목표

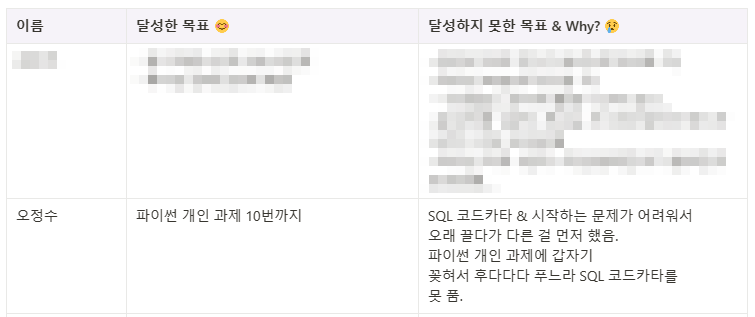
파이썬 개인 과제
4번(여성 생존자 수 계산)
- 문제) 타이타닉 승객의 생존자 중 여성 생존자의 수를 계산하고 출력하세요.
- tip!) 성별 정보는 ‘Sex’ Columns에 존재하며 여성은 ‘female’, 남성은 ‘male’로 정의되어 있습니다.
- tip!) zip 함수를 이용하면 2개 이상의 반복할 것을 동시에 반복할 수 있습니다.
a=sum(df['Sex']=='female')
print(f"여성 생존자는 {a}명입니다.")zip 함수를 알아보는데 굳이 필요 없을 거 같아서 사용하지 않았다.
근데 저건 여성 생존자가 아닌 타이타닉 승객 중 여성의 수이기에 틀렸다.
df['Survived'][df['Sex'] == 'female']
df[(df['Survived'] == 1) & (df['Sex'] == 'female')]첫번째 코드는 여성인 사람의 생존 여부를 알려주는 코드이다.
두번째 코드는 생존한 여성의 데이터프레임을 만들어준다.
6번(특정 연령대 승객 추출)
- 문제) 20세 이하의 승객의 이름들을 추출 하여 승객의 이름을 key로, 승객의 나이를 value로 하는 딕셔너리를 완성하세요.
a=df[df['Age']<=20]
b={'name':a['Name'],'age':a['Age']}
print(b['name'])
b.keys()잘 몰랐을 때 딕셔너리를 만드는 방법을 몰라서 막 썼었다.
a=df[df['Age']<=20]
a_name=a['Name']
a_age=a['Age']
b=dict(zip(a_name,a_age))우선 20세 이하를 추출하고 아까 본 zip함수를 활용해서 dict()함수로 딕셔너리로 변환해주었다.
이전에는 type()으로 확인해보니 pandas.core.series.Series였다.
7번(가장 많은 탑승객 수를 가진 선실 등급 찾기)
- 문제) 타이타닉의 선실 등급 중에서 가장 많은 탑승객이 이용한 선실 등급을 찾으세요
- tip!) 선실 등급은 ‘Pclass’ column에 있으며 1,2,3 등급으로 이루어져 있습니다.
third=sum(df['Pclass']==3)
second=sum(df['Pclass']==2)
first=sum(df['Pclass']==1)
if first >= second and first >= third:
return first
elif second >= first and second >= third:
return second
else:
return third처음 적은 코드다.
알아보니 return은 함수 내에서 사용 가능했다.
def x(df):
third=sum(df['Pclass']==3)
second=sum(df['Pclass']==2)
first=sum(df['Pclass']==1)
if first >= second and first >= third:
return '1등급'
elif second >= first and second >= third:
return '2등급'
else:
return '3등급'
print(f"가장 많은 탑승객 수를 가진 선실 등급은 {x(df)}이다.")함수를 만들어 깔끔하게 적었다.
9번(각 성별의 생존율 계산)
- 문제) 타이타닉 각 성별 (남성/여성) 각각의 생존율을 계산하세요
m_tot=len(df['Sex']=='male')
f_tot=len(df['Sex']=='female')
m_sur=len(df[(df['Sex']=='male') & (df['Survived']==1)])
f_sur=len(df[(df['Sex']=='female') & (df['Survived']==1)])
print(f"타이타닉 성별 생존율은 다음과 같다.\n
남자 생존율:{m_sur/m_tot*100}\n
여자 생존율:{f_sur/f_tot*100}")가시성을 위해서 print()함수 내에 띄어쓰기를 했는데 오류가 생겼다.
m_tot=len(df['Sex']=='male')
f_tot=len(df['Sex']=='female')
m_sur=len(df[(df['Sex']=='male') & (df['Survived']==1)])
f_sur=len(df[(df['Sex']=='female') & (df['Survived']==1)])
print(f"남자 생존율:{m_sur/m_tot*100}\n"
f'여자 생존율:{f_sur/f_tot*100}')이렇게 f-string 함수를 두 번 쓰면 된다.
마무리
어제까지만 해도 파이썬이 증오스러웠다.
너무 어렵고 하나도 이해가 안됐다.
아직 for 반복문은 이해 못했다.
그래도 다행히 for을 사용하지 않아도 풀 수 있었다.
내일은 for를 알아보자.

안녕하세요 오정수입니다