✏️문제 (18405) [ 경쟁적 전염 ]
<문제>
NxN 크기의 시험관이 있다. 시험관은 1x1 크기의 칸으로 나누어지며, 특정한 위치에는 바이러스가 존재할 수 있다. 모든 바이러스는 1번부터 K번까지의 바이러스 종류 중 하나에 속한다.
시험관에 존재하는 모든 바이러스는 1초마다 상, 하, 좌, 우의 방향으로 증식해 나간다. 단, 매 초마다 번호가 낮은 종류의 바이러스부터 먼저 증식한다. 또한 증식 과정에서 특정한 칸에 이미 어떠한 바이러스가 존재한다면, 그 곳에는 다른 바이러스가 들어갈 수 없다.
시험관의 크기와 바이러스의 위치 정보가 주어졌을 때, S초가 지난 후에 (X,Y)에 존재하는 바이러스의 종류를 출력하는 프로그램을 작성하시오. 만약 S초가 지난 후에 해당 위치에 바이러스가 존재하지 않는다면, 0을 출력한다. 이 때 X와 Y는 각각 행과 열의 위치를 의미하며, 시험관의 가장 왼쪽 위에 해당하는 곳은 (1,1)에 해당한다.
예를 들어 다음과 같이 3x3 크기의 시험관이 있다고 하자. 서로 다른 1번, 2번, 3번 바이러스가 각각 (1,1), (1,3), (3,1)에 위치해 있다. 이 때 2초가 지난 뒤에 (3,2)에 존재하는 바이러스의 종류를 계산해보자.
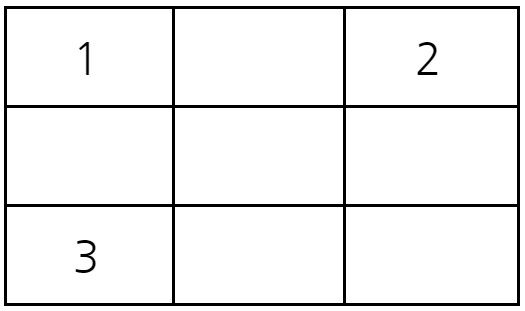
1초가 지난 후에 시험관의 상태는 다음과 같다.
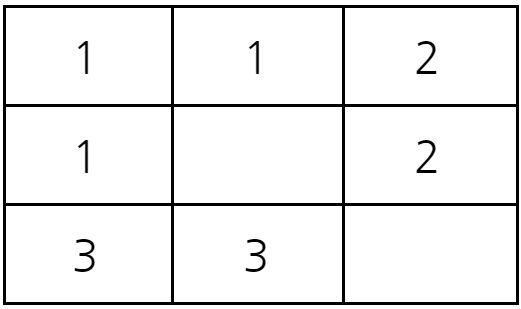
2초가 지난 후에 시험관의 상태는 다음과 같다.
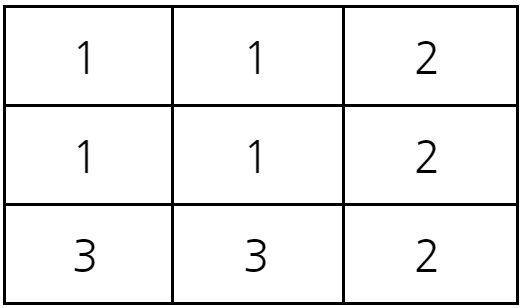
결과적으로 2초가 지난 뒤에 (3,2)에 존재하는 바이러스의 종류는 3번 바이러스다. 따라서 3을 출력하면 정답이다.
입력
첫째 줄에 자연수 N, K가 공백을 기준으로 구분되어 주어진다. (1 ≤ N ≤ 200, 1 ≤ K ≤ 1,000) 둘째 줄부터 N개의 줄에 걸쳐서 시험관의 정보가 주어진다. 각 행은 N개의 원소로 구성되며, 해당 위치에 존재하는 바이러스의 번호가 공백을 기준으로 구분되어 주어진다. 단, 해당 위치에 바이러스가 존재하지 않는 경우 0이 주어진다. 또한 모든 바이러스의 번호는 K이하의 자연수로만 주어진다. N+2번째 줄에는 S, X, Y가 공백을 기준으로 구분되어 주어진다. (0 ≤ S ≤ 10,000, 1 ≤ X, Y ≤ N)
출력
S초 뒤에 (X,Y)에 존재하는 바이러스의 종류를 출력한다. 만약 S초 뒤에 해당 위치에 바이러스가 존재하지 않는다면, 0을 출력한다.
code
from collections import deque
import sys
n,k=map(int, sys.stdin.readline().split())
graph=[]
virus=[] #바이러스 정보
for i in range(n):
graph.append(list(map,int,sys.stdin.readline().split()))
for j in range(n):
if graph[i][j] !=0:
virus.append((graph[i][j],0,i,j))
sec,x,y=map(int,sys.stdin.readline().split())
dx=[0,0,1,-1]
dy=[1,-1,0,0]
data.sort()
q=deque(data)
while q:
v,s,xx,yy=q.popleft()
if sec==s:
break
for k in range(4):
nx=xx+dx[k]
ny=yy+dy[k]
if 0<=nx<n and 0 <=ny<n:
if graph[nx][ny]==0:
graph[nx][ny]=v
q.append((graph[nx][ny],sec+1,nx,ny))
print(graph[x-1][y-1])✏️문제 [괄호 변환]
<문제>
카카오에 신입 개발자로 입사한 "콘"은 선배 개발자로부터 개발역량 강화를 위해 다른 개발자가 작성한 소스 코드를 분석하여 문제점을 발견하고 수정하라는 업무 과제를 받았습니다. 소스를 컴파일하여 로그를 보니 대부분 소스 코드 내 작성된 괄호가 개수는 맞지만 짝이 맞지 않은 형태로 작성되어 오류가 나는 것을 알게 되었습니다.
수정해야 할 소스 파일이 너무 많아서 고민하던 "콘"은 소스 코드에 작성된 모든 괄호를 뽑아서 올바른 순서대로 배치된 괄호 문자열을 알려주는 프로그램을 다음과 같이 개발하려고 합니다.
<용어의 정의>
'(' 와 ')' 로만 이루어진 문자열이 있을 경우, '(' 의 개수와 ')' 의 개수가 같다면 이를 균형잡힌 괄호 문자열이라고 부릅니다.
그리고 여기에 '('와 ')'의 괄호의 짝도 모두 맞을 경우에는 이를 올바른 괄호 문자열이라고 부릅니다.
예를 들어, "(()))("와 같은 문자열은 균형잡힌 괄호 문자열 이지만 올바른 괄호 문자열은 아닙니다.
반면에 "(())()"와 같은 문자열은 균형잡힌 괄호 문자열 이면서 동시에 올바른 괄호 문자열 입니다.
'(' 와 ')' 로만 이루어진 문자열 w가 균형잡힌 괄호 문자열 이라면 다음과 같은 과정을 통해 올바른 괄호 문자열로 변환할 수 있습니다.
- 입력이 빈 문자열인 경우, 빈 문자열을 반환합니다.
- 문자열 w를 두 "균형잡힌 괄호 문자열" u, v로 분리합니다. 단, u는 "균형잡힌 괄호 문자열"로 더 이상 분리할 수 없어야 하며, v는 빈 문자열이 될 수 있습니다.
- 문자열 u가 "올바른 괄호 문자열" 이라면 문자열 v에 대해 1단계부터 다시 수행합니다. 3-1. 수행한 결과 문자열을 u에 이어 붙인 후 반환합니다.
- 문자열 u가 "올바른 괄호 문자열"이 아니라면 아래 과정을 수행합니다.
4-1. 빈 문자열에 첫 번째 문자로 '('를 붙입니다.
4-2. 문자열 v에 대해 1단계부터 재귀적으로 수행한 결과 문자열을 이어 붙입니다.
4-3. ')'를 다시 붙입니다.
4-4. u의 첫 번째와 마지막 문자를 제거하고, 나머지 문자열의 괄호 방향 을 뒤집어서 뒤에 붙입니다.
4-5. 생성된 문자열을 반환합니다.
code
시간이 너무 오래 걸려서 복습시간에 풀어봐야겠다✏️문제 [DFS와 BFS]
<문제>
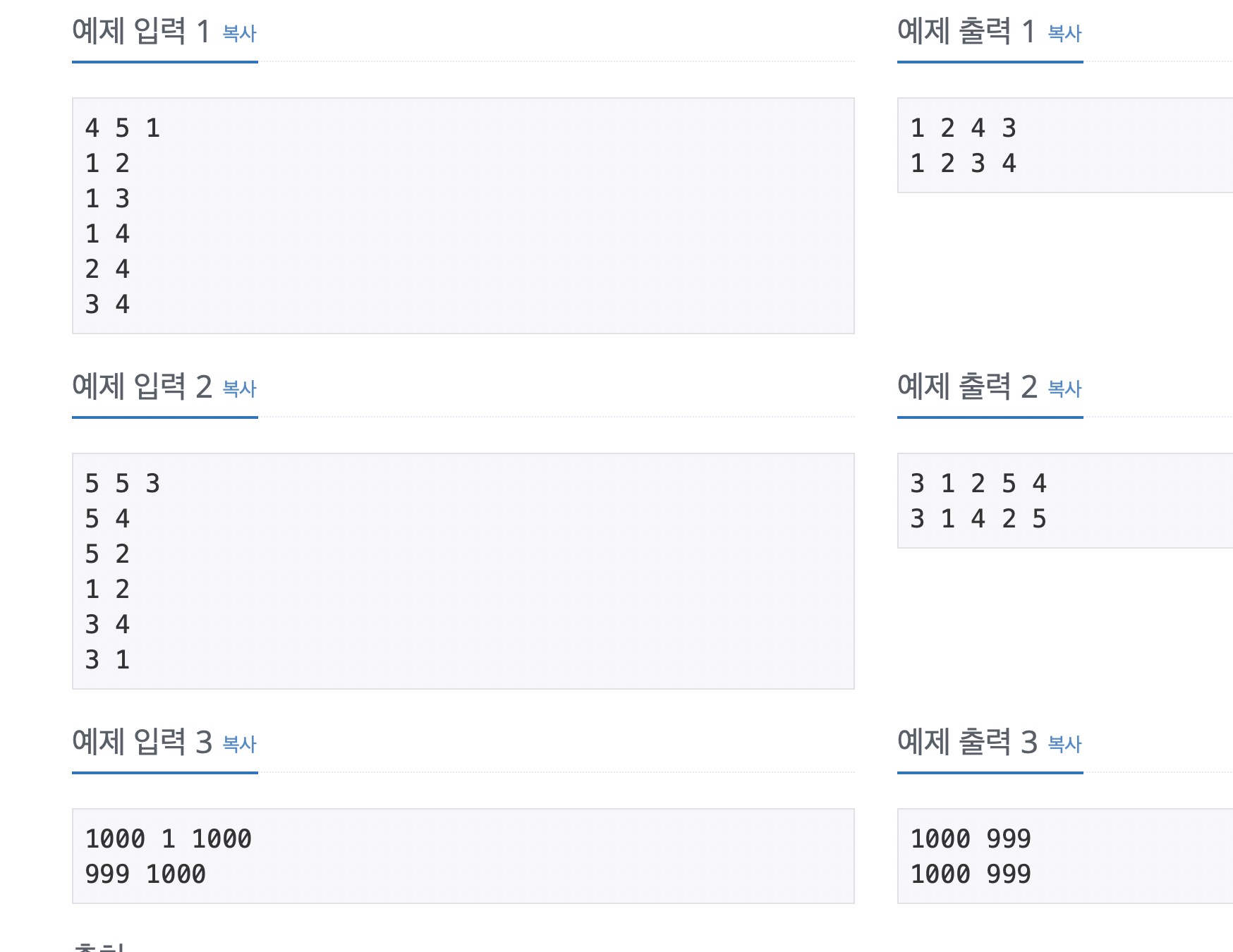
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
출력
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
code
n,m,v=map(int,input().split())
matrix=[[0]*(n+1) for i in range(n+1)]
for i in range(m):
a,b = map(int,input().split())
matrix[a][b]=matrix[b][a]=1
visit_list=[0]*(n+1)
def dfs(v):
visit_list[v]=1 #방문한 점 1로 표시
print(v, end=' ')
for i in range(1,n+1):
if(visit_list[i]==0 and matrix[v][i]==1):
dfs(i)
def bfs(v):
queue=[v] #들려야 할 정점 저장
visit_list[v]=0 #방문한 점 0으로 표시
while queue:
V=queue.pop(0)
print(v, end=' ')
for i in range(1, n+1):
if(visit_list[i]==1 and matrix[V][i]==1):
queue.append(i)
visit_list[i]=0
dfs(V)
print()
bfs(V)참고 블로그:
https://velog.io/@i-zro/파이썬Python-코테-대비-DFSBFS-백준-1260번-DFS와-BFS
가장 풀이가 쉬웠던 것같다.. 이렇게 보니..정말 어렵지만은 않네...복습하면서 다시 풀어봐야지



안녕하세요 😊입니다!! 저도 파파이썬님이 어제 올려주신 import sys 글 참고해서 전염문제 풀어봤는데 오류가 났어요,, 파파이썬님은 잘 활용해서 푸신 것 같아 부러워요!! 저도 다시 공부해봐야겠어요😂 마지막 문제 저랑 같은 블로그 참고하신 것 같아 반갑네요~~ ㅎㅎ ㅎ