카운트 기반의 단어 표현
단어의 표현 방법
국소 표현 vs 분산 표현
-
국소 표현(Local Representation): 해당 단어 그 자체만 보고, 특정 값을 맵핑하여 단어를 표현하는 방법 예) 고양이: 1, 귀여운: 2, 동물: 3
-
분산 표현(Dense Representation): 그 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법 예) ‘고양이’ 단어 주변에 ‘귀여운’과 ‘동물’이 자주 등장 => 고양이는 귀엽다, 동물이다로 인식
Bag of Words(BoW)
-
단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
-
어휘의 빈도(개수)를 기반으로 통계적 언어 모델을 적용해서 나타낸 것 => 국소 표현에 해당
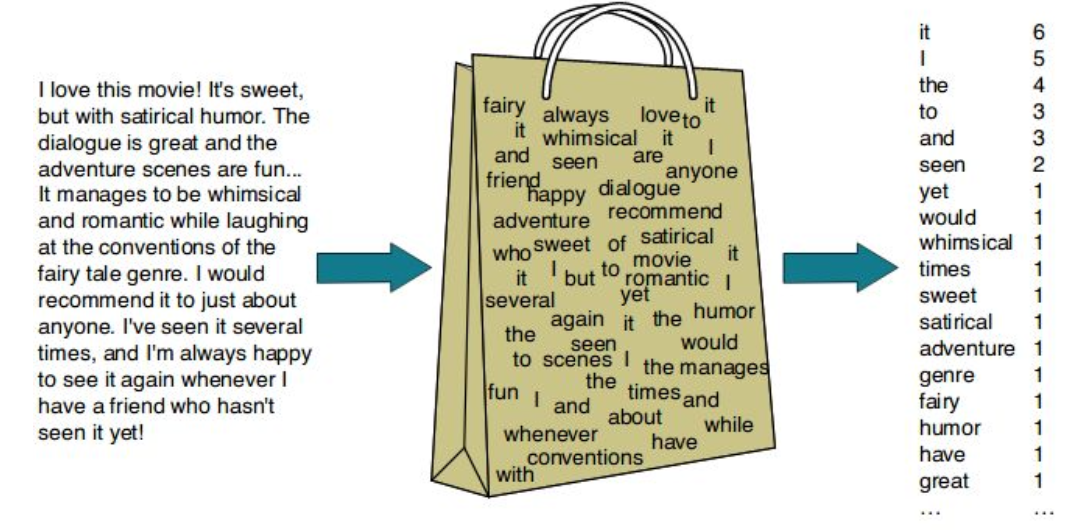
Bag of Words의 구성 방법
- 1 문서 내 단어별로 고유의 정수 인덱스를 할당하여 단어 집합(Vocabulary) 생성
- 2 단어별 인덱스에 단어의 출현 빈도를 저장한 BoW 벡터 생성
Bag of Words의 특징
-
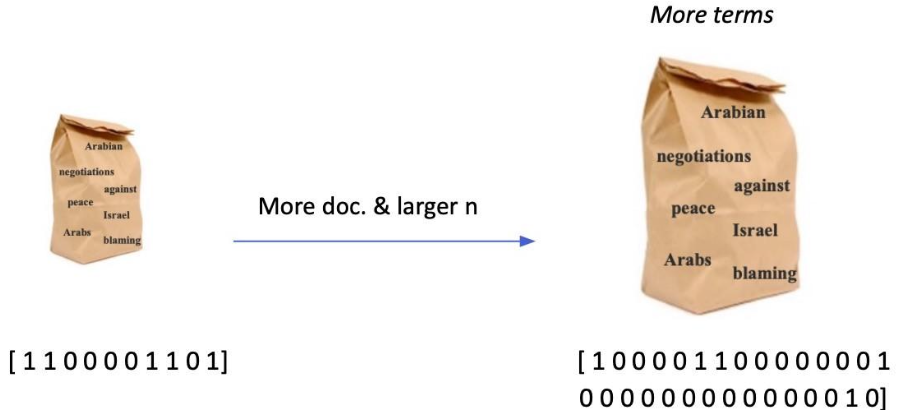
임베딩 벡터의 차원 = 단어의 개수 = 모델의 크기
- 등장하는 단어가 많아질수록 증가
- N-gram의 n이 커질수록 증가
-
단어의 분절이 정확하게 되었을 때 유용
-
단어의 여러 의미를 반영하지 못함 => 동음이의어, 다의어에 대한 의미 표현 불가
02 TF-IDF
TF-IDF 개요
-
Term Frequency (TF): 단어의 등장빈도
-
Inverse Document Frequency (IDF): 단어가 제공하는 정보의 양
-
ex) He is the president of UK.
→ He, is, the, of: 자주 등장하지만 제공하는 정보량이 적음 → president, UK: 좀 더 많은 정보를 제공
단어마다 제공하는 정보량이 서로 다르다는 것을 통계적으로 계산함
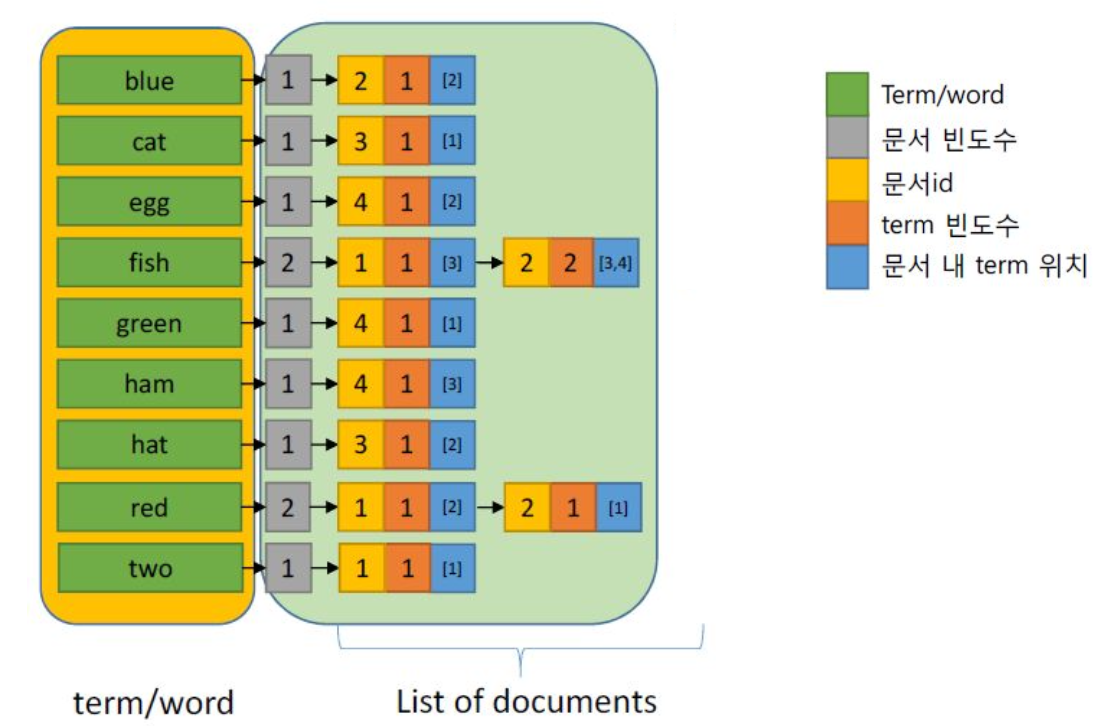
Inverted Index
특정 용어가 어느 문서들에서 발생하는지 빠르게 찾을 수 있도록 구성된 데이터 구조,
용어와 해당 용어가 포함된 문서의 위치를 매핑
- 불용어 (stopword)
• 모든 문서에 자주 사용되어 색인어로 문서를
구분해주는 가치가 없는 어휘 • 예) “in”, “the”, “and” - Map 형식의 자료구조에 inverted index를 저장
• Key: term / word
• Value: 문서빈도 수, term 빈도수, 위치
TF & IDF
Comparison Function (연관성)
-
질의(query)와 문서(document) 사이의 관련성의 정도를 계산
• Query와 inverted index의 term을 비교하여 문서를 검색하고 순위화 • 실시간으로 계산 -
Term 빈도수 (Term frequency)
가정: 사용자가 입력한 query와 매칭하는 term의 빈도수가 높을수록 query와 해당 document 연관성이 높음
• 예) query: fish => “fish”를 포함한 문서 및 term 빈도수
• If Doc1의 “fish” 빈도수: 1, Doc2의 “fish” 빈도수: 2 => 연관성(“fish”, Doc2) > 연관성(“fish”, Doc1)
문서 빈도수 (Document Frequency)
-
가정: 사용자가 입력한 query가 특정 document에만 나타나는 경우, query와 해당 document 사이의 연관성이 높음
• Query가 나타나는 document 의 수가 적을수록 관련성이 높음 -
예) query: egg, red
• “egg”를 포함한 문서 빈도수: 1 => doc 4
• “red”를 포함한 문서 빈도수: 2 => Doc1, Doc2
=> 연관성(“egg”, Doc4) > 연관성(“red”, Doc1) = 연관성(“red”, Doc2)
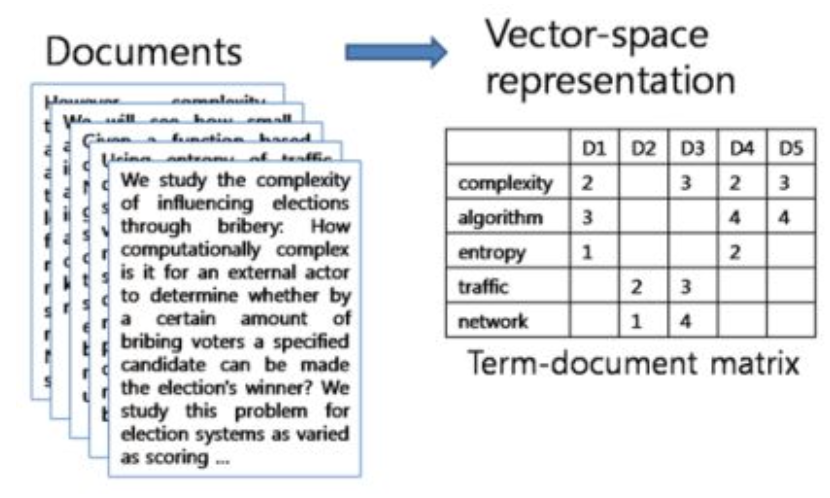
문서-단어 행렬(Document-Term Matrix)
• 문서에서 등장하는 각 단어들의 빈도나 특성을 반영한 행렬
Term Frequency (TF)
- 특정 문서 d에서 단어 t가 등장한 횟수
- 기존의 DTM과 완전히 똑같은 개념이기 때문에 DTM 자체가 이미 TF 값
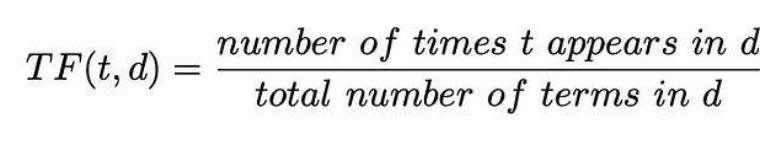
Inverse Document Frequency (IDF)
• Document Frequency (DF): DF는 특정 단어 t가 등장한 문서의 수
=> Inverse Document Frequency (IDF): DF의 역수 == 단어가 제공하는 정보의 양
• 단어가 모든 문서에서 너무 많이 등장 => 정보의 양이 적음. 흔한 단어
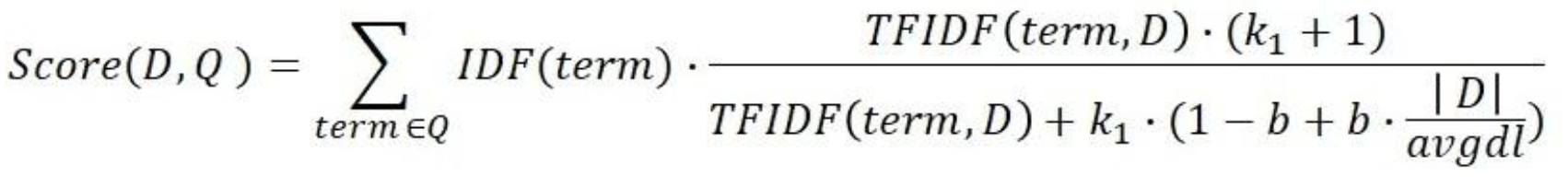
Combine TF & IDF
- ‘a’, ‘the’, ‘of’ 등 관사 및 전치사 ⇒ TF는 높으나, IDF가 0에 근사
=> 거의 모든 document에 등장하면 N ≈ DF(t) ⇒ log(N/DF) ≈ 0
=> 낮은 TF-IDF score - 자주 등장하지 않는 고유 명사 (ex. 사람 이름, 지명 등)
=> 높은 TF-IDF score
BM25
• TF-IDF 를 기반으로, 문서의 길이까지도 고려하여 점수를 매김
• TF 값에 한계를 지정해두어 일정한 범위를 유지하도록 함
• 평균적인 문서의 길이보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 대해 가중치를 부여
• 현재까지도 검색엔진, 추천 시스템 등에서 빈번하게 사용되는 유사도 알고리즘
왜 BM25가 더 좋을까?
- TF의 영향이 감소
TF에서는 단어 빈도가 높아질수록 검색 점수도 지속적으로 높아지는 반면, BM25에서는 특정 값으로 수렴 - IDF의 영향이 커짐
BM25에서는 DF가 높아지면 검색 점수가 0으로 급격히 수렴. 불용어가 검색 점수에 영향을 덜 미침 - 문서 길이의 영향이 줄어듬
BM25에서는 문서의 평균 길이를 계산에 사용해 정규화. 문서의 길이가 검색 점수에 영향을 덜 미침
