
아래와 같은 순서로 환경을 만들고 필요한 라이브러리를 설치한다.
1. 가상환경 만들기
2. 가상환경 활성화
3. beautifulsoup4 설치
4. selenium 설치
5. request 설치
6. webdriver-manager 설치
conda create -n web-scraping python=3.8
conda activate web-scraping
pip install beutifulsoup4
pip install selenium
pip install request
pip install webdriver-manager
- 실습을 위한 아무 폴더를 만들고, pycharm 에서 환경 설정을 해준다.
(Desktop > scraping 폴더를 만듦)
pycharm 환경설정
- 데스크탑의 scraping 폴더를 만들고, pycharm 으로 프로젝트를 열었을 때의 화면.
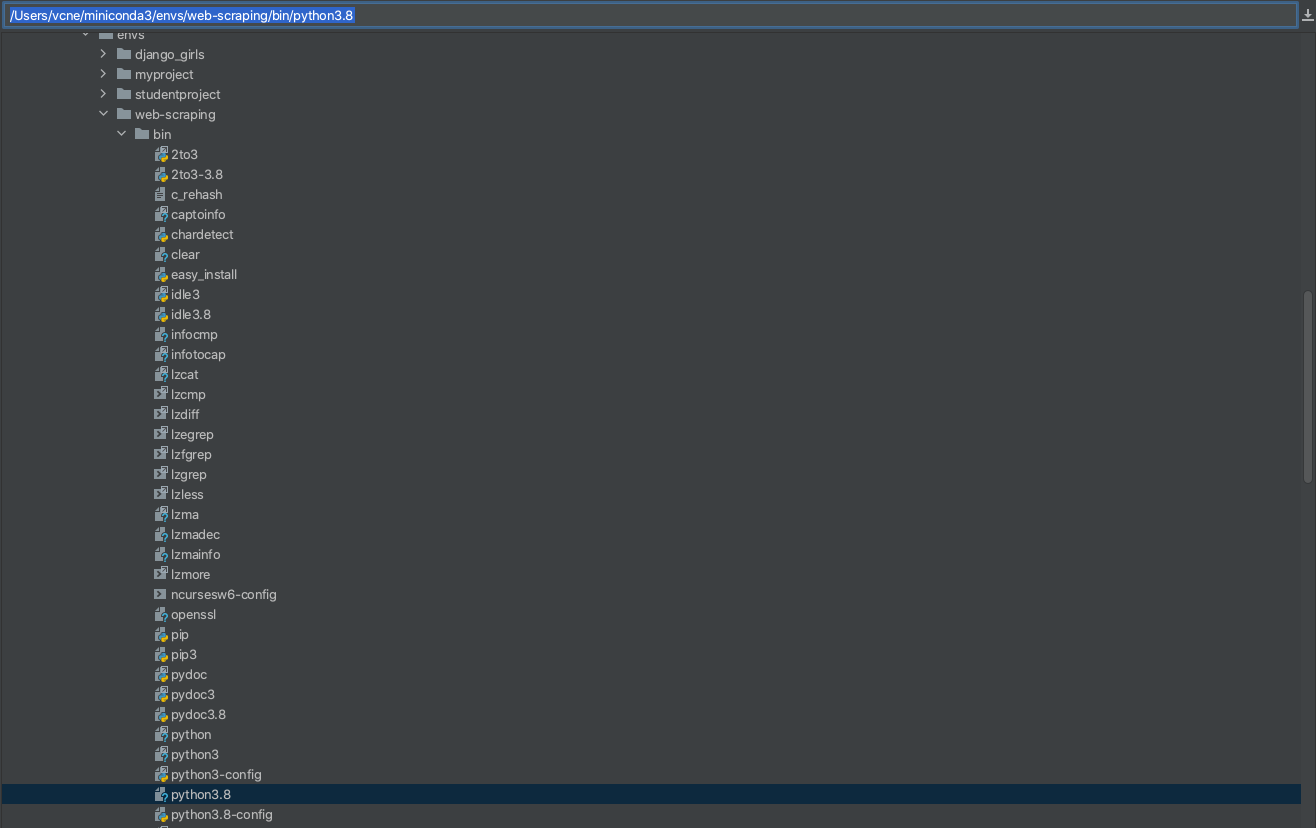
- 파이참 preperences > project:scraping > Python Interpreter > Existing environment 에서 위의 과정에서 만들어준 가상환경 안에 bin 폴더에 있는 python3.8 클릭한다.
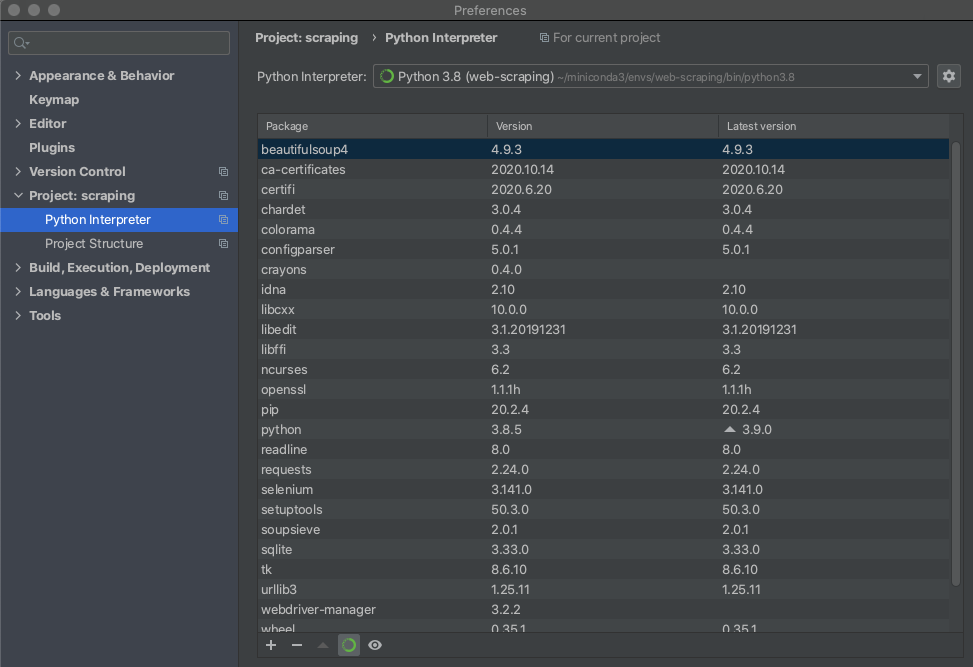
- 그 후 OK 를 누르면 가상환경 안에 들어있는 패키지 목록이 보이는데, pip 으로 설치한 패키지가 있다면 OK.
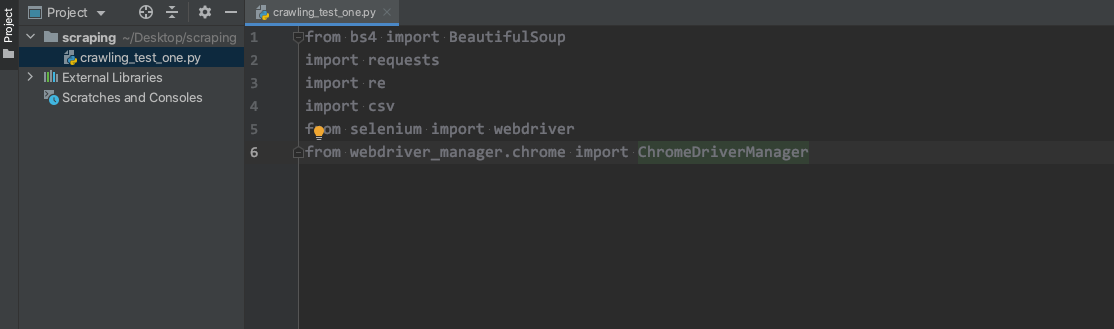
- 그 후 test.py 파일을 만들어 사용하고자 하는 패키지(설치했었던)를 import 시켜보고 에러가 나지 않는다면, 환경 설정 끝.

개발을 취미로 할 수 있는 그 때 까지