의미 기반의 언어 지식 표현 체계
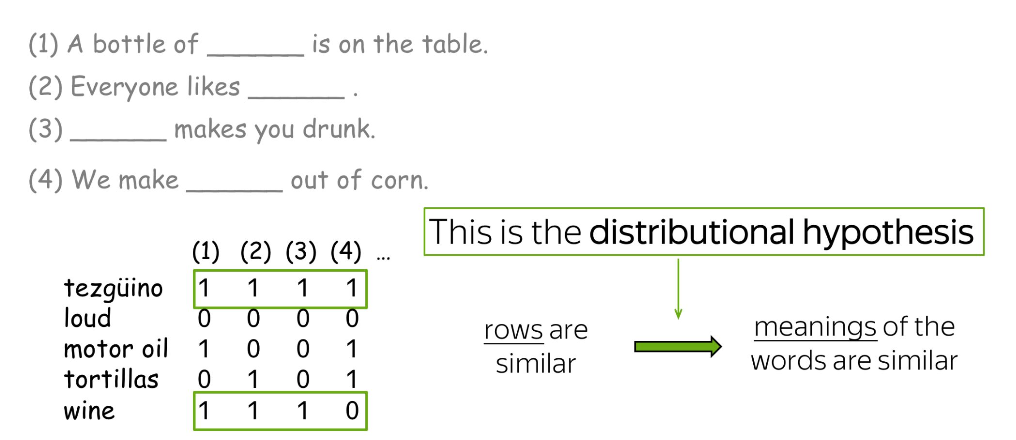
분포 가설
- “단어가 나타나는 주변 맥락이 유사하면, 그 단어들의 뜻도 서로 비슷하다”는 것을 의미
- 즉, 비슷한 의미를 가진 단어는 주변 단어 분포도 비슷함을 의미
- “단어의 의미는 그 단어가 사용되는 맥락에 의해 결정된다”라는
아이디어를 기반으로 단어의 의미를 이해하는 방법론 - ex) Tesgüino와 wine이 등장하는 주변 문맥이 비슷하므로, 두 단어는
유사함
One-Hot Vector
- 단어의 해당하는 인덱스에 1을, 나머지에 0을 할당하여 이루어진 범주형 벡터 (Discrete vector)
- 단어의 수가 많을 때 벡터의 차원이 매우 커져 계산 효율이 낮으며, 단어 벡터가 다른 단어간의 유사도를
반영하지 않음 - 즉, 분포 가설에 기반한 단어의 의미론적 정보를 반영하지 못하는 초기의 방법
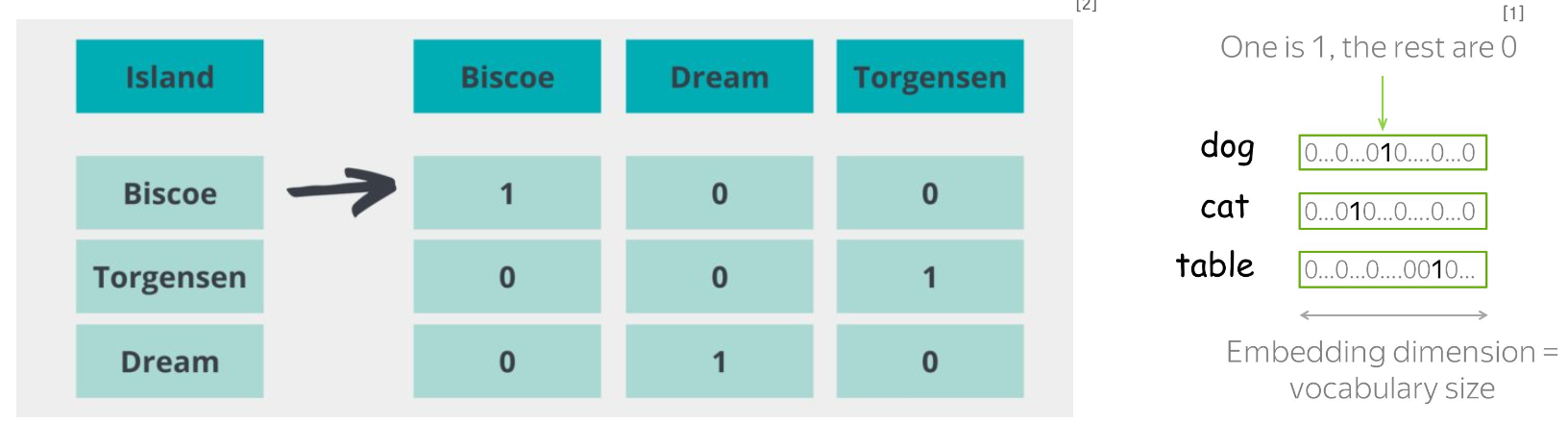
단어 임베딩 (Word Embeddings)
- 단어를 고정된 길이의 밀집 벡터(Dense Vector)로 표현하는 기법
- 단어 벡터가 단어의 의미적, 문법적 특성을 포착할 수 있는 수치적 특성을 가지고 있어, 비슷한 의미를 가진 단어들이 벡터 공간에서 서로 가까이 위치함
- "king"과 "queen"의 벡터는 서로 가깝고, "king" - "man" + "woman"
과 같은 벡터 연산이 "queen"에 가까운 결과를 낼 수 있음
- 입력된 문장을 임베딩으로 변환하기 위해, 각 단어를 Vocabulary에서 조회하여 해당하는 밀집 벡터(Dense Vector)를 사용
- Vocabulary: 단어들의 집합으로, 각 단어는 고유한 인덱스에 매핑되며, 이 인덱스를 사용하여 임베딩 매트릭스에서 해당 단어의 밀집 벡터를 조회하는 룩업 테이블

Word2Vec
- 문맥 예측 (Prediction-based) 기반의 단어 벡터 학습 및 표현 방법공존 행렬 (Co-occurrence Matrix) 기반의 단어 벡터 학습 및 표현 방법
- Word2Vec은 매개변수가 단어 벡터인 모델로, 특정 목표에 대해 반복적으로 최적화
- 분포 가설을 바탕으로, 벡터가 문맥에 대해 알면 단어 의미도 알게 됨을 기반으로 함
- Word2Vec는 학습 방법에 따라 CBoW와 Skip-Gram로 구분
CBow (Continuous Bag of Words)
- 주변 단어들의 맥락을 통해 중심 단어를 예측하는 방식의 Word2Vec 신경망
- 주변 단어들의 문맥 벡터를 합치거나 평균내어 중심 단어를 예측하는 확률을 최대화하는
방향으로 학습
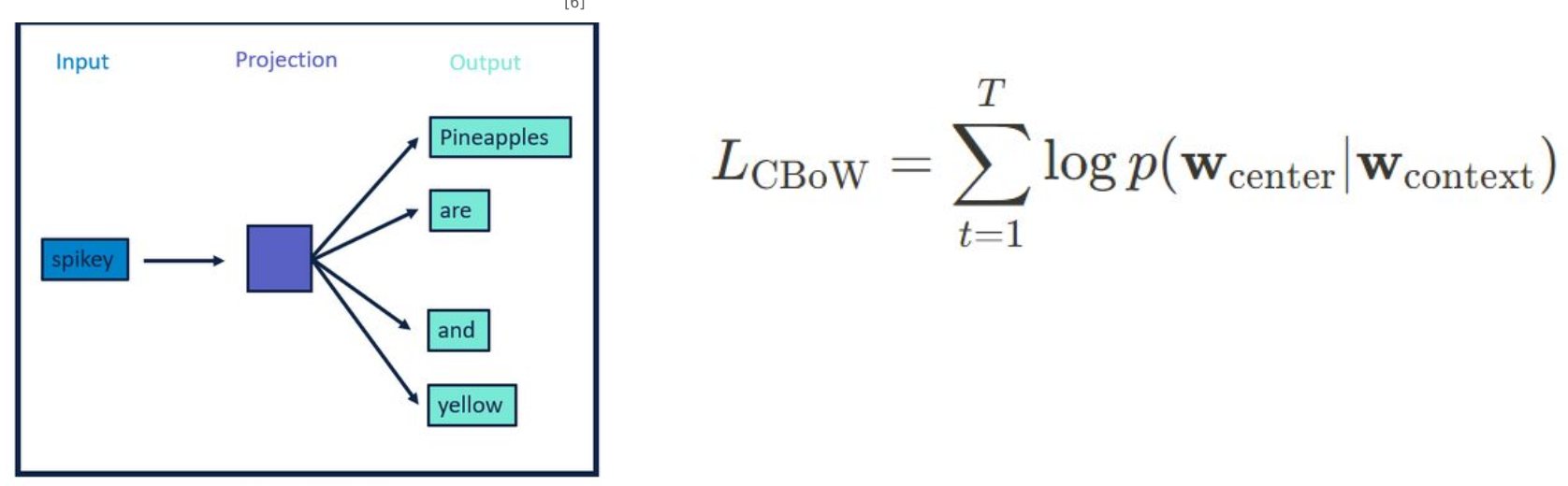
Skip-gram
- 중심 단어로부터 주변 단어들을 예측하는 방식의 Word2Vec 신경망
- 중심 단어의 분산 표현을 사용하여 그 주변에 등장할 가능성이 있는 단어들의 확률을 최대화
하는 방향으로 학습단어 벡터 학습
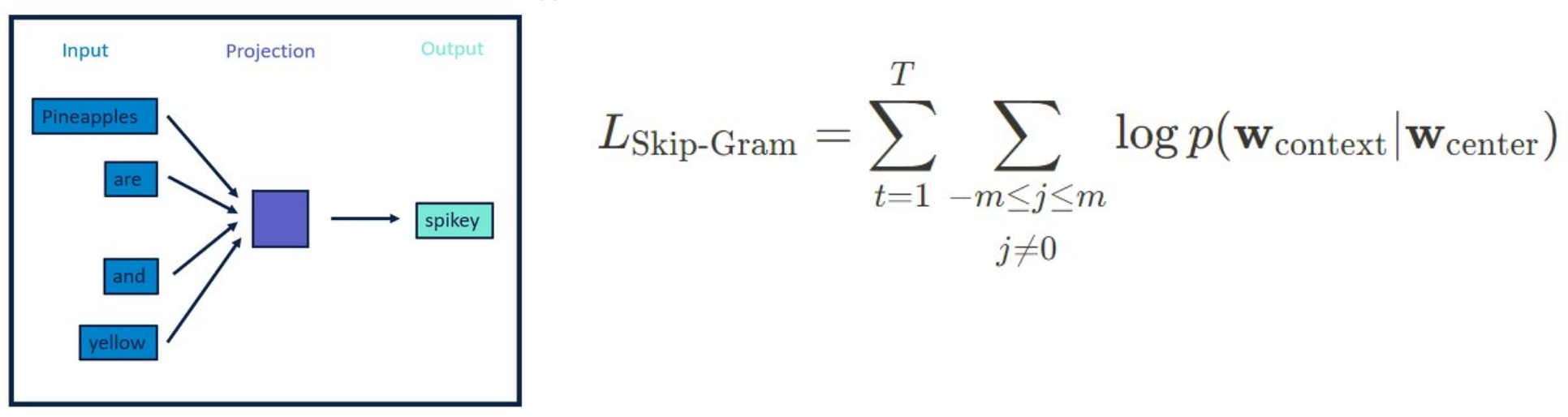
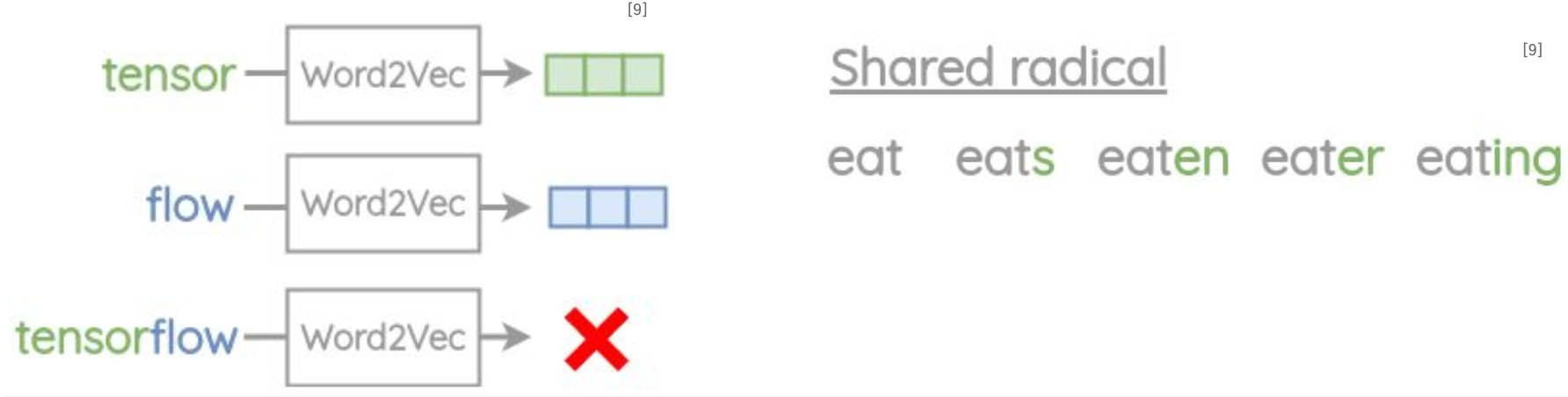
Word2Vec의 문제점
• Out of Vocabulary(OOV) 문제: 학습 중 만나지 않은 새로운 단어나 합성어에 대해 임베딩을 생성할 수 없음
• 형태학적 유연성 부족: 동일한 어근을 공유하는 단어들 간의 매개변수 공유가 없어, 단어의 내부 구조를 활용하지 못함
Glove
- 공존 행렬 (Co-occurrence Matrix) 기반의 단어 벡터 학습 및 표현 방법
- 벡터 간의 dot-product가 단어 쌍의 공존 확률의 로그 값과 같아지도록 학습하여, 단어 간 유사성과 차이를 벡터 공간에 인코딩함
- Word2Vec과 달리 지역적인 문맥 정보만을 사용하는 것이 아니라, 코퍼스 전체의 통계 정보를 바탕으로 단어 벡터를 학습함
FastText
FastText의 개선 방법
-
Subword 단어 분해: 중심 단어의 임베딩은 n-그램 벡터의 합으로 계산되며, 문맥 단어의 벡터는 n-그램을 추가하지 않고 사용함 (Word2Vec의 Skip-gram 개선)
-
Negative Sampling: 실제 문맥 단어 주변에 negative sample을 무작위로 선택하여 임베딩을 최적화
- 문맥 예측 (Prediction-based) 기반으로 서브워드 정보를 포함하는 단어 벡터 학습 및 표현 방법
- 단어를 n-그램 서브워드로 분해하여 내부 구조를 반영, 벡터를 통해 단어의 형태학적 특성을 학습함
- Word2Vec을 확장하여 희귀 단어나 오타에 대한 내성을 강화하고, 보다 풍부한 단어 표현을 제공
FastText 과정
1) FastText의 Subword 단어 분해
- 기존 단어 기반의 임베딩을 3-6 grams 으로 분해하여, OOV 및 형태학적 유연성 확보

- Hashing 기법을 활용하여, 분해된 n-gram의 메모리 사항을 제한

2) FastText의 Negative Sampling
- 중심 단어에 대한 임베딩은 문자 n-gram과 전체 단어 자체에 대한 벡터의 합을 취하여 계산

- 문맥에 등장하는 단어들은 n-gram으로 분리하지 않고, 단어 벡터를 가져옴

- 유니그램 빈도의 제곱근에 대한 확률 비율로 Negative Sample을 무작위 수집 (문맥단어 1개당 5개의 Negative Sample 수집)

- 중심 단어와 문맥 단어 사이의 내적 후 시그모이드를 취하여 0과 1사이의 점수를 얻고, SGD를 통해 실제 문맥 단어를 중심 단어에 더 가깝게, Negative samples을 더 멀게 최적화

Word2Vec VS FastText
Doc2Vec
- 문맥 예측 (Prediction-based) 기반으로 문서 전체의 벡터를 의미공간에 학습 및 표현하는 방법. 즉, 단어 벡터 혹은 서브워드 벡터가 아닌 문서 벡터 단위의 모델
- 단어뿐만 아니라 문장, 문단, 전체 문서를 고유한 벡터로 변환하며, 문서의 순서와 구조를 포함한 정보를 학습함
- Word2Vec의 확장으로, 문서의 의미를 벡터화하여 문서 간 유사성 측정 및 문서 분류 작업에 활용함
CoVe
- 시퀀스 모델링 (Sequence Modeling) 기반의 단어 벡터 학습 및 표현 방법
- 사전 훈련된 기계 번역 모델에서 단어의 문맥적 임베딩을 추출하여, 단어가
사용된 문맥을 더 잘 반영함 - 단어의 고정된 임베딩 대신, 문맥에 따라 변화하는 동적인 단어 벡터를
제공하여 보다 정교한 자연어 이해를 가능하게 함 - 단어가 각기 다른 문맥에서 등장할 때 그에 따라 달라지는 의미를 포착하여,
문맥에 민감한 단어 벡터를 생성
CoVe의 학습과정
• a) 기계번역 모델 학습: Bi-directional LSTM 구조에 Machine Translation 학습
• b) 다른 NLP Task에 적용: 기계 번역 모델의 인코더 context vector와 GloVe 모델을 활용하여
문맥적 정보를 함축한 벡터를 추출하고, 다른 NLP task에 적용

Real Cryptocurrency Trader & AI Engineer LV.0