ML Basics_1
머신러닝이란 무엇일까? 많이 접했지만 쉽사리 답하기 어려운 질문이기도 합니다. 이 물음에 답변하기 위해 머신러닝의 주요 도메인과 기본 프로세스를 통해 이해를 돕고자 합니다.
머신러닝은 데이터에서 시작해 모델을 통한 학습, 그리고 예측에 이르기까지 여러 단계를 포함하는 포괄적인 과정입니다.
1. Domain, 2. Range, 3. Model, 4. Loss, 5. Optimization, 6. Evaluation 이 6가지 키워드로 머신러닝 전 과정을 이해해봅시다.

1) Domain & Range
머신러닝은 기본적으로 함수 f 에 대해 domain x 와 range y 가 주어졌을 때, x와 y 만 가지고 실제 함수 f 와 최대한 가까운 f: x ↦ y 를 만족하는 f를 찾는 과정입니다. 즉, 머신러닝은 입력 변수(X)를 출력 변수(Y)에 매핑하는 함수(f)를 학습하는 것이라고 요약할 수 있습니다.
따라서, 머신러닝의 첫 단계는 domain(x) 를 정의하는 과정입니다. 예를 들어, 컴퓨터 비전에서는 이미지와 비디오 데이터를, 자연어 처리에서는 텍스트 데이터를 사용합니다. 이때 데이터 증강(data augmentation) 기법이 활용될 수 있는데, 이는 한정된 데이터를 변형하여 데이터의 다양성을 높이고, 이를 통해 모델이 더욱 강인하게 학습할 수 있도록 돕습니다.
이때, 우리의 예측의 목표를 range y라고 정의할 수 있고, x 와 y는 함께 dataset을 구성합니다. 단, range y 는 반드시 존재하지 않을수도 있는데, y 가 존재하는 문제를 지도 학습(supervised learning), y가 존재하지 않는 문제를 비지도학습 혹은 자기지도학습(unsupervised learning / self-supervised learning)이라고 합니다.
- content 1) 참고하면 좋은 개념, CLIP and KD: CLIP (Contrastive Language-Image Pre-training)은 텍스트와 시각 정보를 연결시키며, 주로 텍스트 설명과 함께 이미지를 이해하는 작업에 사용된다. KD (Knowledge Distillation)는 더 작고 효율적인 모델이 더 큰 모델의 동작을 복제하도록 훈련하는 방법이다.
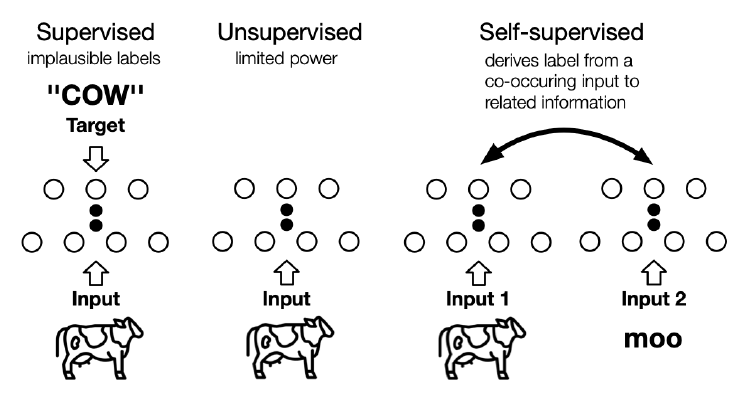
2) Modeling
아래는 머신러닝 모델링을 할 때 있어 고려해야할 중요한 개념들입니다.
2-1. parametric / non-parametric: 머신러닝 모델은 매개변수를 고정된 개수만큼 사용하는 파라메트릭 방식(예: 선형 회귀)일 수도 있고, 데이터에 직접 의존하는 KNN(최근접 이웃)처럼 비파라메트릭 방식일 수도 있습니다.
위에서 배운 개념을 적용해보자면, parametric 모델은 x+y를 모두 가지고있고, 이를 활용해 파라미터 Θ를 튜닝하는 방식으로 학습합니다. 반면, non-parametric 모델은 파라미터를 추정하거나 교정하는 식으로 동작하지 않습니다. 데이터가 스스로 말하게 한다 (dataset speaks itself)는 것인데, 데이터의 분포를 표현해놓고, 비슷한 입력에는 비슷한 출력을 내놓는다는 방침만 세우는 것이죠.
2-2. bias - variance trade off:
모델의 simplicity와 complexity 사이의 균형을 의미합니다. Complexity란? 다항함수는 고차함수로 갈수록 훈련 데이터를 지나치게 잘 학습하는 과적합의 위험을 증가시키는데, 이는 새로운 데이터에 대한 예측력을 떨어뜨립니다. 이에 bias - variance trade off 를 고려하는것은 과적합을 방지하는데 중요한 역할을 합니다.
- content 2) 참고하면 좋은 개념: Sure(training loss != test loss) 훈련 손실과 테스트 손실이 다르다는 것을 확인하면, 이를 노이즈 제거에 활용할 수 있다.
2-3. 최신 모델
최신 모델로는 Transformer가 대표적입니다. Transformer 는 CNN(Convolutional Neural Networks)과 같은 고전적 모델과 종종 비교되고는 하는데, 아래와 같이 설명 가능성 제공 측면에서 고려할만한 부분이 있습니다.
-
content 3) 참고하면 좋은 개념:
인덕티브 바이어스(inductive bias)는 모델이 학습 과정에서 만들어내는 가정으로, 데이터에 아직 나타나지 않은 새로운 상황을 예측하는 데 중요한 역할을 한다. 아래 두 모델의 비교를 통해 각각의 inductive bias가 어떻게 다른지, 그리고 이러한 차이가 결과에 어떻게 영향을 미치는지 설명할 수 있다.
- CNN(합성곱 신경망): 이미지 인식에 강력하며, 이는 인접한 픽셀 간에 의미 있는 연결이 있을 것이라는 가정에서 비롯된다.
- Transformer: 이러한 공간적 가정을 하지 않고, 입력 데이터의 전체적인 관계를 동적으로 파악하여 처리한다.
Explainable AI(XAI)를 통해 이러한 모델들이 어떻게 데이터를 해석하고 결정을 내리는지를 투명하게 만듦으로써 사용자가 AI의 결정 과정을 더 잘 이해하게 하는것이 점점 더 중요해지고 있다.
-
content 4) 참고하면 좋은 개념: SVM, LR (Hypothesis that model has) - have differend inductive bias.
SVM은 데이터 클래스 사이의 최대 마진을 찾아 분류하는 데 초점을 맞춘 모델이다. 이는 강한 inductive bias를 가지고 있으며, 특히 분류 문제에서 뛰어난 성능을 발휘한다. SVM은 hinge loss 함수를 사용하여 이진 분류를 수행합니다.
선형회귀(LR)는 데이터 포인트들 사이의 선형 관계를 모델링하며, 𝑌=𝑤𝑋+𝑏Y=wX+b 형태로 표현된다. 이는 보다 단순한 inductive bias를 반영하며, 연속적인 값의 예측에 적합하다. 이 두 모델의 다른 inductive bias는 각기 다른 유형의 데이터와 문제에 적합한 도구를 선택하는 데 도움을 준다.
3. Loss Functions and Regularization
3-1) Loss Functions
데이터와 타겟을 정한 후 모델을 선택하여 학습한 후, 이제 이 모델이 예측을 얼마나 잘 하는지 측정하기 위해 사용되는 손실 함수(loss functions)에 대해 알아봅시다.
분류 작업(classification)에는 교차 엔트로피 손실(Cross-Entropy Loss, CE)을 사용하며, 회귀 작업(Regression)에는 L1 또는 L2 손실을 사용할 수 있습니다. 이러한 손실 함수들은 모델이 예측한 값과 실제 값 사이의 차이를 수치화하여, 모델 학습 시 이 차이를 최소화하도록 합니다.
각 개념에 대해 간단히 알아보자면:
- 분류(Classification): 교차 엔트로피 손실은 실제 클래스와 예측 클래스 사이의 정보 불일치를 측정합니다. 이 손실 함수는 클래스가 서로 배타적일 때 특히 유용합니다.
- 회귀(Regression): L1 손실은 예측 값과 실제 값의 절대 차이를 합산하며, L2 손실은 차이의 제곱을 합산하여 오차의 제곱합을 최소화합니다(Minkowski distance). L2 손실은 오류를 분산시켜 큰 오류를 더욱 강하게 처벌하는 경향이 있어, 편향 오류(bias error) 즉, 예측의 평균과 실제 값의 차이에 민감합니다.
3-2) Regularization
정규화(Regularization)는 모델의 복잡성을 관리하는 데 도움을 줍니다. 이를 통해 모델이 학습 데이터에 과도하게 적합되는 과적합(overfitting) 문제를 방지할 수 있습니다. 정규화 기법은 모델의 파라미터 값들이 지나치게 크지 않도록 제한함으로써, 모델이 보다 일반화될 수 있도록 돕습니다.
-
content5) 참고하면 좋은 개념: Catastrophic forgetting,EWC(Elastic Weight Consolidation), MLE(Maximum Likelihood Estimation), MAP(Maximum A Posteriori)
- Catastrophic forgetting: 학습 과정에서 이전에 배운 작업(Task1)을 잊어버리고 새로운 작업(Task2)에만 최적화되는 현상이다. 이를 방지하기 위해, 예를 들어 교차 엔트로피 손실에 정규화 항 𝜆∥𝑤−𝑤1∥^2를 추가하여 이전 작업의 가중치와의 차이를 최소화하면서 새로운 작업을 학습할 수 있다.
- EWC: Elastic Weight Consolidation은 중요한 파라미터는 보존하면서 새로운 데이터에 대해 유연하게 학습할 수 있도록 돕는 정규화 기법이다.
- MLE: 주어진 데이터에 대해 가장 가능성이 높은 파라미터 값을 찾습니다. 이는 ∥F(x)−y∗∥^2를 최소화하는 파라미터를 찾는 방법이다.
- MAP: MLE에 사전 지식(prior)을 추가하여, 주어진 데이터 뿐만 아니라 사전에 알고 있는 정보도 함께 고려하여 파라미터를 추정한다. 이는 likelihood와 prior의 합을 최대화하는 방법으로, 더욱 견고한 모델 추정을 가능하게 한다.
4. Optimization
최적화 기법은 모델의 성능을 최대화하기 위해 손실 함수를 최소화하는 모델 매개변수를 찾는 데 사용됩니다. 대표적인 최적화 기법으로는 SGD(Stochastic Gradient Descent, 확률적 경사 하강법)와 Adam(Adaptive Moment Estimation)이 있습니다. 이러한 방법들은 반복적으로 매개변수를 업데이트하여 모델의 성능을 개선합니다.
SGD와 Adam
- SGD (Stochastic Gradient Descent): 이 기법은 각 스텝에서 무작위로 선택된 데이터 샘플을 사용하여 그라디언트를 계산합니다. 이 접근 방식은 계산 비용을 크게 줄이면서도, 매개변수 공간을 효과적으로 탐색할 수 있게 합니다.
- Adam (Adaptive Moment Estimation): Adam은 모멘텀과 학습률 조정을 결합한 방식으로, 각 매개변수에 대해 개별적인 학습률을 조정합니다. 이는 SGD보다 일반적으로 더 빠르게 수렴하며, 다양한 문제에 잘 작동하는 것으로 알려져 있습니다.
고급 기법
- AdamW: Adam의 변형으로, 원래 Adam 알고리즘에서 가중치 감쇠(weight decay)를 재구현한 것입니다. AdamW는 가중치 감쇠를 그라디언트 업데이트 로직 밖에서 별도로 처리하여, 더욱 효과적인 정규화와 더 나은 학습 결과를 도출할 수 있습니다.
- 수식 표현: 매개변수 업데이트는 다음과 같은 수식으로 표현됩니다:
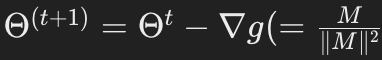 (Adam에서 M은 모멘텀을 의미)
(Adam에서 M은 모멘텀을 의미)
- 수식 표현: 매개변수 업데이트는 다음과 같은 수식으로 표현됩니다:
-
content 6) 참고하면 좋은 개념:
- LDSG (Landriab dynamics): 이는 일반적인 경사 하강법에 가우스 노이즈(Gaussian Noise)를 추가하여, 손실 표면에서의 더 광범위한 탐색을 가능하게 한다. 이는 특히 국소 최소값에서 벗어나 전역 최소값을 찾는 데 도움을 줄 수 있다.
- Normalizing Flow와 Glow: 이 기법들은 복잡한 데이터 분포를 모델링할 때 사용되며, 데이터의 기저 분포를 변형하여 새로운 샘플을 생성할 수 있다. 특히 Glow는 고품질의 이미지 생성에 유용한 특정 유형의 Normalizing Flow이다.
5. Evaluation
마지막 단계로, 모델이 잘 일반화되는지 (즉, 새로운 데이터에 대해 잘 수행되는지) 확인하기 위해, 교차 검증(cross-validation)과 같은 기법을 사용할 수 있습니다. 이는 다양한 데이터 서브셋을 순환시켜 훈련과 테스트를 반복함으로써 모델의 성능을 견고하게 평가할 수 있도록 합니다.
교차 검증 (Cross-validation)
- 교차 검증의 기본: 교차 검증은 데이터를 여러 개의 서브셋으로 나누고, 각 서브셋을 순차적으로 테스트 세트로 사용하면서 나머지는 훈련 세트로 사용하는 방식입니다. 이는 모든 데이터가 적어도 한 번은 테스트 세트로 사용되게 하여, 모델이 데이터의 다양한 측면을 학습할 수 있게 돕습니다.
- 과적합 감소: 교차 검증은 모델이 특정한 데이터 서브셋에 과적합되는 것을 방지하는 데 도움을 줍니다. 각 반복에서 다른 데이터 서브셋을 사용함으로써, 모델이 더 일반적이고 견고한 성능을 발휘하도록 합니다.
메타 학습 (Meta Learning)
- 메타 학습의 개념: 메타 학습은 '학습하는 방법을 학습하는' 접근 방식으로, 모델이 다양한 작업을 빠르게 적응하고 최적화할 수 있도록 합니다. 이는 특히 적은 양의 데이터로 빠르게 학습해야 할 때 유용합니다.
성능이 만족스럽지 않을 때?
모델의 평가 결과가 기대에 미치지 못한다면, 모델 구조 재검토, 하이퍼파라미터 조정, 등을 검토해볼 수 있습니다. 대규모 데이터셋의 경우, 교차 검증은 계산적으로 매우 비효율적일 수 있기때문에, 이런 경우 단순화된 검증 절차나 데이터의 일부만을 사용하는 방법을 고려해보는것이 좋을수도 있습니다.
마무리
지금까지 머신러닝이 무엇이고, 어떤 과정을 거쳐 진행되는지 간략하게 알아보았습니다. content) 로 표시된, 참고하면 좋은 개념들은 설명하는데 다른 배경지식이 필요한 경우가 많아 생략된 부분이 많지만, 관심있으면 한번 조사해보는것을 추천합니다. 질문은 언제나 환영입니다.
작성자: 1기 홍진욱
