Snowflake 운영과 관리
Snowflake의 설치, 운영, 관리에 대해 알아본다.
Redshift와 많은 유사점이 존재한다.
Snowflake 특징 소개
Snowflake가 클라우드 데이터 웨어하우스로 갖는 특징에 대해 알아본다.
Snowflake 소개
- 2014년에 클라우드 기반 데이터웨어하우스로 시작 (2016년부터 뜨기 시작, 2020년 상장)
- 지금은 데이터 팀을 위한 데이터 클라우드라고 부를 수 있을 정도로 발전
- 글로벌 클라우드 위에서 모두 동작 (AWS, GCP, Azure) - 멀티클라우드
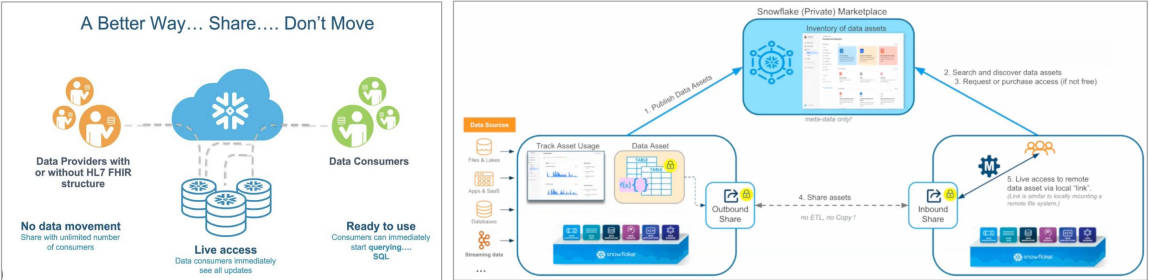
- 데이터 판매를 통한 매출을 가능하게 해주는 Data Sharing/Marketplace 제공
- 내 데이터 웨어하우스에 돈이 될만한 데이터를 공유해주는 기능.
- ETL(SaaS)과 다양한 데이터 통합 기능 제공
Snowflake 특징
- 스토리지와 컴퓨팅 인프라가 별도로 설정되는 가변 비용 모델
- Redshift 고정비용처럼 노드 수를 조정할 필요(data skew 이슈)가 없고
distkey등의 최적화 불필요
- Redshift 고정비용처럼 노드 수를 조정할 필요(data skew 이슈)가 없고
- SQL 기반으로 빅데이터 저장, 처리, 분석을 가능하게 해줌
- 비구조화된 데이터 처리와 머신러닝 기능도 제공
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- S3, GC 클라우드 스토리지, Azure Blog Storage도 지원
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- Time Travel: 과거 데이터 쿼리 기능으로 트렌드를 분석하기 쉽게 해줌
- 웹 콘솔 이외에도 Python API를 통한 관리/제어 가능
- ODBC/JDBC 연결도 지원
- 자체 스토리지 이외에도 클라우드 스토리지를 외부 테이블로 사용 가능
- 대표 고객: Siemens, Flexport, Iterable, Affirm, PepsiCo, …
- 멀티클라우드와 다른 지역에 있는 데이터 공유(Cross-Region Replication) 기능
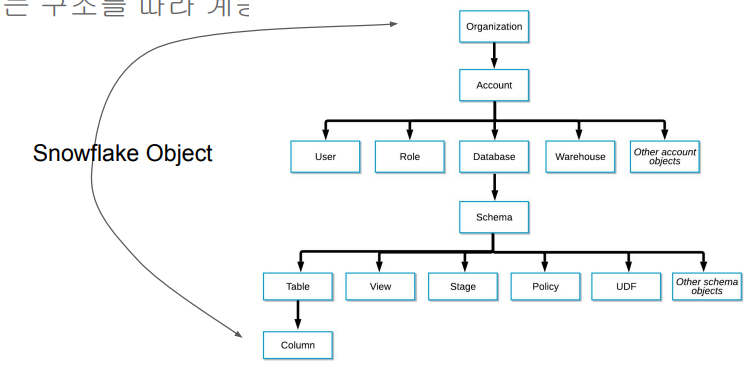
지원 - Snowflake의 계정 구성도: Organization -> 1 + Account -> 1 + Databases

- Organizations
- 한 고객이 사용하는 모든 Snowflake 자원들을 통합하는 최상위 레벨 컨테이너
- 하나 혹은 그 이상의 Account들로 구성되며 이 모든 Account들의 접근권한, 사용트래킹, 비용들을 관리하는데 사용됨
- 보통 큰 회사들이 사용하는 조직 구성도
Accounts - 하나의 Account는 자체 사용자, 데이터, 접근권한을 독립적으로 가짐
- 한 Account는 하나 혹은 그 이상의 Database로 구성됨
Databases - 하나의 Database는 한 Account에 속한 데이터를 다루는 논리적인 컨테이너
- 한 Database는 다수의 스키마와 거기에 속한 테이블과 뷰등으로 구성되어 있음
- 하나의 Database는 PB단위까지 스케일 가능하고 독립적인 컴퓨팅 리소스를 갖게 됨
- 컴퓨팅 리소스를 Warehouses라고 부름. (스토리지는 Databases) Warehouses와 Databases는 일대일 관계가 아님
- Data Marketplace
- 데이터 메시 용어가 생기기 전부터 “데이터 마켓플레이스"라는 서비스 제공
- Data Sharing (“Share, Don’t Move”, 데이터 Copy하지말고 Share하라)
- “Data Sharing” : 데이터 셋을 사내 혹은 파트너에게 스토리지 레벨에서 공유하는 방식
Snowflake 비용 모델

- 가장 싸고 기본적인 모델이 Standard
- VPS는 보안적인 측면에서 매우 좋다.(공유가 적음)
Snowflake의 기본 데이터 타입
- Numeric: TINYINT, SMALLINT, INTEGER, BIGINT, NUMBER, NUMERIC, DECIMAL, FLOAT, DOUBLE, REAL.
- Boolean: BOOLEAN.
- String: CHAR, VARCHAR, TEXT, BINARY, VARBINARY.
- Date and Time: DATE, TIME, TIMESTAMP, TIMESTAMP_LTZ, TIMESTAMP_TZ.
- Semi-structured data: VARIANT (JSON, OBJECT.
- Binary: BINARY, VARBINARY
- Geospatial: GEOGRAPHY, GEOMETRY.
- Array: ARRAY
- Object: OBJECT
Snowflake 무료 시험판 실해
Snowflake를 무료 시험판으로 설정해본다.
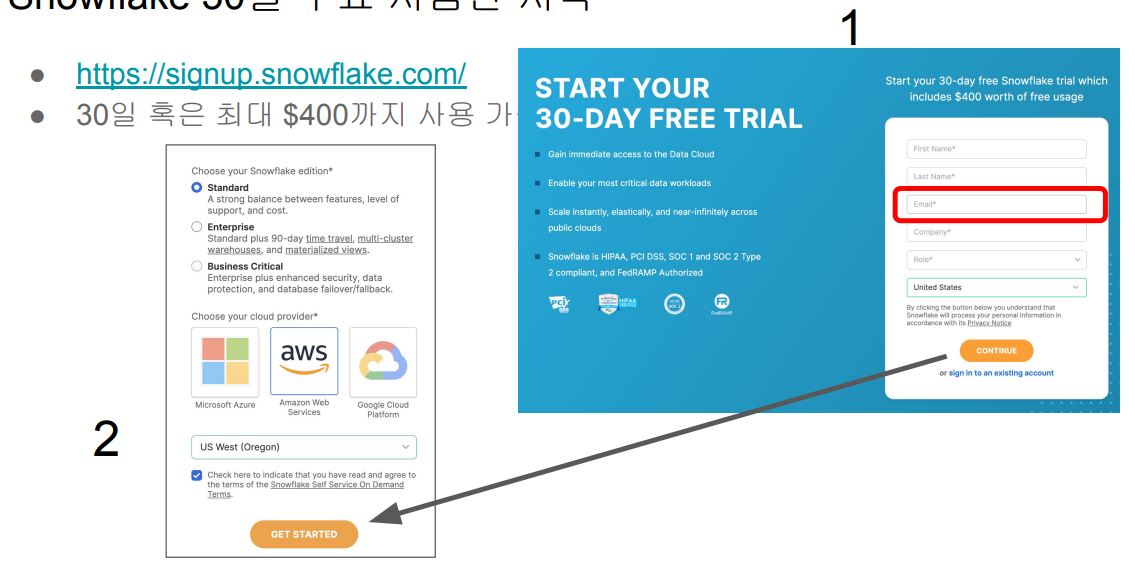
Snowflake 30일 무료 시험판 시작
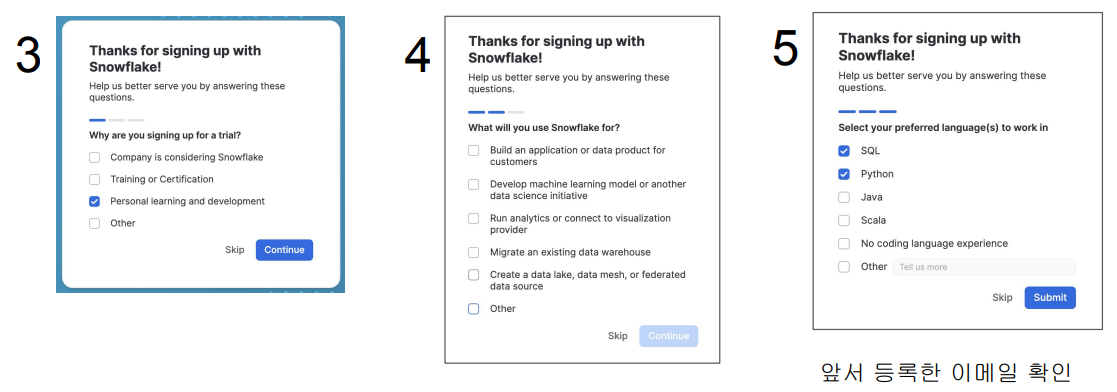
- 무슨 용도로 Snowflake를 사용할 것인가?
- Snowflake 가지고 뭘 할 것인가?
- Snowflake를 무엇으로 제어할 것인가?
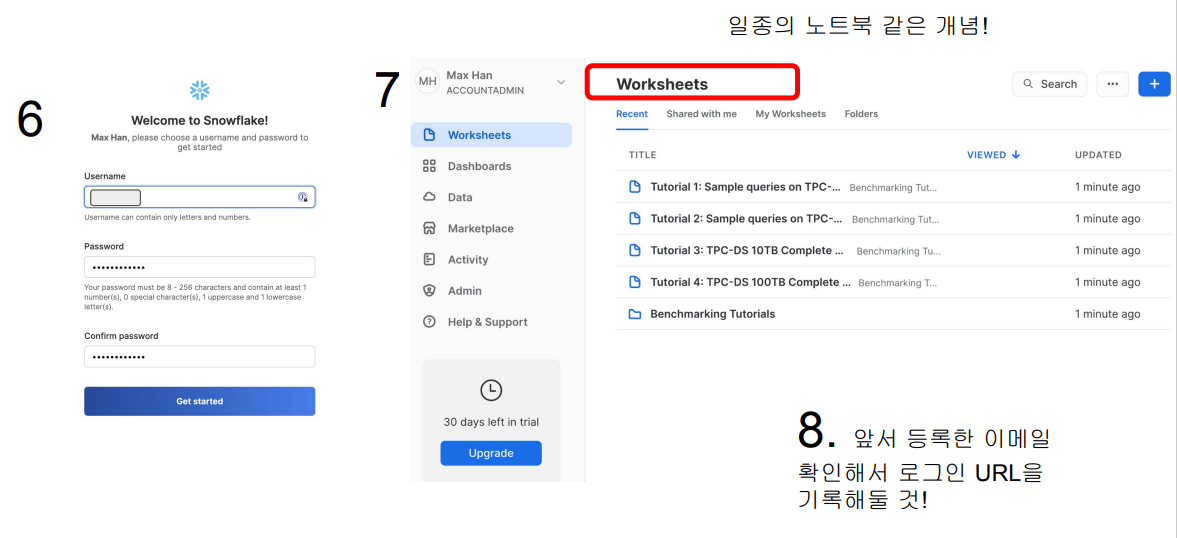
- ID, 비밀번호 설정
- 생성된 것을 확인할 수 있다. 권한을 바꿔서 확인할 수도 있다.
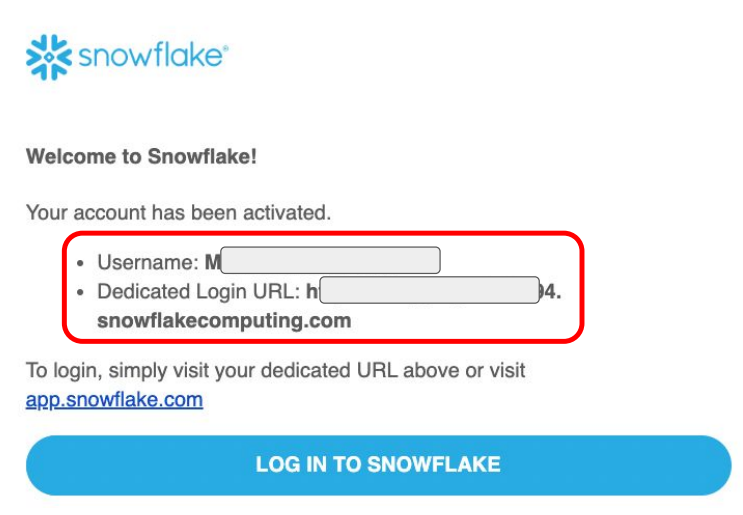
- 로그인에 필요한 URL을 자신의 메일을 통해 확인한다.
-> Snowflake 로그인 URL 확인
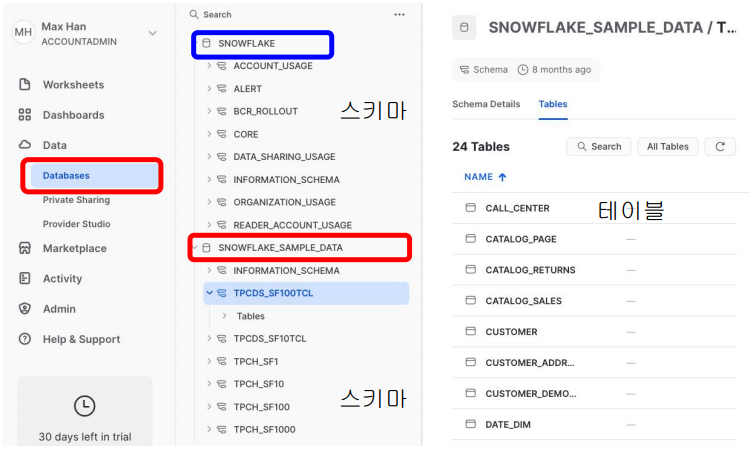
내 Account안의 Databases 확인
- 왼쪽 메뉴에서 Data 밑의 Databases 클릭, 두개의 데이터베이스가 존재
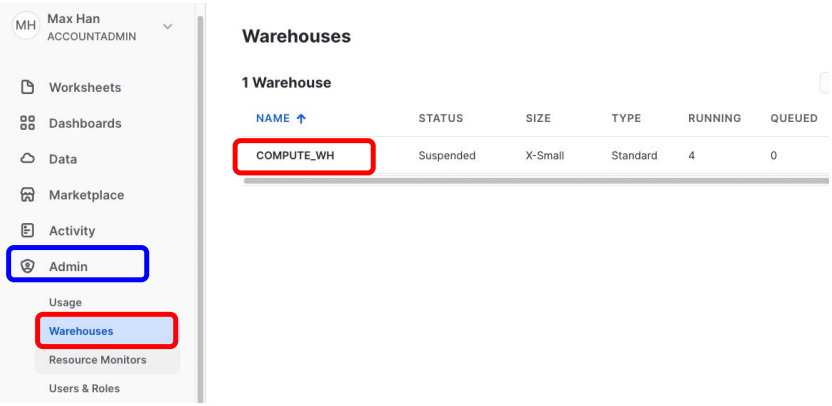
내 Account안의 Warehouses 확인
- 왼쪽 메뉴에서 Admin 밑의 Warehouses 클릭
- COMPUTE_WH라는 Warehouse를 확인 (컴퓨팅 리소스)
새로운 Warehouses 만들기
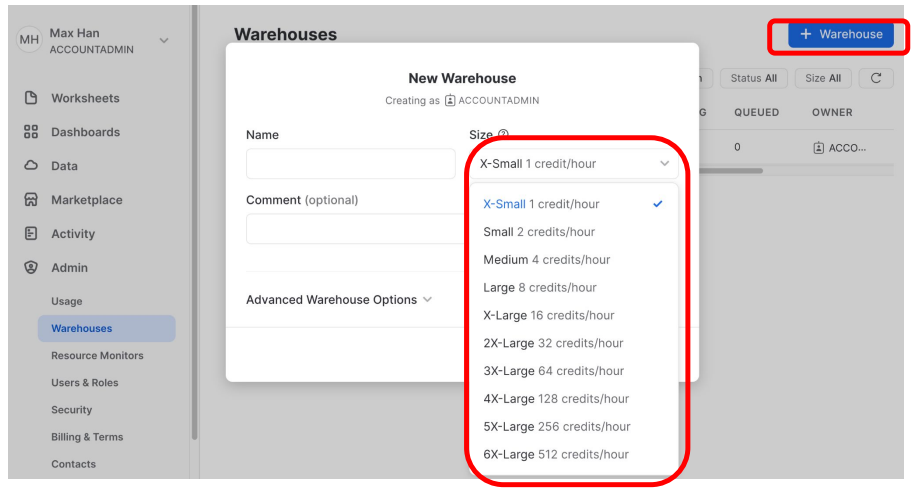
- 다양한 사이즈의 Warehouses를 만들어 놓고 자신의 일에 맞게 각각을 사용하면 된다.
(Credit은 컴퓨팅 파워를 나타내는 사이즈)
Snowflake Warehouse에서 Credit이란?
- 쿼리 실행과 데이터 로드와 기타 작업 수행에 소비되는 계산 리소스를 측정하는 단위
- 1 credit는 상황에 따라 다르지만 대략 $2-$4의 비용을 발생시킴
- credit은 스토리지 제외, 컴퓨팅(SQL 실행)을 위해 사용된 CPU, 메모리 파워
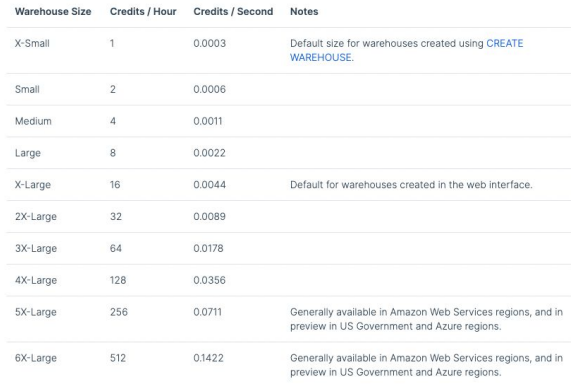
Snowflake 비용 구조
- 크게 아래 3 가지 컴포넌트로 구성됨 (다른 클라우드 업체들도 비슷하게 구성됨)
- 컴퓨팅 비용: 앞서 크레딧으로 결정됨
- 스토리지 비용: TB 당으로 계산
- 네트워크 비용: 지역간 데이터 전송 혹은 다른 클라우드간 데이터 전송시 TB 당 계산
Snowflake Schema
- SNOWFLAKE 데이터베이스 밑에 3개의 스키마를 생성
- raw_data
- analytics
- adhoc
Snowflake 실습을 위한 초기 환경 설정
Snowflake 실습을 위해 초기 환경(스키마, 테이블)을 설정하고 Summary 테이블도 만들어본다.
Worksheet 사용: 웹 SQL 에디터
- ACCOUNTADMIN ROLE 확인
- SQL Worksheet 만들기
- 해당 worksheet을 rename하여 이름을 바꿔준다.
- 현재 ACCOUNTADMIN 권한으로 사용하고 있으며 COMPUTE_WH 웨어하우스를 사용.
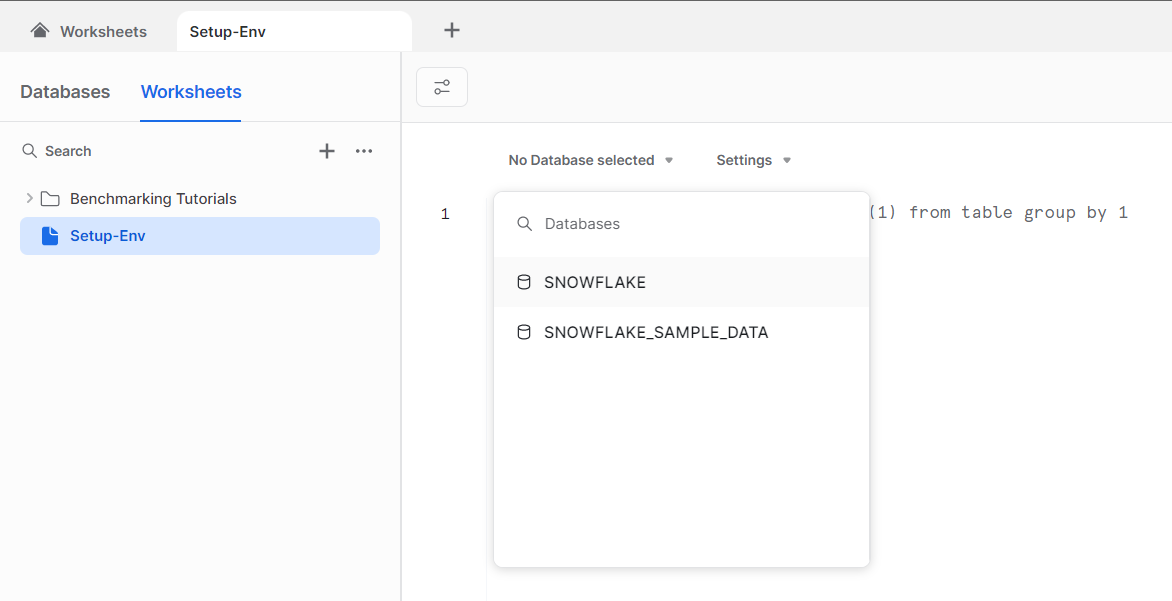
- 현재 사용 가능한 데이터베이스가 없기에 따로 데이터베이스를 만든다
(Database를 선택하지 않는다면 SQL문에서 따로 명명해주어야한다.
데이터베이스와 스키마 생성
-- 데이터베이스 생성
CREATE DATABASE dev;
-- 먼저 3개의 스키마를 생성한다.
CREATE SCHEMA dev.raw_data;
CREATE SCHEMA dev.analytics;
CREATE SCHEMA dev.adhoc; -- 데이터베이스를 선택하지 않은 상태이기에 dev.을 명명해야한다.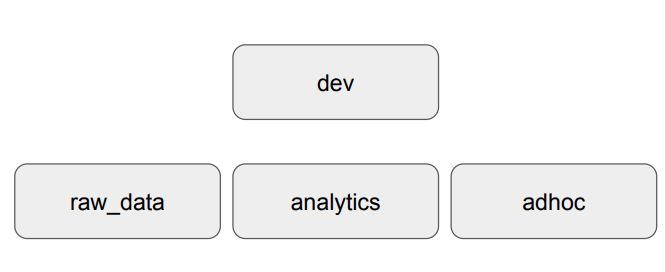
3개의 테이블을 raw_data 밑에 생성
CREATE OR REPLACE TABLE dev.raw_data.session_transaction (
-- TABLE이 있으면 지우고 새로 생성
sessionid varchar(32) primary key,
refunded boolean,
amount int
); -- s3://jeeseok-test-bucket/test_data/session_transaction.csvCREATE TABLE dev.raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
); -- s3://jeeseok-test-bucket/test_data/user_session_channel.csvCREATE TABLE dev.raw_data.session_timestamp (
sessionid varchar(32) primary key,
ts timestamp
); -- s3://jeeseok-test-bucket/test_data/session_timestamp.csvCOPY를 사용해 벌크 업데이트를 수행
COPY INTO dev.raw_data.session_timestamp
FROM 's3://jeeseok-test-bucket/test_data/session_timestamp.csv'
credentials=(AWS_KEY_ID='A…EK' AWS_SECRET_KEY='X…UH')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');- FIELD_OPTIONALLY_ENCLSED_BY는 "로 둘러싸인 경우 "를 제거하고 적재한다.
- crednetials 파라미터는 해당 S3에 접근할 수 있는 권한을 적어주면 된다.
- AWS 어드민 사용자의 AWS KEY ID와 AWS SECRET KEY를 사용하면 안됨!
- Snowflake의 S3 버킷 액세스를 위한 전용 사용자를 IAM으로 만들고 S3 읽기 권한 부여
- 그 다음에 그 사용자의 AWS KEY ID와 AWS SECRET KEY를 사용
- 이어서 그 과정을 설명
Snowflake에서 S3 버킷을 접근하기 위한 IAM 사용자 생성
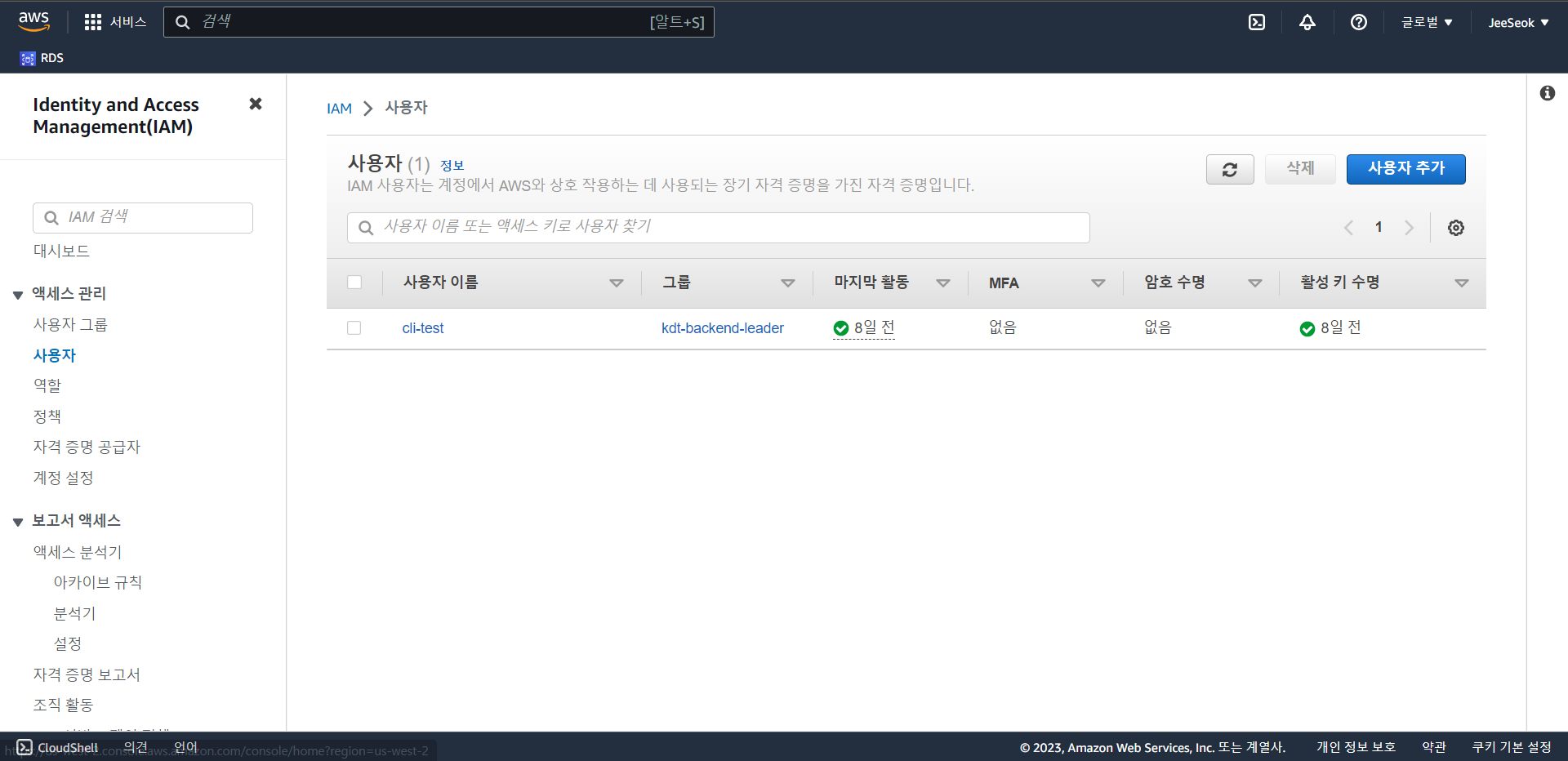
- 사용자 추가를 통해 snowflake 접근을 위한 IAM 사용자 생성.
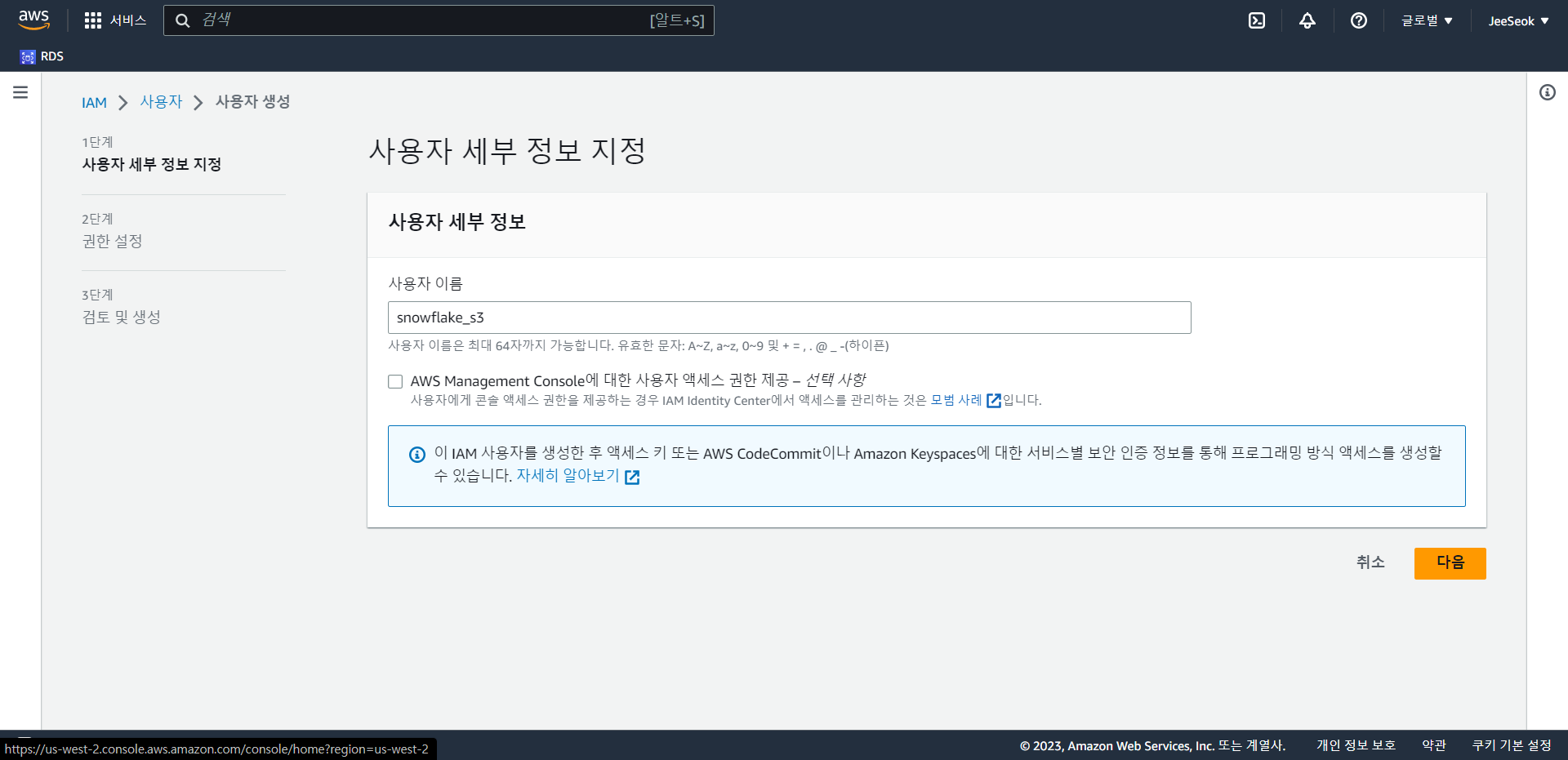
- 이름 설정
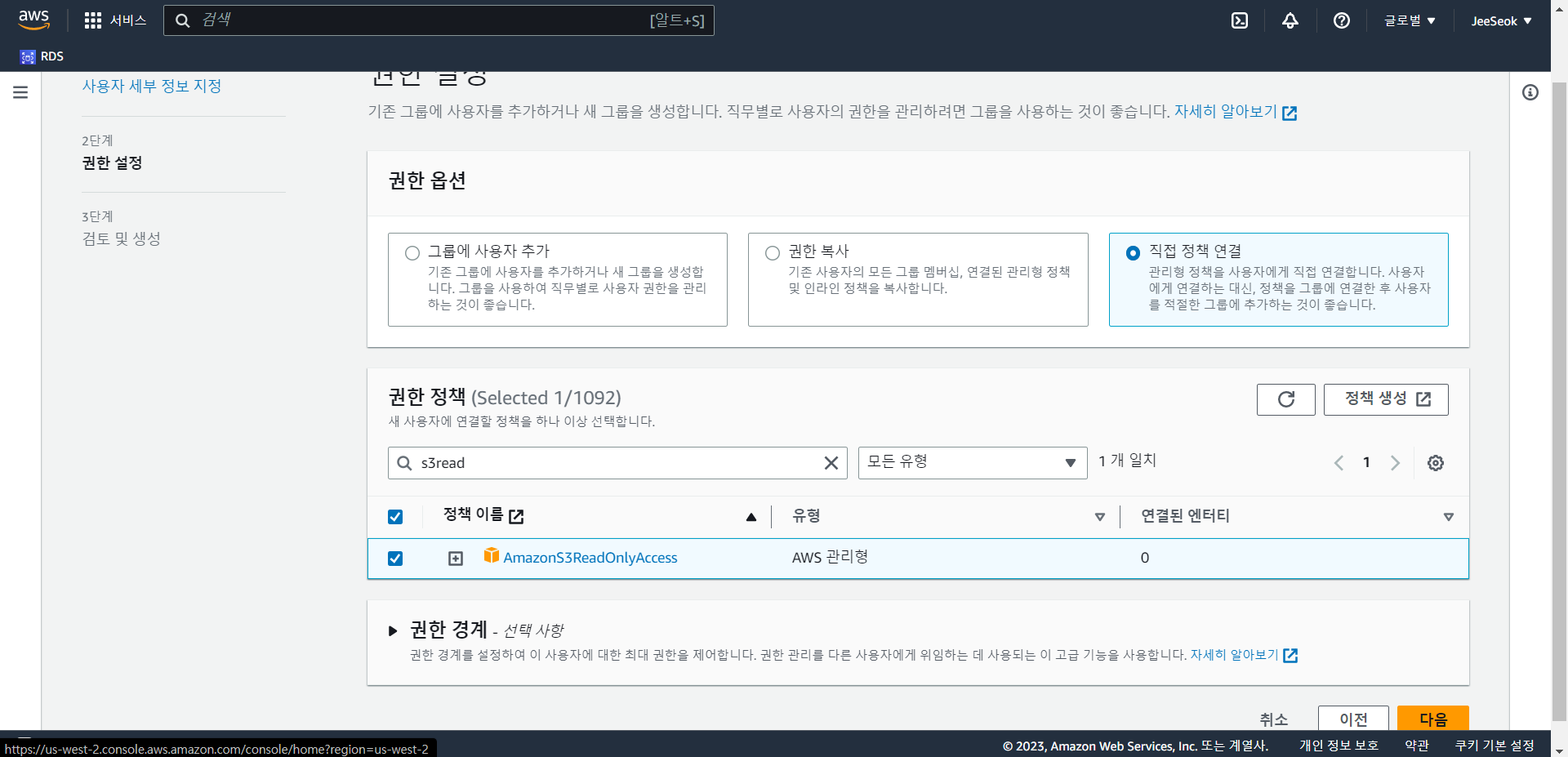
- 직접 정책 연결을 통해 AmazonS3ReadOnlyAccess 권한 정책을 부여한다.
- 이후 사용자 생성을 하면 된다.
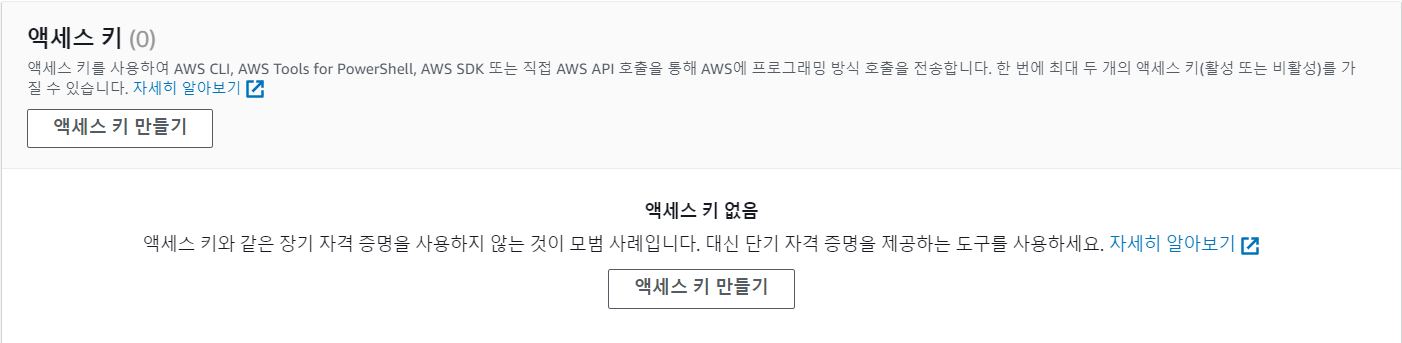
- 만든 사용자에 들어가 보안 자격 증명에 들어가 액세스 키를 만든다.
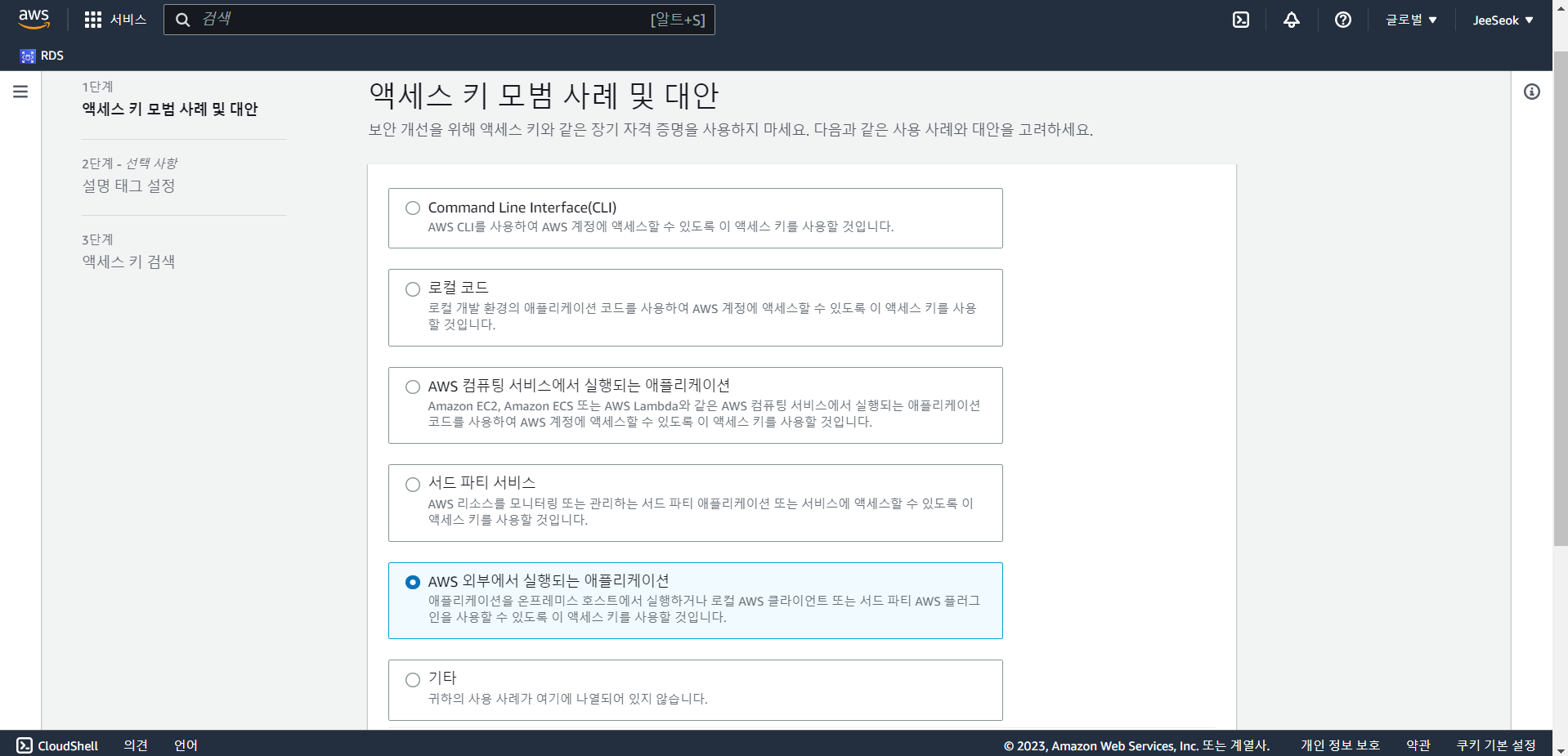
- Snowflake를 사용하기 AWS 외부에서 실행되는 애플리케이션을 선택한다.
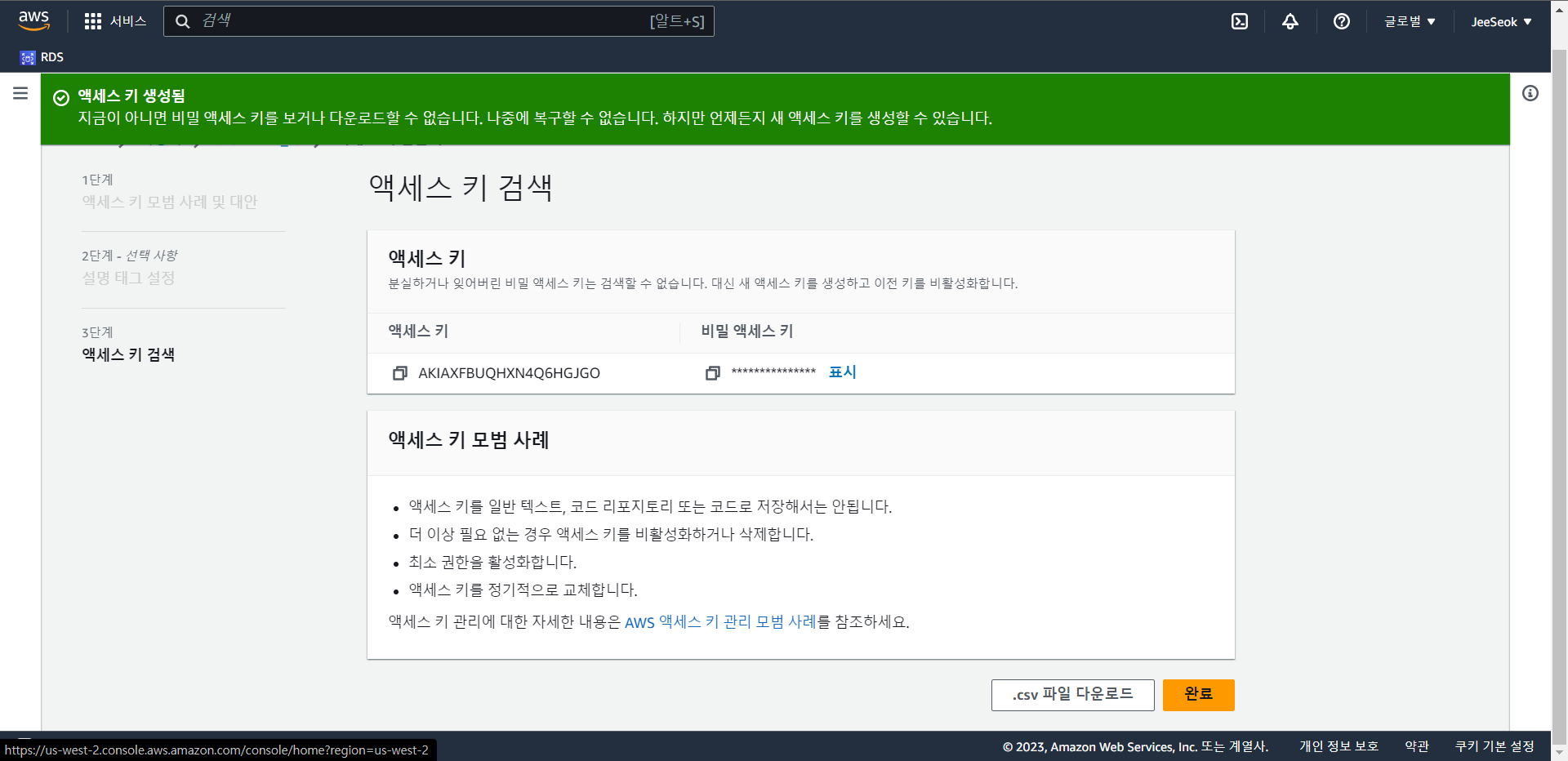
- 만든 키의 액세스 키와 비밀 액세스키를 복사하여 COPY SQL문에 입력한다.
analytics 스키마 밑에 테이블을 CTAS로 생성
CREATE TABLE dev.analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;SELECT * FROM dev.analytics.mau_summary LIMIT 10;- 처음부터 잘하는 사람은 없기 때문에 하면서 깨달으면 좋다.
Snowflake 사용자 권한 설정
Snowflake Role로 권한 설정을 해보고 Snowflake가 제공해주는 보안 관련 기능을 알아본다.
Role과 User 생성
-- 3개의 ROLE을 생성한다
CREATE ROLE analytics_users;
CREATE ROLE analytics_authors;
CREATE ROLE pii_users;
-- 사용자 생성
CREATE USER jeeseok PASSWORD='jeeseokjjang123';
-- 사용자에게 analytics_users 권한 지정
GRANT ROLE analytics_users TO USER jeeseok;- Snowflake는 Group을 지원하지 않음
- Redshift에서 했던 것과 동일
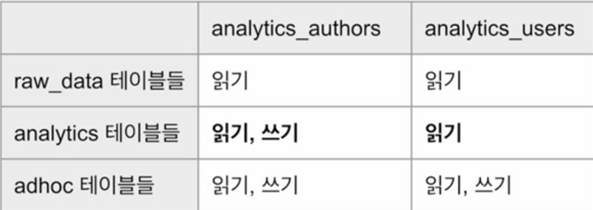
analytics_users와 analytics_authors Role 설정
-- set up analytics_users, 우선 analytics_user의 Role을 설정한다.
-- 읽기만 설정
GRANT USAGE on schema dev.raw_data to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.raw_data to ROLE analytics_users;
-- 읽기만 설정
GRANT USAGE on schema dev.analytics to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.analytics to ROLE analytics_users;
-- 읽기, 쓰기 모두 설정
GRANT ALL on schema dev.adhoc to ROLE analytics_users;
GRANT ALL on all tables in schema dev.adhoc to ROLE analytics_users;-- set up analytics_authors
-- analytics_authors의 역할을 analytics_users 역할에게 똑같이 부여
GRANT ROLE analytics_users TO ROLE analytics_authors;
GRANT ALL on schema dev.analytics to ROLE analytics_authors;
GRANT ALL on all tables in schema dev.analytics to ROLE analytics_authors;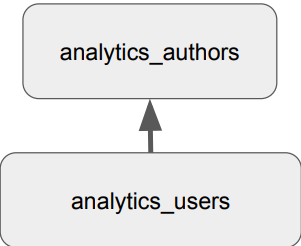
컬럼 레벨 보안 (Column Level Security)
- 테이블내의 특정 컬럼(들)을 특정 사용자나 특정 역할(Role)에만 접근 가능하게 하는 것
- 보통 개인정보 등에 해당하는 컬럼을 권한이 없는 사용자들에게 감추는 목적으로 사용됨
- 사실 가장 좋은 방법은 아예 그런 컬럼을 별도 테이블로 구성하는 것임
- 더 좋은 방법은 보안이 필요한 정보를 아예 데이터 시스템으로 로딩하지 않는 것임
레코드 레벨 보안 (Row Level Security)
- 테이블내의 특정 레코드(들)을 특정 사용자나 특정 역할에만 접근 가능하게
하는 것 - 특정 사용자/그룹의 특정 테이블 대상 SELECT, UPDATE, DELETE 작업에 추가 조건을 다는 형태로 동작
- 일반적으로 더 좋은 방법은 아예 별도의 테이블로 관리하는 것임
- 다시 한번 더 좋은 방법은 보안이 필요한 정보를 아예 데이터 시스템으로 로딩하지 않는 것임
컬럼, 레코드 레벨 보안 둘다 실수가 발생할 수 있으므로 사용을 권장하지 않음
만약 사용한다면 따로 테이블을 만들어 사용한다.
컬럼, 레코드 레벨 보안은 클라우드 기반 데이터 웨어하우스에선 대부분 제공
오픈 소스에서는 잘 제공안해줌
Data Governance 관련 기능
- Object Tagging : 다양한 객체들(Schema, Databases 등)에 태그를 붙인다.
- Data Classification : snowflake이 알아서 데이터의 형태를 알아보고 분류해준다
(개인정보, 식별자정보 등) - Tag based Masking Policies : 태그에 따라서 접근 권한을 부여해준다.
- Access History : 사용자별로 언제 데이터에 접근했는지 컬럼 기준으로 기록해준다.
- Object Dependencies : 데이터 리니지와 관련, 데이터를 맘대로 바꾸지 않게.
- 원본 테이블이 갖고 있는 속성들이 새 테이블을 만들때 같이 따라가게 해주는 기능
Data Governance란 무엇인가?
- 필요한 데이터가 적재적소에 올바르게 사용됨을 보장하기 위한 데이터 관리 프로세스
- 품질 보장과 데이터 관련 법규 준수를 주 목적으로 함 - 다음을 이룩하기 위함이 기본 목적
- 데이터 기반 결정에서 일관성
- 예: KPI등의 지표 정의와 계산에 있어 일관성
- 데이터를 이용한 가치 만들기
- Citizen data scientist가 더 효율적으로 일할 수 있게 도와주기
- Data silos를 없애기
- 데이터 관련 법규 준수
- 개인 정보 보호 -> 적절한 권한 설정과 보안 프로세스 필수!
- 데이터 기반 결정에서 일관성
Data Governance 관련 기능 - Object Tagging
- Enterprise 레벨에서만 가능한 기능. CREATE TAG로 생성
- 문자열을 Snowflake object에 지정 가능 (계정, 스키마, 테이블, 컬럼, 뷰 등등)
- 시스템 태그도 있음 (뒤의 Data Classification에서 다시 이야기)
- 이렇게 지정된 tag는 구조를 따라 계승됨
Data Governance 관련 기능 - Data Classification
- Enterprise 레벨에서만 가능한 기능
- 앞서 Object Tagging은 개인 정보 관리가 주요 용도 중의 하나
- 하지만 이를 매뉴얼하게 관리하기는 쉽지 않음.(scale이 안됨.)
- 그래서 나온 기능이 Data Classification
- 3가지 스텝으로 구성됨
- Analyze: 테이블에 적용하면 개인정보나 민감정보가 있는 컬럼들을 분류해냄(자동)
- Review: 이를 사람(보통 데이터 엔지니어)이 보고 최종 리뷰 (결과 수정도 가능)
- Apply: 이 최종 결과를 System Tag로 적용
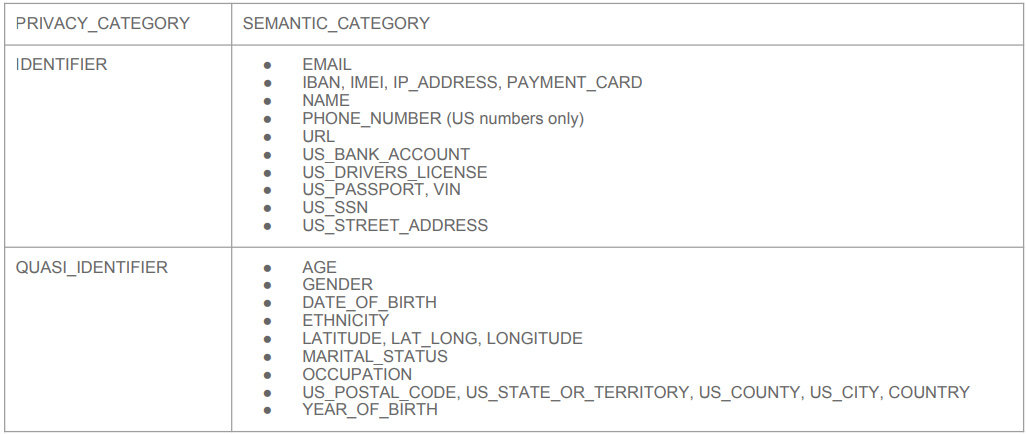
- SNOWFLAKE.CORE.PRIVACY_CATEGORY (상위레벨)
- IDENTIFIER(개인식별자), QUASI_IDENTIFIER(개인준식별자), SENSITIVE(민감정보)
- SNOWFLAKE.CORE.SEMANTIC_CATEGORY (하위레벨 - 상위레벨의 세부정보)
- SNOWFLAKE.CORE.PRIVACY_CATEGORY (상위레벨)
Data Governance 관련 기능 - 식별자와 준식별자
- 개인을 바로 지칭하는 식별자 (Identifier)
- 영어 중심으로 구분해준다.
- 몇 개의 조합으로 지칭가능한 준식별자 (Quasi Identifier)
Data Governance 관련 기능 - Tag based Masking Policies
- Enterprise 레벨에서만 가능한 기능
- 먼저 Tag에 액세스 권한을 지정
- 해당 Tag가 지정된 Snowflake Object의 액세스 권한을 그에 맞춰 제한하는 방식
- 보통 앞서 본 개인정보와 같은 Tag에 부여하는 것이 가장 많이 사용되는 패턴
- Tag Lineage가 여기에도 적용됨.
Data Governance 관련 기능 - Access History
- Enterprise 레벨에서만 가능한 기능
- 목적은 데이터 액세스에 대한 감사 추적을 제공하여 보안과 규정 준수
- 잠재적인 보안 위반이나 무단 액세스 시도의 조사를 가능하게 해줌
- 캡처된 정보에는 사용자 신원, IP 주소, 타임스탬프 및 기타 관련 세부 정보 포함
- 'Access History'를 통해 다음 활동(audit trail)의 추적이 가능
- 데이터베이스 로그인, 실행된 쿼리, 테이블 및 뷰 액세스, 데이터 조작 작업
- 이 기능은 사실 다른 모든 클라우드 데이터 웨어하우스에서도 제공됨
Data Governance 관련 기능 - Object Dependencies
- 데이터 거버넌스와 시스템 무결성 유지를 목적으로 함
- 테이블이나 뷰를 수정하는 경우 이로 인한 영향을 자동으로 식별
- 예를 들어 테이블 이름이나 컬럼 이름을 변경하거나 삭제하는 경우
- 즉 데이터 리니지 분석을 자동으로 수행해줌
- 계승 관계 분석을 통한 더 세밀한 보안 및 액세스 제어
- 어떤 테이블의 개인정보 컬럼이 새로운 테이블을 만들때 사용된다면?
- 원본 테이블에서의 권한 설정이 그대로 전파됨 (Tag 포함)
- 어떤 테이블의 개인정보 컬럼이 새로운 테이블을 만들때 사용된다면?
Snowflake 기타 기능과 사용 중단하기 살펴보기
Snowflake가 제공해주는 부가 기능, 최종적으로 무료시험판을 중단하는 방법
Marketplace
- ETL 관련 기능 (무료 시험판에선 사용 못함)
- 비용을 지불하면 코딩을 최소화하여 stripe data pipeline을 사용할 수 있다.
- 내가 원하는 데이터 소스를 검색할 수 있다.
Data Sharing
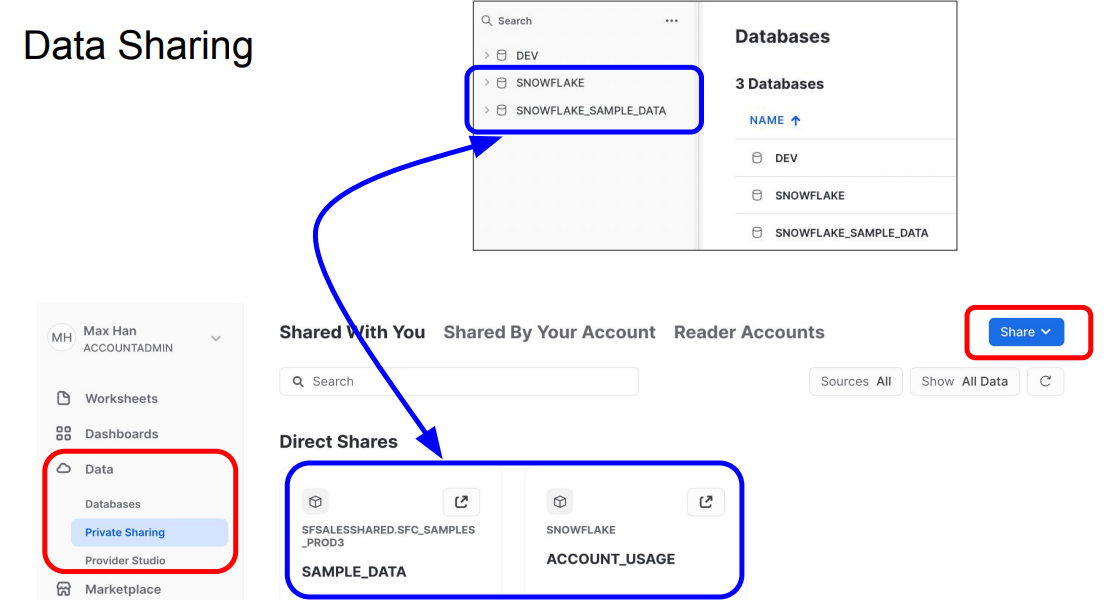
- 이전에 만든 2개의 데이터베이스는 완전히 소유한 DB가 아닌 Snowflake에서 만들어서 공유해준 DB.
- 대부분 테이블들을 읽기만 가능
- 다른 account와 공유하려면 share를 통해 가능 (무료 시험판은 사용에 제한)
Activity - Query/Copy/Task History
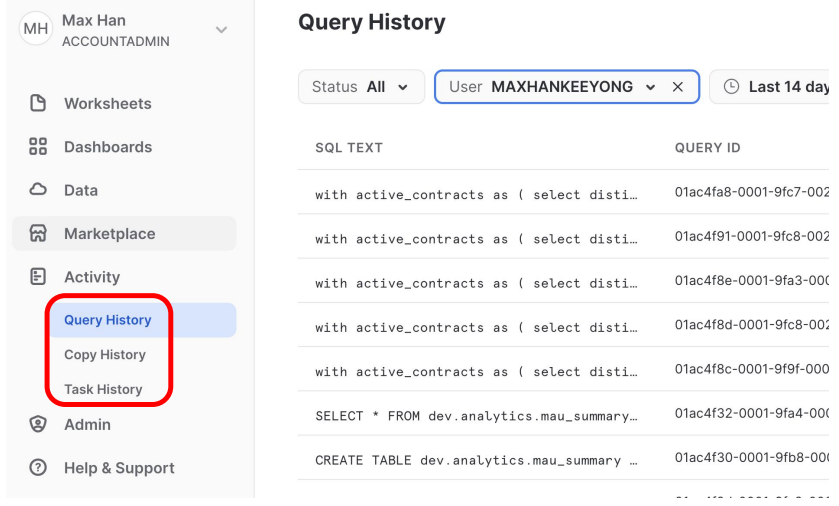
- Query History : SELECT, CREATE, UPDATE등의 SQL 문의 history
- Copy History : 벌크 업데이트한 history
- Task History : 특정 sql 문을 주기적으로 시행했을 때의 history
무료 시험판을 끝내는 방법
- 무료 시험 기간이 끝나면 계정은 자동으로 “Suspended” 모드로 변경됨
- 첫 신청시 크레딧 카드 정보를 입력하지 않음
- Suspended 모드에서 벗어나려면 크레딧 카드 정보 입력이 필요
- 그전에 끝내고 싶다면 Snowflake 서포트에 이메일을 보내서 종료 가능
- credit card 정보만 입력 안하면 됨!
실습완료
한기용 강사님의 강의
프로그래머스 데이터 엔지니어링 데브코스

초짜에요...