
Redis의 두 가지 용도
1. Redis Cache(Pub/sub)
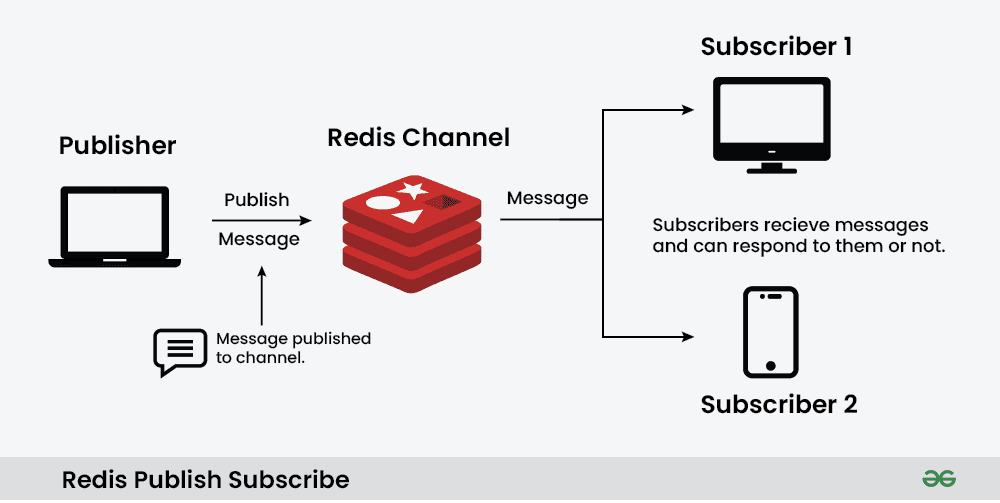
Redis Pub/Sub은 메시지를 보내는 발행자(Publisher)와 메시지를 받는 구독자(Subscriber)가 서로를 알 필요 없이 채널(Channel)을 통해 통신하는 구조입니다.
Redis Pub/Sub이 다른 메시징 시스템(Kafka, Redis Streams 등)과 가장 차별화되는 특징은 '데이터의 비영속성*과 '실시간성'입니다.
자세한 내용은 Redis Pub/Sub 을 참고하세요. 오늘의 핵심 주제는 Redis Streams입니다.
2. Redis Streams
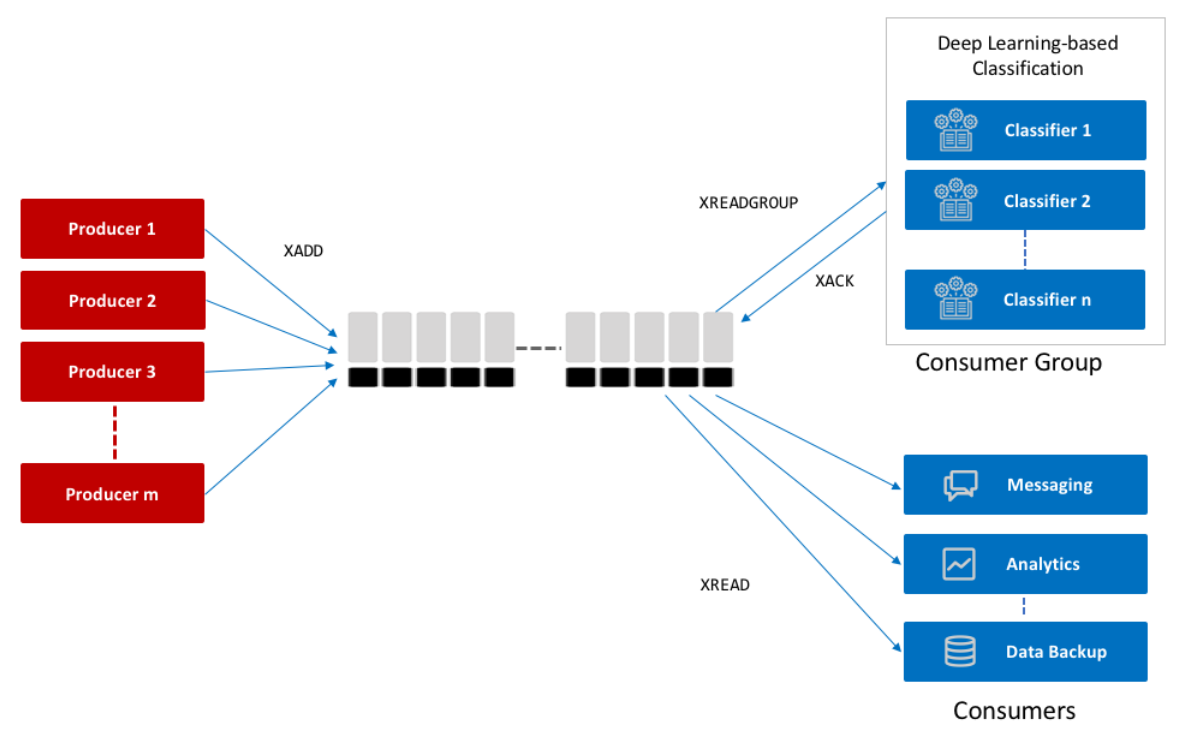
Redis streams는 Append-only Log(추가 전용 로그) 형태의 ‘자료구조’로, 시간 순서대로 이벤트나 메시지를 저장하고 관리하는 데 특화되어 있습니다.
자세한 설명은 Redis streams 을 참고하면 될 것 같습니다.
그래서 Redis streams를 왜 알아봤는데
제가 담당한 기능의 요구사항은 다음과 같았습니다. 상세하게 다 적기에는 부담스러우니 대략적으로만 정리해보겠습니다.
- 대화 종료 시, 약 1시간분량의 대화내역을 파일로 다운로드받아볼 수 있어야 함
- 실시간으로 대화내역도 모니터링 할 수 있어야 함
기존에 Redis pub/sub을 이용하여 간단한 메세지 전달만 수행하고 있던 저에게 난관이 봉착했습니다.
기존에 유명한 해결책은 바로 ‘Kafka’. 바로 도입해봐야겠다 싶었는데, 혹시나 하는 마음에 요구사항을 프롬프트로 풀어 GPT에게 입력한 결과. 그는 ‘Redis streams’라는 키워드를 뱉었습니다.
Kafka vs Redis streams

이 둘을 비교하며 고민해봅시다.
1. 아키텍처 및 데이터 저장 방식 (Architecture & Data Storage)
- Apache Kafka:
- 디스크 기반 (Disk-based): 데이터를 디스크에 저장하며 메모리 캐싱을 활용합니다. 이로 인해 대용량 데이터의 장기 보관(수일~수년)에 적합합니다.
- 분산 로그 구조: 분산 커밋 로그(Commit Log)로 작동하며, 브로커(Broker), 토픽(Topic), 파티션(Partition)으로 구성된 분산 아키텍처를 가집니다.
- Redis Streams:
- 인메모리 기반 (In-memory): 데이터를 주 메모리(RAM)에 저장합니다. 이로 인해 속도가 매우 빠르지만, 메모리 용량에 의해 데이터 저장량이 제한됩니다.
- 자료구조: Redis의 Append-only 로그 데이터 구조(Radix Tree 기반)로, Redis 서버의 단일 스레드 이벤트 루프 내에서 동작합니다. 데이터 영속성(AOF/RDB)은 선택 사항입니다.
말이 어렵습니다.
쉽게 정리하면, 양이 많고 오래 보관해야 하면 Kafka
양이 적고, 단시간 보관해야 하면 Redis streams 가 적합해 보였습니다.
2. 성능 특성 (Performance Characteristics)
성능 측면에서는 처리량(Throughput)과 지연 시간(Latency) 사이의 트레이드오프가 존재합니다.
| 특성 | Redis Streams | Apache Kafka |
|---|---|---|
| 지연 시간 (Latency) | 1ms 미만 (Sub-millisecond). 메모리에서 직접 처리하므로 즉각적인 응답이 가능 | 밀리초 단위 (Low, but higher than Redis). 디스크 I/O 및 복제 과정 등으로 인해 Redis보다는 높음 |
| 처리량 (Throughput) | 높음. 하지만 메모리와 단일 스레드 구조의 한계가 있음 | 매우 높음. 대규모 데이터 스트리밍 처리에 최적화되어 있으며, 초당 수백만 건의 이벤트를 처리할 수 있음 |
요약하자면,
- 지연시간: Redis streams > Kafka
- 처리량: Redis streams < Kafka
입니다.
3. 메시지 소비 및 처리 모델 (Consumption Model)
두 시스템 모두 컨슈머 그룹(Consumer Group) 개념을 지원하지만, 작동 방식에는 차이가 있습니다.
- Kafka:
- Pull 방식: 컨슈머가 브로커로부터 데이터를 가져옵니다(Poll). 이를 통해 컨슈머가 처리 속도를 제어할 수 있습니다.
- 파티션 기반 분산: 컨슈머 그룹 내의 각 컨슈머는 특정 파티션에 할당됩니다. 파티션 내에서의 순서는 보장되지만, 파티션이 나뉘면 전체 순서는 보장되지 않을 수 있습니다.
- Redis Streams:
- Push 방식 (대기 가능): 클라이언트가 차단(Blocking) 모드로 대기하면 새 메시지가 도착하는 즉시 전달받습니다.
- 로드 밸런싱 방식: Redis의 컨슈머 그룹은 파티션 개념 없이 하나의 스트림 키에서 메시지를 여러 컨슈머에게 로드 밸런싱하여 분배합니다. 따라서 특정 컨슈머가 더 빠르면 더 많은 메시지를 가져갈 수 있으며, 이 경우 그룹 전체의 처리 순서가 섞일 수 있습니다.
핵심은 순서 보장 관련이었습니다. 이것 같은 경우는 요구사항에 따라 중요한 것이 달라질 수 있을 것 같습니다.
4. 확장성 및 데이터 보존 (Scalability & Retention)
- Kafka:
- 수평적 확장: 파티션을 여러 브로커에 분산시켜 처리량과 저장 용량을 무제한에 가깝게 확장할 수 있습니다.
- 데이터 보존: 디스크 기반이므로 설정에 따라 데이터를 영구적으로 보존하거나 매우 긴 기간(수년) 동안 저장할 수 있습니다.
- Redis Streams:
- 수직적 확장 중심: 단일 노드의 메모리 크기에 제한을 받습니다. 수평 확장을 위해서는 클러스터링이나 샤딩을 직접 구현해야 하는 복잡함이 있을 수 있습니다.
- 데이터 보존: 메모리 효율을 위해 주로 짧은 기간(수시간~수일)의 데이터를 보관하며,
MAXLEN등을 사용해 오래된 데이터를 정리하는 것이 일반적입니다
솔직히 둘다 직접 만져보지 않는 한 모르겠습니다. 우선 이렇구나 라고 넘어가겠습니다.
아 그래서 Redis streams를 선택했구나
맞습니다. 위의 요구사항에서 살펴보았다시피,
- 데이터를 오래 보관할 필요 없고
- 바로바로 데이터 소모 후 채널을 초기화 할 예정이기에 대용량 아키텍처 또한 필요 없습니다
기존에 Redis Pub/Sub을 사용하고 있었기에 기술학습비용이 적기도 하고, 인프라 비용 측면에서도 고려해 보았을 때, Redis Streams이 적합하다고 판단했습니다.
‘과유불급’, 멋있는말로는 ‘오버테크놀로지’를 피하는 것 또한 역량 중 하나이니까요.
Redis streams만 사용하면 끝나는 거네 이제?

아쉽게도 아니었습니다. TTS 음성데이터도 처리를 했어야 하기 때문입니다.
TTS데이터도 Redis streams로 관리하면 안되는거야?
네. 안됩니다. 저장할 필요가 없는 데이터이기 때문입니다.
이유는 다음과 같습니다.
기본적으로 Redis streams는 ‘자료구조’
Redis streams는 자료구조입니다. Redis streams로 Produce한 데이터는 내부에 쌓이게 됩니다.
이는 수동으로 비우지 않으면 계속해서 쌓이기 때문에 메모리의 성능이 저하됩니다. (메모리가 빨리 차기 때문)
특정 개수를 지정해놓고 관리하는 방법도 있다(GPT피셜)고는 하지만 그다지 효율적이라고 생각되지 않았습니다.
결국 장기적으로는 잠재 결함(latent defect)과 비결정적 장애 요인을 누적시켜 시스템의 안정성과 예측 가능성을 구조적으로 저하시킬 위험이 있기 때문이죠.
말이 어려웠습니다. 결론은 “예상치 못한 문제가 발생할 수 있기 때문”입니다.
문제를 해결하기 위한 해결책

답은 의외로 간단했습니다.
Redis streams와 Redis Pub/Sub을 동시에 사용하면 되는 것입니다.
- 저장해야 하는 텍스트 데이터 → Redis streams
- 휘발되어야 하는 binary 데이터 → Redis Pub/Sub
하나의 Redis 서버는 각각 streams나 cache 방식으로 단일 목적으로 사용하는 것이 가장 안정성이 좋다고 하여(GPT피셜) 서버를 각각 다르게 설정하고 띄웠습니다.
Springboot 설정
구글링해보니 하나를 @Primary설정을 하여 하나를 우선으로 쓰는 다중 Redis 설정법이 대부분이길래, 제 상황과 맞는 솔루션이 아니기에, GPT에게 물어가며 진행했습니다.
.yml
spring:
redis:
cache:
host: {redis_cache_server_url} # pub/sub
port: {redis_cache_port}
password: {redis_cache_password}
stream:
host: {redis_streams_server_url} # streams
port: {redis_streams_port}
password: {redis_streams_password}각 Properties는
@ConfigurationProperties(prefix = "spring.redis.stream")
@ConfigurationProperties(prefix = "spring.redis.cache")로 별도의 property 객체를 만들어줬습니다.
MultiRedisConfig
@Configuration
@EnableConfigurationProperties({
RedisCacheProperties.class,
RedisStreamProperties.class
})
public class MultiRedisConfig {
@Primary // 기본 연결 공장으로 지정
@Bean("redisCacheConnectionFactory")
public RedisConnectionFactory redisCacheConnectionFactory(RedisCacheProperties props) {
RedisStandaloneConfiguration config = new RedisStandaloneConfiguration(props.getHost(), props.getPort());
config.setPassword(props.getPassword());
return new LettuceConnectionFactory(config);
}
@Bean("redisStreamConnectionFactory")
public RedisConnectionFactory redisStreamConnectionFactory(RedisStreamProperties props) {
RedisStandaloneConfiguration config = new RedisStandaloneConfiguration(props.getHost(), props.getPort());
config.setPassword(props.getPassword());
return new LettuceConnectionFactory(config);
}
@Bean("redisCacheTemplate")
public StringRedisTemplate redisCacheTemplate(
@Qualifier("redisCacheConnectionFactory") RedisConnectionFactory factory) {
return new StringRedisTemplate(factory);
}
@Bean("redisStreamTemplate")
public StringRedisTemplate redisStreamTemplate(
@Qualifier("redisStreamConnectionFactory") RedisConnectionFactory factory) {
return new StringRedisTemplate(factory);
}
}StreamsConfig
@Slf4j
@Configuration
public class StreamConfig {
@Bean
public StreamMessageListenerContainer<String, MapRecord<String, String, String>>
streamListenerContainer(
@Qualifier("redisStreamConnectionFactory")
RedisConnectionFactory factory
) {
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, MapRecord<String, String, String>>
options = StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder()
.pollTimeout(Duration.ofSeconds(1))
.build();
StreamMessageListenerContainer<String, MapRecord<String, String, String>> container =
StreamMessageListenerContainer.create(factory, options);
// Consumers are now managed dynamically by ConferenceStreamManager.
// We only start the container here.
container.start();
return container;
}
}저는 Consumer Group을 동적으로 할당하기 위해 위와 같이 설정해두었습니다.
CacheConfig
@Configuration
public class CacheConfig {
@Bean
public RedisMessageListenerContainer pubSubContainer(
@Qualifier("redisCacheConnectionFactory")
RedisConnectionFactory factory,
MessageListenerAdapter subscriber
) {
RedisMessageListenerContainer container =
new RedisMessageListenerContainer();
container.setConnectionFactory(factory);
container.addMessageListener(subscriber, new PatternTopic("conference:*"));
return container;
}
@Bean
public MessageListenerAdapter subscriber(CacheSubscriber subscriber) {
return new MessageListenerAdapter(subscriber, "onMessage");
}
}이후 Streams의 Producer와 Consumer, Pub/Sub의 Publisher와 Subscriber로직은 각자에 맞는 방식으로 구현하면 됩니다.
물론 설정도 각자에 맞게 하는 것이지만요.
결론
Kafka의 명성에 가려져 주목받지 못하는 Redis streams를 상황에 맞게 적절히 선택하여 사용해보기에 충분히 매력적인 기술이라고 생각합니다.
1년차 주니어가 실제 사례로 보여주는 기술적 의사결정 과정에서 설명했다시피, 모든 기술 결정에는 근거가 필요하다고 생각합니다.
모든 기술 좋고 유행한다고 쓰는 것이 아니라 필요 여부에 따라 명확하게 나누어 오버테크놀로지를 경계하고 적합한 기술을 채택하는 것이 중요한 역량 중 하나라고 생각합니다.
피드백은 언제나 환영입니다 :)
