
💡 Spring Batch
대용량 데이터를 효율적으로 일괄(배치) 처리하기 위한 프레임워크
: Spring Batch 로깅/추적, 트랜잭션 관리, 작업 재시작/건너뛰기, 작업 처리 통계, 리소스 관리 등 배치 처리에 필요한 다양한 기능들을 제공
📒 용어
배치 처리 시 사용되는 기본적인 객체 및 테이블명 정리!
-
Job: 한 번에 처리해야 할 배치 작업 단위(객체) -
JobInstance: Job의 논리적 실행 단위 → 실행될 때마다 새로운 JobInstance 생성 -
JobParameter: Job이 실행될 때 필요한 파라미터를 제공하고, 이를 통해 JobInstance를 구분 →String,Double,Long,Date타입 지원 -
JobExecution: JobInstance 실행 시도에 대한 객체 → 시작/종료시간, 상태 등에 대한 정보를 담고 있으며, 실패 후 재시도 시 별도의 JobExecution 생성 -
Step: 처리해야 할 작업 내용(단계) → Job은 하나 이상의 Step으로 이루어지며, 각 Step은 순차적으로 처리됨 -
StepExecution: Step의 실행 시도에 대한 객체 → JobInstance와 유사하며, read/write/commit/skip 수 등의 정보도 저장 -
ExecutionContext: Step 혹은 Job의 실행 중에 발생하는 데이터를 저장하고 공유 → 작업 실패 시, ExecutionContext에 저장된 데이터를 통해 마지막 실행 상태를 재구성하여 작업 수행JobExecutionContext: Commit 시점에 저장StepExecutionContext: 실행 사이에 저장
-
JobRepository: 배치 처리와 관련된 모든 정보(Job/StepExecution, JobParameters)를 저장하고 관리 -
JobLauncher: Job과 JobParameters를 사용하여 Job을 실행하고, 생명주기를 관리 -
ItemReader: 배치 작업에서 처리할 아이템(데이터)을 읽어오기 위한 인터페이스 -
ItemProcessor: ItemReader로부터 읽어온 데이터를 처리(필터링, 변환 등)하기 위한 인터페이스 -
ItemWriter: 배치 처리된 데이터를 최종적으로 기록(DB에 저장, 파일 생성, 메시지 발행 등)하기 위한 인터페이스 -
Tasklet: 간단한 단일 작업 시 사용 -
Chunk: 한 번에 처리 될 row수를 의미하는 Chunk라는 단위를 생성하고, 해당 단위로 트랜잭션을 수행 → 주로 대용량 데이터 처리 시 사용되며, Reader, Processor, Writer 단계를 거침
💻 구현
Spring Boot 3.x + Spring Batch 5.x 버전 사용!
⚙️ 설정
- build.gradle
implementation 'org.springframework.boot:spring-boot-starter-batch' # batch
implementation 'org.springframework.boot:spring-boot-starter-quartz' # 스케줄러- application.yml
-
job.enabled: 서비스가 실행될 때, 배치 작업을 자동으로 실행할 것인지에 대한 설정true: 서비스 실행 시 배치 실행 /false: 실행 X
-
jdbc.initialize-schema: 배치 관련 메타 테이블 생성 여부always: 항상 생성 /embedded: 내장 DB인 경우, 생성 /never: 생성하지 않음
spring:
batch:
job:
enabled: false
jdbc:
initialize-schema: always만약 jdbc:initialize-schema: always 임에도 테이블이 생성되지 않는다면, schema-db명.sql 파일을 찾아서 스크립트를 복사한 후 DB에서 직접 실행시켜주면 된다.
인텔리제이의 경우 CTRL+N 후 files에서 schema로 검색하면 쉽게 찾을 수 있음!
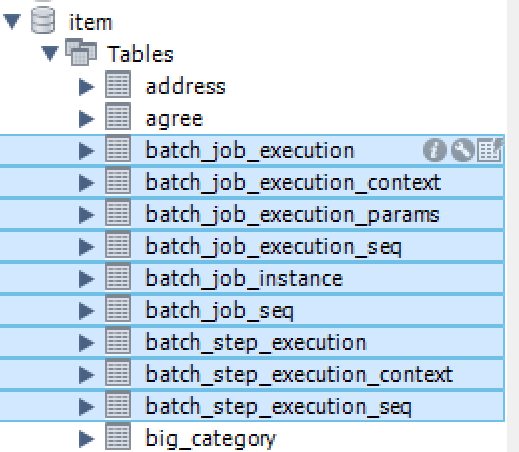 총 9개의 메타테이블이 생성되어야 함!
총 9개의 메타테이블이 생성되어야 함!
📝 처리 로직
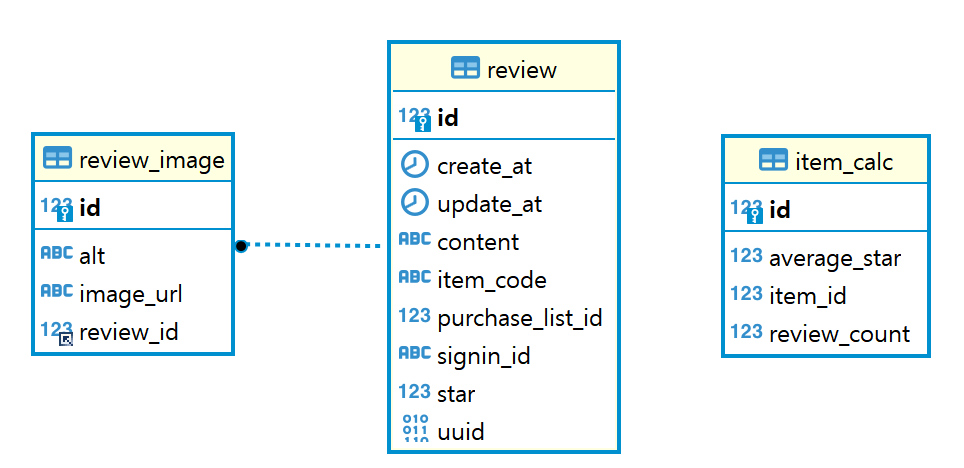
각 상품에 대한 집계 데이터(평균 별점, 리뷰 개수)를 리뷰가 등록될 때마다 업데이트 하는 것은 비효율적이라고 판단했고, 이를 해결하기 위해 30분 단위로 데이터를 집계하여 업데이트하는 방식으로 로직을 구현하기로 함.
이런 방식으로 구현하면 리뷰 데이터를 실시간으로 반영할 수 없다는 문제가 발생하기는 하는데, 실제 쇼핑몰에서도 리뷰 검수 등의 단계를 거쳐 바로 보여주지 않는 곳이 있기 때문에 괜찮다고 판단했고,, 대신 시간을 30분 단위로 정하여 최대한 빠르게 반영될 수 있도록 처리하기로 함!
✍🏻 코드
- JobConfig
실행할 Job에 대한 정의 : Step, Reader, Processor, Writer 등
Job
-
JobRepository와 트랜잭션 매니저를 생성하고, 이를 각 스텝마다 전달 -
JobBuilder: Job의 이름, Step 등을 정의 ➡️ 해당 Job은 스텝을 하나만 가지고 있지만, Step을 순차적으로 실행시키고 싶다면.next(step)으로 이어나가면 됨!
@Bean(name = "itemSummaryJob")
public Job itemSummaryJob(JobRepository jobRepository, PlatformTransactionManager txm) throws Exception {
return new JobBuilder("itemSummaryJob", jobRepository)
.start(step(jobRepository, txm))
.build();
}Step
-
@JobScope: Job 실행 시 bean을 생성하며, Job의 생명주기 관리 -
StepBuilder: Step의 이름, 작업 단위(taskle/chunk) 등을 정의-
Chunk단위 사용 : 상품 데이터가 약 1000개 이므로, 100개 단위로 묶어서 트랜잭션 실행 -
allowStartIfComplete: 이미 완료된 Job을 실행시킬 지에 대한 설정
-
@Bean(name = "itemSummaryStep")
@JobScope
public Step step(JobRepository jobRepository, PlatformTransactionManager txm) throws Exception {
return new StepBuilder("itemSummaryStep", jobRepository)
.<ReviewSummaryDTO, ItemCalc>chunk(100, txm)
.reader(reader())
.processor(processor())
.writer(writer())
.allowStartIfComplete(true)
.build();
}ItemReader
-
@StepScope: Step 실행 시 bean을 생성하며, Step의 생명주기 관리 -
Review테이블에서 각 상품 별 집계 데이터를 조회하여ReviewSummaryDTO형태로 저장하기 위한 Reader 🌟 -
JpaPagingItemReaderBuilder: JPA의 페이징을 활용하여 데이터를 읽어오기 위한ItemReader구현체 → 원래는 Querydsl을 활용하려고 했으나,, 구현체를 직접 구현해야 해서 이미 구현되어 있는 페이징 구현체 사용,,pageSize: Chunk의 단위 사이즈와 동일하게 지정 (100개)queryString: 데이터를 읽어오기 위한 쿼리
@Bean
@StepScope
public JpaPagingItemReader<ReviewSummaryDTO> reader() throws Exception {
return new JpaPagingItemReaderBuilder<ReviewSummaryDTO>()
.pageSize(100)
.queryString(
"select new com.comehere.ssgserver.review.dto.resp.ReviewSummaryDTO("
+ "min(i.id), min(ic.id), round(avg(r.star), 1), count(r)) "
+ "from Review r "
+ "join Item i on r.itemCode = i.code "
+ "join ItemCalc ic on i.id = ic.itemId "
+ "group by r.itemCode"
)
.entityManagerFactory(emf)
.name("itemSummaryReader")
.build();
}ItemProcessor
-
Reader에서 읽어온
ReviewSummaryDTO를ItemCalc형태로 변환하기 위한 Processor 🌟 -
ItemProcessorBuilder:process(가공할 데이터)를 통해 데이터 처리 로직 구현
@Bean
@StepScope
public ItemProcessor<ReviewSummaryDTO, ItemCalc> processor() {
return new ItemProcessor<ReviewSummaryDTO, ItemCalc>() {
@Override
public ItemCalc process(ReviewSummaryDTO dto) throws Exception {
return ItemCalc.builder()
.id(dto.getCalcId())
.reviewCount(dto.getReviewCount())
.averageStar(dto.getAverageStar())
.build();
}
};
}ItemWriter
- Proccesor에서 처리한
ItemCalc를 데이터베이스의Item_Calc테이블에 최종적으로 저장 ➡️ 변경 내역 업데이트 🌟
@Bean
@StepScope
public JpaItemWriter<ItemCalc> writer() {
return new JpaItemWriterBuilder<ItemCalc>()
.entityManagerFactory(emf)
.build();
}✅ 전체 코드
@Slf4j
@Configuration
@RequiredArgsConstructor
@Transactional
public class BatchJobConfig {
private final EntityManagerFactory emf;
@Bean(name = "itemSummaryJob")
public Job itemSummaryJob(JobRepository jobRepository, PlatformTransactionManager txm) throws Exception {
log.info("job start");
return new JobBuilder("itemSummaryJob", jobRepository)
.start(step(jobRepository, txm))
.build();
}
@Bean(name = "itemSummaryStep")
@JobScope
public Step step(JobRepository jobRepository, PlatformTransactionManager txm) throws Exception {
log.info("step start");
return new StepBuilder("itemSummaryStep", jobRepository)
.<ReviewSummaryDTO, ItemCalc>chunk(100, txm)
.reader(reader())
.processor(processor())
.writer(writer())
.allowStartIfComplete(true)
.build();
}
@Bean
@StepScope
public JpaPagingItemReader<ReviewSummaryDTO> reader() throws Exception {
log.info("reader start");
return new JpaPagingItemReaderBuilder<ReviewSummaryDTO>()
.pageSize(100)
.queryString(
"select new com.comehere.ssgserver.review.dto.resp.ReviewSummaryDTO("
+ "min(i.id), min(ic.id), round(avg(r.star), 1), count(r)) "
+ "from Review r "
+ "join Item i on r.itemCode = i.code "
+ "join ItemCalc ic on i.id = ic.itemId "
+ "group by r.itemCode"
)
.entityManagerFactory(emf)
.name("itemSummaryReader")
.build();
}
@Bean
@StepScope
public ItemProcessor<ReviewSummaryDTO, ItemCalc> processor() {
log.info("processor start");
return new ItemProcessor<ReviewSummaryDTO, ItemCalc>() {
@Override
public ItemCalc process(ReviewSummaryDTO dto) throws Exception {
return ItemCalc.builder()
.id(dto.getCalcId())
.reviewCount(dto.getReviewCount())
.averageStar(dto.getAverageStar())
.build();
}
};
}
@Bean
@StepScope
public JpaItemWriter<ItemCalc> writer() {
log.info("writer start");
return new JpaItemWriterBuilder<ItemCalc>()
.entityManagerFactory(emf)
.build();
}
}💾 실행
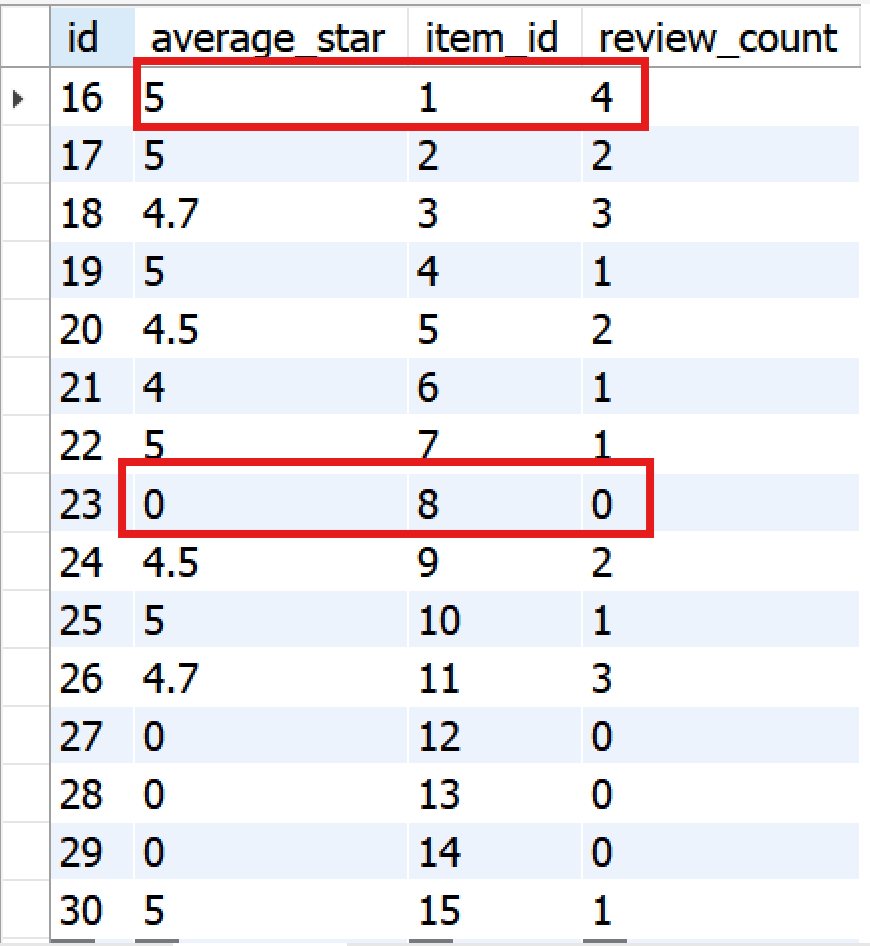
현재 상품별 집계 내역은 아래와 같은데, 현재 집계 데이터가 없는 8번 상품의 리뷰를 작성하고, 1번 상품의 리뷰를 추가로 작성한다고 했을 때, 배치 실행 후 집계 내역은 어떻게 변할까?
🌟 배치 작업 수행
실행 시간이 정각이 아닌 이유는 테스트를 위해
job.enabled: true로 설정했기 때문,,
1. Reader
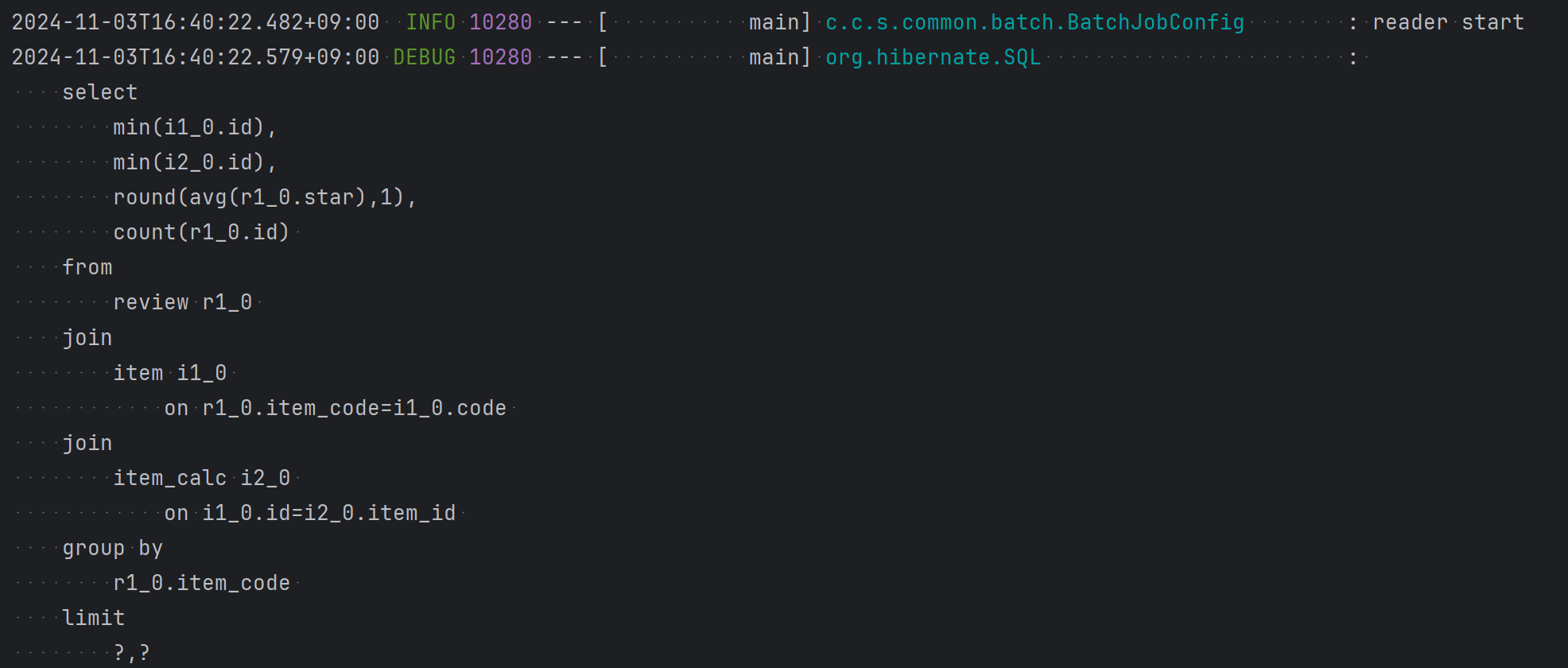 : Reader에 작성한 쿼리를 실행하여 집계 내역 조회
: Reader에 작성한 쿼리를 실행하여 집계 내역 조회
2. Processor + Wirter

 : JPA의 변경 감지를 활용하여 업데이트 된 2개의 상품(1번, 8번)에 대해 업데이트 실행
: JPA의 변경 감지를 활용하여 업데이트 된 2개의 상품(1번, 8번)에 대해 업데이트 실행
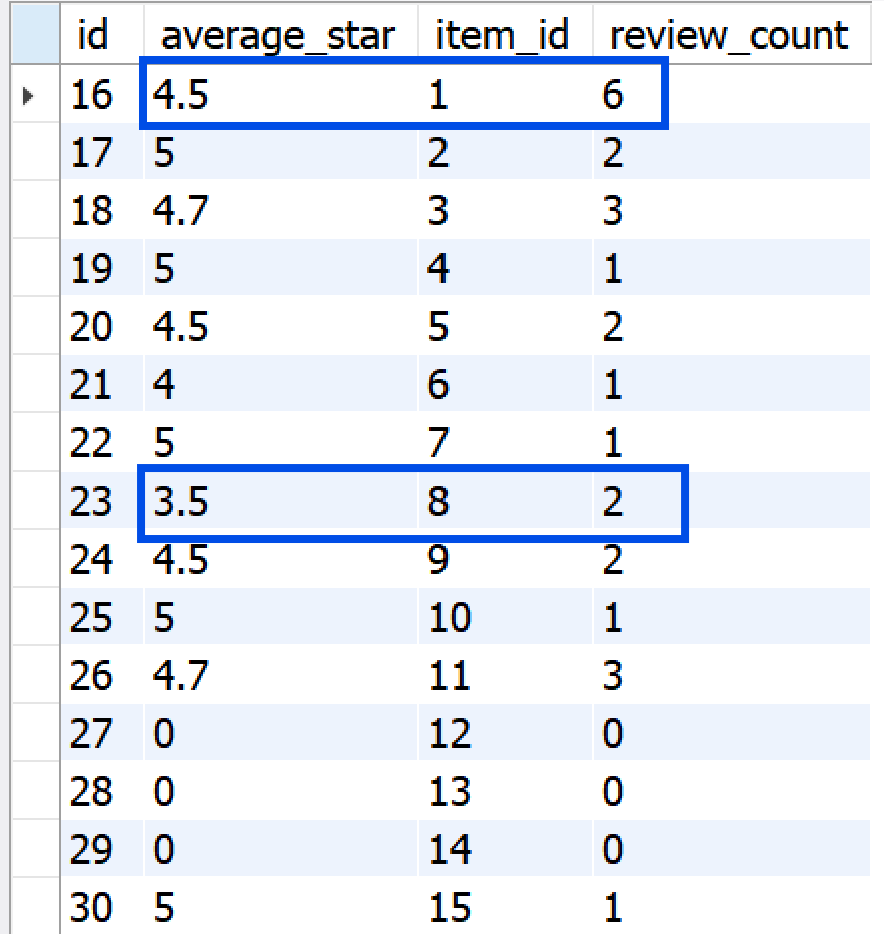
✅ 결과
1번과 8번 각각 2개의 리뷰를 추가로 작성하였고, 그에 따라 리뷰 개수와 평균 별점이 업데이트 된 것을 확인할 수 있다!
🙏🏻 참고
