좋은 모델 학습을 위한 기초
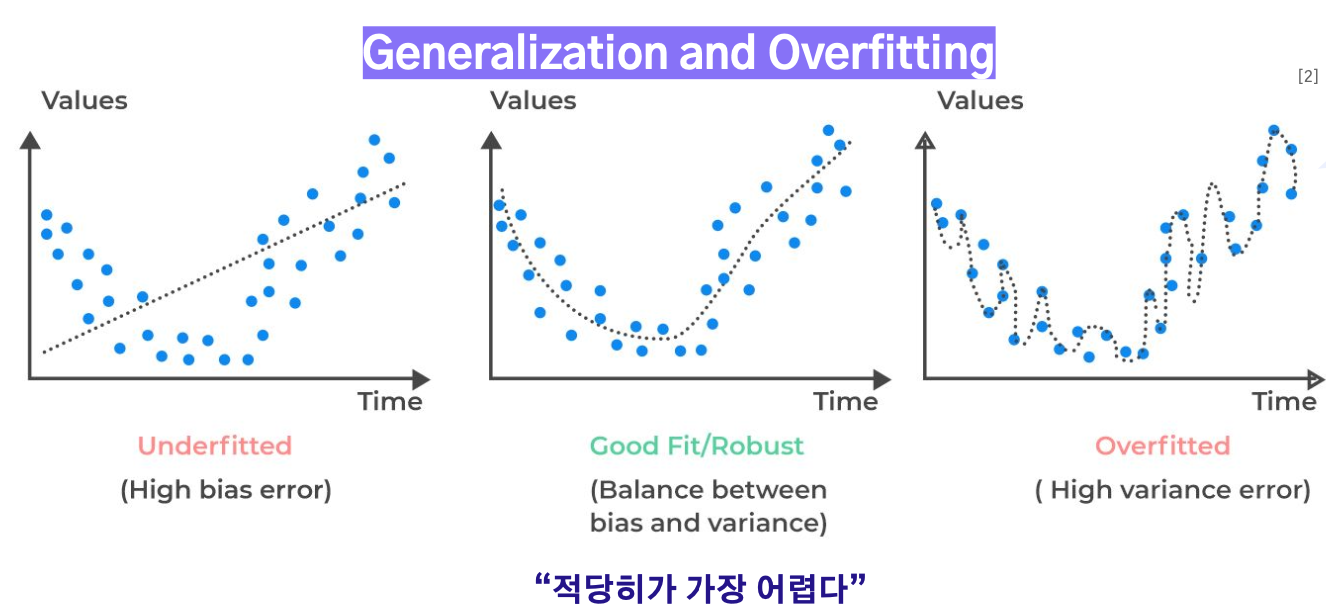
과적합
과적합은 모델이 학습 데이터에 너무 맞춰져 일반화하지 못하는 현상
편향과 분산
편향은 모델의 예측이 실제 값에서 일관되게 벗어나는 정도
분산은 예측이 학습 데이터의 작은 변화에 얼마나 민감한지의 표현
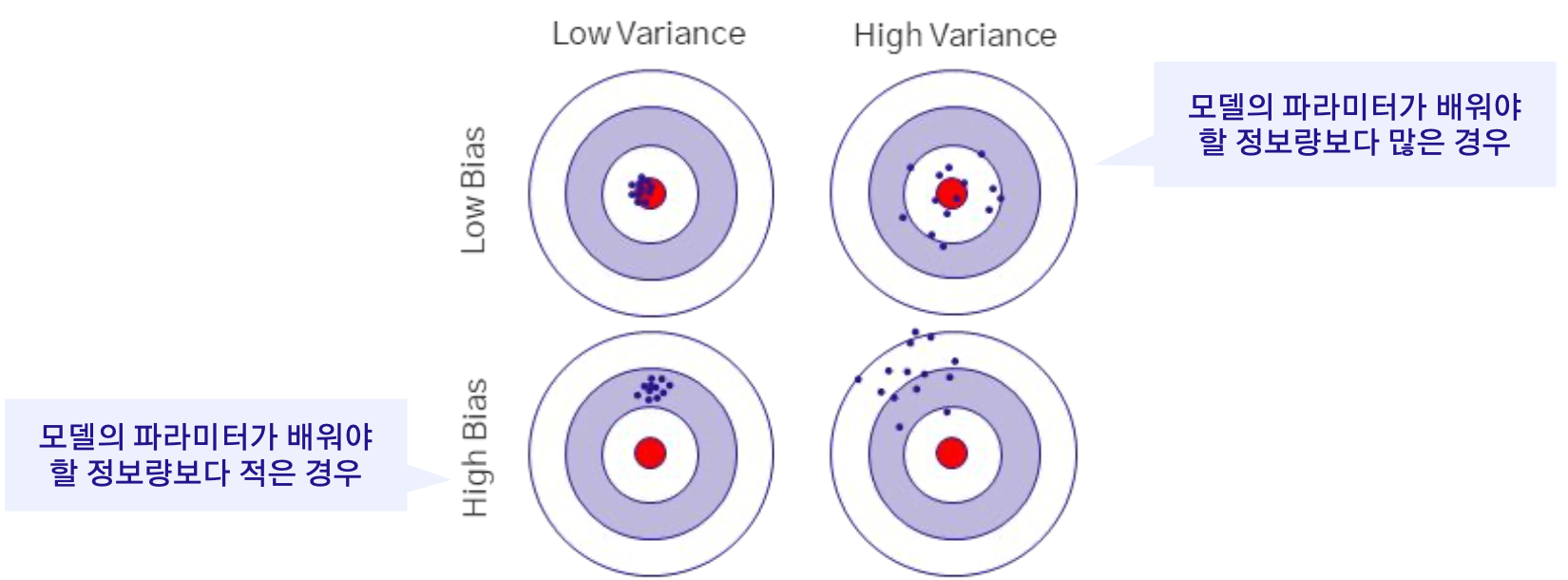
모델의 복잡성이 증가하면 분산은 증가하고 편향은 감소, 모델의 복잡성이 감소하면 편향은 증가하고 분산은 감소하는 경향이 있다.
따라서 모델을 설계하고 학습할 때는 편향과 분산 두 가지를 동시에 최소화하는 방향으로 Trade-off를 고려해야한다.
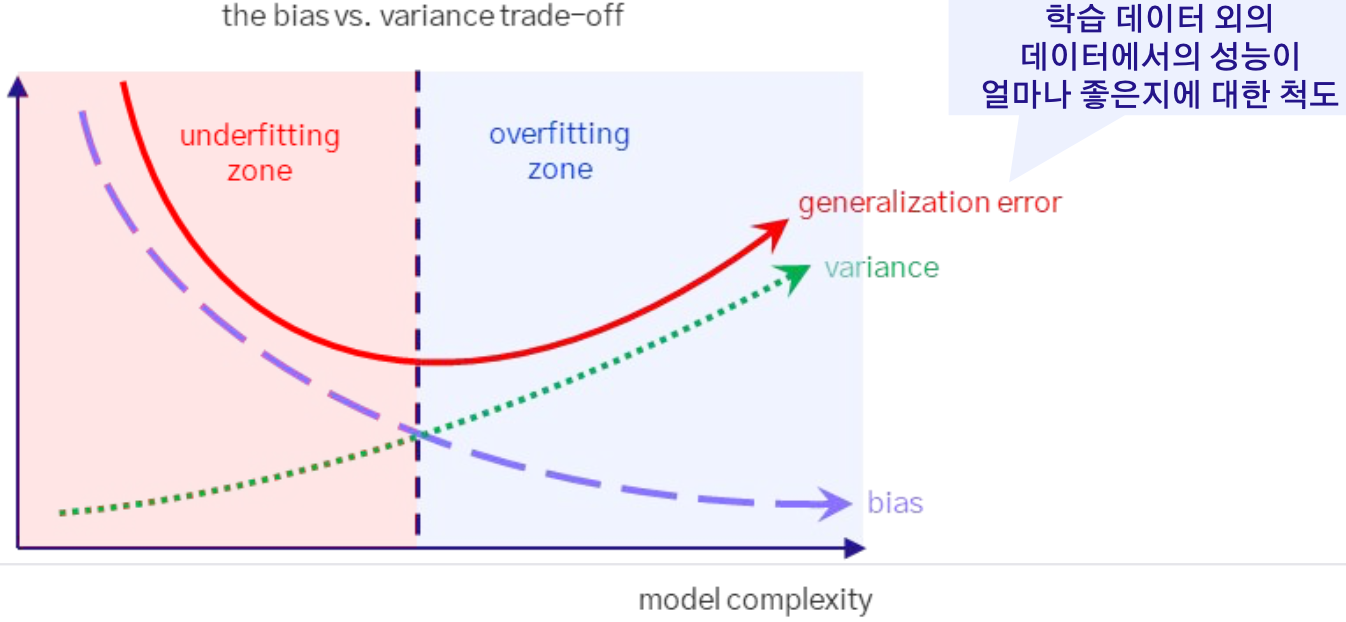
이는 매우 중요하지만 어려운 작업으로, 적절한 복잡성을 가진 모델을 선택함으로써 평가 데이터에 대한 성능을 최대화하는 것이 목표
Dropout
임의의 가중치 노드(뉴런)를 일정 확률로 비활성화시키는 방법
- 학습이 잘 된 모델이라면, 모델 중 일부 노드를 비활성화시켜도 여전히 좋은 성능을 유지할 것으로 기대
- 일반화가 잘 된 모델이라면 일부 노드가 없다고
(약간의 노이즈가 있다고) 성능 감소 X
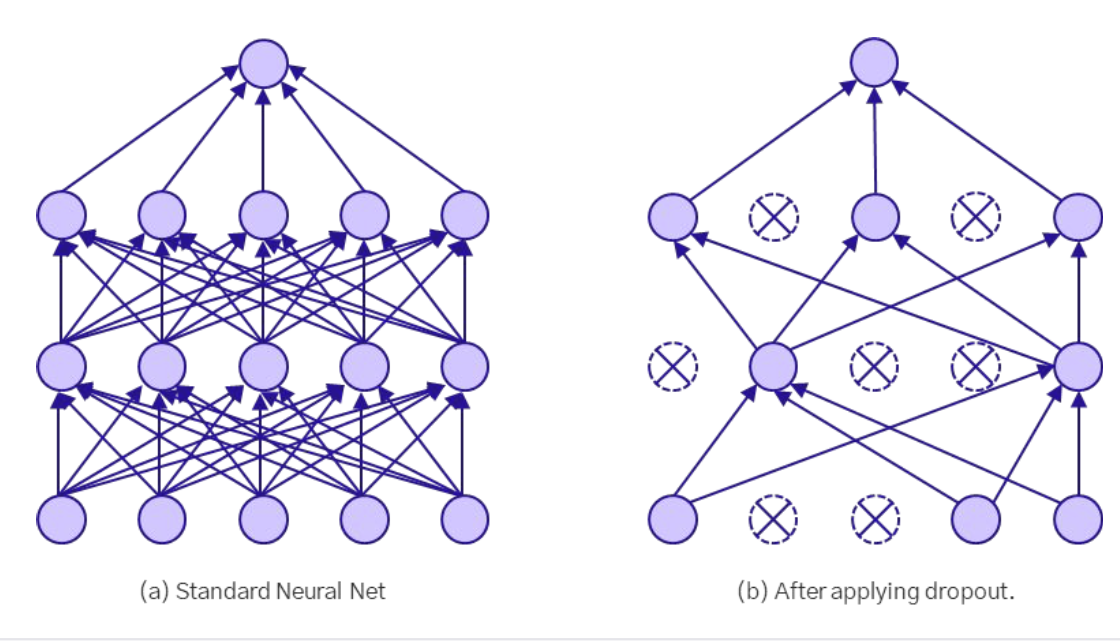
- 과적합을 방지하기 위해서 모델의 중간 가중치 노드에 노이즈를 주면서 학습이 진행되지 않게끔 한다.
- 모델 학습 중에는 손실함수에 대한 기울기(Gradient)가 흐르지 않아 가중치 업데이트가 되지 않는다.
class Dropout:
def __init__(self, dropout_ratio =0.5):
# dropout 할 뉴런의 비율 =0.5
# 0.5는 50%의 뉴런을 무작위로 꺼버림
self.dropout_ratio = dropout_ratio
# mask: dropout할 뉴런을 결정하는 boolean mask
# 오직 학습 시에만 사용
self.mask = None
def forard(self,x,train_flg = True):
# 학습 시(train_flg가 True일 때)
if train_flg:
# 입력 데이터 x와 동일한 모양의 무작위 배열 생성
# dropout_ratio보다 큰 값만 True로 설정
# 이로써 어떤 뉴런을 꺼버릴 지 결정.
self.mask = np.random,rand(*x.shape) > self.dropout_ratio
#mask를 사용해 x의 일부 뉴런을 꺼버림.
return x* self.mask
# 테스트 시 ( train_flg가 false일때)
else:
return x*(1.0 - self.dropout_ratio)
# 역전파 함수
def backward(self, dout)"
# mask를 사용하여, 순전파 때 꺼진 뉴런은 그래디언트도 전달되지 않게함.
return dout * self.mask
# 테스트 시에는 모든 뉴런을 사용
⇒ 학습 시보다 뉴런의 수가 많아져 전체적인 활성화 출력의 크기가 증가하기 때문 Normalization
Feature Scaling
서로 다른 입력 데이터의 값을 일정한 범위로 맞추는 작업. 이러한 연산을 통해서 모델 학습시 모든 특징(Feature)을 편향없이 학습할 수 있다. 딥러닝에서는 일반적으로 0과 1 사이로 정규화를 거친다.
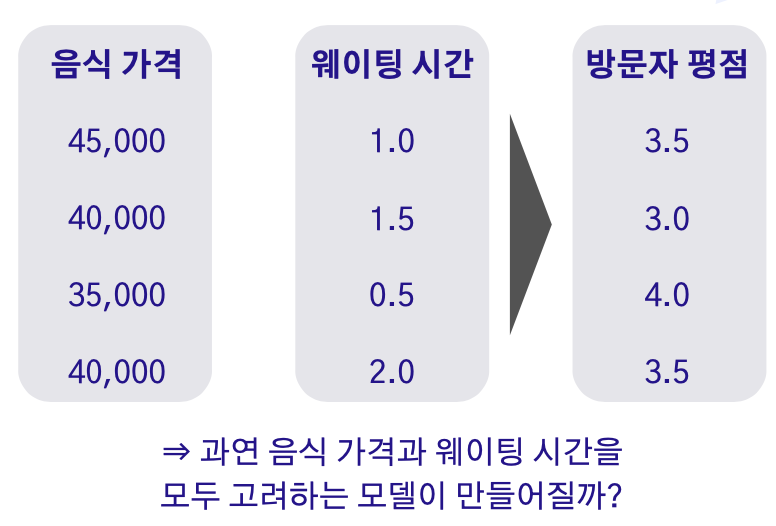
-
음식 가격 피처의 크기가 웨이팅 시간 피처보다 훨씬 커서 웨이팅 시간이 묻힐 수 있음.
-
피쳐스케일링은 입력 간에서의 스케일링
중간 레이어 단계에서의 scaling
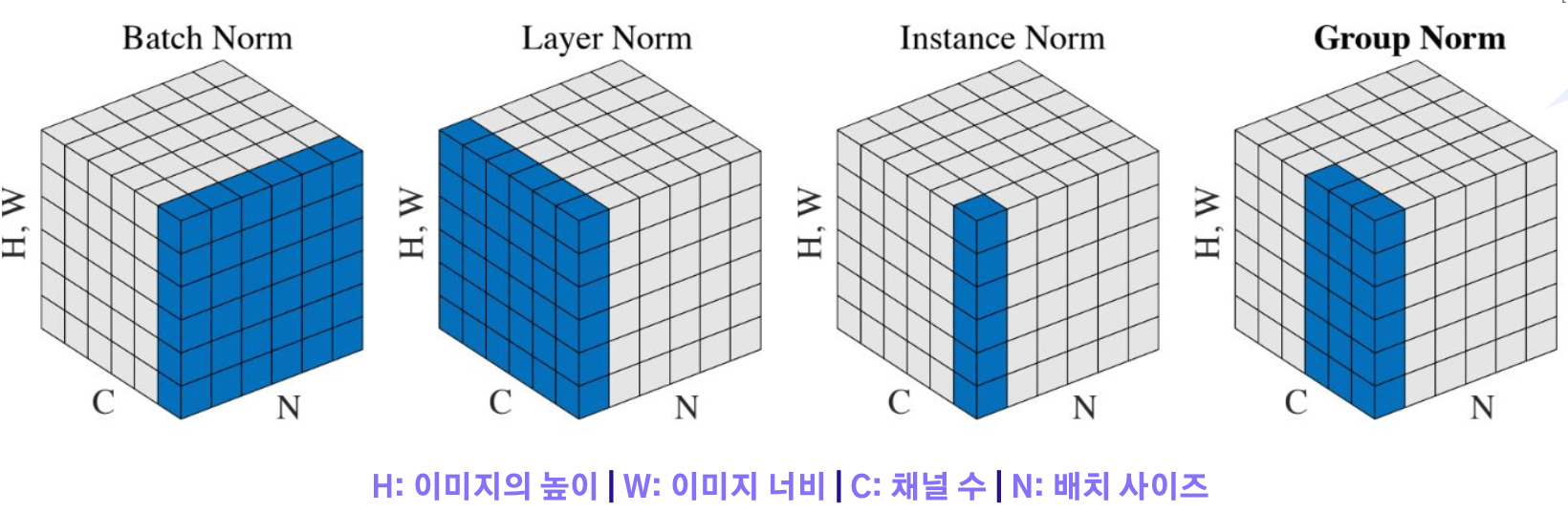
- 배치 정규화: 배치 단위로 학습시 발생할 수 있는 분포를 정규화하여 모델 학습을 안정화함
- 레이어 정규화: 시계열 데이터와 같은 가변적인 입력에서 적용이 힘든 배치 정규화의 단점을 보완함
- 인스턴스 정규화: 이미지 스타일 변환와 같이 각 데이터만의 고유한 정보를 유지할 때 이용
- 그룹 정규화: 인스턴스 정규화의 확장 버전으로 배치 사이즈의 크기가 작아도 잘 동작하는 방법을 제안
배치 정규화를 해야하는 이유 1.
3층 레이어를 가지고 각 레이어의 활성화 함수로 시그모이드를 사용한다고 가정해보자.
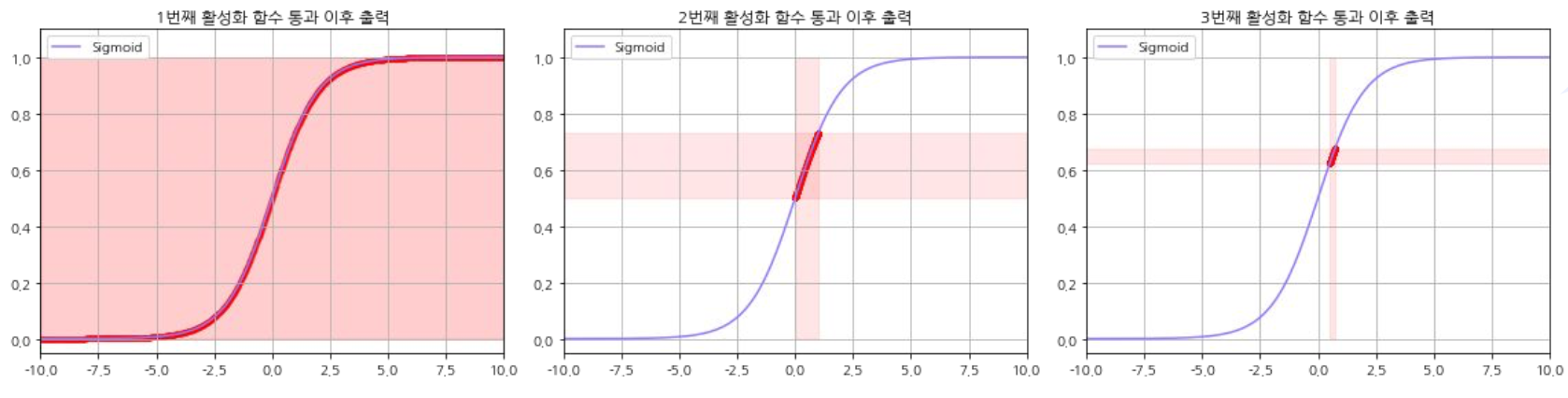
이는 깊은 모델의 경우 기울기 소실 문제이나 기울기 폭발 문제와 같은 치명적인 문제로 이어질 수 있다.
배치 정규화를 해야하는 이유 2.
일반적으로 모델 학습 과정에서 내부 데이터 분포 변화(Internal Covariate Shift)가 발생으로 인해 모델이 제대로 학습하지 못하게 될 수 있다. 이러한 현상은 모델의 각 층에서 발생하는 파라미터 업데이트로 인해 다음 층의 활성화 값들의 분포가 변화하기 때문에 발생한다. 이로 인해 네트워크의 학습이 느려지거나 불안정해질 수 있다.
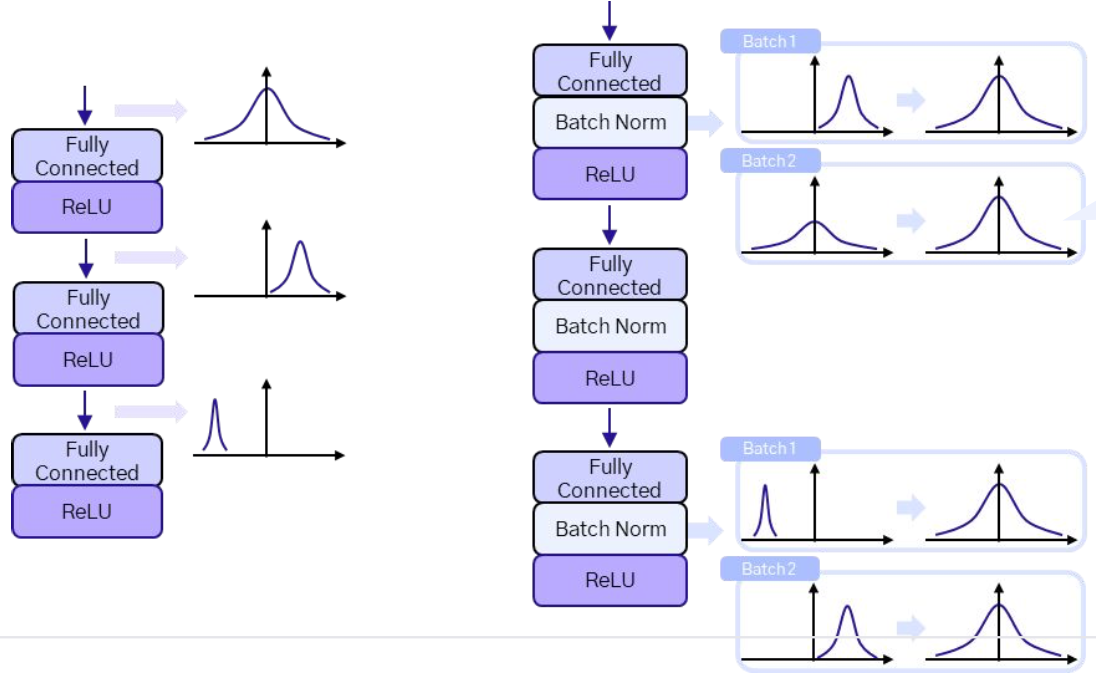
- 데이터가 레이어를 통과해도 배치 정규화로 인해 분포가 일정
배치 정규화 논문의 저자들에 의하면,
1) 완전 연결 레이어 이후, 2) 활성화 함수를 적용하기 전에 적용하는 것을 추천한다. 배치 정규화의 목적이 출력을 의도한대로 나오게 하는데 있기 때문이다.
