Redshift 권한과 보안
관한과 보안이란 측면에서 Redshift가 제공해주는 기능을 알아보자. AWS의 IAM Role을 사용해보자.
사용자별 테이블 권한 설정
- 일반적으로 사용자별 테이블별 권한 설정은 하지 않음
- 너무 복잡하고 실수의 가능성이 높음
- 역할 (Role) 혹은 그룹(Group) 별로 스키마별 접근 권한을 주는 것이 일반적
- RBAC(Role Based Access Control)가 새로운 트렌드 : 그룹 보다 더 편리
- 여러 역할에 속한 사용자의 경우는 각 역할의 권한을 모두 갖게 됨 (Inclusive)
- 새로운 역할에 원래 있던 특정 역할의 권한을 한번에 부여할 수 있음
- 개인정보와 관련한 테이블들이라면 별도 스키마 설정
- 극히 일부 사람만 속한 역할에 접근 권한을 줌
- 뒤의 예는 그룹에 적용했지만 GROUP이란 키워드를 ROLE로 바꾸어도 동작
사용자 그룹 권한 설정
- 앞서 생성한 그룹들의 권한을 아래처럼 설정하고 싶음
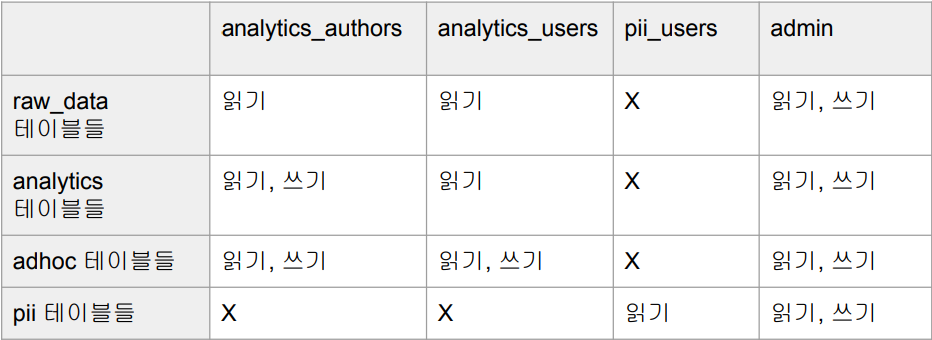
analytics_authors 권한 설정
GRANT ALL ON SCHEMA analytics TO GROUP analytics_authors;
-- analytics 스키마에 대해선 모든 권한을 준다.
GRANT ALL ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_authors;
-- analytics 스키마의 모든 테이블에 대해선 모든 권한을 준다.
GRANT ALL ON SCHEMA adhoc to GROUP analytics_authors;
GRANT ALL ON ALL TABLES IN SCHEMA adhoc TO GROUP analytics_authors;GRANT USAGE ON SCHEMA raw_data TO GROUP analytics_authors;
-- SELECT(읽기) 권한만 주기 위해선 USAGE 권한만 준다.
GRANT SELECT ON ALL TABLES IN SCHEMA raw_data TO GROUP analytics_authors;
-- 모든 테이블에 대해서 SELECT 권한을 준다.analytics_users 권한 설정
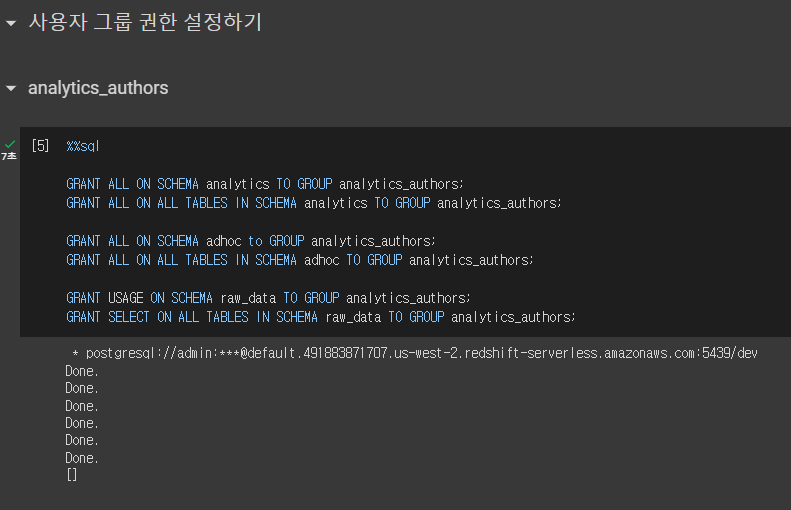
GRANT USAGE ON SCHEMA analytics TO GROUP analytics_users;
GRANT SELECT ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_users;
-- 읽기 권한만 부여한다.GRANT ALL ON ALL TABLES IN SCHEMA adhoc TO GROUP analytics_users;
GRANT ALL ON SCHEMA adhoc to GROUP analytics_users;
-- 모든 권한을 부여한다.GRANT USAGE ON SCHEMA raw_data TO GROUP analytics_users;
GRANT SELECT ON ALL TABLES IN SCHEMA raw_data TO GROUP analytics_users;
-- 읽기 권한만 부여한다.pii_users 권한 설정
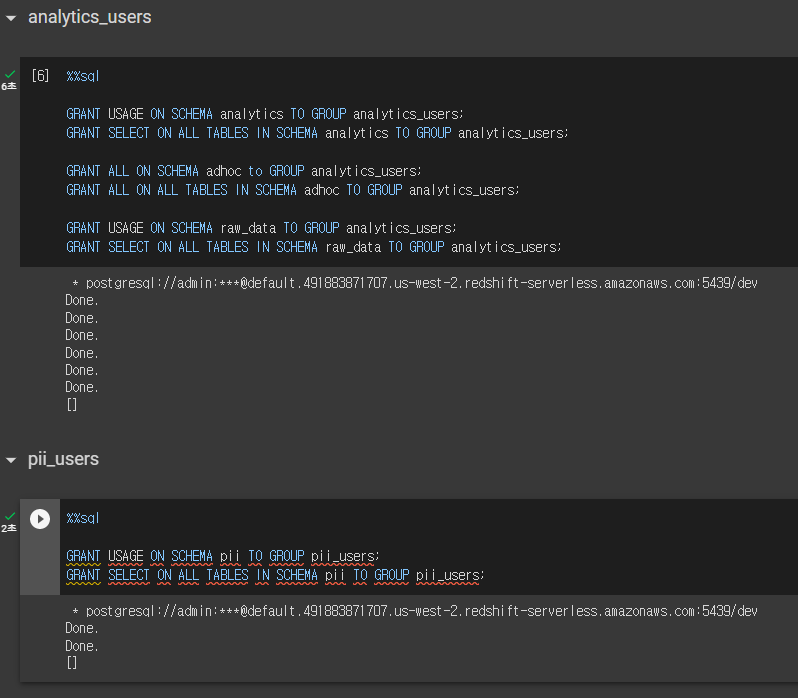
GRANT USAGE ON SCHEMA pii TO GROUP pii_users;
GRANT SELECT ON ALL TABLES IN SCHEMA pii TO GROUP pii_users;
-- 개인정보 스키마이므로 해당 그룹에 SELECT 권한만 부여한다.- 역할을 이용하면 개승구조를 통해 더 쉽게 권한을 부여할 수 있다.
컬럼 레벨 보안 (Column Level Security)
- 테이블내의 특정 컬럼(들)을 특정 사용자나 특정 그룹/역할에만 접근 가능하게 하는 것
- 좋은 방법은 아님.
- 보통 개인정보 등에 해당하는 컬럼을 권한이 없는 사용자들에게 감추는 목적으로 사용됨(사용자 테이블의 민감한 개인정보(주소, 주민번호 등) 컬럼)
- 사실 가장 좋은 방법은 아예 그런 컬럼을 별도 테이블로 구성하는 것임
- 더 좋은 방법은 보안이 필요한 정보를 아예 데이터 시스템으로 로딩하지 않는 것임
레코드 레벨 보안 (Row Level Security)
- 테이블내의 특정 레코드(들)을 특정 사용자나 특정 그룹/역할에만 접근 가능하게 하는 것
- 이 또한 좋은 방법이 아님.
- 특정 사용자/그룹의 특정 테이블 대상 SELECT, UPDATE, DELETE 작업에 추가 조건을 다는 형태로 동작
- 이를 RLS (Record Level Security) Policy라고 부름
CREATE RLS POLICY명령을 사용하여 Policy를 만들고 이를ATTACH RLS POLICY명령을 사용해 특정 테이블에 추가함
- 일반적으로 더 좋은 방법은 아예 별도의 테이블로 관리하는 것임
- 다시 한번 더 좋은 방법은 보안이 필요한 정보를 아예 데이터 시스템으로 로딩하지 않는 것임
실습
- 그룹 권한 설정 실습
- 없는 권한 사용시 에러 확인
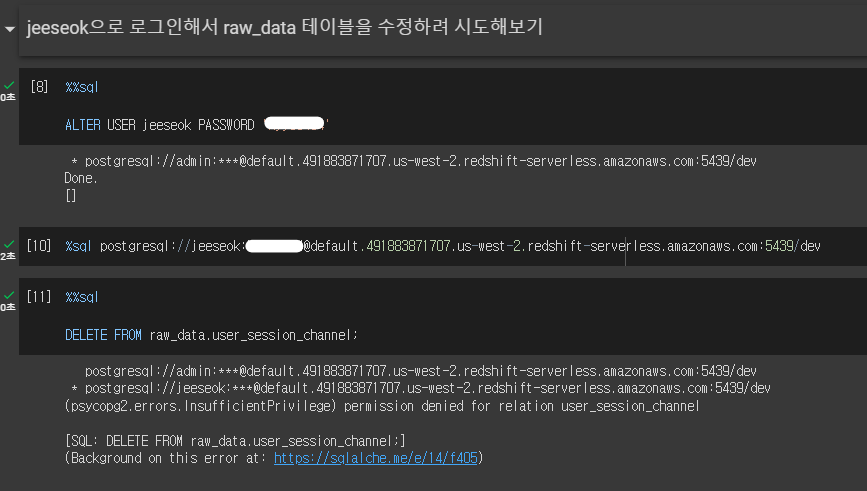
- ALTER USER 명령어를 사용하여 비밀번호를 변경할 수 있다.
- jeeseok 계정으로 들어가서 DELETE를 하려고 하면 권한이 없어서 에러를 확인할 수 있다.
Redshift 백업과 테이블 복구
Redshift가 제공하는 Snapshot 백업 기능과 이를 이용한 테이블 복구 기능에 대해 알아보자
Redshift가 지원하는 데이터 백업 방식
- 기본적으로 백업 방식은 마지막 백업으로부터 바뀐 것들만 저장하는 방식
(백업 크기가 그렇게 크지 않음)- 이를 Snapshot이라고 부름
- 백업을 통해 과거로 돌아가 그 시점의 내용으로 특정 테이블을 복구하는 것이 가능 (Table Restore)
- 또한 과거 시점의 내용으로 Redshift 클러스터를 새로 생성하는 것도 가능
- 자동 백업:
- 기본은 하루이지만 최대 과거 35일까지의 변경을 백업하게 할 수 있음.
- 이 경우 백업은 같은 지역에 있는 S3에 이뤄짐.
- 다른 지역에 있는 S3에 하려면 Cross-regional snapshot copy를 설정해야함. 이는 보통 재난시 데이터 복구에 유용함
- 매뉴얼 백업:
- 언제든 원할 때 만드는 백업으로 명시적으로 삭제할 때까지 유지됨
(혹은 생성시 보존 기한 지정)
- 언제든 원할 때 만드는 백업으로 명시적으로 삭제할 때까지 유지됨
자동 백업
- 기본 1일 보관에서 35일까지 늘리고 싶다면?
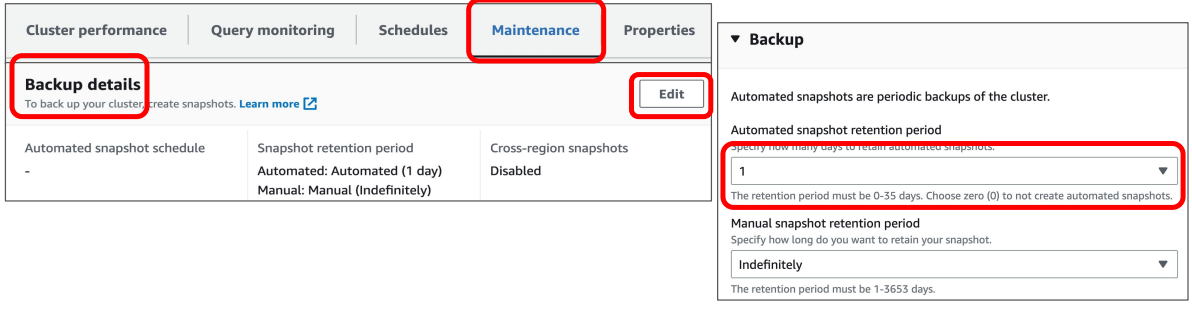
- 관련 Redshift 클러스터의 Maintenance 탭 -> Backup details -> Edit
- 드롭다운박스에서 원하는 보관일수 선택
매뉴얼 백업
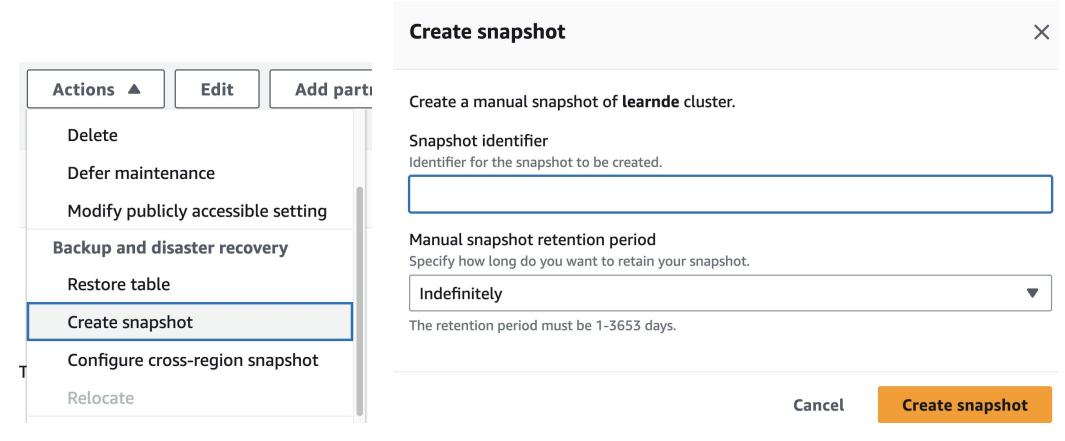
- 필요시 스냅샷 생성하기
- configure cross-region snapshot을 통해 다른 지역에 스냅샷을 만들 수 있음.
백업에서 테이블 복구
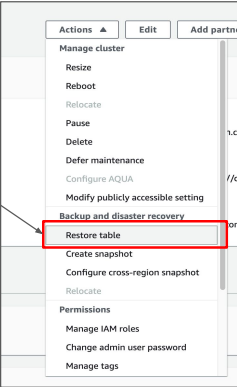
1. 해당 Redshift 클러스터에서 “Restore table” 메뉴 선택
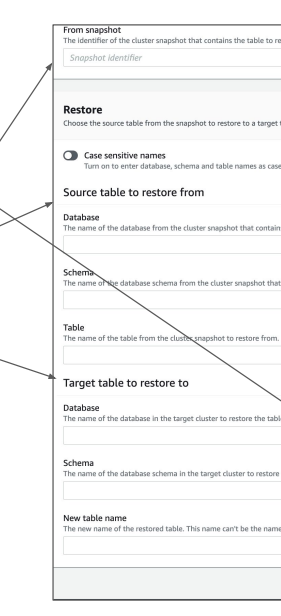
- 복구 대상이 있는 백업(Snapshot) 선택
- 원본 테이블 (Source table) 선택
- 어디로 복구될지 타켓 테이블 선택
Redshift Serverless가 지원하는 데이터 백업 방식
- 고정비용 Redshift에 비하면 제한적이고 조금 더 복잡함
- 고정비용은 컴퓨팅 자원과 스토리지 자원을 돈을 내고 고객에게 할당하는 방식
- 정해진 스토리지가 있어서 바로바로 스냅샷을 잡을 수 있다.
- 가변 비용에서는 컴퓨팅 자원과 스토리지 자원이 별개로 존재.
- 특정 지점에서 스냅샷을 잡는 것은 불가능하다.
- 일단 Snapshot 이전에 Recovery Points라는 것이 존재
- Recovery Point를 Snapshot으로 바꾼 다음에 여기서 테이블 복구를 하거나 이것으로 새로운 Redshift 클러스터 등을 생성하는 것이 가능
- Recovery Points는 과거 24시간에 대해서만 저장하는 방식이다.
- 그래서 백업이 하루밖에 안됨.
정리
- 매뉴얼 스냅샷은 Serverless에서도 가능하다.
- 자동 백업 스냅샷은 recovery points를 사용해야하고 24시간밖에 안된다.
실습
- AWS Redshift 웹 콘솔에서 데모
- 고정 비용
- 가변 비용
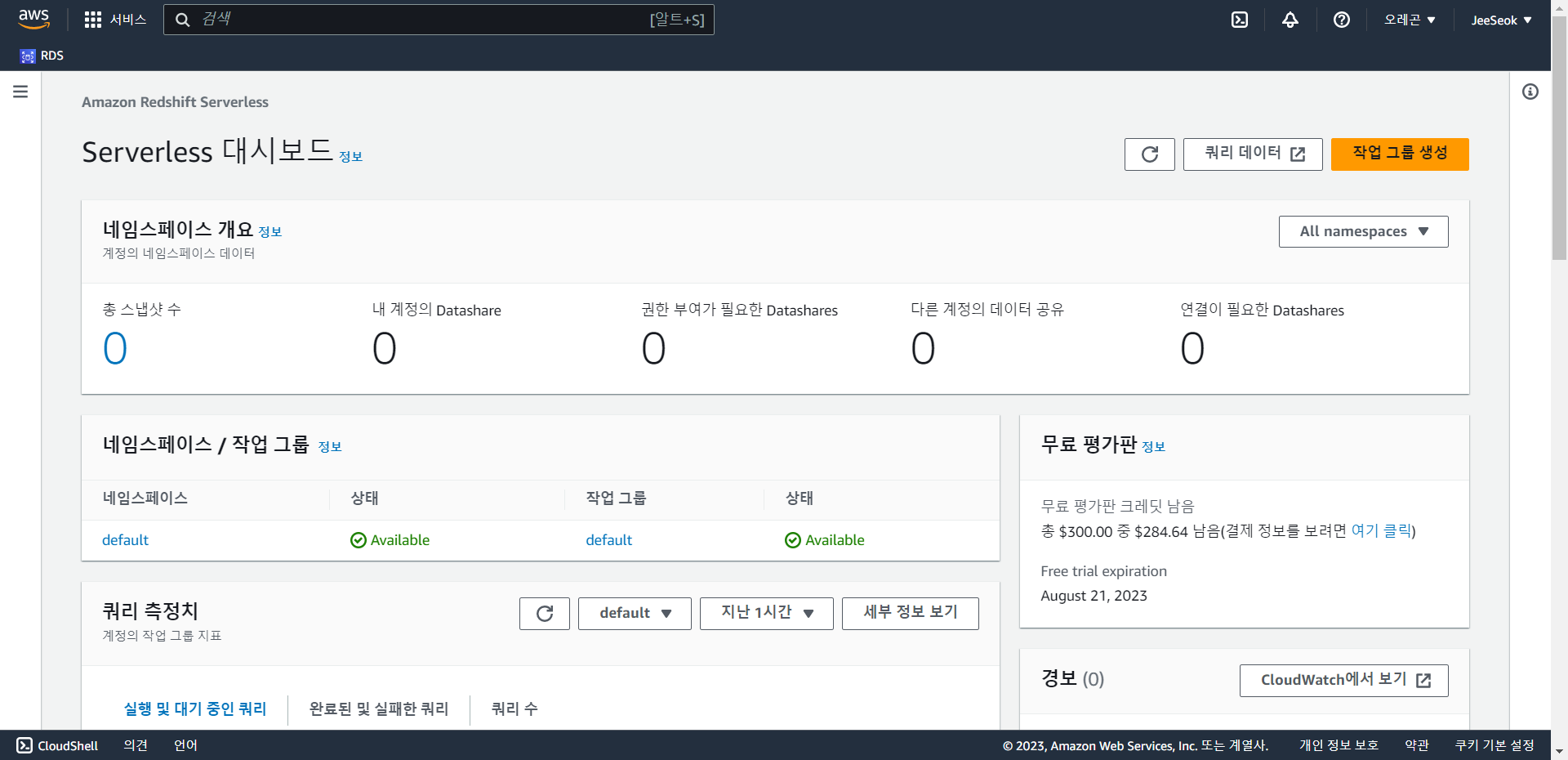
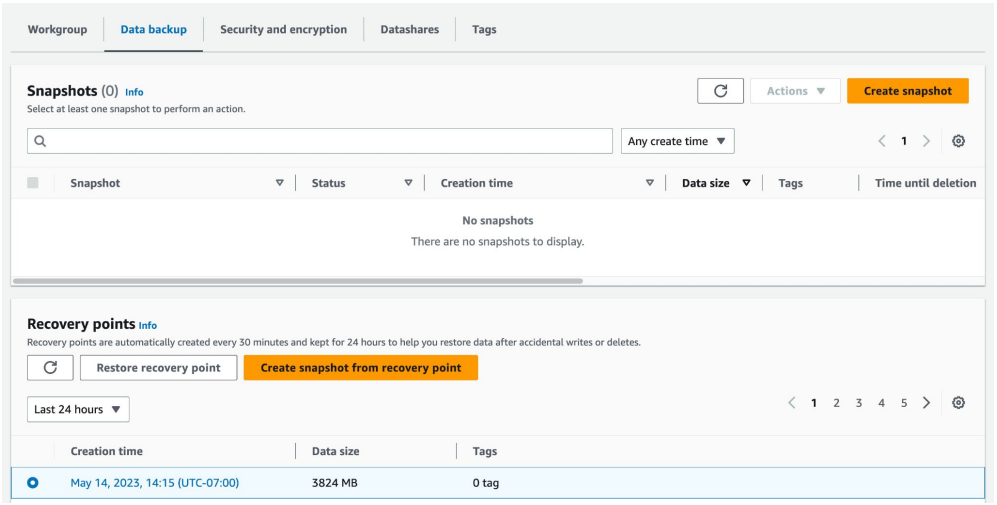
- 해당 Redshift Serverless에 들어와 default 네임스페이스에 들어간다.
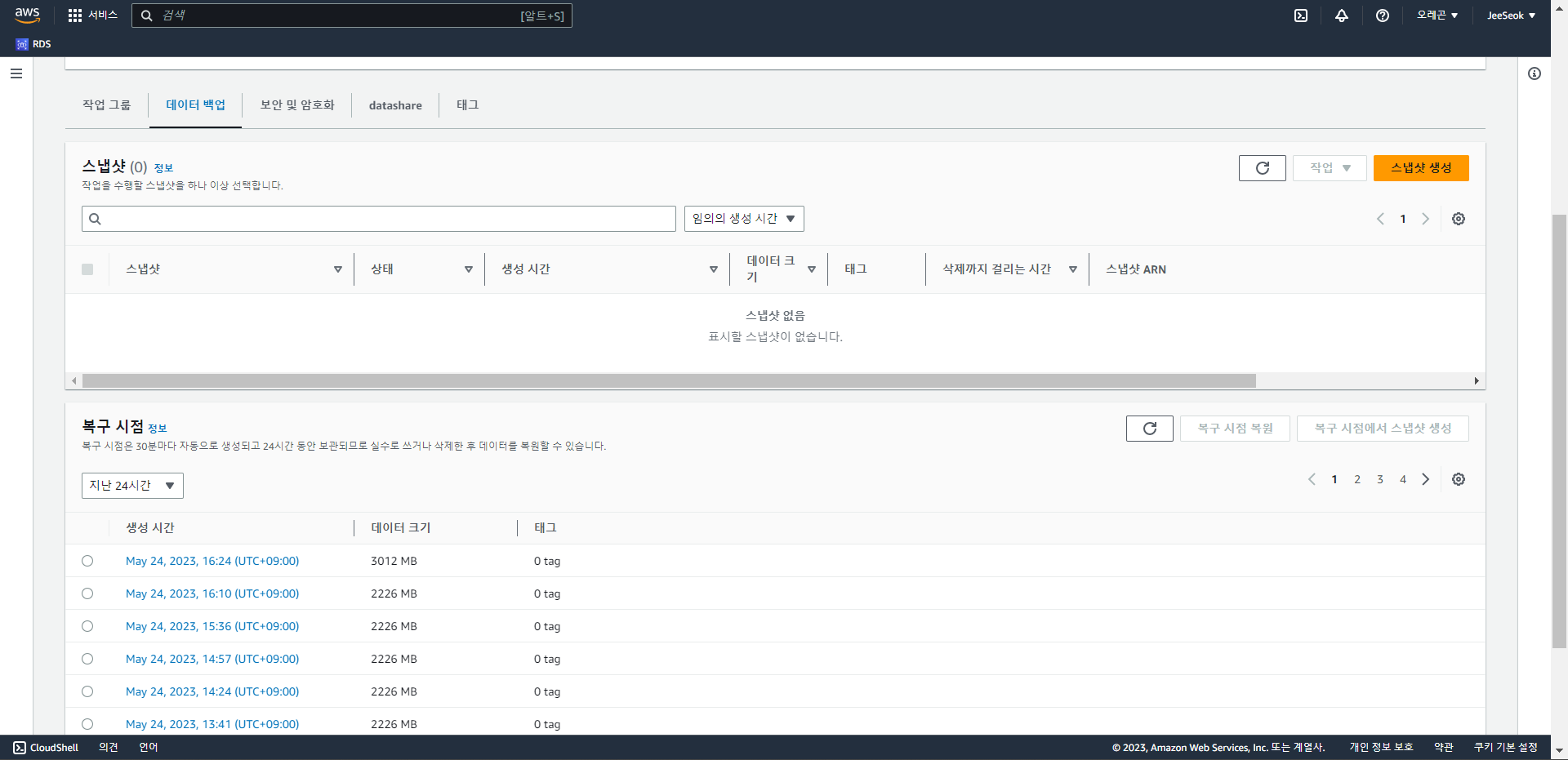
- 하단 메뉴에 데이터 백업에 들어가면 스냅샷들과 Recovery Points들을 확인할 수 있다.
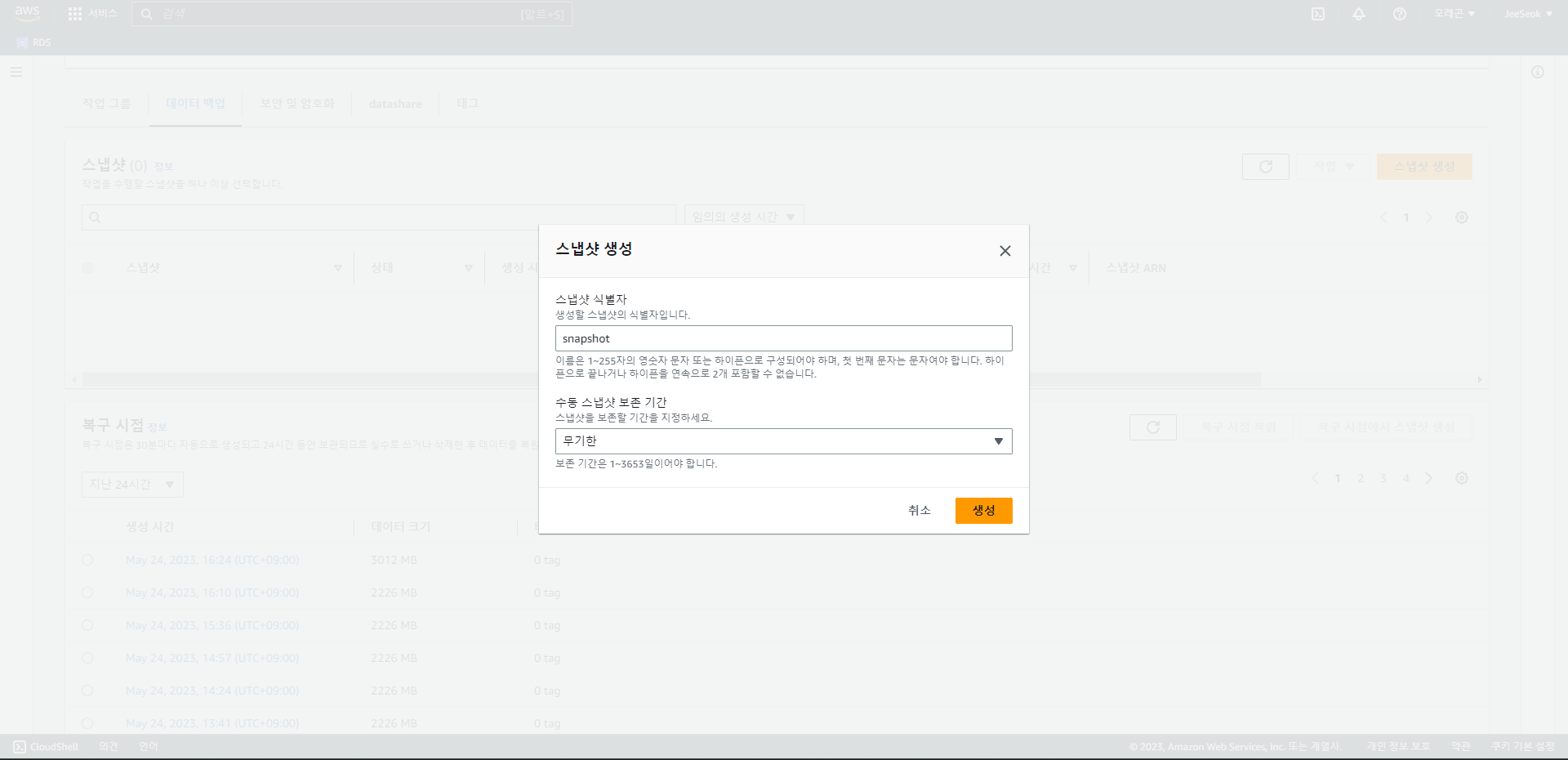
- 스냅샷 생성을 통해 매뉴얼 스냅샷을 생성할 수 있으며 보존 기간 또한 설정 가능하다.
Redshift 관련 기타 서비스 소개
Redshift가 제공해주는 다른 기타 서비스들이 무엇이 있는지 살펴본다.
Redshift Spectrum

- Redshift의 확장 기능, 데이터 레이크에 있는 파일들을 처리할 수 있게 AWS에 구현한 것
- S3에 있는 파일들을 마치 테이블처럼 SQL로 처리 가능
- S3 파일들을 외부 테이블들(external table)로 처리하면서 Redshift 테이블과 조인 가능
- S3 외부 테이블들은 보통 Fact 테이블들이 되고 Redshift 테이블들은 Dimension 테이블
- 1TB를 스캔할 때마다 $5 비용이 생김
- 이를 사용하려면 Redshift 클러스터가 필요
- S3와 Redshift 클러스터는 같은 region에 있어야함
Redshift Serverless
- Redshift의 경우 용량을 미리 결정하고 월정액 (Fixed Cost) 지급 : 고정비용 옵션
- Redshift Serverless는 반대로 쓴만큼 비용을 지불하는 옵션 : 가변비용 옵션
- BigQuery와 같은 사용한 자원에 따른 비용 산정 방식
- 데이터 처리 크기와 특성에 따라 오토 스케일링이 적용됨
Athena
- AWS의 Presto 서비스로 사실상 Redshift Spectrum과 비슷한 기능을 제공
- AWS Redshift를 사용한다면 Redshift Spectrum을,
Redshift를 사용하지 않고 S3 데이터를 처리해야 하면 Athena를 사용한다. - S3에 있는 데이터들을 기반으로 SQL 쿼리 기능 제공
- 이 경우 S3를 데이터 레이크라 볼 수 있음

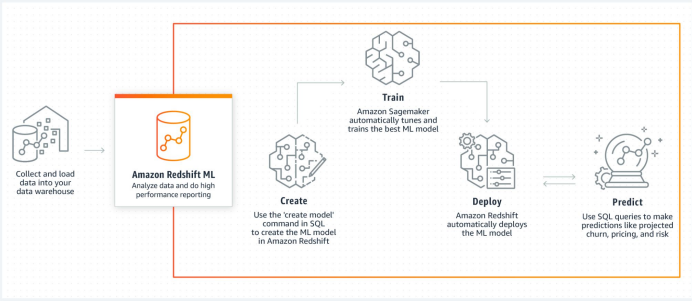
Redshift ML
- SQL만 사용하여 머신러닝 모델을 훈련하고 사용할 수 있게 해주는 Redshift 기능
- 이 기능은 사실 AWS SageMaker에 의해 지원됨
- SageMaker는 Auto Pilot이라 하여 최적화된 모델을 자동 생성해주는 기능 제공
- 지도학습에만 적용 (훈련대상과 예측값이 있을 때)
- Classification, Regression 등을 정해준다.
- 이미 모델이 만들어져 있다면 이를 사용하는 것도 가능 (BYOM: Bring Your Own Model)
- 그 모델을 Redshift 안에 마치 SQL 함수처럼 임베딩하여 테이블 안에 있는 레코드들, 컬럼들을 머신러닝 모델의 input으로 넣으면 머신러닝의 결과(예측값)가 아웃풋으로 간편하게 나올 수 있다.
Redshift Spectrum으로 S3 외부 테이블 조작해보기
S3에 굉장히 큰 데이터가 있는데 이를 Redshift로 로딩하기가 버겁다면
이를 외부 테이블로 설정해서 Redshift에서 조작이 가능하다.
Fact 테이블과 Dimension 테이블
- Fact 테이블: 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이블 (굉장히 큰 데이터)
- 일반적으로 매출 수익, 판매량 또는 이익과 같은 사실 또는 측정 항목을 포함하며 비즈니스 결정에 사용
- Fact 테이블은 일반적으로 외래 키를 통해 여러 Dimension 테이블과 연결됨
- 보통 Fact 테이블의 크기가 훨씬 더 큼
- Dimension 테이블: Fact 테이블에 대한 상세 정보를 제공하는 테이블
- 고객, 제품과 같은 테이블로 Fact 테이블에 대한 상세 정보 제공
- Fact 테이블의 데이터에 맥락을 제공하여 사용자가 다양한 방식으로 데이터를 조각내고 분석 가능하게 해줌
- Dimension 테이블은 일반적으로 primary key를 가지며, fact 테이블의 foreign key에서 참조
- 보통 Dimension 테이블의 크기는 훨씬 더 작음
- Fact 테이블은 매우 크기에 데이터 웨어하우스에 로딩하는게 비용적으로, 시간적으로 손해가 크다.
- 따라서 S3같은 값이 싼 Storage에 저장해놓고 필요할 때마다 로딩해서 Redshift에 저장
Fact 테이블과 Dimension 테이블의 예
- Fact 테이블
- 앞서 사용했던 user_session_channel
- Dimension 테이블: 사용자나 채널에 대한 정보로 상대적으로 크기가 작음
- 앞서 존재하지 않았지만 user_session_channel 테이블에 사용된 사용자나 채널에 대한 정보
- user
- channel
- 앞서 존재하지 않았지만 user_session_channel 테이블에 사용된 사용자나 채널에 대한 정보
- Fact 테이블
- Order 테이블 : 사용자들의 상품 주문에 대한 정보가 들어간 테이블
- Dimension 테이블
- Product 테이블 : Order 테이블에 사용된 상품에 대한 정보
- User 테이블 : Order 테이블에서 상품 주문을 한 사용자에 대한 정보
Redshift Spectrum 사용 유스 케이스
- S3에 대용량 Fact 테이블이 파일(들)로 존재, Redshift에 소규모 Dimension 테이블이 존재
- Fact 테이블을 Redshift로 적재하지 않고 위의 두 테이블을 조인하고 싶다면?
-> 이 때 사용할 수 있는 것이 Redshift Spectrum- 이는 별도로 설정하거나 론치하는 것이 아니라 Redshift의 확장 기능으로 사용하고 그만큼 비용 부담(1TB 스캔하는데 $5 정도 지불하면 됨)
외부 테이블(External Table)이란?
- 데이터베이스 엔진이 외부에 저장된 데이터를 마치 내부 테이블처럼 (읽기 전용으로)사용하는 방법
- 외부 테이블은 외부(보통 S3와 같은 클라우드 스토리지)에 저장된 대량의 데이터를 데이터베이스 내부로 복사하고 쓰는 것이 아니라 임시 목적으로 사용하는 방식
- SQL 명령어로 데이터베이스에 외부 테이블 생성 가능 :
CREATE EXTERNAL TABLE- 이 경우 데이터를 새로 만들거나 하는 것이 아니라 참조만 하게 됨
- 외부 테이블은 CSV, JSON, XML과 같은 파일 형식 뿐만 아니라 ODBC 또는 JDBC 드라이버를 통해 액세스하는 원격 데이터베이스와 같은 다양한 데이터 소스에 대해 사용 가능
- 외부 테이블을 사용하여 데이터 처리 후 결과를 데이터베이스에 적재하는데 사용 가능
- 예를 들어, 외부 테이블을 사용하여 로그 파일을 읽고 정제된 내용을 데이터베이스 테이블에 적재 가능
- 외부 테이블은 보안 및 성능 문제에 대해 신중한 고려가 필요
- 이는 Hive등에서 처음 시작한 개념으로 이제는 대부분의 빅 데이터 시스템에서 사용됨
Redshift Spectrum 사용 방식
- S3에 있는 파일들을 마치 테이블처럼 SQL로 처리 가능
- S3 파일들을 외부 테이블들(external table)로 처리하면서 Redshift 테이블과 조인 가능
- S3 외부 테이블들은 보통 Fact 테이블들이 되고
Redshift 테이블들은 Dimension 테이블이 됨
- 이를 사용하려면 Redshift 클러스터가 필요
- S3와 Redshift 클러스터는 같은 region에 있어야함
- S3 Fact 데이터를 외부 테이블(External Table)로 정의해야함
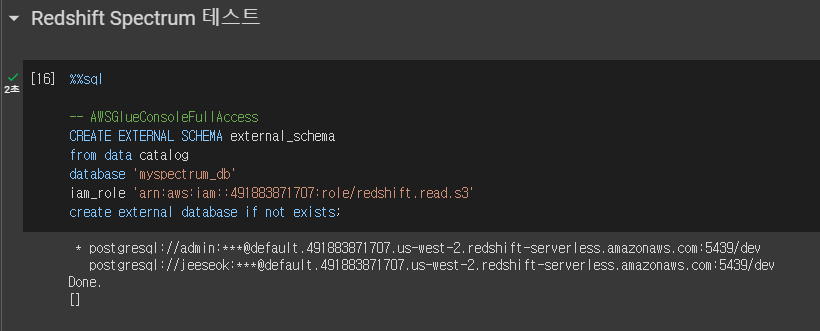
Redshift Spectrum 실습을 위한 외부 테이블 용 스키마 설정
- 먼저 앞서 만든 redshift.read.s3 ROLE에 AWSGlueConsoleFullAccess 권한
지정이 필요 - 다음으로 아래 SQL을 실행하여 외부 테이블용 스키마 생성
CREATE EXTERNAL SCHEMA external_schema
from data catalog
database 'myspectrum_db' -- 외부 DB를 정의
iam_role 'arn:aws:iam::521227329883:role/redshift.read.s3'
create external database if not exists; -- 생성된 적이 없으면 동시에 생성까지 해준다.잠깐 AWS Glue란 무엇인가?
- AWS Glue는 AWS의 Serverless ETL 서비스로 아래와 같은 기능 제공 (Airflow 비슷)
- AWS Glue로 만든 기능은 AWS 안에서는 가장 최적화 됐다.
- 데이터 카탈로그:
- AWS Glue Data Catalog는 데이터 소스 및 대상의 메타데이터 를 대상으로 검색 기능을 제공. 이는 주로 S3나 다른 AWS 서비스 상의 데이터 소스를 대상으로 함 (Redshift Spectrum의 경우에는 외부 테이블를 정의하는 순간 그 정보가 AWS Glue Data Catalog에도 저장되어야 함)
- ETL 작업 생성: AWS Glue Studio
- 간단한 드래그 앤 드롭 인터페이스를 통해 ETL 작업 생성 가능
- 사용자는 데이터 소스 및 대상을 선택하고 데이터 변환 단계를 정의하는 스크립트 생성
- 작업 모니터링 및 로그:
- AWS Glue 콘솔을 통해 사용자는 ETL 작업의 실행 상태 및 로그를 모니터링 가능
- 서버리스 실행:
- AWS Glue는 서버리스 아키텍처를 사용하므로 사용자는 작업을 실행하는 데 필요한 인프라를 관리할 필요가 없음 (Auto Scaling)
Redshift Spectrum 실습을 위한 외부 Fact 테이블 정의
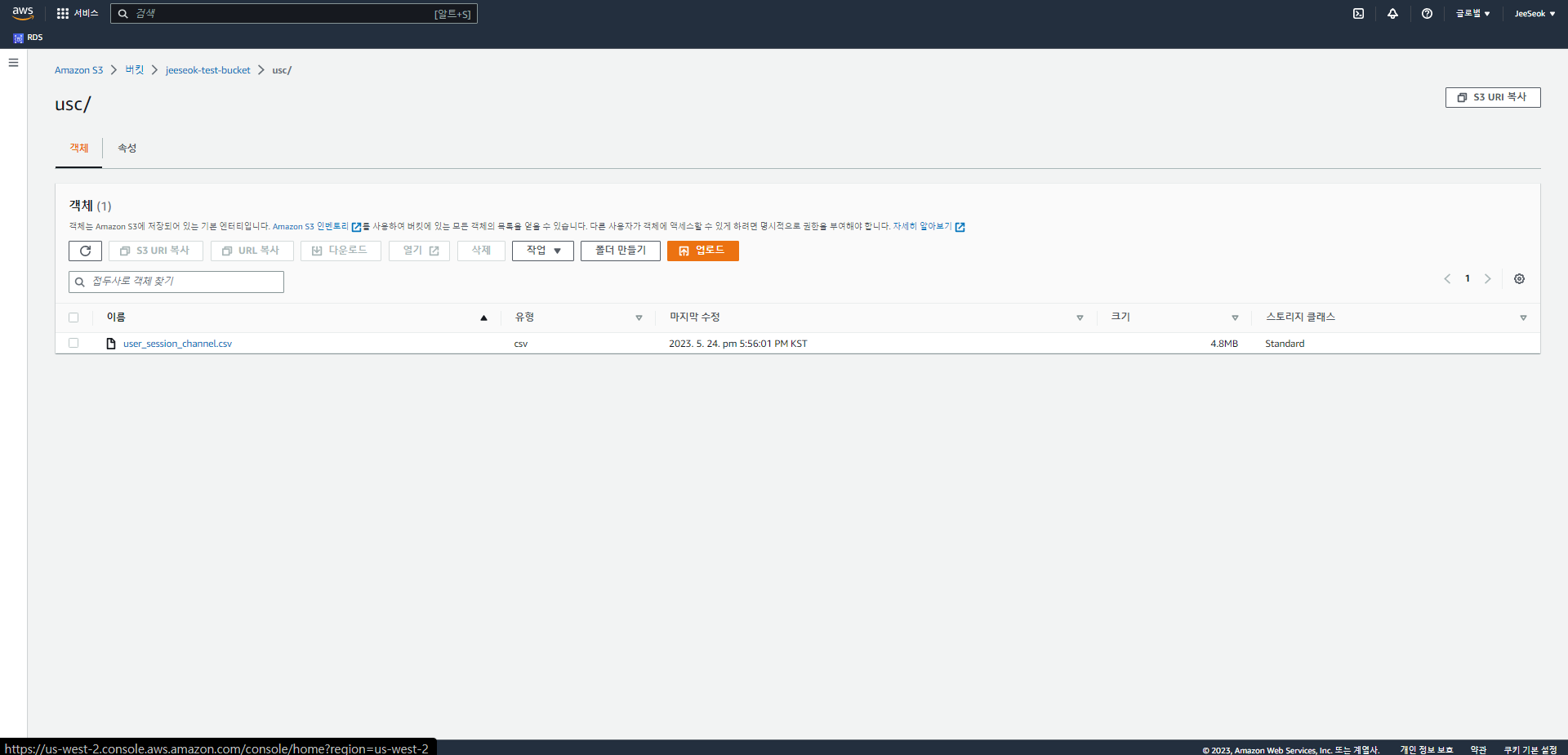
- S3에 usc라는 폴더를 각자 S3 버킷 밑에 만들고
- 그 폴더로 user_session_channel.csv 파일을 복사
- 다음으로 아래 SQL을 실행 (이런 형태의 명령은 Hive/Presto/SparkSQL에서 사용됨)
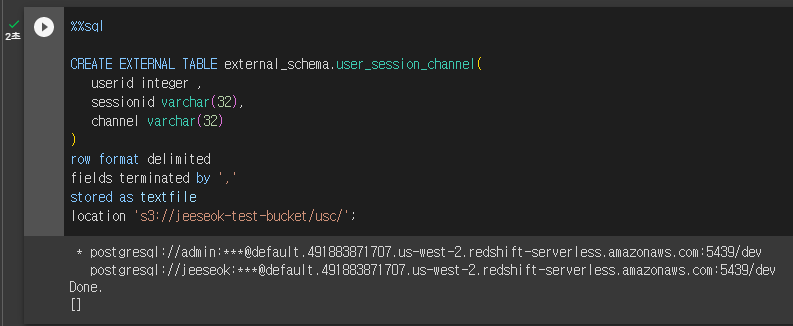
CREATE EXTERNAL TABLE external_schema.user_session_channel (
userid integer ,
sessionid varchar(32),
channel varchar(32)
)
row format delimited -- 한줄이 한 레코드에 해당
fields terminated by ',' -- csv 파일이므로 , 기준으로 구분한다
stored as textfile -- 텍스트 파일로 저장되어있다.
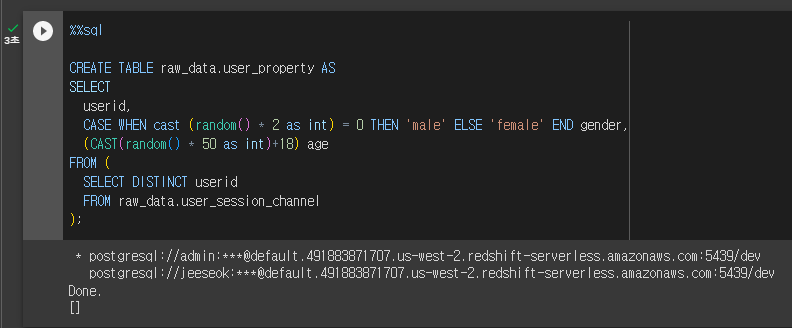
location 's3://jeeseok-test-bucket/usc/'; -- 파일이 들어있는 위치Redshift Spectrum 실습을 위한 내부 Dimension 테이블
- 테스트를 위해 user 테이블을 하나 raw_data 스키마 밑에 생성
CREATE TABLE raw_data.user_property AS
SELECT
userid,
CASE WHEN cast (random() * 2 as int) = 0 THEN 'male' ELSE 'female' END gender,
-- 성별을 랜덤으로 설정
(CAST(random() * 50 as int)+18) age
-- 나이도 랜덤으로 설정
FROM (
SELECT DISTINCT userid
FROM raw_data.user_session_channel
);Redshift Spectrum Fact + Dimension 테이블 조인
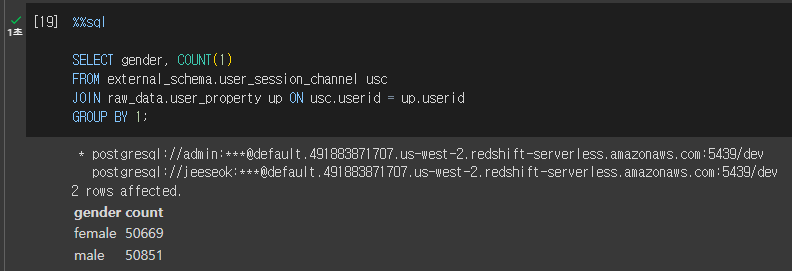
SELECT gender, COUNT(1)
FROM external_schema.user_session_channel usc
JOIN raw_data.user_property up ON usc.userid = up.userid
GROUP BY 1;실습
- 외부 테이블용 스키마 생성
- 내부 Dimension 테이블 생성
- Redshift의 S3 접근용 IAM Role에 권한 추가 (AWSGlueConsoleFullAccess)
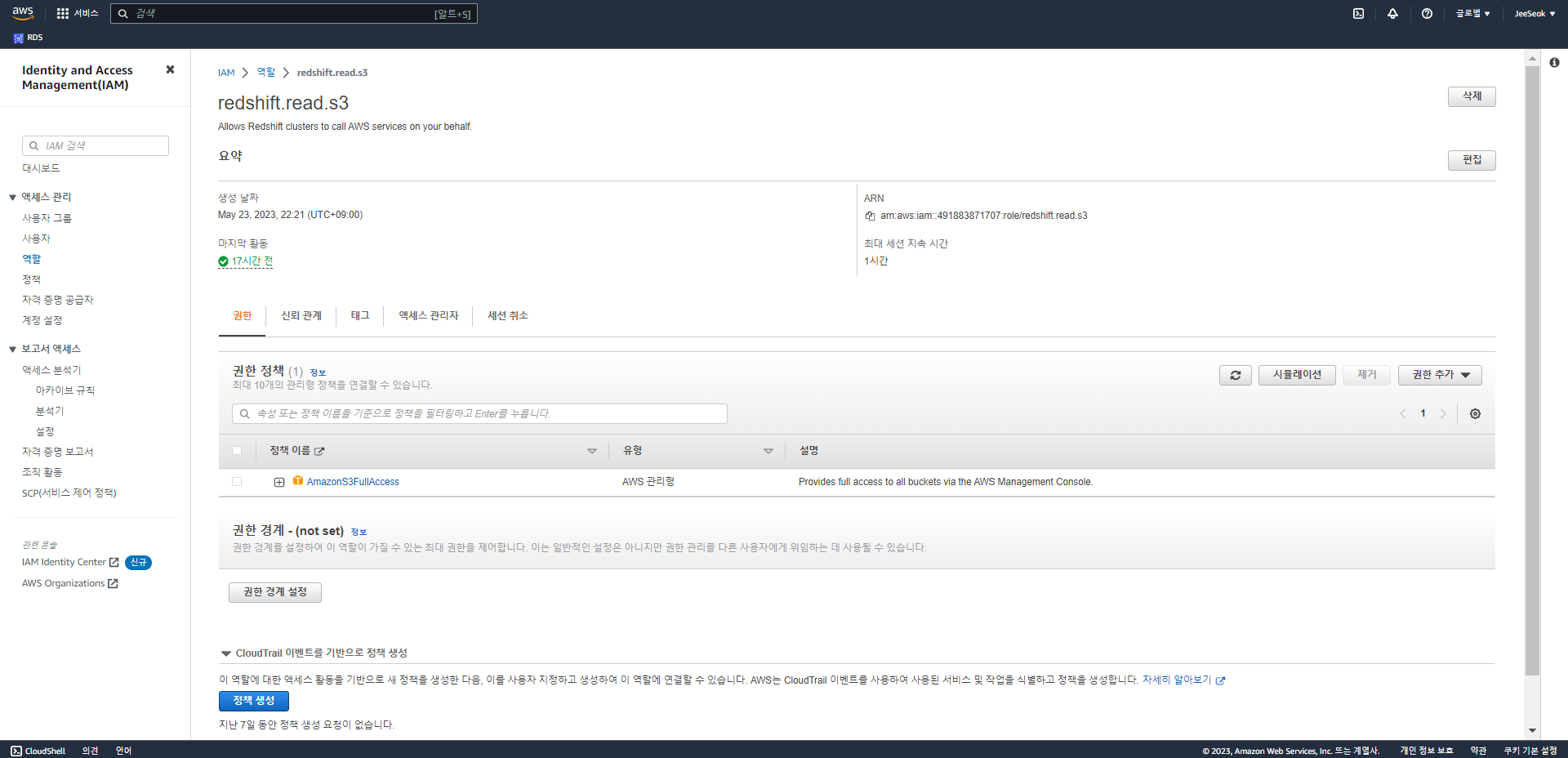
- 권한 추가 눌러서 정책 연결에 들어간다.
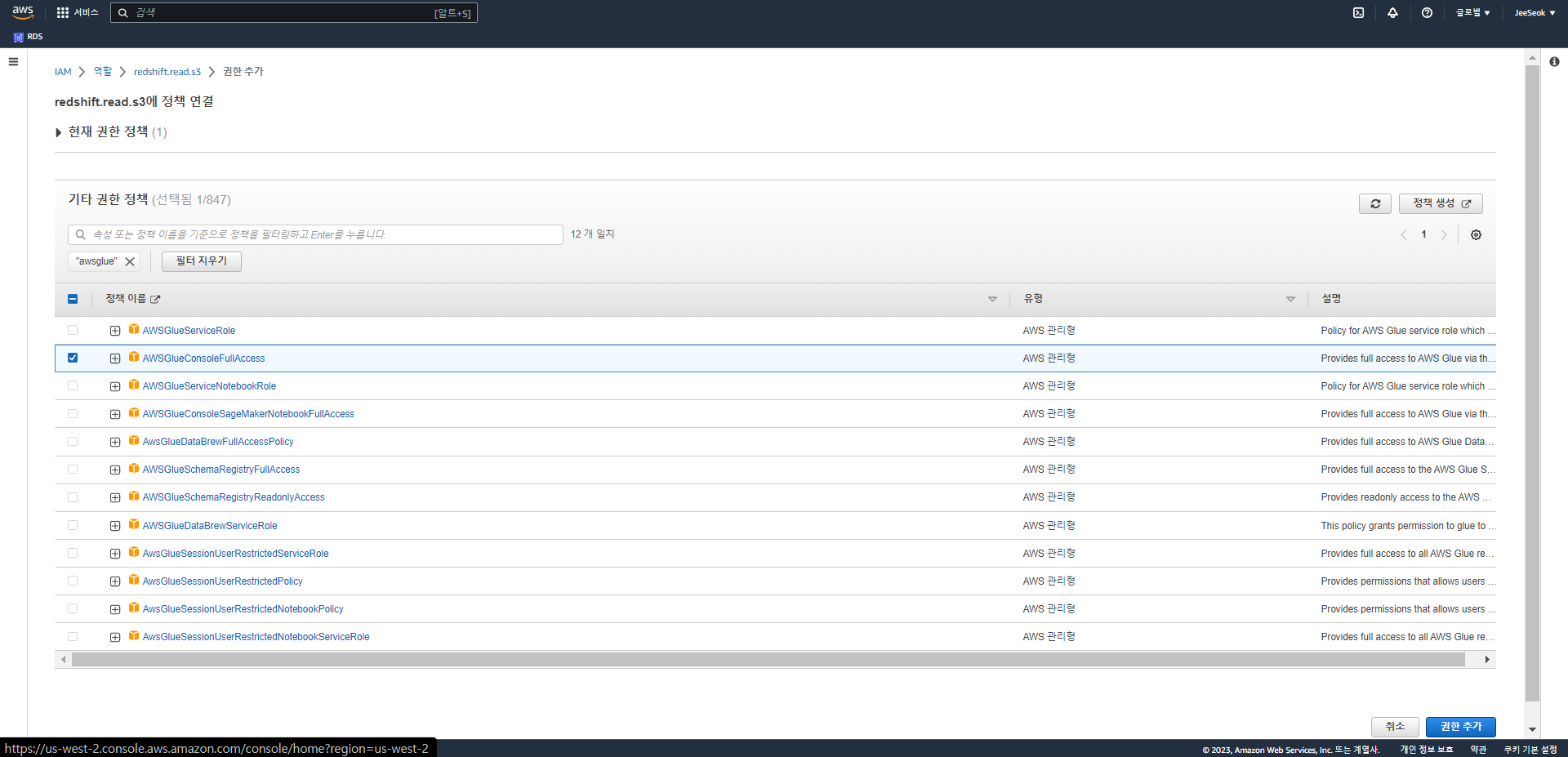
-
해당 권한을 찾아서 추가한다. (AWSGlueConsoleFullAccess)
- S3 버킷에 새 폴더 만들고 user_session_channel.csv 파일 업로드
- 위 파일을 바탕으로 외부 테이블 생성
- 내부 테이블과 외부 테이블 조인
Redshift ML 사용하기
Redshift ML을 사용하여 간단하게 ML 모델을 하나 생성해보기
머신러닝의 정의
- 배움이 가능한 기계(혹은 알고리즘)의 개발
- 결국 데이터의 패턴을 보고 흉내(imitation)내는 방식으로 학습
- 학습에 사용되는 이 데이터를 트레이닝셋 (training set)이라고 부름
- 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
- 딥러닝(신경망의 다른 이름)은 머신 러닝의 일부
- 비젼, 자연언어처리 (텍스트/오디오)등에 적용되고 있음
- 인공지능은 머신러닝을 포괄하는 개념
머신러닝 모델
- 머신 러닝의 최종 산물이 머신 러닝 모델
- 학습된 패턴(트레이닝셋)에 따라 예측을 해주는 블랙박스
- 선택한 머신러닝 학습 알고리즘에 따라 내부가 달라짐
(딥러닝, Linear Regression, Logistic Regression, Decision Tree 등) - 디버깅은 쉽지 않으며 왜 동작하는지 이유를 설명하기도 쉽지 않음
(딥러닝 / 상대적으로 이해하기 쉬운 것 : Linear Regression, Decision Tree - 트레이닝셋의 품질이 머신러닝 모델의 품질을 결정
(트레이닝 셋에 bias가 있으면 모델에도 bias가 생김)
- 선택한 머신러닝 학습 알고리즘에 따라 내부가 달라짐
- 학습된 패턴(트레이닝셋)에 따라 예측을 해주는 블랙박스
- 입력 데이터를 주면 그를 기반으로 예측
- 정확히 이야기하자면 지도 머신러닝 (Supervised Machine Learning)
- 이외에도 2가지의 다른 머신러닝 방식이 존재
- 비지도 머신러닝(Unsupervised Machine Learning)
- 강화 학습 (Reinforcement Learning)
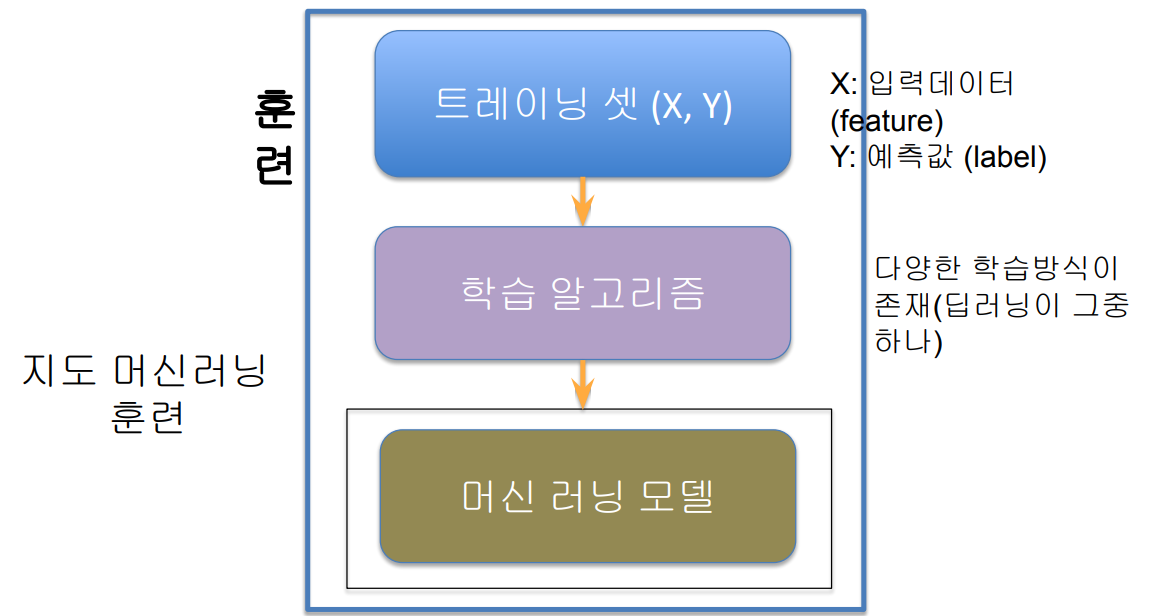
- 머신러닝 모델 트레이닝 혹은 빌딩이란?
- 이런 머신 러닝 모델을 만드는 것을 지칭
- 입력은 트레이닝셋
트레이닝셋 예시 - 타이타닉호 승객 생존 여부 예측
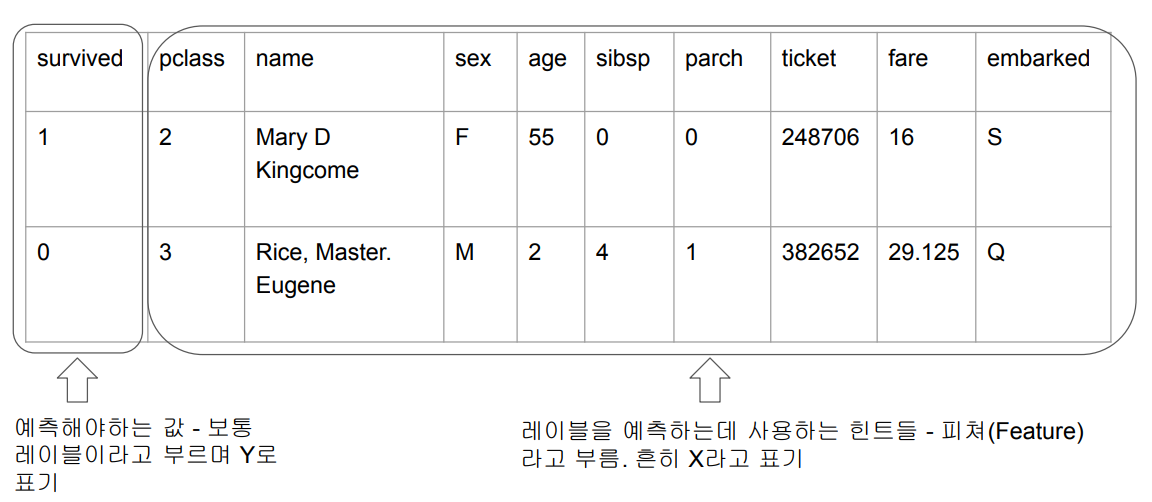
- 숫자가 아닌 값들은 생략하거나 숫자로 바꿔서 사용한다.
- 지정할 파라미터를 최대한 많은 조합들을 토대로 설정한다. 그렇게 성능을 평가한다.
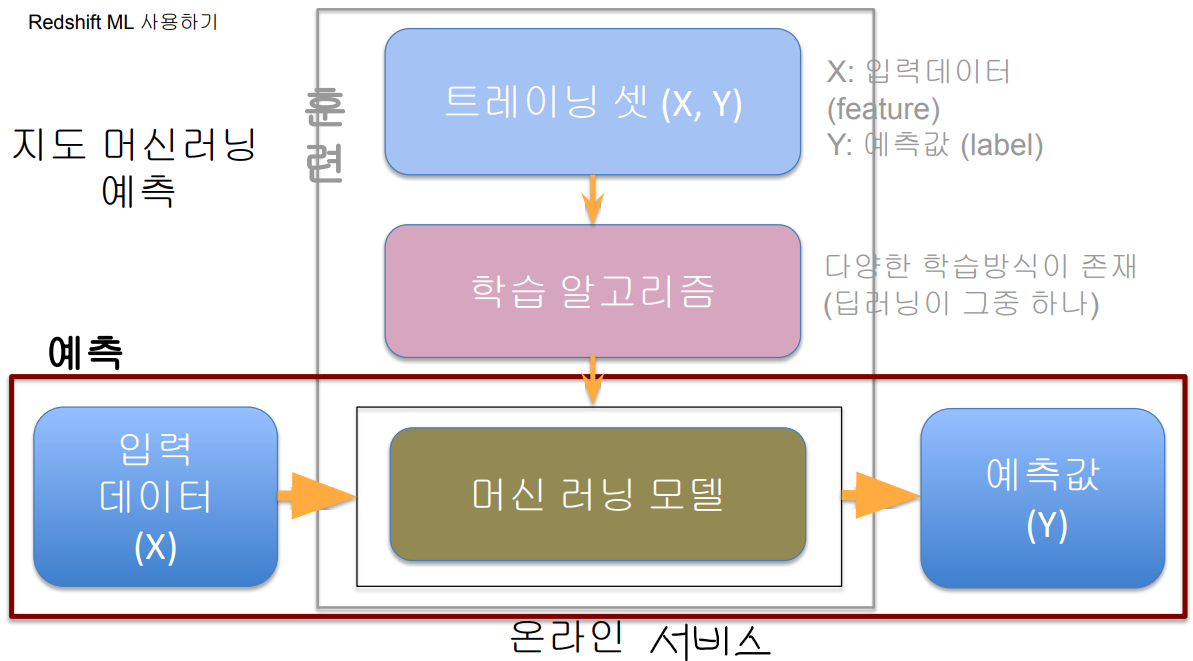
- 배포된 모델에 입력 데이터는 사용자의 과거 행동 및 개인 정보가 된다.
- 동일한 데이터를 학습 되었단 가정으로 예측값을 모델에서 만들어준다.
- 예측 대상이 binary 경우 Classification, 연속적인 값일 경우 Regression
Amazon SageMaker란?
- 머신러닝 모델 개발을 처음부터 끝까지 해결해주는 AWS 서비스
- MLOps 프레임웍
- 크게 4가지 기능 제공
- 트레이닝 셋 준비
- 모델 훈련 (머신러닝 모델 빌딩)
- 모델 검증 (fold-out, cross-validation)
- 모델 배포와 관리
- API 엔드포인트, 배치 서빙, …
- 다양한 머신러닝 프레임웍을 지원
- Tensorflow/Keras, PyTorch, MXNet, …
- 자체 SageMaker 모듈로 머신러닝 모델 훈련 가능
- SageMaker Studio라는 웹기반 환경 제공 (노트북)
- 다양한 개발방식 지원
- 기본적으로 Python Notebook (SageMaker 모듈을 import)을 통해 모델 훈련
- 스칼라/자바 SDK도 제공
- AutoPilot이라는 코딩 불필요 모델 훈련 기능 제공
- 이 경우에도 코드를 만들어줌
- 3~4시간정도 걸리며 비용도 비쌈
- 기본적으로 Python Notebook (SageMaker 모듈을 import)을 통해 모델 훈련
- 다른 클라우드 업체들도 비슷한 프레임워크 제공
SageMaker의 AutoPilot 소개
- AutoPilot: SageMaker에서 제공되는 AutoML 기능
- AutoML이란 모델빌딩을 위한 훈련용 데이터 셋을 제공하면 자동으로 모델을 만들어주는 기능
- AutoPilot은 훈련용 데이터 셋을 입력으로 다음을 자동으로 수행
- 먼저 데이터 분석(EDA: Exploratory Data Analysis)을 수행하고 이를 파이썬 노트북으로 만들어줌
- 다수의 머신 러닝 알고리즘과 하이퍼 파라미터의 조합에 대해 아래 작업을 수행
- 머신 러닝 모델을 만들고 훈련하고 테스트하고 테스트 결과를 기록
- 선택 옵션에 따라 모델 테스트까지 다 수행하기도 하지만 코드를 만드는 단계(노트북)로 마무리도 가능
- 즉 AutoPilot 기능을 통해 모델개발 속도를 단축하는 것이 가능
- 최종적으로 사용자가 모델을 선택 후 API로 만드는 것도 가능
- 여기에 로그를 설정할 수 있음 (전체 로깅이나 샘플 로깅 설정 가능)
전체적인 절차
- 캐글 Orange Telecom Customer Churn 데이터셋(회사 고객 이탈률 데이터) 사용
a. 여기에서 다운로드 받을 것 (File -> Download -> CSV)
b. 고객이 이탈할지 안할지를 예측한다. - 데이터 준비: 여기에 있는 csv 파일을 적당히 S3 버킷 아래 폴더로 업로드
a. s3://jeeseok-test-bucket/redshift_ml/train.csv - 위의 데이터를 raw_data.orange_telecom_customers로 로딩 (COPY, 벌크 업데이트)
- SageMaker 사용권한을 Redshift cluster에 지정해주어야함
a. 해당 IAM Role 생성 후 지정 (AmazonSageMakerFullAccess) - CREATE MODEL 명령을 사용
a. train 데이터의 80%로 훈련 example 데이터를 만들어서 모델을 만든다.
b. 모델을 생성하고 모델 사용시 호출할 SQL 함수도 생성
d. 이 때 SageMaker와 관련한 비용이 발생함을 유의 - Model SQL 함수를 사용해서 테이블상의 레코드들을 대상으로 예측 수행
a. 선정된 모델에 train 데이터의 나머지 20%를 test 데이터로 설정하고 입력한다. - 사용이 다 끝난 후 SageMaker와 관련한 리소스 제거
Orange Telecom Customer Churn 데이터 다운로드
- 21개의 컬럼과 3,333개의 레코드를 갖는 CSV 파일 : train.csv
- 20%의 레코드들은 Purpose 컬럼 값이 “Test”, 80%의 레코드들은 “Train”을 갖게 됨
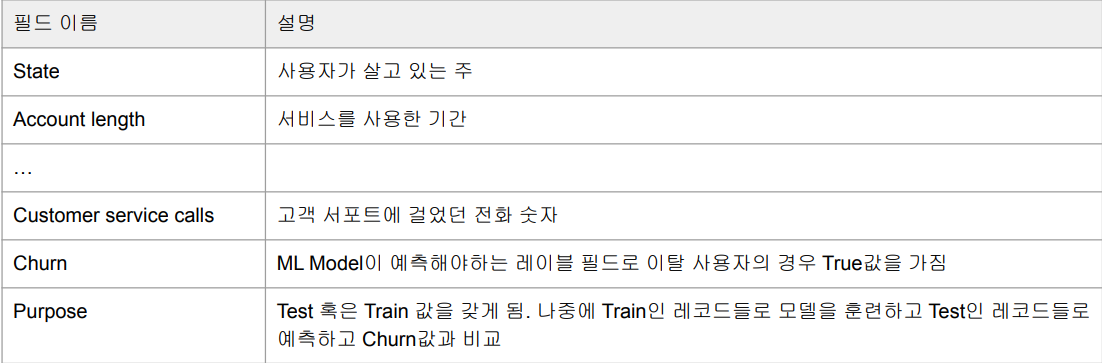
- 19개의 컬럼들이 예측을 하는데 필요한 힌트들이 될 것이며 어떤 컬럼들을 사용해야할 지는 data scientist의 몫이다.
train.csv를 S3 버킷 아래 redshift_ml 폴더 아래 업로드
- AWS S3 웹콘솔로 이동
- S3 버킷 아래 redshift_ml 폴더 생성
- 앞서 다운로드받은 train.csv 파일을 위 폴더로 업로드
a. s3://jeeseok-test-bucket/redshift_ml/train.csv
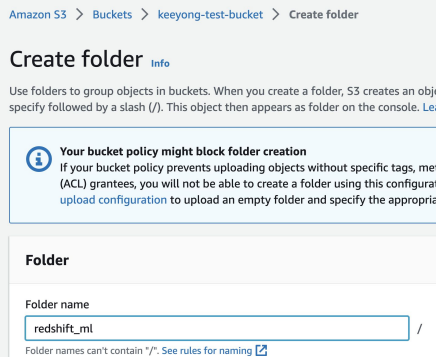
S3 train.csv를 raw_data.orange_telecom_customers로 로딩
CREATE TABLE raw_data.orange_telecom_customers (
state varchar,
account_length integer,
area_code integer,
international_plan varchar,
…
customer_service_calls integer,
churn varchar,
purpose varchar
);COPY raw_data.orange_telecom_customers
FROM 's3://jeeseok-test-bucket/redshift_ml/train.csv'
credentials 'aws_iam_role=arn:aws:iam::521227329883:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1
removequotes;SageMaker 사용권한을 Redshift cluster에 지정해주어야함
- 새 Role 생성
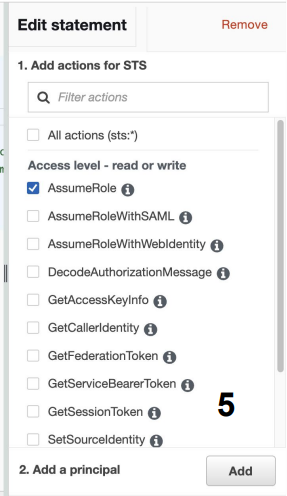
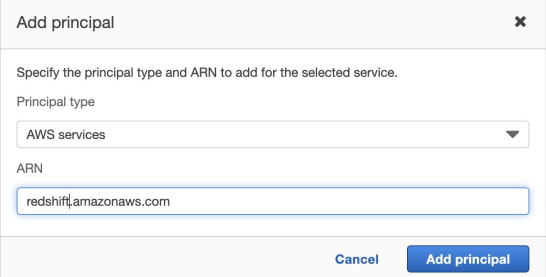
a. AWS Service 타입의 권한을 만들고 SageMaker 권한과 S3 권한을 지정 - 다음으로 이 Role을 사용할 수 있는 서비스로 Redshift를 지정
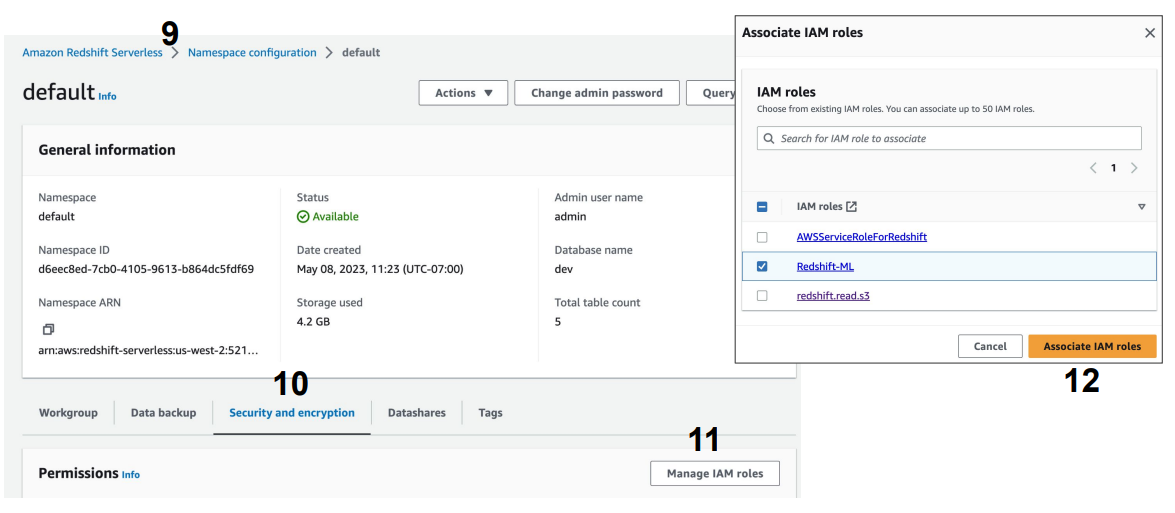
a. Principal을 redshift. - 마지막으로 이를 Redshift의 권한으로 지정 (Associate IAM Roles)
- 최종적으로 이 권한의 ARN 문자열을 클립보드로 복사
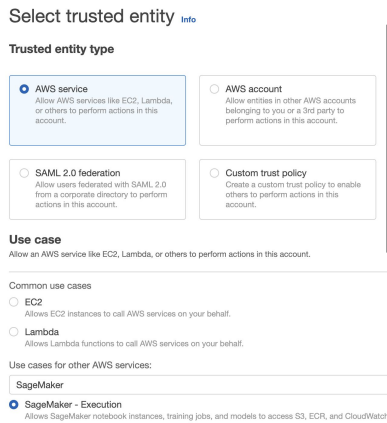
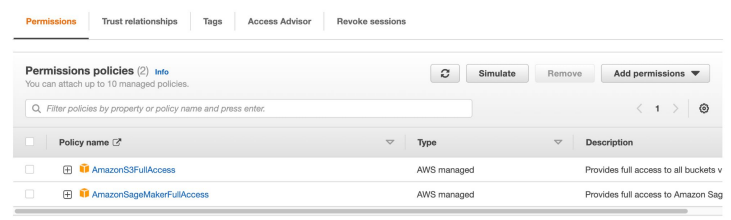
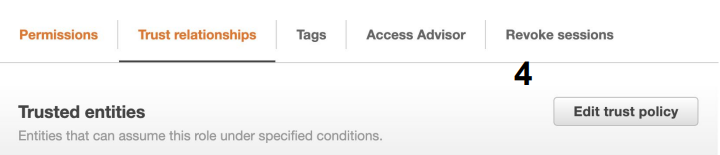
- 방금 만든 역할(Role)의 이름은 Redshift-ML로 설정한다.
CREATE MODEL 명령을 사용하여 ML 모델 생성
- raw_data.orange_telecom_customers에서 purpose 컬럼의 값이 Train을 대상으로 SageMaker를 이용해서 ML 모델을 생성하고 이를 호출할 수 있는 SQL 함수도 지정
CREATE MODEL orange_telecom_customers_model
FROM (
SELECT
state, account_length, …, customer_service_calls, churn
FROM raw_data.orange_telecom_customers
WHERE purpose = 'Train'
)
TARGET churn -- 타겟(예측) 컬럼
FUNCTION ml_fn_orange_telecom_customers -- 모델 생성 시 SQL 함수로 이름 설정
IAM_ROLE 'arn:aws:iam::521227329883:role/Redshift-ML' -- iam ARN
SETTINGS (
S3_BUCKET 'keeyong-test-bucket'
);MODEL이 만들어질 때까지 대기
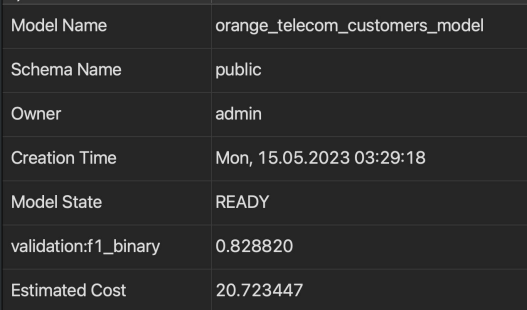
- SHOW MODEL 명령을 실행하여 모델이 준비되었는지 체크
- 이 때 SageMaker가 백그라운드에서 가장 동작을 잘 하는 알고리즘과 파라미터 결정
- $21의 비용이 들어감
SHOW MODEL orange_telecom_customers_model;
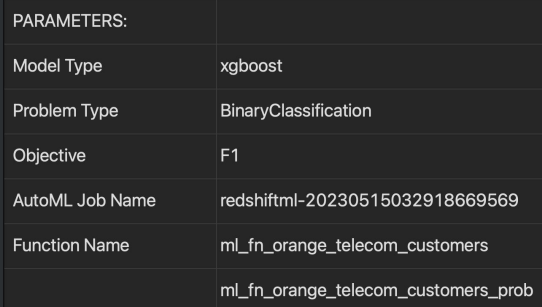
Model SQL 함수로 테이블의 Test 레코드들을 대상으로 예측 수행
- 앞서 만들어진 ml_fn_orange_telecom_customers 호출 결과와 churn 필드와 비교
SELECT churn,
ml_fn_orange_telecom_customers(
state, account_length, area_code, international_plan, voice_mail_plan,
number_vmail_messages, total_day_minutes, total_day_calls,
total_day_charge, total_eve_minutes, total_eve_calls, total_eve_charge,
total_night_minutes, total_night_calls, total_night_charge,
total_intl_minutes, total_intl_calls, total_intl_charge,
customer_service_calls -- purpose, churn 컬럼 제외한 19개
) AS "prediction"
FROM raw_data.orange_telecom_customers
WHERE purpose = 'Test';Model을 제거하고 기타 청소 작업 수행
- Drop Model 실행
- SageMaker 서비스 웹 콘솔로 이동 후 혹시라도 남은 잔재들이 있는지 찾아서 삭제
Redshift 중지/제거하기
Redshift가 더 이상 필요하다면 잠시 중지하거나 아예 제거할 수 있다.
Redshift 관련 유지보수
- Redshift 서비스는 주기적으로 버전 업그레이드를 위해 중단됨
- 이를 Maintenance window라고 부름
- Serverless에는 이게 존재하지 않음
테이블 청소와 최적화 - VACUUM 명령
- 주기적으로 해주는 것이 음
- 테이블 데이터 정렬:
- Redshift 테이블에 데이터가 삽입, 업데이트 또는 삭제될 때 데이터는 불규칙하게 분산되어 저장될 수 있는데 VACUUM 명령어는 데이터를 정렬하여 남아 있는 행을 모아 쿼리 실행 시 검색해야 할 블록 수를 줄이는 작업 수행
- 디스크 공간 해제:
- 테이블에서 행이 삭제되면 디스크 공간이 즉시 해제되지 않음.
- VACUUM 명령어는 더 이상 필요하지 않은 행을 제거하고 사용한 디스크 공간을 해제
- 삭제된 행에서 공간 회수:
- 테이블에서 행이 삭제되면 VACUUM 명령 실행 전까지 이 공간은 회수되지 않음
- 테이블 통계 업데이트:
- VACUUM은 테이블 통계를 업데이트하여 Query Planner가 쿼리 최적화 지원
- 큰 테이블에 대한 VACUUM 명령은 리소스를 많이 잡아먹음
- 바쁘지 않을 때 실행해주는 것이 좋음
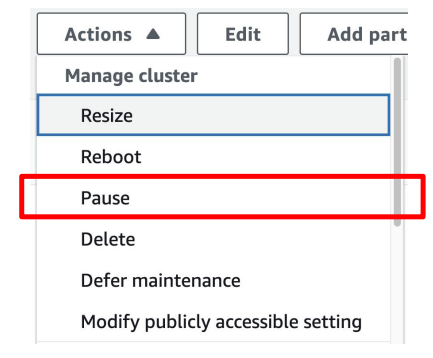
(고정 비용) Redshift 클러스터 중지/재실행
- Redshift가 당분간 필요없다면?
- Redshift 콘솔에서 해당 Redshift 클러스터를 선택하고 상단 메뉴에서 Stop 선택
- 이 경우 Redshift 클러스터의 스토리지 비용만 부담. 당연히 SQL 실행은 불가능
- Redshift가 다시 필요해지면
- 같은 메뉴에서 Resume 선택
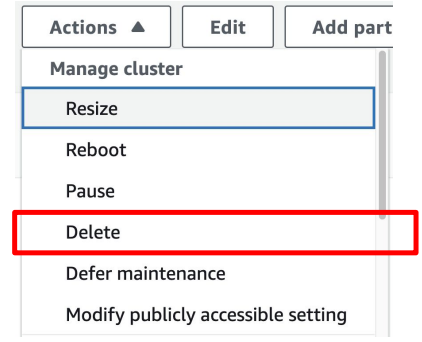
(고정 비용) Redshift 클러스터 삭제
- Redshift가 영원히 필요없다면?
- Redshift 콘솔에서 삭제할 클러스터를 선택하고 상단 메뉴에서 Delete 선택
- 이 때 데이터베이스 내용 백업을 S3로 할지 여부를 선택 가능
- 이 S3 백업으로부터 Redshift 클러스터를 나중에 새로 론치 가능함
(가변 비용) Redshift Serverless 삭제
- 먼저 모든 Workgroup들을 삭제
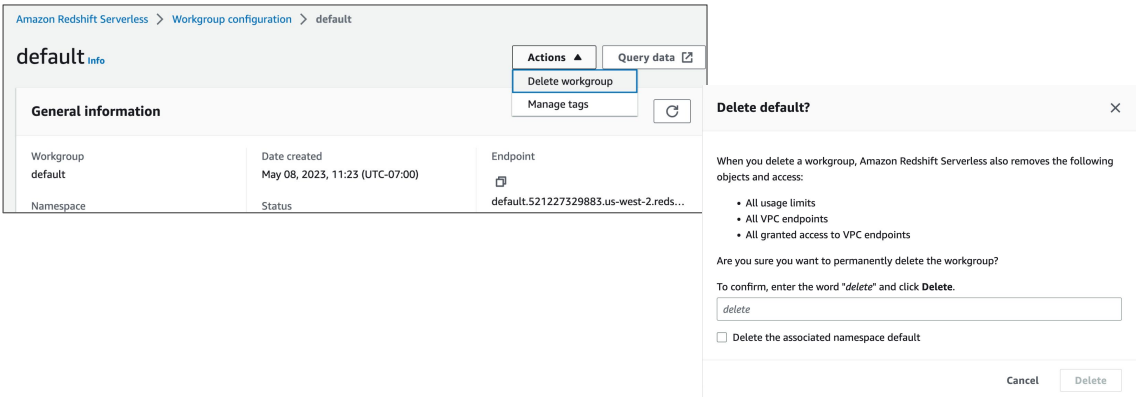
- 다음으로 모든 Namespace들을 삭제
- 그래도 주기적으로 billing에서 돈이 나가는지 확인해준다.
실습완료
한기용 강사님의 강의
프로그래머스 데이터 엔지니어링 데브코스

초짜에요...