모델 경량화 방법
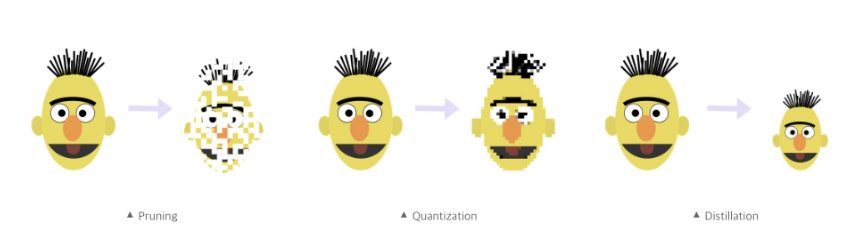
1. 모델 경량화란?
- 모델 경량화는 규모가 크거나 복잡한 모델을 작고 가벼운 형태로 변환하는 프로세스를 의미합니다.
- 모델 경량화는 일반적으로 딥러닝 모델, LLM(거대 언어 모델), AI 모델 등등에서 효율성과 성능의 향상을 위해 사용됩니다.
2. 모델 경량화를 사용하는 이유 및 장점
- 많은 기기 및 시스템은 제한된 하드웨어 자원을 갖고 있어 대규모 모델을 실행하기에는 데이터의 전송과 저장에서 요구되는 비용이 많이 들며 사용자 경험의 향상에도 어려움이 있습니다.
- 이때 모델 경량화를 사용하게 되면 모델의 크기와 연산량이 줄어들기 때문에 제한된 환경이나 저사양 하드웨어에서도 실행 할 수 있게 됩니다. 또 서버 비용을 줄일 수도 있게 되며 모델이 간결해짐에 따라 성능과 형태 등의 주요 측면에서의 효율성도 높아집니다.
3. 모델 경량화 방법
- 모델 경량화 방법은 모델을 간결하게 하여 효율성을 높인다는 공통점이 있지만 모델에 따라 조금씩 다른 특성을 보입니다.
- 저는 그 중 딥러닝 모델, LLM(거대 언어 모델), AI 모델의 경량화 방법에 대해서 설명하겠습니다.
(1) 딥러닝 모델의 경량화 방법
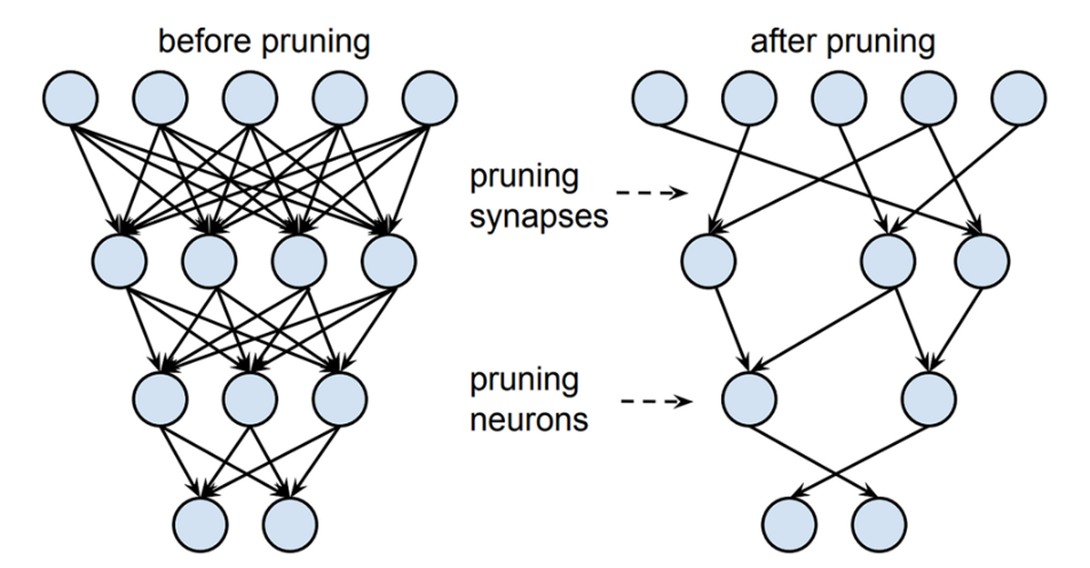
가지치기(Pruning)(네트워크 구조화 관점 경량화)
-
중요하지 않은 weight(가중치)를 제거하여 모델의 연결 수를 줄이고 계산량을 감소시키는 방법.
-
머신을 딥러닝 할 때는 training 과정에서 complexity가 늘어나는데 이때 중요하거나 자주 쓰는 parameter는 살리고 자주 쓰지 않는 parameter을 제거하는 방식입니다.
-
사람이 50조개의 뉴런을 가지고 태어나 1년 뒤에는 1000조개가 된다고 할 때, 어른이 되는 과정에서 자주 쓰는 뉴런은 보존하고 그렇지 않은 뉴런은 없어지면서 결국에는 500조개의 뉴런이 되는 것으로 빗대어서 설명할 수 있습니다.
-
가지치기(Pruning)은 network의 parameter을 제거하기 때문에 정보가 손실될 수 있다는 단점과 complexity가 감소하기 때문에 추론 속도(inference speed)가 빨라지며 일반화를 할 수 있다는 장점이 있습니다.
-
중요하지 않은 parameter을 그룹(channal, filter, layer) 단위로 제거하는 structured pruning과 parameter을 독립적으로 제거하는 unstructured pruning이 있습니다.
Network Quantization((가중치)양자화)
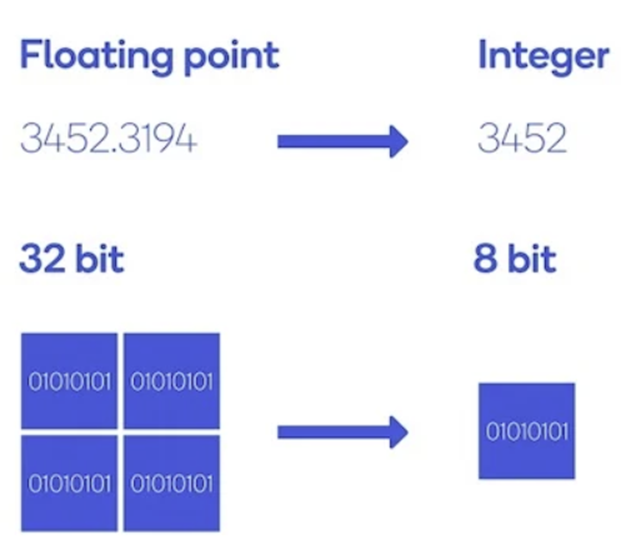
- 학습된 딥러닝 모델이 weight 값을 저장할 때 사용하는 비트의 수를 줄여서 모델의 크기를 줄이고 연산 효율을 높이는 방법입니다.
- 더 적은 비트를 사용해서 모델을 실행시킬 수 있기 때문에 모델의 메모리 사용량이 줄어들고, inference(추론)할 때 동작시간을 단축시킬 수 있다는 장점이 있으나 숫자가 덜 정밀하게 표현되어 성능이 떨어진다는 단점이 있습니다.
- 딥러닝에서는 숫자의 저장과 연산에서 32-bit floating point나 FP32(32비트)를 사용하는데 이것을 FP16(16비트)이나 INT8(64비트)로 표현 가능한 범위의 숫자로 변환한 뒤(=bitband를 낮춰서 표현한 뒤) 해당 비트 수만큼의 메모리에 저장하는 방법입니다.
(2) LLM(거대 언어 모델)의 경량화 방법
PEET(Parameter Efficient Fine-Tuning)
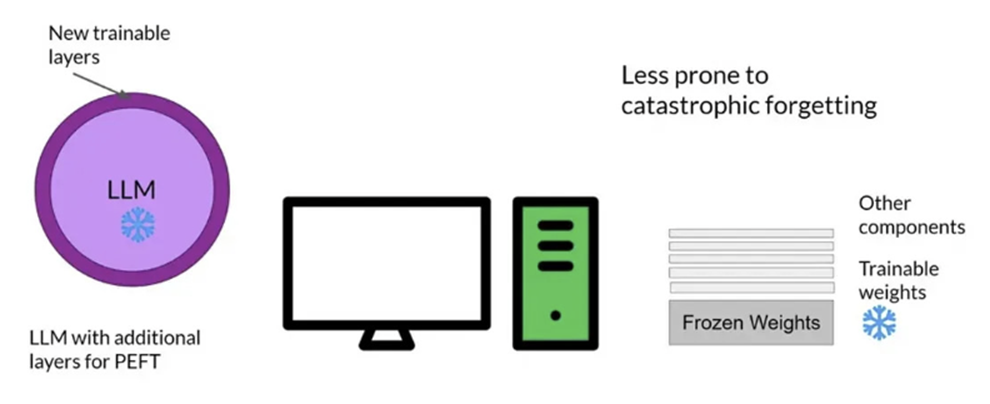
-
적은 매개변수(parameter) 학습만으로 빠른 시간에 새로운 문제를 효과적으로 해결하는 미세 조정 방법
-
전체 모델을 조정하는 것보다 적은 계산 자원과 데이터 자원을 사용하기 때문에 실행속도와 결과제공, 피드백의 과정이 효율적으로 작동하게 됩니다. 또 더 적은 리소스가 요구되기 때문에 더 많은 사용자가 모델을 사용할 수 있게 되며 더 다양한 작업(도메인에의 접근 등), 더 다양한 환경(제한이 있는 환경 등)에서의 사용도 용이하게 한다는 장점이 있습니다.
-
Parameter(매개변수)의 일부를 조정하기 때문에 원래 모델과 동일한 성능을 보장할 수 없고 PEET 적용 시 사용되는 하이퍼파라미터에 따라 성능이 크게 변할 수 있다는 단점이 있습니다.
-
PEET의 방법론 중 Quantization와 LoRA이 있습니다.
-
Quantization(양자화)
: 매개변수를 실수형에서 정수형으로 바꾸어 비트 수를 줄여서 모델 사이즈를 감소시키는 방식입니다. 모델의 크기가 줄어들기 때문에 계산의 효율성이 향상되고 복잡도는 감소한다는 장점이 있습니다. 추론(inference) 속도는 빨라지며 메모리 사용량도 효율적으로 작동하게 됩니다. -
LoRA(Low Rank Adaption), 즉 낮은 순위 적용 방식
: 매개변수 가중치(weight) 중 일부만 미세조정하고 나머지는 원래대로 유지시키는 방식입니다. 전체 매개변수를 사용하는 큰 체크포인트 파일 대신 작은 체크포인트 파일을 얻어 저장공간을 효율적으로 사용할 수 있습니다. 훈련비용과 컴퓨터 리소스를 절약하면서도 성능을 향상시킬 수 있다는 장점이 있습니다.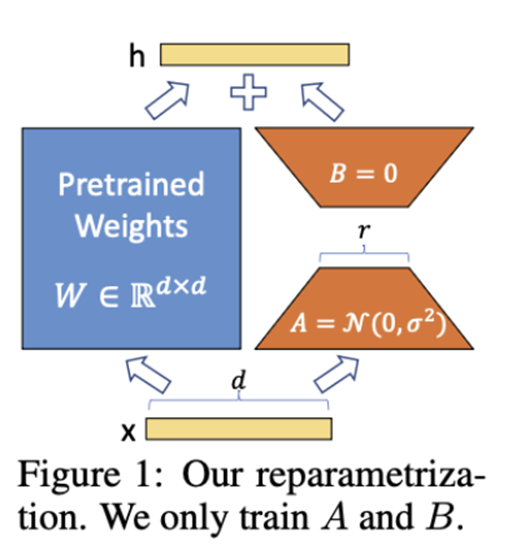
-
(3) AI 모델의 경량화 방법
-
Quantization(양자화)
- 앞선 설명과 마찬가지로, 모델 파라미터를 정수로 변환하여 저장공간을 줄이는 방법
- 예시 : 32비트 부동 소수점 수를 8비트 정수로 양자화하여 모델의 크기를 줄인다.
-
Pruning(가지치기)
- 앞선 설명과 마찬가지로, 불필요하거나 중요도가 낮은 가중치(weight)들을 제거하여 모델의 크기를 줄이는 방법
- 예시 : 기울기의 절댓값이 가장 작은 가중치를 제거하여 모델의 크기를 줄인다.
-
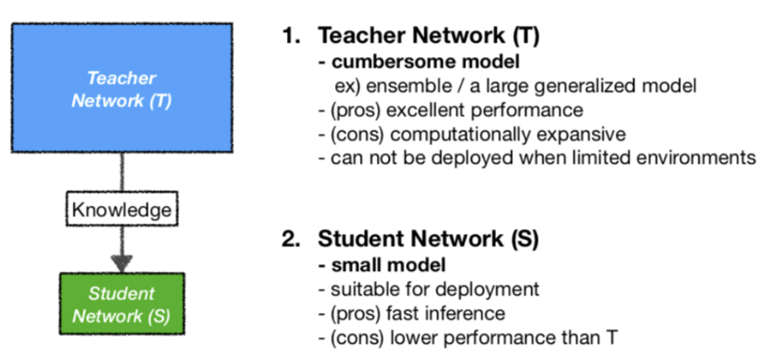
Distillation(증류)
-
큰 모델에서 작은 모델로 지식을 전달하는 방법
-
작은 모델이 큰 모델과 유사한 성능을 내도록 학습시킵니다.
-
Distillation(증류)에는 큰 모델로부터 작은 모델로 지식을 전달하는 과정을 다루는 Knowledge Distillation(지식 증류)와 학습 데이터의 크기를 줄이고(학습에 일부 관련성이 높은 데이터만을 사용) 모델의 정확도를 향상시키는 Data Distillation(데이터 증류)가 있습니다.
-
마침
모델 경량화 방법은 꼭 해당 모델마다 국한된 것이 아니라 한 가지 방법이 여러 모델에도 적용 가능합니다. 모델의 경량화는 거의 모든 측면에서의 효율성을 향상시킨다는 장점이 있지만 손실이나 정밀도의 측면에서는 성능이 떨어질 수 있다는 단점 또한 존재합니다. 현재 단점을 개선, 보안하기 위한 여러 경량화 방법들이 연구 중에 있습니다.
작성자 : 5기 송지윤
