[논문 리뷰] A Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning
Paper Seminar
데이터과학 분야에서 실무자들은 가능한 한 많은 Feature를 수집하고, 기존 Feature에서 새로운 Feature를 만들어내기도 한다. 이후, 모델링 단계에서 Overfitting을 막기 위해 자동화된 Feature Selection (FS)를 활용한다. 현재 존재하는 Tabular data의 FS 방법론 Benchmark들은 Feature selecor를 Downstream task 성능 기준으로 평가하지 않는다. 본 논문에서는 실제 Dataset과 생성한 불필요한 Feature를 이용해서 성능을 평가하는 Benchmark를 새롭게 마련하였다. 또한, 신경망에 대한 Lasso 기반 모델인 Deep Lasso를 제안하며 이는 손상되거나 Second-order Feature에서 유용한 feature를 골라날 때와 같은 어려운 문제상황에서 기존 기법보다 우수한 성능을 보인다.
Introduction
-
Tabular data는 Machin learning 분야에서 널리 사용되고 실무자들은 사용 가능한 모든 feature를 포함하거나, 직접 feature를 추가하여 Tabular dataset을 구성함
-
이러한 경우, overfitting이 발생할 가능성이 크기 때문에 자동화된 Feature Selection (FS) 기법을 사용해서 특정 feature를 필터링하고 제거하는 과정을 거침
-
기존 연구에서는 전통적인 ML 알고리즘을 FS 기준으로 사용하거나, 전통적인 알고리즘을 Downstream model로 활용하기 위한 FS 기법들을 제안하고 평가 해왔음
-
그러나, 딥러닝 기반 모델이 Noisy features에 특히 과적합하기 쉽다는 점은 이미 잘 알려져 있으며 Tabular 신경망 모델을 위한 FS 기법을 체계적으로 평가한 사례는 아직 부족함
-
이에 따라 본 논문에서는 실제 데이터셋을 기준으로 선정된 Feature들의 성능을 평가하여 Tabular Deep learning에서의 Feature selection 방법론을 Benchmarking 함
-
또한, Deep Lasso 방법론을 제안함
Experimental Setup
- 본 논문에서는 실제 데이터셋을 활용하고 외부 Feature의 통제된 구성을 위한 여러 접근 방식을 포함하는 Feature selection Benchmark를 구성함. Downstream 신경망의 성능에 따라 Feature selection 방법을 평가함
- 이를 위한 Downstream 신경망으로는 MLP Architecture와 FT-Transformer Architecture를 활용함
Are Deep Tabular Models More Susceptible to Noise than GBDT?
- 최근 연구에서 Tabular deep learning model과 GBDT 간의 비교에서 Tabular deep learning model이 최대 10,000 sample 크기의 데이터셋에서 Noise에 더 민감하다는 것이 밝혀졌음. 본 논문에서는 이를 더 큰 데이터셋으로 확장하고 Tabular deep learning model에 특화된 Feature selection 방법 및 Benchmark 개발의 Motivation을 소개함
-아래 그림은 3가지 모델의 성능과 Dataset에서 Noise의 비율에 따른 성능 관계를 나타냄. MLP Architecture는 평균적으로 Noise에 대해 더 많은 overfitting을 보이는 것으로 관찰되었기 때문에 이에 따른 feature selection이 필요하다는 것을 알 수 있음 - 반면, FT-Transformer는 XGBoost만큼 Noise에 강건하다는 것을 알 수 있으며 이는 Transformer Architecture가 Attention mechanism을 통해 정보가 없는 Noise feature를 걸러내는 능력에 기인함
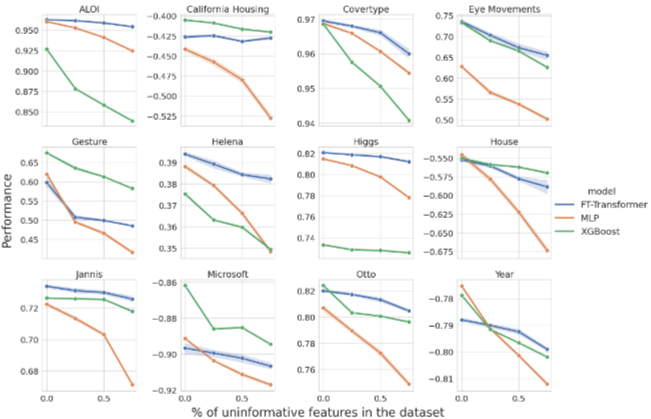
Feature Selection Benchmark
- 실제 데이터셋에서 완전히 무작위 Noise를 Feature에 포함하는 것은 흔하지 않음. 그럼에도 불구하고, Feature selection algorithm은 종종 Gaussian noise에서 생성된 불필요한 feature가 포함된 데이터셋에서 평가됨
- 이는 실제 Feature selection scenario와 다를 뿐만 아니라, 대부분의 Feature selection algorithm이 이러한 Noise feature를 제거하는 게 비교적 간단한 작업임. 따라서 본 논문에서는 추가적인 Feature를 만들기 위한 세 가지 방법을 도입함
-
Random Features - Gaussian 분포에서 noise를 sampling하고 이를 원래 데이터셋의 feature와 결합
-
Corrupted Features - 데이터셋의 원래 Feature에서 불필요한 Feature를 sampling하고 이를 Gaussian noise로 손상시킴. 또한, Laplace noise corruption 실험을 수행함
-
Second-Order Features - 원래 Feature 중에서 무작위로 선택된 Feature의 제곱인 가공된 Feature를 추가함
Results
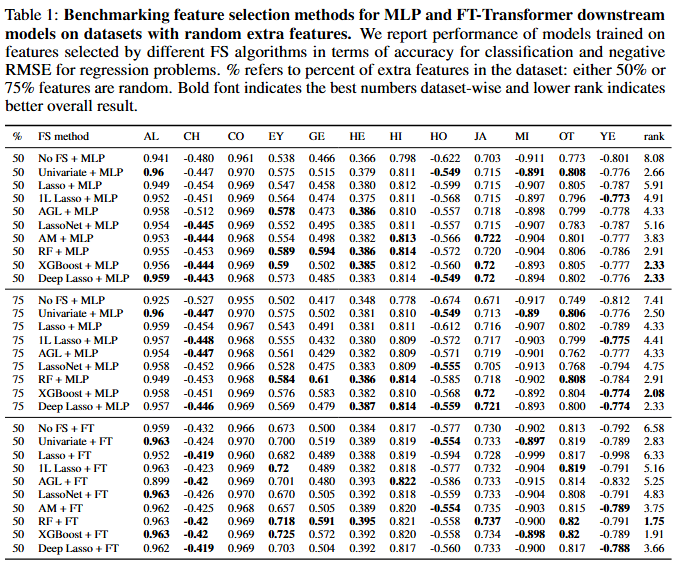
- 외부 Feature가 Gaussian noise인 시나리오에서는 MLP Architecture의 경우 XGBoost, RF, Univariate, Deep Lasso가 동등한 성능을 보이는 반면, FT-Transformer의 경우 RF와 XGBoost가 다른 방법보다 성능이 뛰어난 것을 확인할 수 있음
- 반대로 Lasso, 1L Lasso, AGL, LassoNet은 성능이 떨어지는 것으로 나타났음. 이러한 결과는 Lasso 기반 방법론이 Noise feature에 더 높은 중요도 순위를 할당하는 경향이 크다는 점을 나타냄

- Corrupted extra feature가 포함된 시나리오에서는 Deep Lasso와 XGBoost 모두 다른 Feature selection 방법보다 성능이 훨씬 뛰어남. 특히, MLP Architecture에서는 Deep Lasso가 더 우수한 성능을 보이는 반면, FT-Transformer에서는 XGBoost가 약간 더 나은 성능을 보임
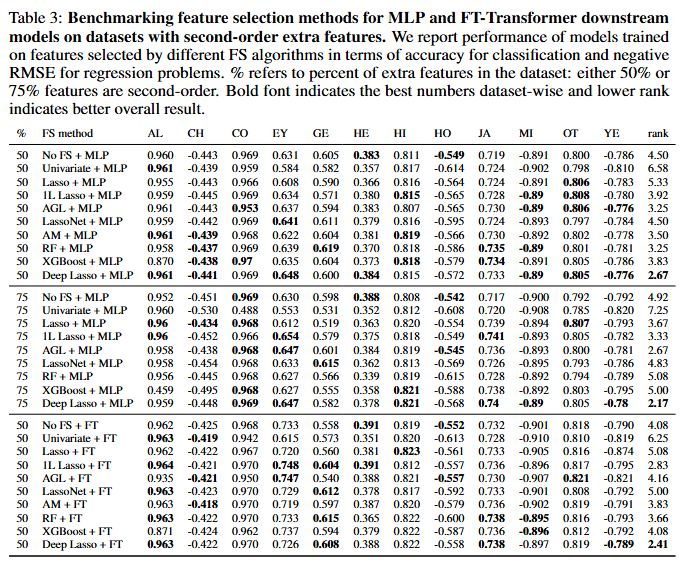
- Second-order Feature를 추가한 마지막 시나리오에서는 Deep Lasso가 다른 방법보다 상당한 성능 우위를 보임. 전체 Feature의 75%가 Second-order로 생성될 때 Deep Lasso의 성능이 좋아지는 것을 알 수 있는데, 이는 Deep Lasso가 corrupted feature와 Secon-order feature 모두에서 상당수의 허위 또는 중복 Feature가 포함된 더 어려운 Feature selection 문제에서 탁월한 성능을 발휘한다는 것을 나타냄.
Discussion
- 본 논문에서는 Tabular deep learning model을 위한 Feature selection Benchmark를 제안함. 해당 Benchmark는 불필요한 정보, 손상된 정보, 중복된 Feature가 포함된 실제 데이터셋임. 포괄적인 실험 결과 Tree 기반 알고리즘을 포함한 고전적인 Feature selection 방법은 무작위 및 손상된 feature를 가진 시나리오에서 높은 성능을 발휘하지만, 본 논문에서 제안한 Deep Lasso와 같은 특수한 Feature selection 방법은 Second-order feature가 포함된 시나리오에서 다른 방법론들보다 높은 성능을 발휘함
- 본 연구는 Tabular deep learning model의 성능과 Robustness 향상에 대한 통찰력을 갖춘 체계적인 새로운 Benchmark를 제공함
