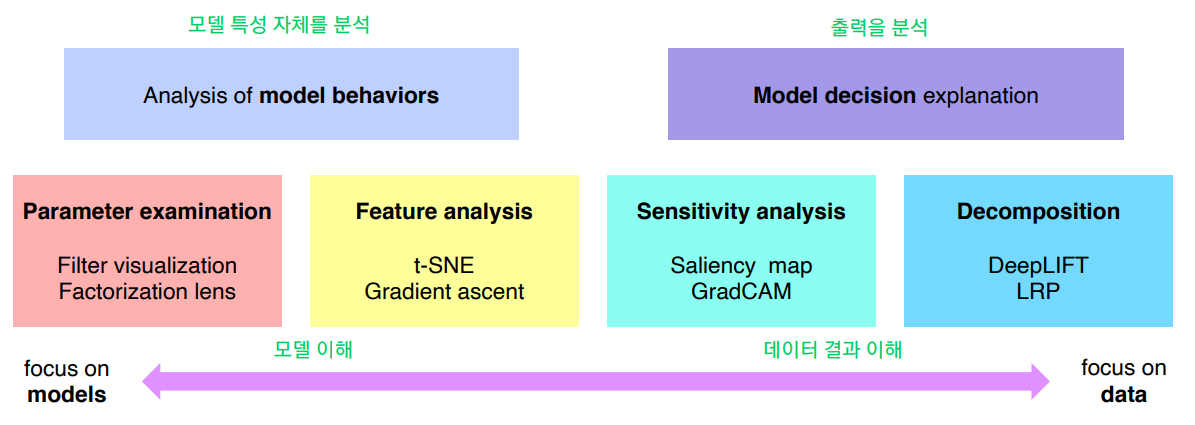
Analysis of Model Behaviors
Embedding feature analysis (High Level)
-
Low, middle, high level layor를 거쳐서 나온 feature들을 분석하는 방법.
예제 영상을 통해 시각화하는 방법으로 예제와 비슷한 특징을 갖고있는 사진을 추출한다(Nearest Neighbors). 검색된 예제를 통해서 분석하는 방법은 전체적인 그림을 파악하기 어려운 단점이 있다. -
t-SNE로 고차원을 저차원으로 낮춘다
Activation Investigation (Mid, High Level)
- 레이어의 activation을 분석해서 모델의 특성을 파악
- hidden node의 역할을 파악할 수 있음
- Maximally activating patch : 히든 레이어의 가장 큰 값을 뽑아 나열해서 특징 파악
- 분석하고자하는 특정 레이어를 정함
- 예제 데이터를 feed후 지정한 레이어의 activation을 저장
- 가장 큰 값을 파악해 receptive field를 찾아 그림으로 표시
Class visualization
- 예제 데이터를 사용하지 않고 네트워크가 기억하고 있는 이미지를 추출
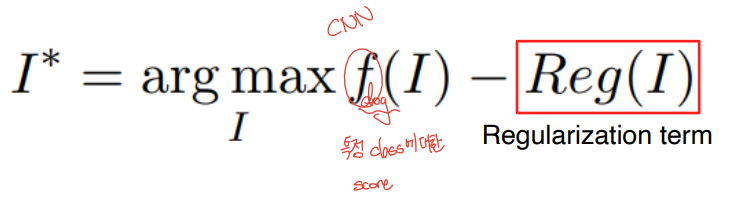
- 임의의 영상으로 분석하고자 하는 CNN 모델에 입력으로 넣어준다
- 관심 클래스 스코어를 추출
- Backpropagate을 통해 입력의 gradient를 구함, 입력이 어떻게 변해야 target class score가 높아지는지를 찾아서 업데이트함
- 입력을 업데이트 후 반복
Model decision explanation
Saliency Test : 영상이 제대로 판정되기 위한 각 영역의 중요도 추출 방법
- Occlusion map
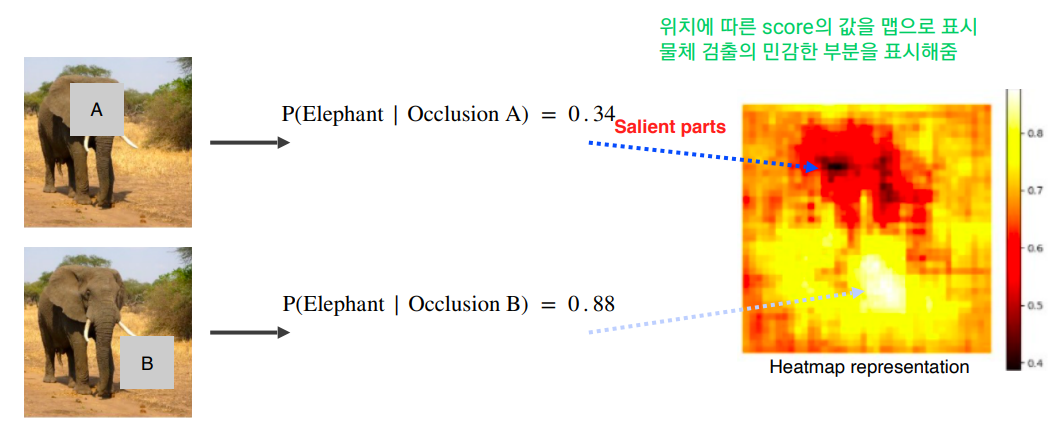
- via Backpropagation - 특정 이미지를 분류해보고 최종 결론이 나온 클래스에 결정적으로 영향이 미친 부분이 어디인지를 히트맵 형태로 보여줌
- 입력 영상으로 클래스 스코어를 구함
- 입력까지 backpropagate을 진행 후 절댓값, 제곱을 취함 (값의 크기가 중요, 업데이트 되어야 하는 거)
- 시각화
- Backprop
- DeConv
- Guided backprop
Class activation mapping (CAM)
- 최종 분류시 어떤 부분을 보고 분류했는지 히트맵으로 표시
- 네트워크 변형 필요! FC layer 대신 Global average pooling 사용 후 FC layer 1개 사용
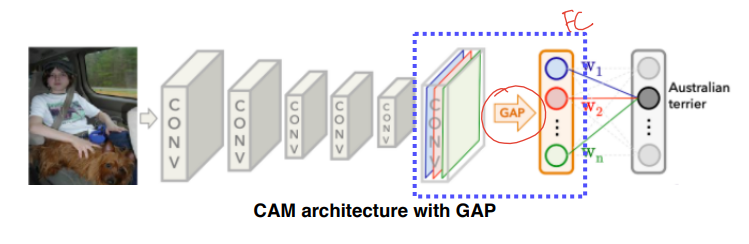
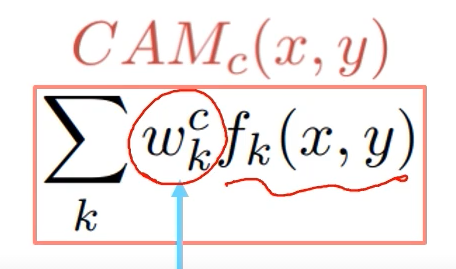
- 마지막 레이어가 GAP과 FC 레이어로 구성 되어 있어야 하며, 재학습해야되는 단점이 있음
Grad-CAM
- 구조를 바꾸지 않고 재학습도 필요없이 CAM을 뽑을 수 있게함
- activation map까지만 back propagation함
과제 정리
피어세션 정리 및 학습 회고
Day 02
강의 복습 내용
[Instance/Panoptic segmentation & Landmark localization]
Instance Segmentation : Semantic segmentation + distinguishing instances
Mask R-CNN
- 2 stage 구조
- mask branch가 추가
- RoI pooling을 대신해 RoI align이 추가됨 (더 정교한 feature를 뽑음)
- 모델을 확장해서 key poing branch로 발전함
YOLACT
- 1 stage 구조 / 백본 FPN
- Real-time instance segmentation network
- 전체 이미지에 대한 prototype mask dictionary 생성
- instance 마다 linear combination coefficients 예측
- 후 prototype mask를 linear하게 합친다
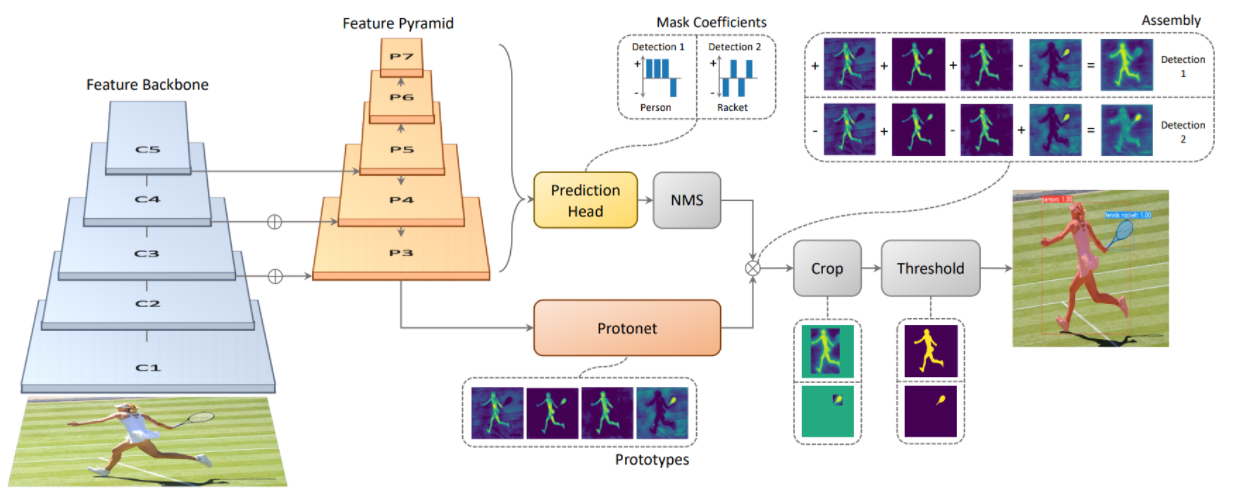
YolactEdge
- 소형화된 디바이스에 올릴 수 있음
- 키 프레임에 해당하는 걸 다음 프레임에 전달 후 특징 맵의 계산량을 줄여서 빠른 속도로 할 수 있음
Panoptic Segmentation : 배경화면 + Instance Segmentation
UPSNet
- FPN 구조 사용
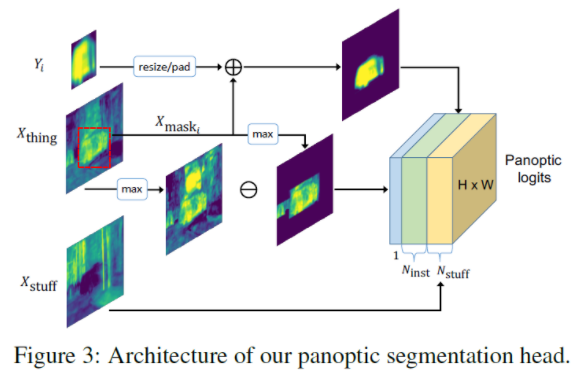
- Semantic Head : things / stuff (모든 semantic class를 segment)
- Instance Head, 물체 detection. box regression, mask 추출 담당 (특정 클래스를 더욱 정확하게 식별 하는 것이 목표)
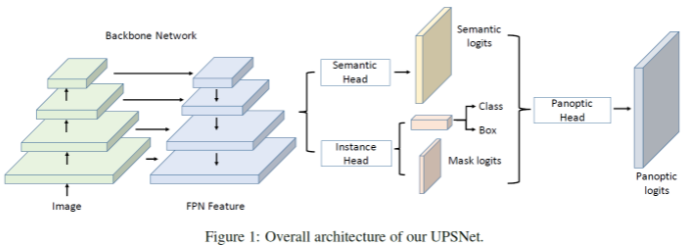
- Panoptic Head으로 최종적으로 하나의 head로 추출
- Semantic head의 배경은 바로 Panoptic head로 감
- Semantic head의 물체 부분 masking 후 Instance head와 더함
- Semantic head의 물체 부분을 제외하면 Unknown 부분만 남김
VPSNet
- for video
- 이전 frame의 feature들을 합쳐서 시간 연속적으로 부드러운 segmentation을 진행
Landmark Localization
Facial, Human pose 시 사용. 중요하다고 생각하는 key point를 위치 축적하는 방식
- Coordinate regression : 부정확하고 편향됨
- Heatmap classification : 좋은 성능, 모든 픽셀 계산해야되서 계산량 많음
각 위치마다 confidence가 나타나는 표현
Semantic segmentation 처럼 한 채널이 각각의 키포인트를 담당(하나의 클래스), 키포인트가 발생할 확률맵을 각 픽셀별로 분류하는 방법 - 좌표 -> 히트맵
- 히트맵 -> 좌표
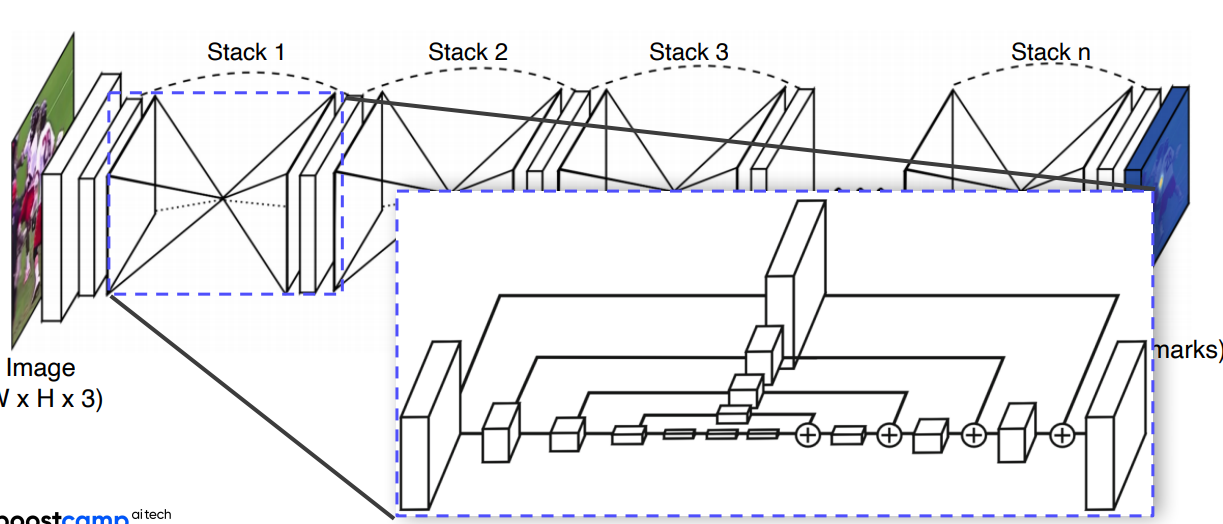
Hourglass network
- Unet 과 비슷
- 영상 전체를 작게 만들어서 receptive field를 키워서 landmark를 찾아
- skip connection이 있어 정확한 위치를 참조
- Unet과 다른 점은 + (채널이 안커짐) & skip시 Conv layer를 통과함
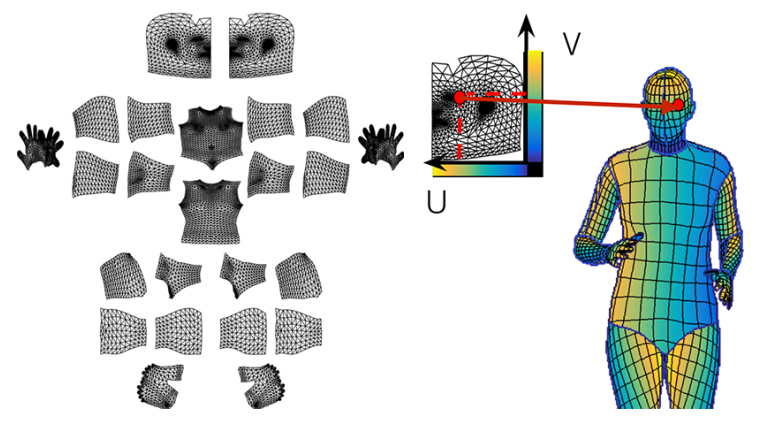
DensePose
- 신체 전체의 랜드마크 -> 3D
- Faster R-CNN + 3D surface regression branch
- UV map : 표준 3d 모델을 이미지 형태로 표현한 거
Extensions
RetinaFace = FPN + Multi-task branches
- 다른 태스크에서 오는 공통된 정보에서 백본이 더 강하게 학습
- 더 적은 데이터로도 더 많이 학습
과제 정리
피어세션 정리 및 학습 회고
Day 03
강의 복습 내용
[Conditional Generative Model]
Generative model : 영상을 생성만 할 수 있음
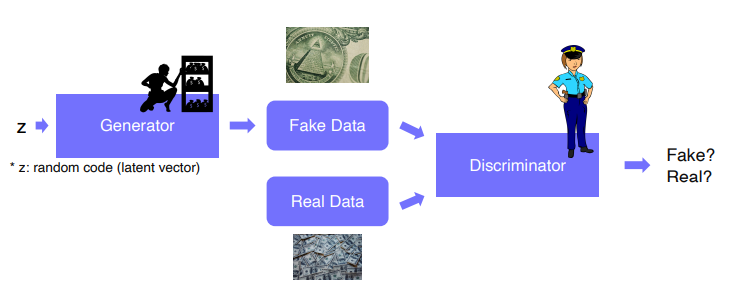
- 도둑 : 생성모델
- 경찰 : 판별사
- 생성모델이 경찰이 판별하지 못하도록 학습
- 경찰은 가짜를 더 잘 찾기 위해 학습
- 서로 학습됨, 상호작용을 통해 성능이 올라감 Adversarial Training
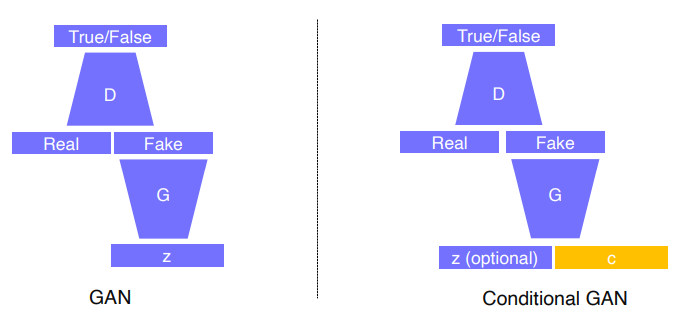
Conditional Generative model
- 유저의 의도를 반영할 수 있음
- 응용 : 저퀄리티 오디오 -> 고퀄 오디오 / machine translate / article generation with the title
- Image-to-Tmage translation (Style transfer, Super resolution, Colorization)
Super Resolution
- 저해상도 -> 고해상도
- Regression Model
MAE/MSE를 loss로 사용. 이런 모델을 사용하면 해상도는 높아지지만 흐릿하게 나옴. 왜??
픽셀 자체의 평균 에러를 구하다보니까 영상의 평균을 구하면 가장 안전한 loss가 나오기 때문이다.
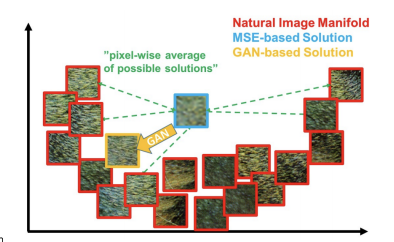
- ex) 검정 or 흰으로 예측해도 틀리는 경우가 있어 에러가 적당히 적은 회색 예측
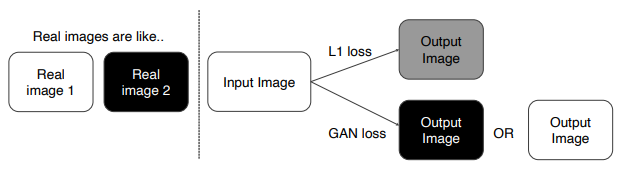
- 반면 GAN loss로 하면 Discriminator에서 회색 데이터를 판별할 수 있기 때문에 검, 흰이 나옴
Image Translation
한 이미지를 다른 스타일로 변환하는 거. (흑백 -> 컬러 / 낮 -> 밤 / 일반사진 -> 지도 ...)
Pix2Pix
Image Translation을 CNN 구조로 이용해서 처음 정리한 연구 방법. Supervised Learning, "pairwise data"
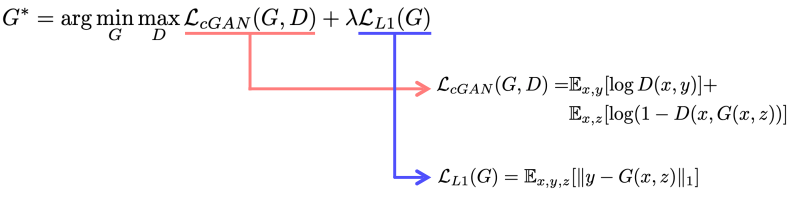
L1 loss를 사용하는 이유 : ground truth(y)와 입력 (x)과 직접 비교해서 y와 비슷한 영상을 만듬 / 학습이 안정적으로 할 수 있게 보조
GAN 사용 이유 : 좀더 현실적인 그림을 위해

CycleGAN
Non-pairwise dataset을 사용. X, Y가 직접적인 연관성이 없도록 활용하는 방법
CycleGAN loss = GAN loss + Cycle-consistency loss
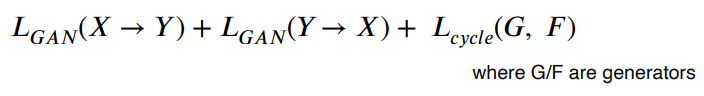
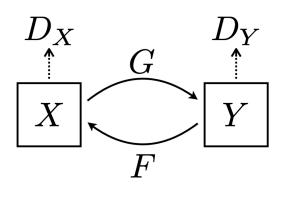
GAN loss만 사용시 mode collapse가 나옴. 인풋에 상관 없이 하나의 결과만 나오는 결과 이걸 예방하기 위해 Cycle-consistency loss가 필요함
Cycle-consistency loss는 style과 컨텐츠가 유지되도록 확인함. (X -> Y -> X / Y -> X -> Y) 과정 중 X가 원본과 같아야됨.
GAN은 alternating traing을 함으로 훈련과정이 복잡하다. 다른 방법이 없을까?
GAN loss
- 복잡함
- pre-trained network 필요없음. 다양한 어플리케이션에서 활용 가능
Perceptual loss
- Simple to train and code
- pre-trained network 필요함
- Image Transform Net : 원하는 스타일로 이미지가 나옴
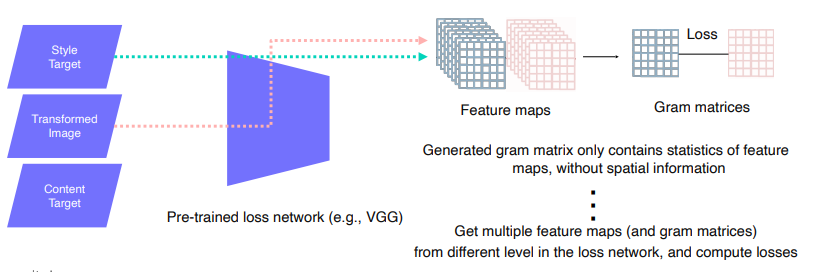
- Loss Network : 학습된 vgg모델로 생성된 모델을 넣어서 feature들을 뽑아서 style, content의 loss를 뽑고 image transform net을 학습함.
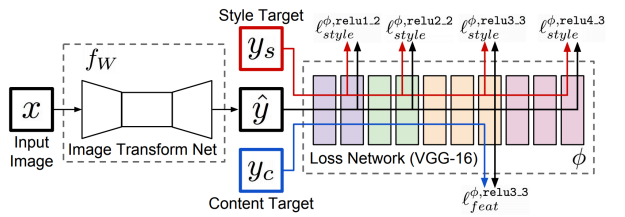
- Feature reconstruction loss : 변형된 이미지와 입력 이미지를 비교해서 loss(l2)를 만든다.
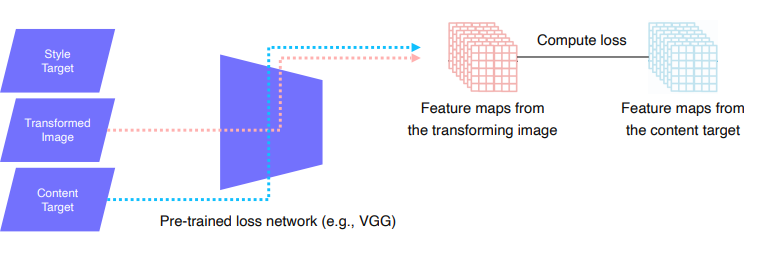
- Style reconstruction loss : 변환하고 싶어하는 스타일의 이미지를 style target과 변형된 입력 이미지의 feature들을 뽑음. Style를 담기 위해 Gram matrices를 뽑음. Style의 특징만 필요함으로 공간적인 특징들은 다 제거함. (채널에 해당하는 공간 유사도를 평가) Style target의 style을 따르게됨
응용 사례
- Deepfake 생성
- Deepfake Detection Challenge (detection 성능이 올라가면 deepfake 성능도 올라가겠네?)
- Face de-identification
- Face anonymization with passcode
- Video translation
과제 정리
피어세션 정리 및 학습 회고
Day 04
강의 복습 내용
[Multi-modal Learning]
다른 특성을 갖는 데이터 타입을 같이 사용해서 학습하는 것.
1. Overview of multi-modal learning
어려운 점
- 데이터가 다양함 -> 데이터 표현이 다 다르다
- 서로 다른 모델에서 오는 정보의 양이 다르다
- 다양한 표현 방식의 데이터를 넣게 되면 학습에 방해 (편향) 될 수 있음
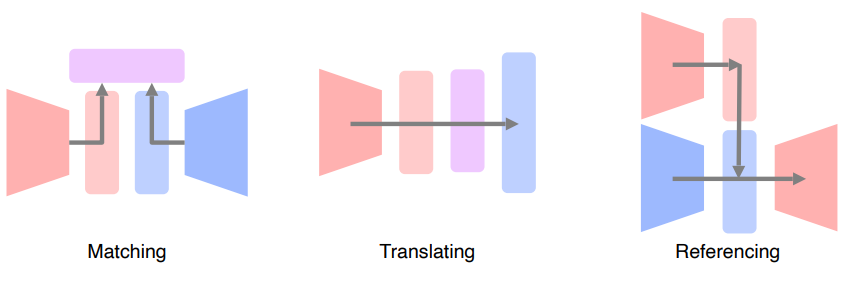
Multi-Modal 패턴
- Matching : 서로 다른 두 데이터 타입이 있을 때 2개의 타입을 공통된 공간에 보내서 서로를 매칭하는 구조
- Translating : 하나의 데이터를 다른 데이터로 변형해줌
- Referencing : 하나의 데이터를 다른 데이터를 참조하면서 상호적인 작용을 이용한다.
2. Visual data & Text
2.1 Matching
Text Embedding
Character를 사용하지 않고 word level을 사용함. Dense vector로 표현
일반화의 능력이 있다.
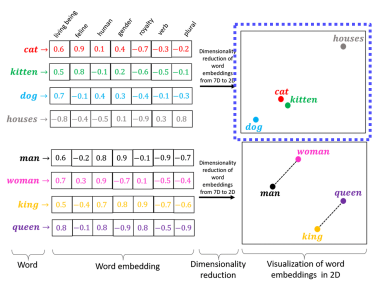
word2vec - Skip-gram model (???)
주변의 n개의 단어를 예측하는 학습을 진행. 관계성을 알기 위해
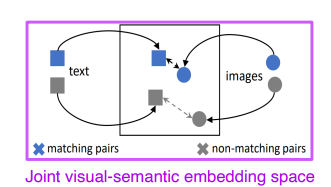
Joint Embedding
1. Image tagging : 주어진 이미지에 태그 생성 혹은 태그를 통해 이미지 생성
- Pre-trained unimodal model을 합친다.
- 하나의 d 차원의 feature vector를 만들어 표현한다.
- 2개가 호환성이 있도록 Joint embedding을 학습한다.
서로 매칭이 되면 2개의 거리를 가깝게 학습하고, 서로 다른 매칭이면 거리를 멀게해 학습함 (Metric learning)
- Image & food recipe retrieval
- 재료와 지침의 순서들을 각각 하나의 fixed vector를 만들고 concat해서 하나로 만듬
- 이미지는 cnn으로 하나의 벡터로 만들어줌
- cosin similarity loss를 사용해서 연관성을 학습
- semantic regularization loss를 사용해서 학습
2.2 Translating
Image captioning : 이미지가 주어지면 이미지를 설명하는 텍스트를 생성 image to sentence (CNN & RNN)
Show and tell : CNN과 RNN을 합치는 방법
Show, attend, and tell
- 이미지를 cnn에 넣어
- 14x14의 공간 정보를 유지하는 feature map을 뽑아 RNN에 넣어
- 어디를 reference하...............
Text to image by generative model
- Text 전체를 fixed dimension vector로 만듬,가우시안 랜덤 코드를 붙임 (똑같은 입력이 들어 갔을 때 다른 결과를 내기 위함) 후 Generative model 통과 이미지 생성
- 생성된 이미지가 입력으로 들어오면 입력한 문장 정보을 기준으로 이미지가 알맞는 건지 확인함.
2.3 Referencing
Visual question answering : 영상과 질문이 주어지면 답을 도출하는 과제
3. Visual data & Audio
소리는 시간축에 대해서 표현이 됨(waveform), 딥러닝에서는 Acoustic feature 표현 방식으로 바꿔야됨. 푸리에 트랜스폼(STFT)을 사용해서 변환함. 짧은 시간 구간 동안만 FT을 적용해서 spectrum을 만든다. Hamming window를 사용해서 구간의 끝 구간 보다 가운데에 더 집중하도록 만듬.
3.1 Matching
Sound tagging : 현재의 소리로 어디서 일어나는 것인지 파악하는 거
SoundNet : 오디오의 표현을 학습. visual recognition networks를 통해 object와 scene의 결과값과 소리의 결과값을 학습해 오디오의 모델을 학습함. (visual knowledge를 sound에 transfer함)
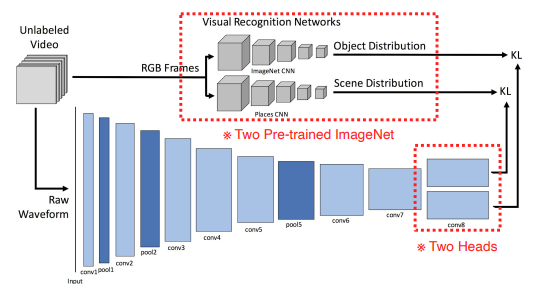
3.2 Translation
Speech2Face - Module networks 미리 학습된 네트워크를 잘 조합
- VGG-Face Model, Face Decoder을 사용함
- 얼굴을 통해 face feature를 뽑고, 음성을 voice encoder를 통해 feature들을 뽑는다.
- face, voice feature가 호환이 되도록 하여 voice가 face를 따라하도록 학습
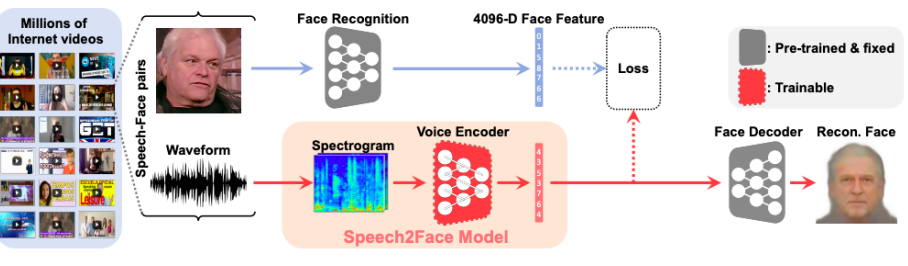
Image-to-speech
- 입력 이미지를 14x14 feature map으로 만들어주고 sub-word units으로 추출
- unit-to-speech model을 학습
- image-to-unit, speech-to-unit으로 unit의 호환성을 맞춰서 end to end 네트워크를 생성. 학습은 end to end가 아님!
Referencing
Sound source localization : 소리가 영상의 어디에서 나오는지 찾음
- sound feature와 visualized feature를 내적해서 관계성을 파악
- supervised, unsupervised????
과제 정리
피어세션 정리 및 학습 회고
Day 05
강의 복습 내용
[3D Understanding]
3D가 왜 중요할까?? 우리가 3D에 살고 있기 때문에 3D 공간에 대한 이해도를 높여야 됨!!
- AR/VR
- 3D printing
- Medical applications
Triangulation : The way to obtain a 3d point from 2D images
2D 이미지에서 3D 이미지를 구하기 위한 방법

3D는 컴퓨터에 어떻게 표현될까??
- Multi-view images
- Volumetric
- Part assembly
- Point cloud
- Mesh
- Implicit shape
3D Datasets
- ShapeNet
- PartNet (useful for segment)
- SceneNet (indoor images)
- ScanNet (실제 스캔함)
- Outdoor 3D datasets are for autonomous vehicle applications
3D Recognition : Volumetric CNN을 통해 분류할 수 있음
3D Object detection
3D Semantic segmentation
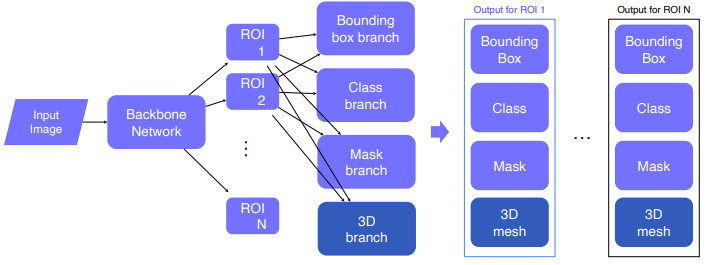
Conditional 3D generation (Mesh R-CNN) : 2D image -> 3D mesh / Mask R-CNN에서 3D branch를 추가함
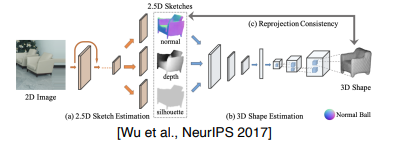
More complex 3D reconstructin models : reconstruction into multiple sub-problems(물리적으로 의미있는 형태로 분리)
과제 정리
피어세션 정리 및 학습 회고
