탐색
원하는 데이터를 찾는 과정
-DFS & BFS
스택 자료구조
-먼저들어온 데이터가 나중에 나가는 형식(선입후출)
-입구와 출구가 동일한 형태로 스택을 시각화
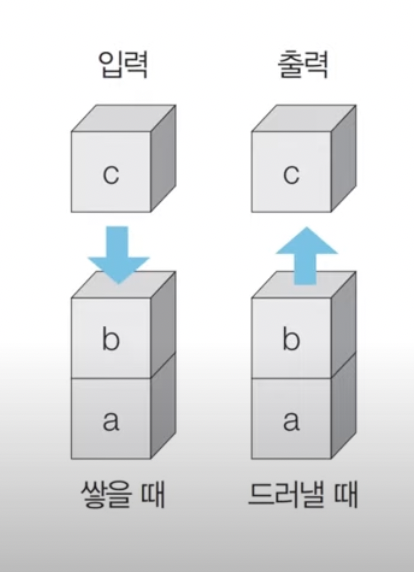
파이썬에서는 리스트를 이용하면 된다.
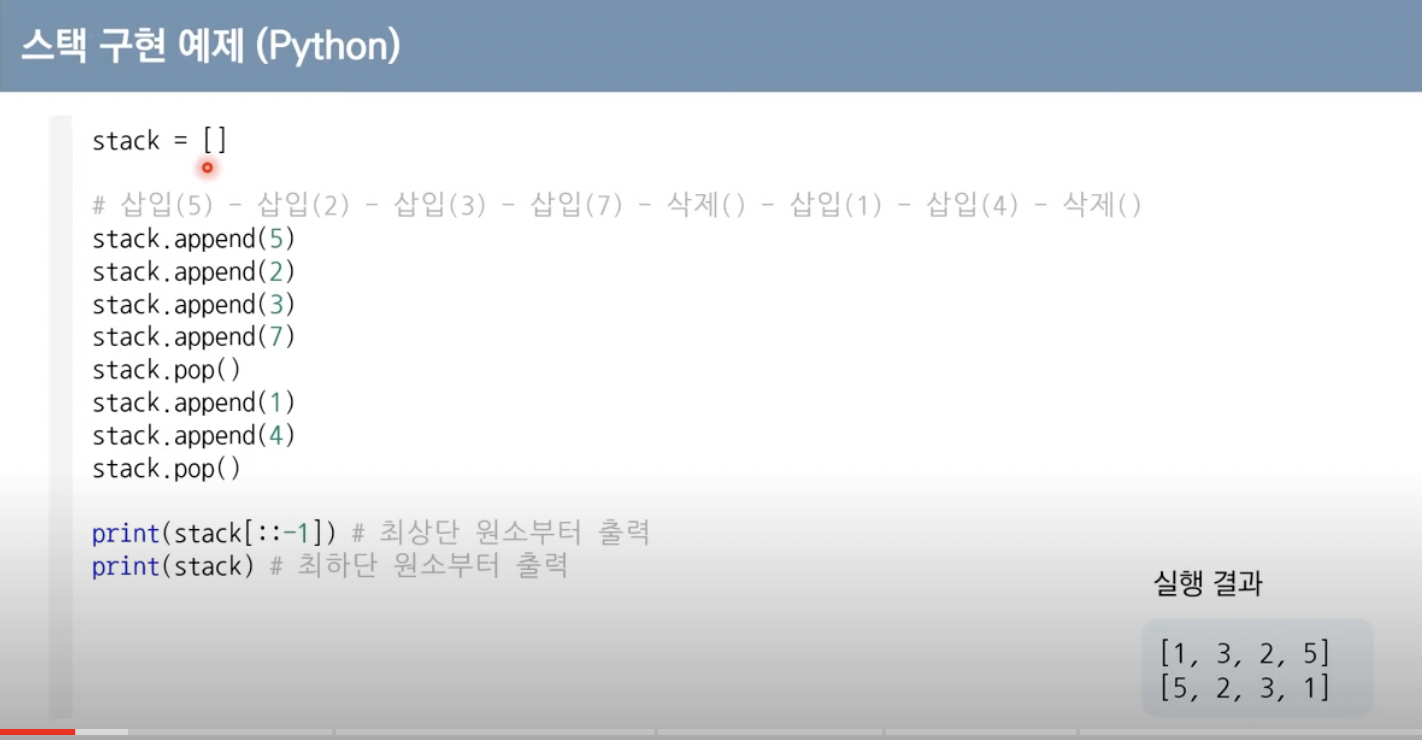
가장 왼쪽에 있는원소가 가장 먼저들어온 원소
큐 자료구조
-먼저들어온 데이터가 먼저 나가는 형식의 자료구조
-큐는 입구와 출구가 모두 뚫려 있는 터널과 같은 형태로 시각화
-deque
-queue.(append,popleft,reverse)
-리스트를 이용하지 않고 deque를 이용하기

재귀함수
-자기자신을 다시 호출하는 함수

재귀함수의 종료 조건
-재귀함수를 문제 풀이에서 사용할 때는 재귀 함수의 종료 조건을 반드시 명시해야 함.
-종료 조건을 제대로 명시하지 않으면 함수가 무한히 호출됨
➕종료조건을 포함한 재귀 함수 예제
def recursive_function()
if i==100: #100번째에서 종료(종료 조건)
return
print(i,'번째 재귀함수에서',i+1,'번째 재귀함수를 호출')
recursive_function(i+1)
print(i,'번째 재귀함수를 종료합니다')
recursive_function(1)팩토리얼 구현 예제
def fac_iterative(n):
result=1
for i in range(1,n+1):
result *=i
return result
def fac_recursive(n): #간결하고 직관적
if n<=1:
return 1
return n*fac_recursive(n-1)
유클리드 호제법
-두 개의 자연수에 대한 최대공약수를 구하는 대표적인 알고리즘
->두 자연수 a,b에 대해 (a>b) a를 b로 나눈 나머지를 r이라고 할때 a,b의 최대공약수는 b와 r의 최대공약수와 같다.
->유클리드 호제법의 아이디어를 재귀함수로 작성할 수 있다
*gcd( , ):최대 공약수
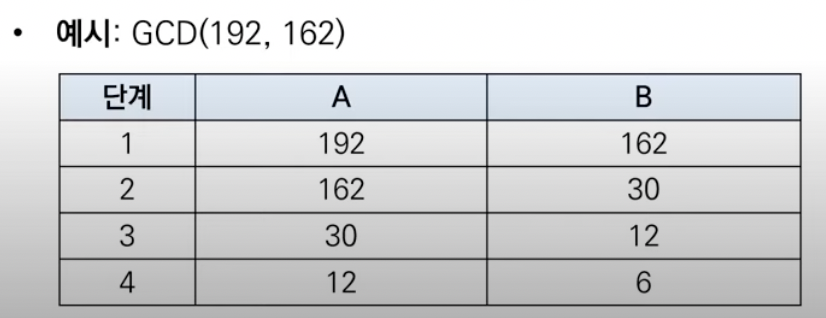
->12는 6의 배수이므로 최대 공약수는 6
def gcd(a,b):
if a%b==0:
return b
else:
return gcd(b, a%b)
print(gcd(192,162))실행결과: 6
재귀함수 사용의 유의 사항
1.재귀함수를 잘 활용하면 복잡한 알고리즘을 간결하게 작성할 수 있다.
▶️단, 오히려 다른 사람이 이해하기 어려운 형태의 코드가 될 수도 있다(신중하게 사용)
2.모든 재귀함수는 반복문을 이용하여 동일한 기능을 구형할 수 있다.
3.재귀함수가 반복문보다 유리할 수도 불리할 수도 있다
4.컴퓨터가 함수를 연속적으로 호출하면 컴퓨터 메모리 내부의 스택 프레임에 쌓인다( 스택을 사용해야 할 때 구현상 스택 라이브러리 대신에 재귀 함수를 이용하는 경우가 많다)
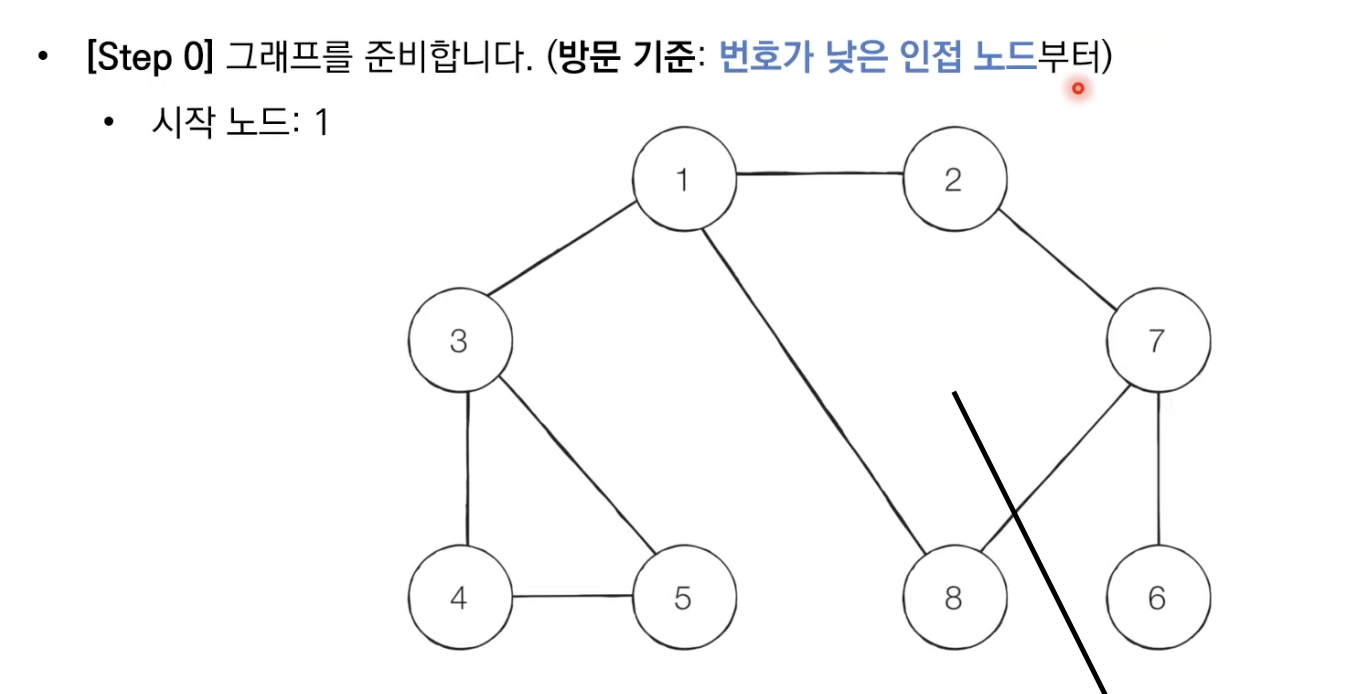
DFS
:깊이 우선 탐색, 깊은 부분을 우선적으로 탐색하는 알고리즘
-스택 자료구조(재귀함수)를 이용한다
1.탐색시작 노드를 스택에 삽입하고 방문처리를 한다
2.스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에넣고 처리한다.(방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다)
3.더 이상 2번의 과정을 수행할 수 없을 때까지 반복한다.
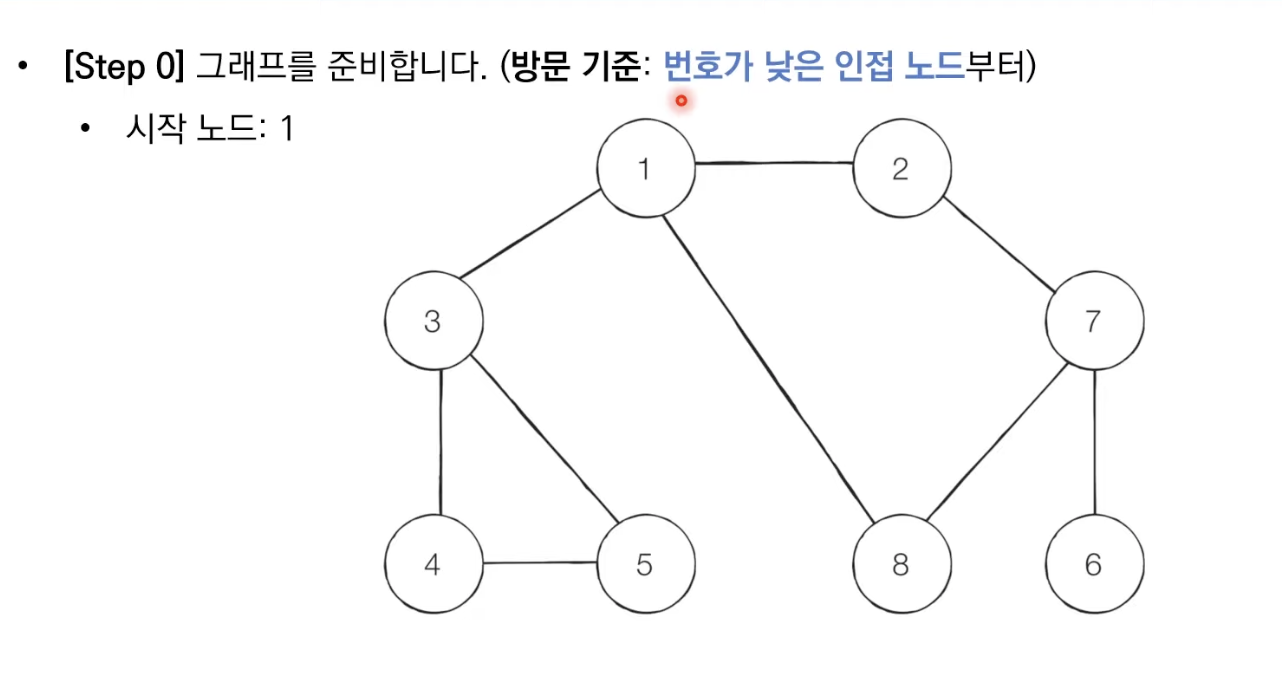

(방문하지 않은 & 가장 작은 노드 선택)
#dfs 메서드 정의
def dfs(graph,v,visited):
visited[v]=True
print(v, end=' ')
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
graph=[ [],[2,3,8],[1,7], [1,4,5], [3,5],[3,4],[7],[2,6,8],[1,7]]
visited=[False]*9
dfs(graph,1,visited)
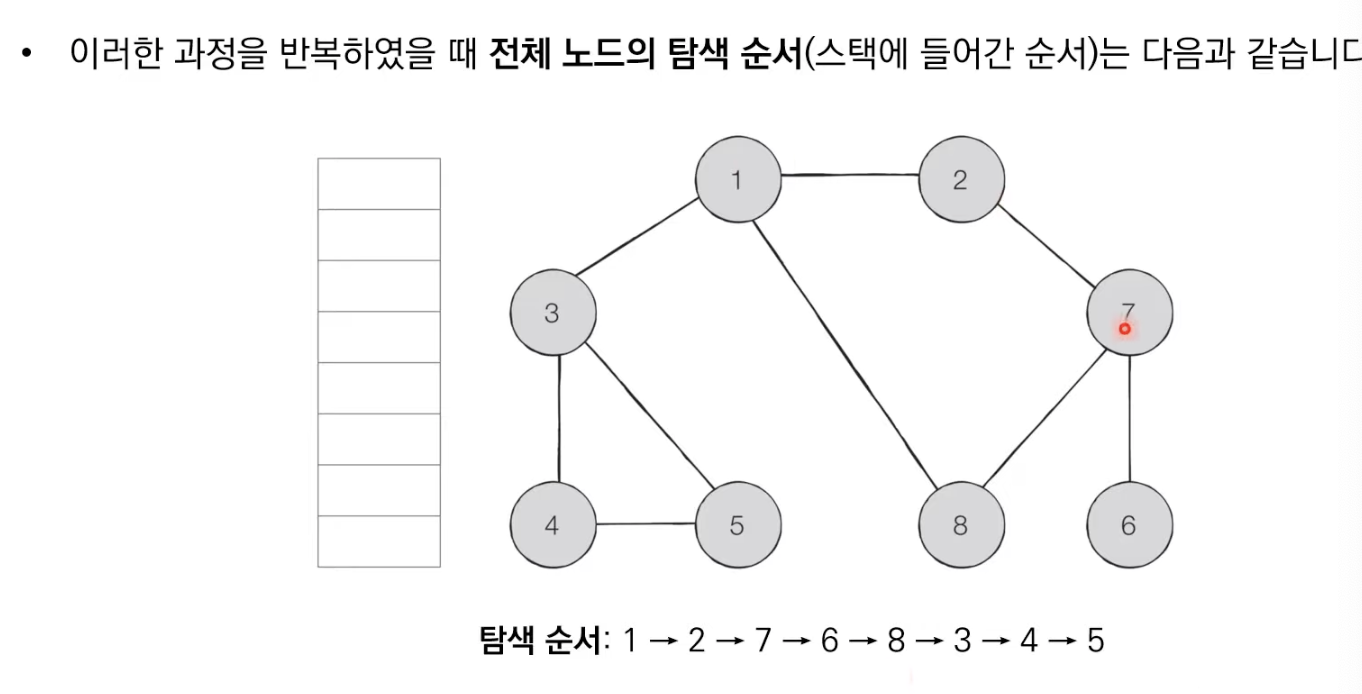
BFS
너비 우선 탐색, 가까운 노드부터 우선적으로 탐색하는 알고리즘
-큐 자료구조 이용
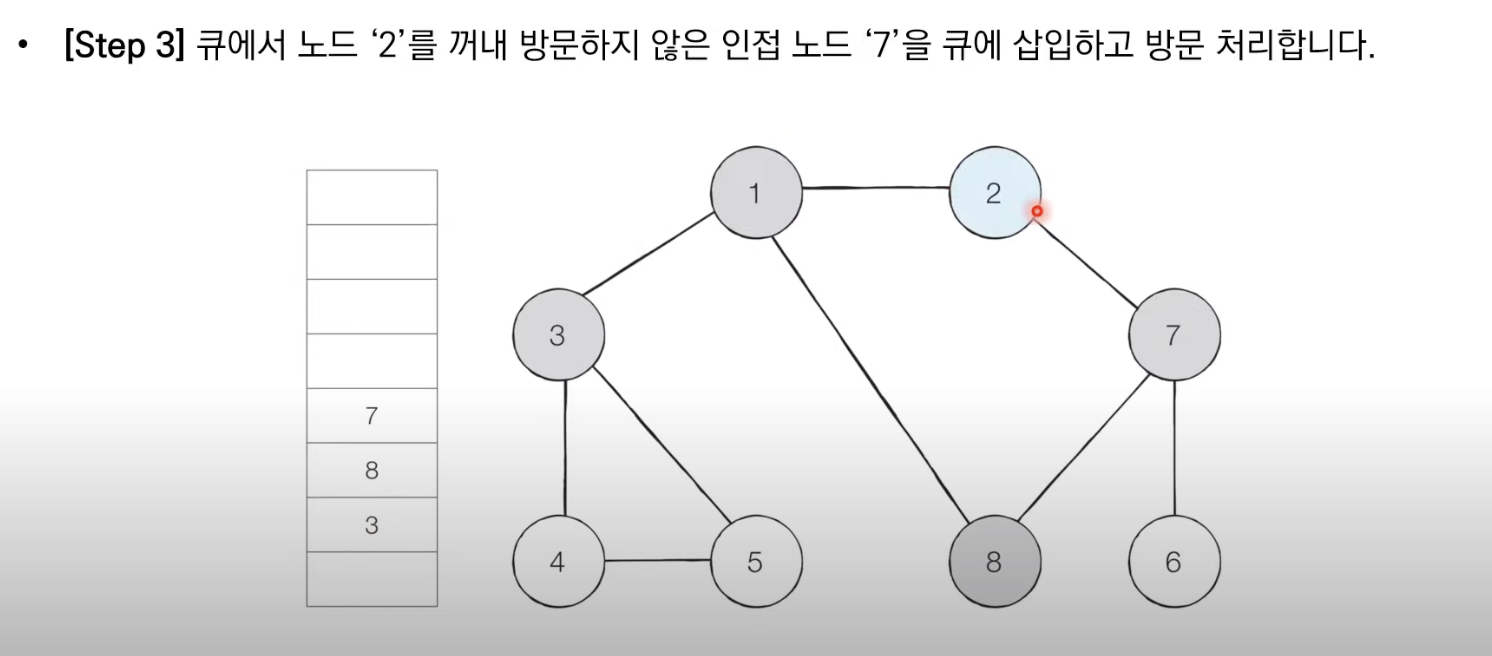
1.탐색 시작 노드를 큐에 삽입하고 방문 처리.
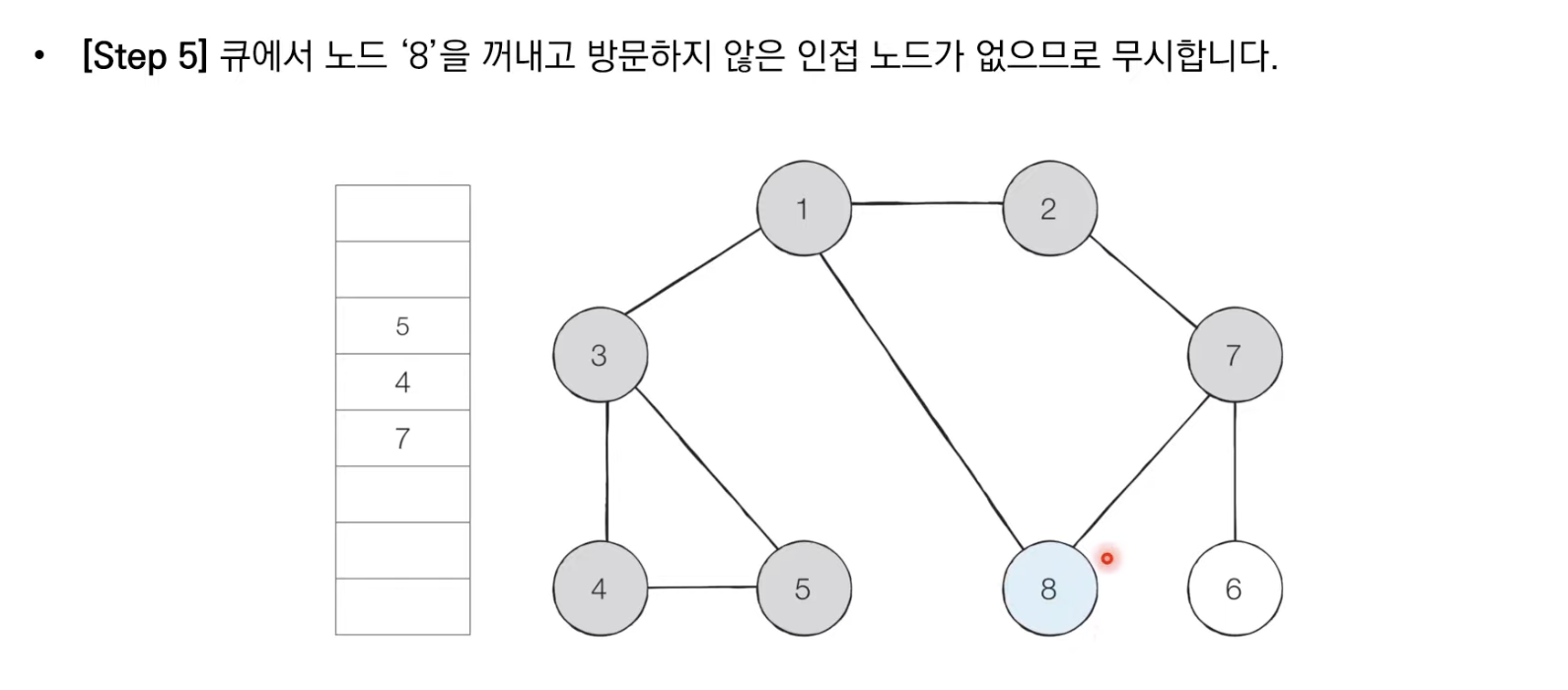
2.큐에서 노드를 꺼낸뒤에 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문처리
3.더이상 2번의 과정을 수행할 수 없을 때까지 반복


거리 0 : 1
거리 1 : 2, 3, 8
거리 2 : 7, 4, 5
거리 3 : 6
from collections import deque
def bfs(graph, start, visited):
queue= deque([start])
visited[start]=True
while queue:
v=queue.popleft()
print(v,end=' ')
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i]=True
graph=[[],[2,3,8],[1,7],[1,4,5],[3,5],[3,4],[7],[2,6,8],[1,7]]
visited=[False]*9
bfs(graph, 1, visited)
실행결과: 1 2 3 8 7 4 5 6



안녕하세요, 😊입니다!! 핵심을 딱딱 정리해주셔서 너무 좋은 것 같아요,,! 저는 아는게 별로 없다보니 책에 있는걸 그냥 다 써서 정신없어 보이는데 파파이썬 님 글을 보니 더 잘 이해가 가는 것 같습니다!! 이번 한주도 같이 힘내봐요!!