
💡 EDA (Event Driven Architecture)
⭐ 이벤트 기반 아키텍처 : 분산 시스템 환경에서 서비스들이 이벤트를 기반으로 비동기 통신하는 구조
이벤트를 기반으로 통신한다는 것은 한 서비스에서 이벤트를 생성하여 발행하면(pub) 해당 이벤트를 필요로 하는 서비스가 이벤트를 받아서 처리(sub)하는 방식으로 작동한다.
여기서 이벤트란 주목할 만한 사건, 즉, 회원가입이나 주문과 같이 어떠한 작업이 실행됐다고 생각하면 편하다. 그렇다면 이벤트가 발행되는 것은 API가 호출되는 것이라고 치고, 이벤트를 구독하고, 받아서 처리한다는 것은 어떤 개념일까? 나는 이걸 MSA & 분산 DB 환경에서 한 서비스의 이벤트가 다른 서비스의 이벤트나 데이터에 영향을 미친다. 라는 느낌으로 이해하고 작업을 진행했다.
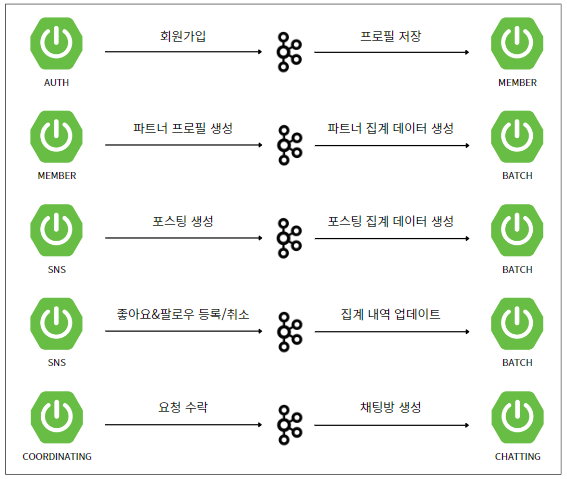 내가 2차 프로젝트를 진행하면서 EDA를 적용한 부분을 정리해봤는데, 대충 이정도였다. 이걸 참고해서 위 설명에 예시를 들어보자면, 인증(Auth) 서비스에서 회원가입 이벤트가 발행되면 카프카(아래 설명 예정)에 관련된 데이터(메세지)가 저장되고, 이 이벤트를 구독한 회원(Member) 서비스에서 해당 데이터를 들고 회원 DB 서버에 프로필 데이터를 저장하는 방식으로 동작하게 된다.
내가 2차 프로젝트를 진행하면서 EDA를 적용한 부분을 정리해봤는데, 대충 이정도였다. 이걸 참고해서 위 설명에 예시를 들어보자면, 인증(Auth) 서비스에서 회원가입 이벤트가 발행되면 카프카(아래 설명 예정)에 관련된 데이터(메세지)가 저장되고, 이 이벤트를 구독한 회원(Member) 서비스에서 해당 데이터를 들고 회원 DB 서버에 프로필 데이터를 저장하는 방식으로 동작하게 된다.
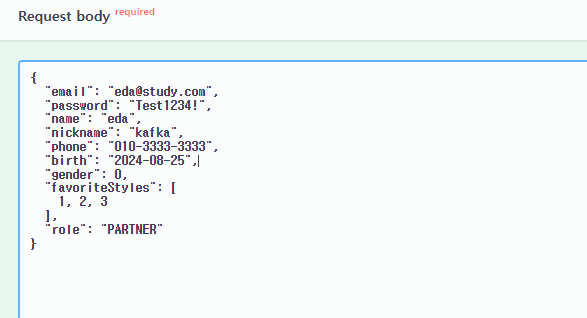 인증 서버에서 회원가입 요청을 처리할 때 위와 같은 데이터들을 받는데,
인증 서버에서 회원가입 요청을 처리할 때 위와 같은 데이터들을 받는데, 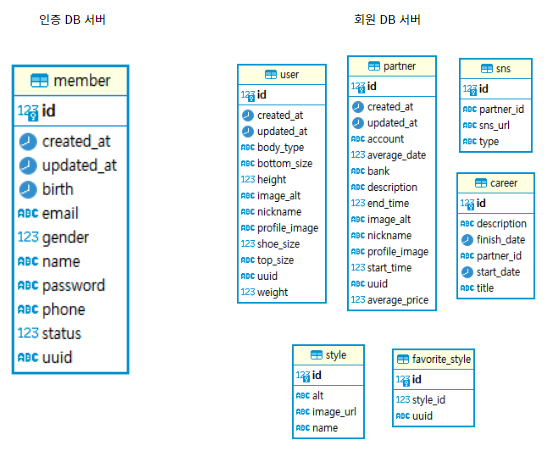 각 DB의 테이블을 살펴보면
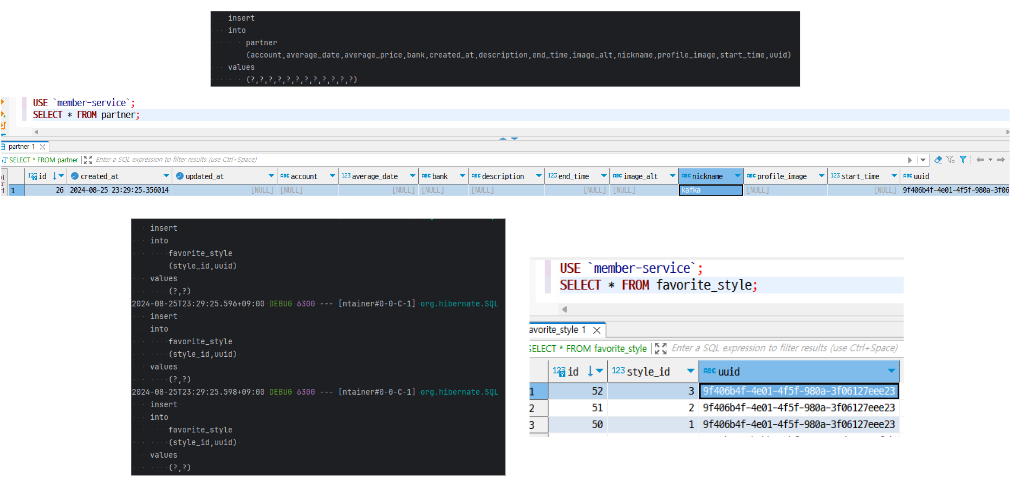
각 DB의 테이블을 살펴보면 email, password, name, phone, birth, gender는 인증 서버에서, nickname, favoriteStyle은 회원 서버에서 관리하는 것을 알 수 있다. 그렇다면, 회원가입 시 인증 서버의 Member 테이블과 회원 서버의 User/Partner(role에 따라 분기), Favorite_Style 테이블에 INSERT문을 실행해야 하는데, 인증 서비스에서는 인증 DB 서버만 다루기 때문에, 해당 서비스에서 회원 DB 서버에 프로필 정보를 저장을 처리할 수 없는 문제가 발생하게 된다.
이러한 경우, 어떻게 다른 서비스로 데이터를 전달할 수 있을까? 바로 카프카와 같은 메시지 큐를 활용하면 된다!
📢 Kafka
메시지 큐 방식을 기반으로 하여 분산 시스템 환경에서 대규모 메시지를 안정적으로 전송, 수집, 활용할 수 있도록 서비스를 중개하는 분산 메시징 시스템
메시지 큐를 찾아보면 가장 많이 나오는 툴이 Kafka와 RabbitMQ인데, 위에서 설명했던 내가 구현한 부분 외에도 다른 팀원분도 EDA를 사용하는 경우가 제법 있어서 대용량 메시지를 좀 더 안정적으로 처리할 수 있는 Kafka를 선택하게 되었다.
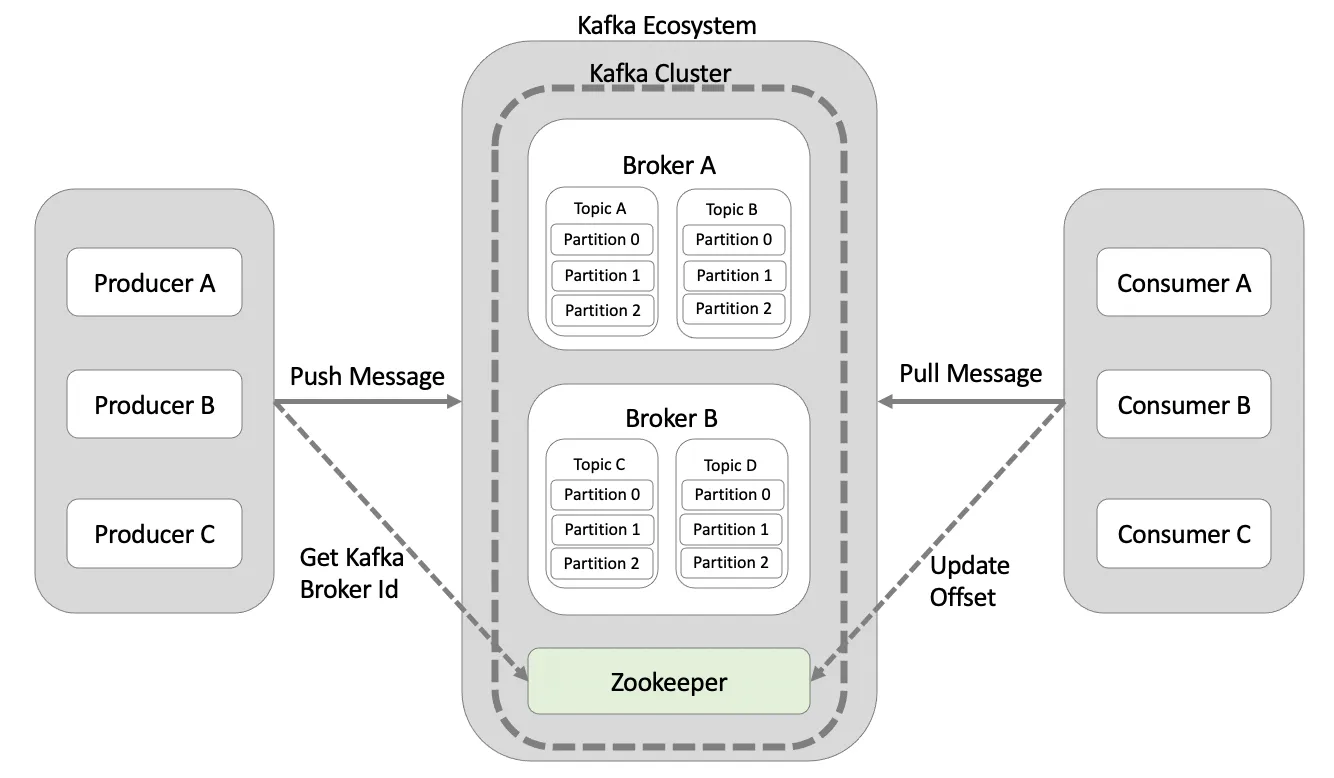
- Broker : 카프카 애플리션이 설치된 서버
- Producer : 메시지(이벤트)를 발행하여 브로커에 전달하는 서비스
- Consumer : 브로커의 메시지를 구독하여 처리하는 서비스
- Topic : 브로커에서 메시지를 구분하기 위해 설정하는 고유한 이름
- Partition : 브로커 내에서 병렬 처리를 가능하게 함
- Zookeeper : 분산 애플리케이션들을 그룹화하여 관리하는 시스템
카프카에 대해서 정리하자면 글이 한없이 길어질 것 같아서.. 일단 이 글에서는 이 정도 개념만 가지고 서비스 통신을 구현하는 코드 위주로 정리할 예정.. 주키퍼와 카프카 서버를 구축하는 과정이나, 좀 딥한 개념에 대해서는 추후 작성할 인프라 파트에서 다룰 예정!
⚙️ Producer
이벤트 발행 시,
<토픽명, 메시지>를<String, Json>형태로 전송
✍🏻 KafkaConfig
@Configuration
public class KafkaConfig {
@Value("${spring.kafka.bootstrap-servers}") // .yml에 환경변수 선언
private String BOOTSTRAP_SERVER;
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> configs = new HashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configs);
}
}✍🏻 KafkaProducer
- 프로필 정보를
InsertProfieDto객체 형태로 전송하면, 설정값에 따라 DTO를 JSON으로 변환하여 브로커에 저장
@Service
@RequiredArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, Object> kafkaTemplate;
public void sendProfile(InsertProfileDto dto) {
kafkaTemplate.send("profile-insert", dto);
}
}✍🏻 AuthService
SignUpReqDto에서 프로필 데이터를InsertProfileDto객체에 담아producer를 통해 브로커에 전송
@Service
@RequiredArgsConstructor
@Transactional
public class AuthServiceImpl implements AuthService {
private final MemberRepository memberRepository;
private final KafkaProducer producer;
@Override
public String signUp(SignUpReqDto dto) {
if(!dto.getRole().equals("USER") && !dto.getRole().equals("PARTNER")) {
throw new BaseException(NO_EXIT_ROLE);
}
Member member = createMember(dto);
producer.sendProfile(InsertProfileDto.toBuild(dto, member.getUuid()));
return member.getUuid();
}
}⚙️ Consumer
토픽명에 따른 JSON 형태의 메시지를 DTO로 변환하여 처리
✍🏻 KafkaConfig
InsertProfileDto타입의 메시지를 받아서 처리하는ConsumerFactory생성
➡️ 처음에는 프로듀서처럼 Object로 받아서 처리하려고 했는데, 계속 예외가 발생해서 각 컨슈머 별로 DTO를 분리해서 설정하니까 정상적으로 처리됨 + 프로듀서도 Object 보다는 나누어서 처리하는게 좋다고 함!
@Configuration
public class KafkaConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String BOOTSTRAP_SERVER;
@Value("${spring.kafka.consumer.group-id}")
private String GROUP_ID;
@Bean
public ConsumerFactory<String, InsertProfileDto> insertProfileConsumer() {
Map<String, Object> configs = new HashMap<>();
configs.put(BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);
configs.put(GROUP_ID_CONFIG, GROUP_ID);
configs.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
return new DefaultKafkaConsumerFactory<>(
configs,
new StringDeserializer(),
new JsonDeserializer<>(InsertProfileDto.class, false)
);
}
@Bean
ConcurrentKafkaListenerContainerFactory<String, InsertProfileDto> insertProfileListener() {
ConcurrentKafkaListenerContainerFactory<String, InsertProfileDto> factory
= new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(insertProfileConsumer());
return factory;
}✍🏻 KafkaConsumer
-
@KafkaListner(topics="토픽명", containerFactory="리스너명"): 브로커에서 해당 토픽명을 가지는 메시지를 받아와서 처리- DTO내의
role값에 따라서 유저 혹은 파트너 프로필 생성 + 선호 스타일 저장 ➡️ 파트너 프로필 생성 시, 배치 서비스에 집계 데이터를 생성해야 하므로 새로운 이벤트 발행
- DTO내의
@Service
@RequiredArgsConstructor
@Transactional
@Slf4j
public class KafkaConsumer {
private final UserRepository userRepository;
private final PartnerRepository partnerRepository;
private final FavoriteStyleRepository favoriteStyleRepository;
private final KafkaProducer producer;
@KafkaListener(topics = "profile-insert", containerFactory = "insertProfileListener")
public void insertProfile(InsertProfileDto dto) {
if(dto.getRole().equals("USER")) { // 유저
userRepository.save(User.builder()
.uuid(dto.getUuid())
.nickname(dto.getNickname())
.build());
}
else if(dto.getRole().equals("PARTNER")) { // 파트너
Partner partner = partnerRepository.save(Partner.builder()
.uuid(dto.getUuid())
.nickname(dto.getNickname())
.build());
// 새로운 이벤트 발행 : 배치 서비스에서 사용
producer.createPartner(PartnerSummaryDto.builder()
.partnerId(partner.getUuid())
.build());
}
else { // 이외의 파라미터 : 예외 발생
throw new BaseException(NO_EXIT_ROLE);
}
dto.getFavoriteStyles() // 선호 스타일 저장 : 파트너 & 유저 공통
.forEach(i -> favoriteStyleRepository.save(
FavoriteStyle.builder()
.uuid(dto.getUuid())
.styleId(i)
.build()));
}
} ⭐ 결과
1. 인증 서버
- 신규 회원 데이터 생성 → 회원 서비스에 UUID와 프로필, 선호 스타일 전달

2. 회원 서버
- 신규 회원의 UUID를 가지는 파트너 프로필, 선호 스타일 데이터 생성 → 배치 서비스에 UUID 전달
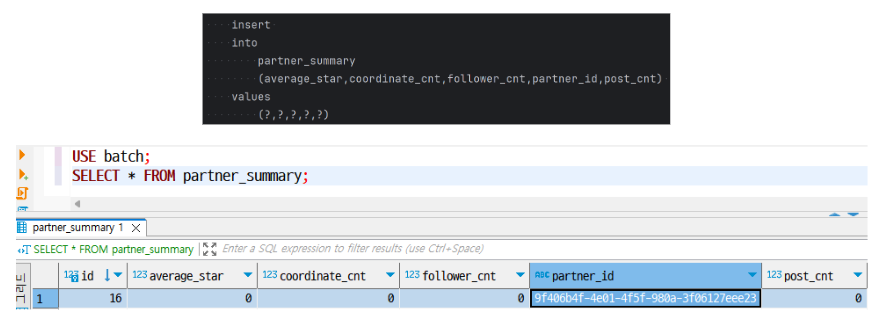
➕ 배치 서버
- 신규 회원의 UUID를 가지는 파트너 집계 데이터 생성
✅ 장단점
그렇다면 분산 시스템에서 데이터를 EDA를 통해 관리하면 어떤 점이 좋고, 어떤 점에서 문제가 발생할까?
🙆🏻♀️ 장점
-
서비스 간 느슨한 결합 : 브로커는 메시지 수신 여부와 관계 없이 독립적으로 메시지를 관리함. 즉, 수신 측 서비스가 작동하지 않아 메시지를 수신하지 못하더라도 송신 측 서비스는 이미 메시지를 전송하였기 때문에 이에 영향을 받지 않고 독립적으로 작동함.
-
이벤트 전달 보장 : 이벤트가 발행되는 순간 브로커가 메시지를 안전하게 저장하므로, 수신 측 서비스가 작동하지 않더라도 재가동 시 누락된 메시지를 수신할 수 있음.
-
비동기 처리를 통한 성능 최적화 : EDA는 비동기 통신 기반이므로 여러 요청을 한 번에 처리할 수 있기 때문에 시스템 전체의 처리량을 높일 수 있음.
-
확장성 및 재사용성 향상 : 하나의 메시지를 여러 서비스에서 구독하여 사용할 수 있으므로, 필요에 따라 기능을 추가하거나 변경할 수 있음.
🙅🏻♀️ 단점
-
시스템 복잡도 증가 : 이벤트의 흐름을 추적하고 관리하는 처리 로직을 구현하는 부분에서 전체적인 시스템이 복잡해질 수 있음.
-
이벤트 처리 순서 보장의 어려움 : 다수의 이벤트가 비동기로 처리되기 때문에, 동일한 이벤트에 대해 순차적 처리를 보장할 수 없음.
-
데이터 일관성 유지의 어려움 : DB 서버가 분산되어 있기 때문에, 이벤트 발행 시점에 수신 측 서비스가 작동하지 않는 경우 데이터가 실시간으로 반영되지 않아 일관된 데이터 상태를 유지하기 어려울 수 있음.
🙏🏻 참고
