
⚠️ 문제
잦은 업데이트로 인한 서버 및 데이터베이스 트래픽 증가
MFC에서 파트너의 포스팅, 파트너의 팔로우 등을 관리하는 SNS 서비스를 구현했는데, 이 중 사용자가 포스팅 좋아요 등록/취소나 파트너 팔로우 추가/취소 버튼을 계속해서 클릭했을 때 각 작업에 대해 업데이트 구문이 발생하게 되는데, 이 부분에서 MySQL 서버에 계속 접근하는 과정에서 너무 많은 부하를 발생시키지 않을까? 라는 생각이 들었다.
 실제로 동시에 한 포스팅 혹은 파트너에 대해 n명의 사용자가 좋아요나 팔로우를 등록하기만 해도 총 n건의 업데이트문이 발생하게 된다. 업데이트문이 실행될 때마다 MySQL 서버에 접근하게 되고, 이러한 작업이 동시에 많이 발생하게 되면 그만큼 부하가 증가하여 처리 속도가 길어지게 된다.
실제로 동시에 한 포스팅 혹은 파트너에 대해 n명의 사용자가 좋아요나 팔로우를 등록하기만 해도 총 n건의 업데이트문이 발생하게 된다. 업데이트문이 실행될 때마다 MySQL 서버에 접근하게 되고, 이러한 작업이 동시에 많이 발생하게 되면 그만큼 부하가 증가하여 처리 속도가 길어지게 된다.
💡 해결 방안 : 배치 서버 도입
🌟 배치 서비스 도입 : 업데이트 내역을 집계하여 배치로 한 번에 업데이트 처리
배치 로직 자체는 SSG.COM 프로젝트에서 적용했던 배치 처리와 유사하지만, 이번 프로젝트는 MSA 환경으로 구성되어 있기 때문에 처리 로직이 더 복잡해질 수 밖에 없다..
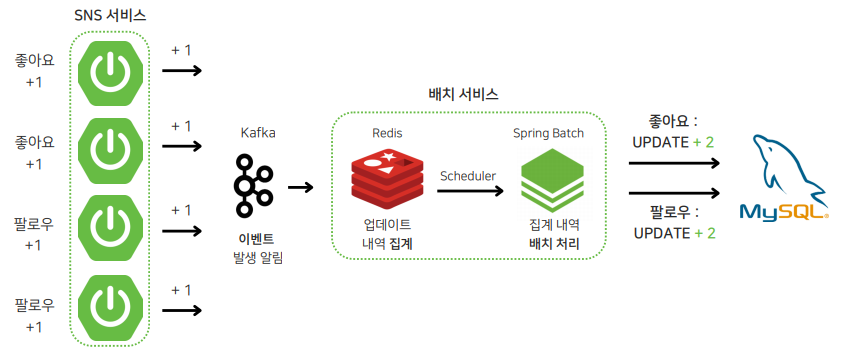 일단 전반적인 로직은 SNS 서비스에서 업데이트 작업 발생하면 Kafka를 통해 포스팅/파트너 ID와 업데이트 내역을 배치 서비스에 전달하고, 배치 서비스에서는 이를 Redis에 집계해두었다가 스케줄러를 통해 특정 시간마다 업데이트 내역을 MySQL에 최종적으로 반영 하도록 구성하였다.
일단 전반적인 로직은 SNS 서비스에서 업데이트 작업 발생하면 Kafka를 통해 포스팅/파트너 ID와 업데이트 내역을 배치 서비스에 전달하고, 배치 서비스에서는 이를 Redis에 집계해두었다가 스케줄러를 통해 특정 시간마다 업데이트 내역을 MySQL에 최종적으로 반영 하도록 구성하였다.
여기서 업데이트 내역을 최대한 빠르게 반영하기 위해 스케줄러 실행 간격을 초 단위로 설정하였다. 이외에도 해당 로직을 구성하기 위해 고민했던 2가지의 문제를 아래에 자세히 설명해보겠다.
🤔 고민
- 배치 로직 구현 : 기존 서비스 VS 배치 서버 분리
이전에는 모놀리식 구조였기 때문에 비즈니스 로직과 배치 로직이 하나의 서비스에 구현되었지만, 이번 프로젝트는 MSA 환경이였기 때문에 많은 고민을 했는데,, 결국 배치 서버를 분리하기로 한 이유는 아래와 같다,,
-
다른 서비스에서도 배치 로직이 필요했는데, 이를 각 서비스에서 관리하기 보다는 하나의 서비스에서 일괄 관리하는 것이 효율적이라고 판단함
-
배치 로직이 짧은 간격으로 실행되기 때문에, 배치 로직에서 많은 자원을 사용하게 되면 다른 비즈니스 로직의 실행에 영향을 미치게 됨
-
장애 전파를 최소화하기 위한 MSA의 장점을 살려, 배치 서비스에서 문제가 발생해도 기존 서비스는 정상적으로 실행될 수 있도록 설계
이를 구현하기 위해서는 SNS 서비스 업데이트 내역을 배치 서비스로 전달하기 위한 로직이 추가적으로 필요했고, 이는 Kafka를 통해 구현하였다. Kafka를 선택하게 된 이유와 데이터 전달 로직과 관련된 자세한 내용은 이 글에서 자세히 다루고 있다! (데이터 전달 관련은 이 부분은 아니긴 함..)
- 업데이트 내역 집계 : Map VS Redis
배치 서비스는 전달받은 데이터를을 사용하여 다음 스케줄러가 실행되기 전까지의 업데이트 내역을 집계해야 한다. (ex : 30초 사이에 n번 글의 좋아요 개수가 4개 증가 → n, +4)
각 ID 별로 내역을 집계해야 하기 때문에 <ID : 업데이트 내역>, 즉, <Key, Value> 형태로 데이터를 저장할 수 있는 Map과 Redis 중에 고민하다가,, 최종적으로 Redis를 선택하게 된 이유는 다음과 같다.
-
Map은 메모리 기반이기 때문에 애플리케이션 서버가 꺼지면 저장된 데이터가 휘발되지만, Redis는 별도의 데이터베이스 서버 기반으로 동작하므로 애플리케이션의 서버가 꺼져도 저장된 데이터가 유지됨
-
빠른 데이터 접근 및 대규모 데이터 저장에 적합
💻 구현
포스팅과 파트너 처리 로직이 동일하므로, 포스팅 관련 작업에 대한 코드만 작성 + 배치 처리 로직이 중요하므로 Config, Controller 등의 일부 내용은 생략될 예정!
1. SNS 서비스
✅ 포스팅 좋아요 등록/취소 요청 시
ID, 업데이트 내역을 배치 서비스로 전송
- KafkaProducer, PostSummaryDTO
@Service
@RequiredArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, Object> kafkaTemplate;
public void createBookmark(PostSummaryDto dto) { // 좋아요 등록
kafkaTemplate.send("create-bookmark", dto);
}
public void deleteBookmark(PostSummaryDto dto) {
kafkaTemplate.send("delete-bookmark", dto); // 좋아요 취소
}
}
@Getter
@Builder
public class PostSummaryDto {
private Long postId;
private String partnerId;
}지금 와서 드는 생각인데,, producer를 두 개로 분리하지 말고 producer는 하나만 두고 DTO에 업데이트 상태?(등록/취소)를 구분하는 추가해서 분기점 두고 구현하는 게 훨씬 덜 복잡하기 편했을 것 같기도,,
- BookmarkServiceImpl
createBookmark: 좋아요 내역 저장 후, 메시지 생성deleteBookmark: 좋아요 취소 시, 좋아요 내역 삭제 후 메시지 생성
@Service
@Transactional
@Slf4j
@RequiredArgsConstructor
public class BookmarkServiceImpl implements BookmarkService {
private final BookmarkRepository bookmarkRepository;
private final KafkaProducer producer;
@Override
public void createBookmark(Long postId, String userId) { // 좋아요 등록
if(bookmarkRepository.existsByPostIdAndUserId(postId, userId)) {
throw new BaseException(BOOKMARK_CONFLICT);
}
bookmarkRepository.save(Bookmark.builder()
.userId(userId)
.post(postId)
.build());
producer.createBookmark(PostSummaryDto.builder().postId(postId).build());
}
@Override
public void deleteBookmark(Long postId, String userId) { // 좋아요 취소
int cnt = bookmarkRepository.deleteByPostId(postId, userId);
if(cnt > 0) producer.deleteBookmark(PostSummaryDto.builder().postId(postId).build());
}
}2. 배치 서비스 (1) : 업데이트 내역 집계
✅ 업데이트 내역을 Redis에 집계
- KafkaConsumer
createBookmark:increment(key, 1)을 통해 key번 글의 좋아요 개수 +1deleteBookmark:decrement(key, 1)을 통해 key번 글의 좋아요 개수 -1
@Service
@RequiredArgsConstructor
@Slf4j
@Transactional
public class KafkaConsumer {
private final PostSummaryRepository postSummaryRepository;
private final RedisTemplate<String, Object> redisTemplate;
private static final String POST_PREFIX = "post:like:";
@KafkaListener(topics = "create-bookmark", containerFactory = "postSummaryListener")
String key = POST_PREFIX + dto.getPostId();
redisTemplate.opsForValue().increment(key, 1);
}
@KafkaListener(topics = "delete-bookmark", containerFactory = "postSummaryListener")
public void deleteBookmark(PostSummaryDto dto) {
String key = POST_PREFIX + dto.getPostId();
redisTemplate.opsForValue().decrement(key, 1);
}
}3. 배치 서비스 (2) : 배치 로직 구현 및 실행
✅ Redis의 집계 내역을 MySQL에 최종적으로 반영 → 30초 간격으로 실행
- PostJobConfig
sacnKeys(pattern): Redis 내에 저장된 다양한 업데이트 내역 중, 구별자를 통해 포스팅 관련 데이터만 조회하기 위한 메서드
private Set<String> scanKeys(String pattern) {
Set<String> keys = new HashSet<>();
ScanOptions options = ScanOptions.scanOptions().match(pattern).count(1000).build();
try (Cursor<byte[]> cursor = redisTemplate.getConnectionFactory()
.getConnection()
.scan(options)) {
while (cursor.hasNext()) {
keys.add(new String(cursor.next()));
}
} catch (Exception e) {
throw new RuntimeException("Failed to scan Redis keys", e);
}
return keys;
}
ItemReader: Redis에서 포스팅 관련 내역을 조회하여 포스팅 ID와 업데이트 내역을PostBookmarkDTO형태로 저장했다면, Redis에는 다음 기간동안의 집계 내역을 새로 저장해야 하므로 기존의 집계 내역 삭제
@Bean(name = "postReader")
@StepScope
public ItemReader<PostBookmarkDto> postSummaryItemReader() {
Set<String> keys = scanKeys("post:like:*");
List<PostBookmarkDto> bookmarkList = new ArrayList<>();
for (String key : keys) {
Long postId = Long.valueOf(key.replace("post:like:", ""));
Integer bookmarkCnt = Integer.valueOf((String)redisTemplate.opsForValue().get(key));
bookmarkList.add(new PostBookmarkDto(postId, bookmarkCnt));
redisTemplate.delete(key);
}
return new ListItemReader<>(bookmarkList);
}ItemProcessor:PostBookMarkDTO→PostSummary변환 시, 기존 좋아요 개수 + 업데이트 내역ItemWriter: MySQL에 업데이트 내역 최종 반영
@Bean(name = "postProcessor")
@StepScope
public ItemProcessor<PostBookmarkDto, PostSummary> postSummaryProcessor() {
return dto -> {
PostSummary summary = postSummaryRepository.findByPostId(dto.getPostId())
.orElseThrow(() -> new BaseException(BaseResponseStatus.POST_NOT_FOUND));
return PostSummary.builder()
.id(summary.getId())
.postId(dto.getPostId())
.bookmarkCnt(summary.getBookmarkCnt() + dto.getBookmarkCnt())
.build();
};
}전체 코드는 너무 길어서,, 깃허브에서 확인 가능!
- JobScheduler
@Slf4j
@Configuration
public class JobScheduler {
private final JobLauncher jobLauncher;
private final Job postSummaryJob;
@Scheduled(fixedRate = 30000) // 30초 간격으로 실행
public void postJobSchedule() throws Exception {
JobParameters jobParameters = new JobParametersBuilder()
.addLocalDateTime("time", LocalDateTime.now())
.toJobParameters();
JobExecution postJob = jobLauncher.run(postSummaryJob, jobParameters);
}
}⚙️ 실행
초기 데이터
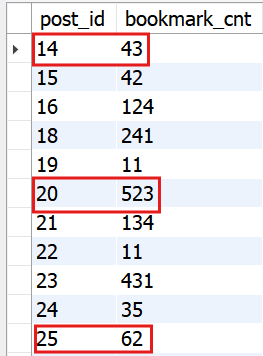
실행 결과
- 14번 포스팅에 사용자 A, B, C가 좋아요 등록 (+3)
- 20번 포스팅에 사용자 A, B, C가 좋아요 등록 후, A가 좋아요 취소 (+3-1=+2)
- 25번 포스팅에 사용자 B가 좋아요 등록 후, 취소 (+1-1=0)

 :
: kafkaConsumer에서 집계 과정에 로그를 찍어서 확인해본 결과, 좋아요 등록텍스트 시에는 집계값+1, 취소 시에는 집계값-1을 수행하는 것을 확인할 수 있다!
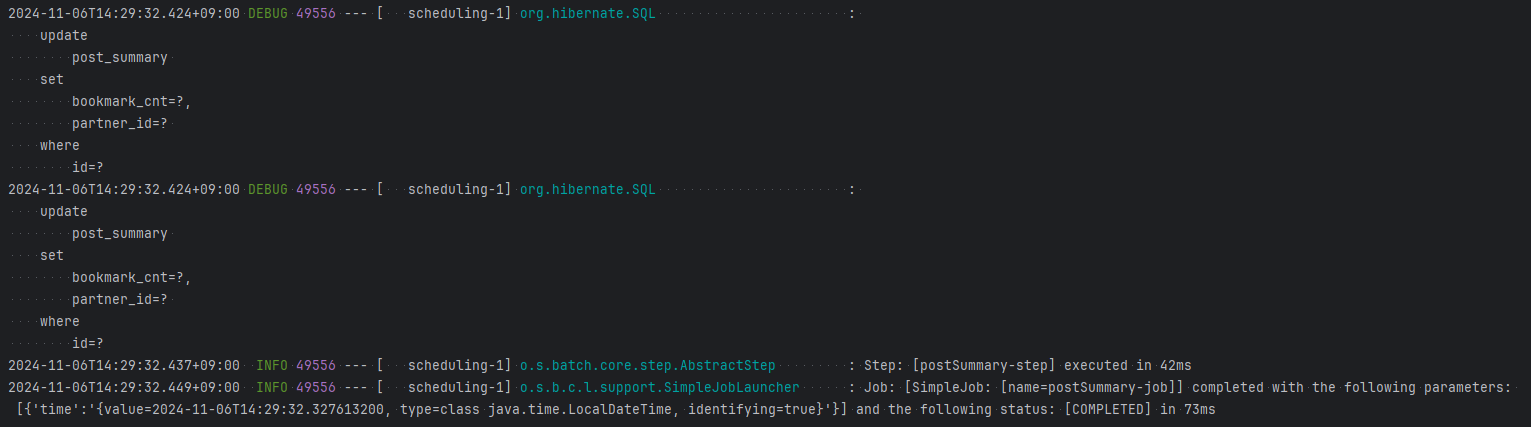 : 배치 실행 후
: 배치 실행 후 ItemWriter에서 실행된 쿼리를 보면, 총 2개의 업데이트문이 실행된 것을 확인할 수 있다. 25번 포스팅의 경우 등록과 취소가 한 번에 이루어져 집계값이 0이기 때문에 값이 변하지 않았고, 이로 인해 JPA의 변경 감지가 적용되지 않아 업데이트문이 별도로 실행되지 않았다.
업데이트문은 각 포스팅에 대해 실행되기 때문에 N개의 포스팅에 대한 업데이트가 발생하면 N개의 업데이트문이 실행되기는 하겠지만, 그래도 위 작업들을 배치 처리 없이 각자 업데이트 처리 했다면 3개의 포스팅에 대해 총 9개(14번 3개, 20번 4개, 25번 2개)의 업데이트문이 발생했을 것이다. 쿼리 개수가 줄어든 것은 물론이고, 다수의 업데이트문이 하나의 트랜잭션으로 처리되므로 DB 서버에 대한 접근이 줄어 트래픽 수 또한 줄일 수 있을 것이다!
➕
그러나 이를 완벽한 해결책이라고 볼 수는 있을까? 처음에는 집계 처리 과정에서 발생하는 업데이트 처리 최적화에 대해서만 고민해서 위와 같은 해결책을 생각했었는데, 배치 로직을 구현하다 보니 Redis에 접근하거나, 변경 감지를 위한 SELECT문 추가 실행에 대한 트래픽 문제가 신경쓰이기 시작했다,, 변경 감지의 경우 JPA를 사용하지 않으면 해결될 것 같기도 하고?,, 하여튼 이 부분에 대해서는 더 고민해봐야 할 것 같다,,!
