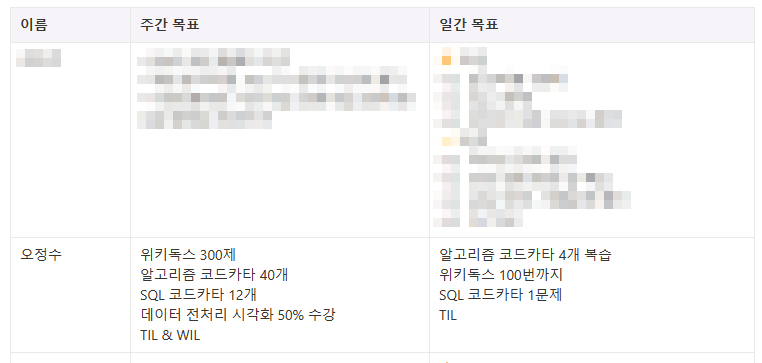
TIL
1.TIL - SQL 1주차 강의
TIL 20240320
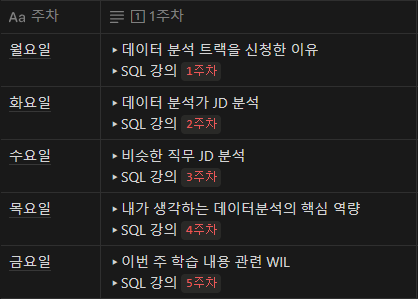
2.TIL - SQL 2주차 강의

바로 본론으로 첫 시간은 1주차 강의 복습이었다. 위 그림과 같다. 다음은 계산하는 방법을 배웠다. 사칙연산인 +, -, shift+8, / 말고도 여러개를 할 수 있다. 위의 그림과 같다. 이때 count에 노랑색을 기억하자. 다음은 실습을 하고 범주별 연산
3.TIL - SQL 3주차 강의

오늘 실습이 많은 날이었다. 처음엔 쉬웠는데 점점 응용을 해서 꽤나 어려워 내 마음이 심란했다. 전 강의 복습을 했다. SQL 기본 구조이며 순서는 select, from, where, group by, order by 순이다. 다음은 가공문에 대해 배웠다. 하
4.TIL - 4주차 SQL 강의

주말 동안 4주차를 학습했다. 우선 3주차 복습을 했다.replace, substring, concat, if, case의 구조와 뜻을 이해했다. 이번에는 서브쿼리를 배웠다.서브쿼리가 필요한 경우는 다음과 같다.1\. 여러 번의 연산이 필요할 때2\. 조건문에 연산 결
5.TIL - SQL 코드카타
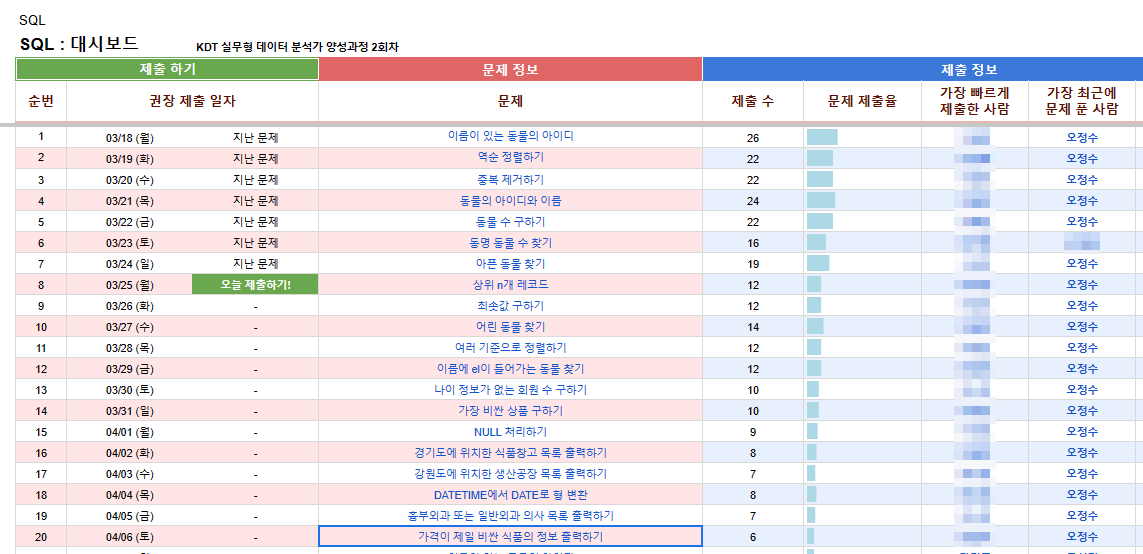
오늘은 SQL 강의 5주차를 앞두고 문제들을 풀었다.이유는 나의 코딩 능력이 어떤지 알아보기 위해서이다. 20문제를 와다다다 풀었다. 가장 최근에 문제를 푼 사람에 내 이름이 도배가 되었을 때 희열은 이루 말할 수가 없다.이 문제들을 풀면서 알게 된 것이 3개 있다.하
6.TIL - 파이썬 강의 정리 1

파이썬을 설치하고 제일 먼저 한 것은hello335 3파이썬은 살짝 R이나 SQL과 조금 달라서 다른 거와 병행하기 조금 힘들다.매커니즘이 달라서 생각할 때 멈칫 멈칫한다.변수에 저장된 값을 연산 후 다시 값을 저장할 수 있다.811boolean으로 참과 거짓을 나타낼
7.TIL - 파이썬 강의 정리 2
리스트는 순서가 있는 다른 자료형들의 모임이다.a = 1, 5, 2print(len(a)) b = \[1, 3, 2, 0, 1]print(len(b)) \`\`\`순서가 있기에 문자열처럼 인덱싱과 슬라이싱이 가능하다.a = \[1, 2, 2, 3, 0]print
8.TIL - 240422
오늘 일일 과제가 있어서 과제를 했는데 너무 쉬웠다.아직 난이도가 쉬워서 15분안에 4문제를 모두 끝냈다.근데 복붙을 하다가 실수를 해서 확인을 하려고 노력해야겠다.알고리즘 코드카타를 3개했다.몫과 나머지는 //과 %인데 헷갈렸다.SQL 코드카타를 2문제 풀었다.주요
9.TIL - 240423
중복값 제거에 distinct를 넣지 않았다.having에는 select 뒤에 만든 새로운 열 이름을 사용할 수 있지만 where에는 사용 불가능하다.group by > having > order by 등등 group by 부터 사용 가능하다고 한다.3개를 풀었다.기초
10.TIL - 240424
날짜 적으니까 뭔가 이쁘다 오늘 날짜.240424 중복되는 게 많아서 이쁘다.마치 2022년 2월 22일같은 느낌.오늘 목표리터리시 강의 3/5 완료SQL 코드카타 복습 9/10 완료알고리즘 코드카타 2/3 완료파이썬 코테 책 1단원 안 함일일과제 완료오늘은 일일 과제
11.TIL - 240425
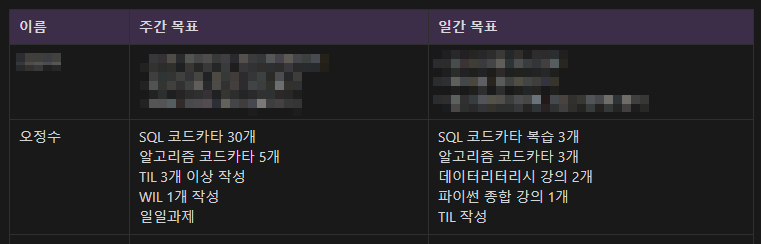
오늘 목표를 모두 이루었다.데이터 리터리시는 내일 노션을 한 번 읽고 정리해서 WIL에 작성할 거다.64번 문제count()를 사용할 때 group by()를 무조건 사용하자.having()에 count()를 사용해서 까먹었다 유의하자.9번 문제for()과 range
12.TIL - 240426
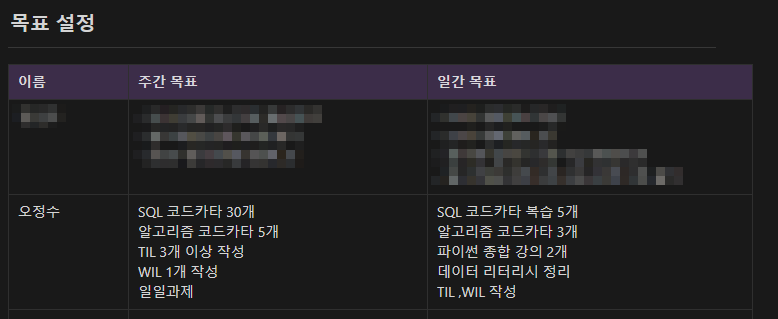
알고리즘 코드카타가 어려워서 1개만 풀었다. 파이썬 종합 강의와 데이터 리터리시는 정리해서 WIL에 올릴 것이다.5문제를 풀었다.68번 문제는 내가 문제를 제대로 읽지 않았다.특정 월 데이터만 뽑아서 where과 like를 통해서 뽑아냈다.69번은 어려웠다.다음에 또
13.TIL - 240427

계획 주말이니 조금 여유롭게 파이썬을 공부할 계획이다. 우선 복습을 하고 4,5주차 강의를 들을 수 있으면 들어보려 한다. 우선 오늘 TIL에서는 1~3주차 강의를 정리할 것이다. 파이썬 종합 강의 1주차 출력문 Python의 기본은 출력문이다. > print()
14.TIL - 240430
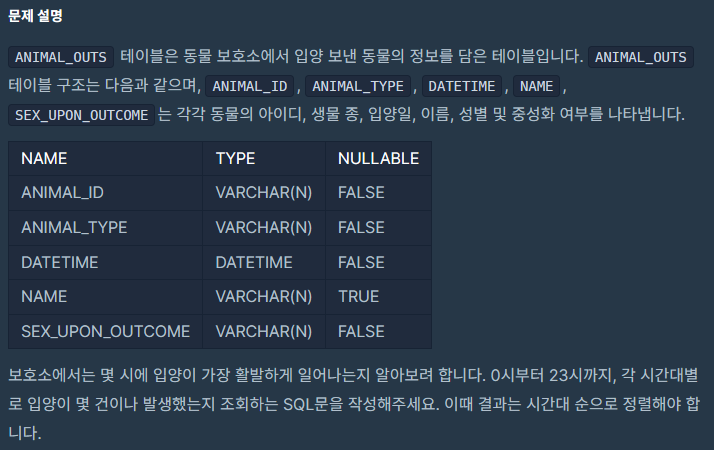
코드카타는 모르는 거나 틀린 거를 기록할 예정이다.코드들을 복기하면서 정리할 거다. 도저히 0시부터 23시까지 조회를 못하겠더라.그래서 결국 해설을 봤는데 처음 보는 친구가 있었다.RECURSIVE라고 하는 그래서 대충 해설 보고 했는데 실수를 했다.솔직히 아직 잘 모
15.TIL - 240501
문제) 타이타닉 승객의 생존자 중 여성 생존자의 수를 계산하고 출력하세요.tip!) 성별 정보는 ‘Sex’ Columns에 존재하며 여성은 ‘female’, 남성은 ‘male’로 정의되어 있습니다.tip!) zip 함수를 이용하면 2개 이상의 반복할 것을 동시에 반복할
16.TIL - 240502
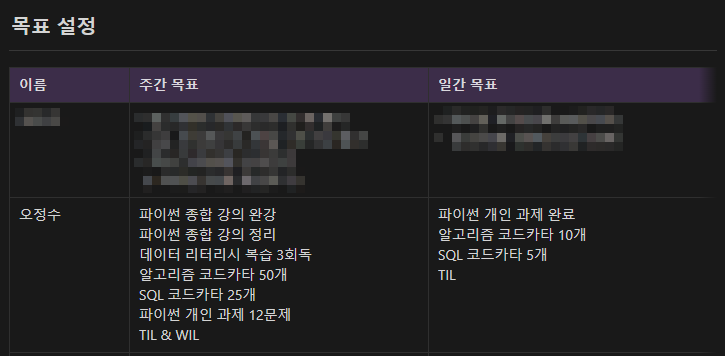
월요일까지만 해도 파이썬 너무 어려워서 징징거렸는데 많이 발전했다.알고리즘 코드카타를 하면서 느꼈다.어제는 파이썬의 기초적인 걸 이해했다면 오늘은 for문에 대해 대충 이해했다.좋다.자연수 N이 주어지면, N의 각 자릿수의 합을 구해서 return 하는 solutio
17.TIL - 240508
연휴가 지나고 기강이 해이해졌다.다시 TIL을 작성해 보자. 메서드 append()로는 맨 뒤에 추가인데 insert를 사용하면 원하는 인덱스에 삽입할 수 있다.추가로 numpy에 있는 mean()을 사용할 수도 있다.메서드 join()으로 리스트를 하나의 문자열로
18.TIL - 240514

\+=과 같은 개념으로 \*=도 돼서 신기했다.첫번째 코드로 하면 리스트가 출력된다.그래서 두번쨰 코드로 해야 보기와 같이 출력된다.첫번째 코드는 오류가 나온다.for문을 저렇게 쓰면 안되는 거 같다.두번째 코드는 0이 출력된다.리스트로 추가할 수가 없는 거 같다.세번
19.TIL - 240516
계획 오늘 위키독스 20문제를 하고 개인과제를 했는데 판다스 개인 과제가 생각보다 어려웠다. 배웠는데 다 까먹어서 체화의 중요성을 느끼고 경각심을 동시에 느꼈다. 위키독스 185번 첫번째 코드로 사용하면 [101, 102] 호와 같이 출력된다. 이중 리스트이기에
20.TIL - 240701
안녕 오랜만에 TIL이다. 5월 16일이 마지막인 걸 보니 많이 부끄럽다. 쓰려고 메모만 하다가 귀찮아서 안 쓴 날, 프로젝트로 바빠서 미룬 날, 어느덧 TIL을 안 쓰고 패널티 같은 게 없어 해이해졌다. 그래도 이제 24년도 하반기 시작을 맞이해서 나를 리프레시
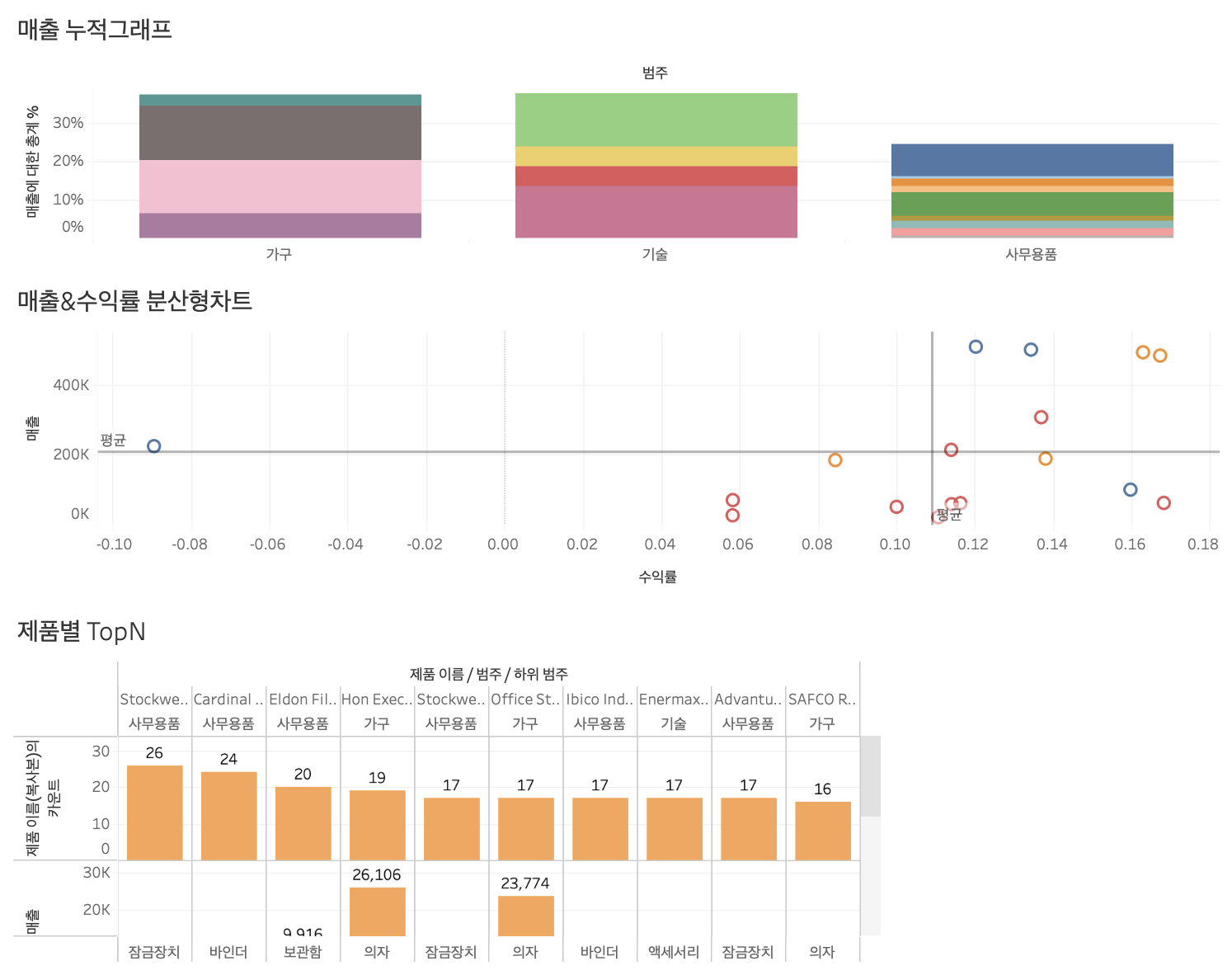
21.TIL - 240702
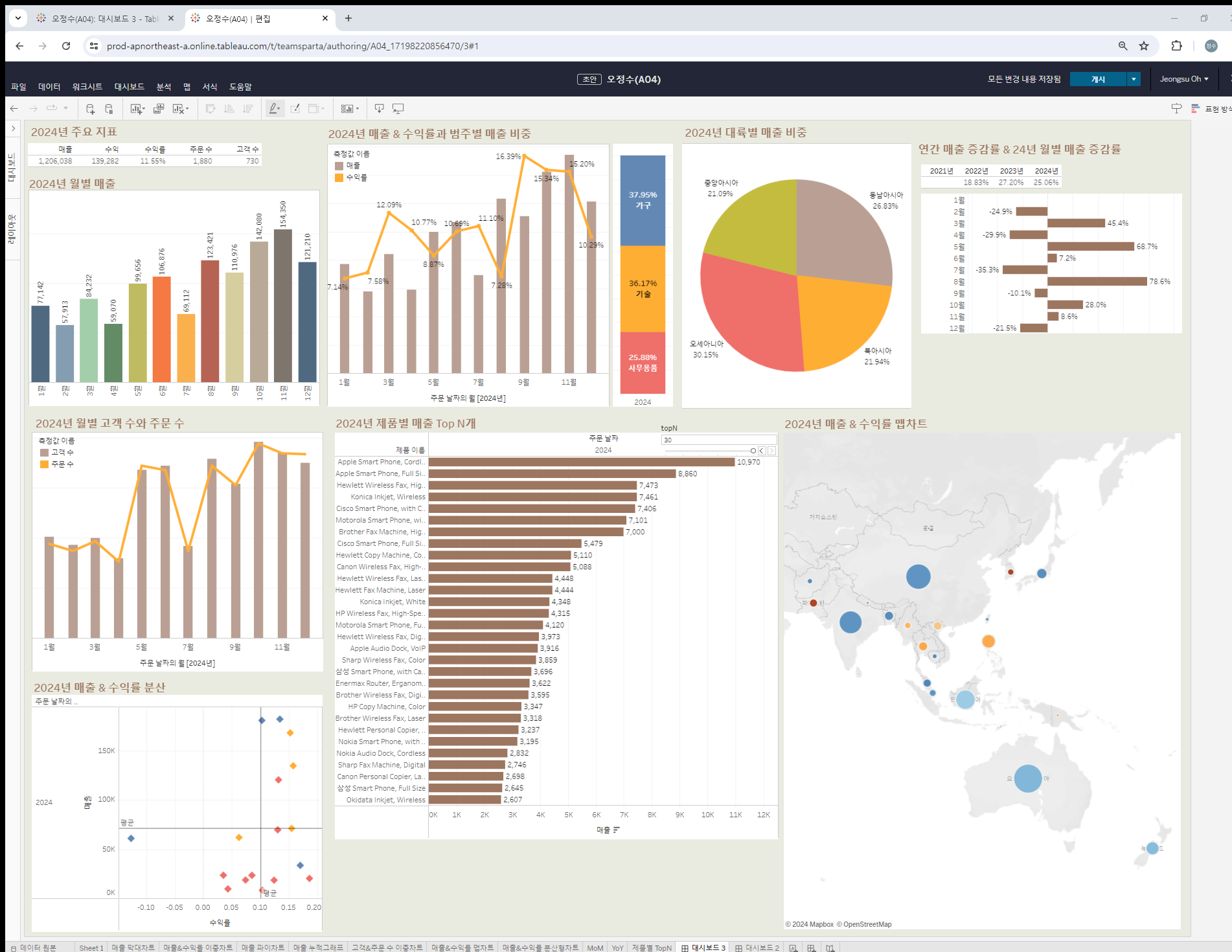
어제 대충 바둑판으로 만들었는데 저녁 스크럼 때 보고 놀랐다.다들 대시보드 꾸미기에 진심인..나는 미적 감각이 없어서 최대한 깔끔하게 하려고 노력했다.더러운 머리글들을 지워버리고 필요한 것만 남겼다.오늘 라이브 세션을 두 번 진행했는데 집에서 해서 그런가 집중이 살짝
22.TIL - 240703
TIL의 목적은 오늘 한 공부를 적는 건데 그냥 일기처럼 쓰고 있네.오늘은 공부한 것이 없다.프로젝트 시작인데 당차게 자유 주제를 하기로 했으나 데이터 찾는 것이 힘들 줄은 몰랐다.원하는 분야가 없으니 데이터 찾는 것도 힘들었던 거 같다.하루 빨리 내가 원하는 분야를
23.TIL - 250107 (실습)
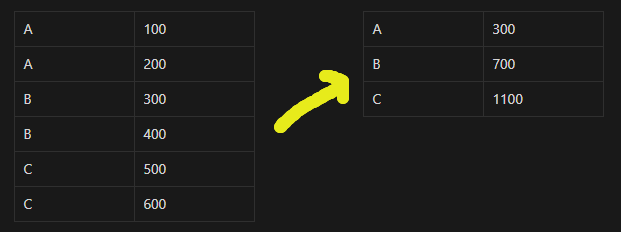
MySQL로 이렇게 쓰면 값을 다음과 같이 얻을 수 있다.하지만 WINDOW 함수를 사용하면 다음과 같이 얻을 수 있다.집계 함수는 주로 GROUP BY와 묶이며 데이터의 그룹별 요약을 제공한다.하지만 WINDOW 함수는 OVER과 묶이며 각 행의 추가적인 정보를 제공
24.TIL - 250108
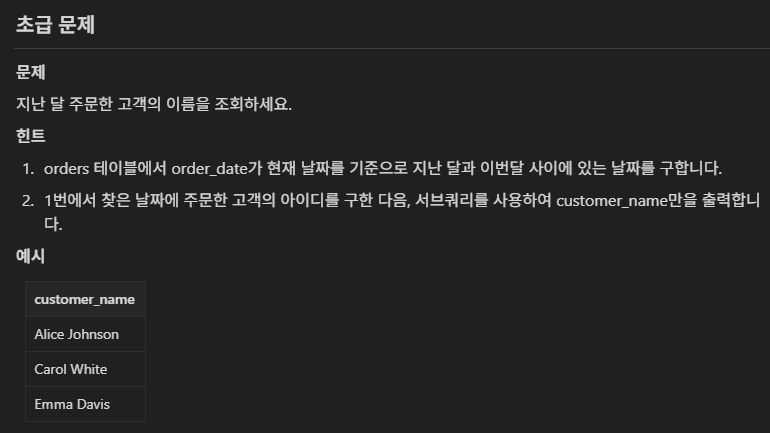
SQL basic 2강 서브쿼리 서브쿼리는 SQL 문장에서 메인 쿼리 내부에 포함된 쿼리이다. 메인 쿼리의 일부로 실행되어 메인 쿼리의 결과를 제한하거나 계산하는 데 사용된다. select, from, where, having안에 사용할 수 있다. 서브쿼리의 종류
25.TIL - 250109
merge, join, concat, append가 대표적이다.대표적인 것만 알아보자.개념 : pandas의 함수 중 하나로, 공통 컬럼을 기준으로 테이블을 병합한다.SQL 구문의 JOIN 함수와 가장 유사하다.on: 조건 컬럼(공통컬럼)이 한개인지 여러개인지how:
26.TIL - 250110
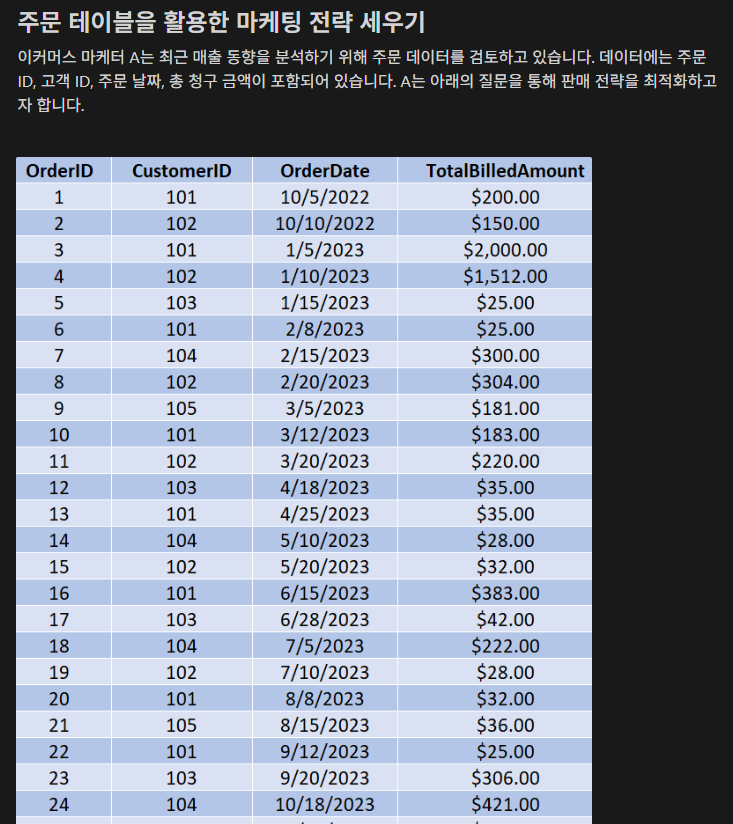
※ 4강은 단순 join에 관한 이야기라서 넘어갔다.5, 6강은 예제를 풀었다.ORDERS 테이블OrderID : 주문 아이디CustomerID: 고객 아이디OrderDate: 주문 일자TotalBilledAmount: 일일 주문 금액설명 : \`\`를 사용하면 함수와
27.TIL - 250111
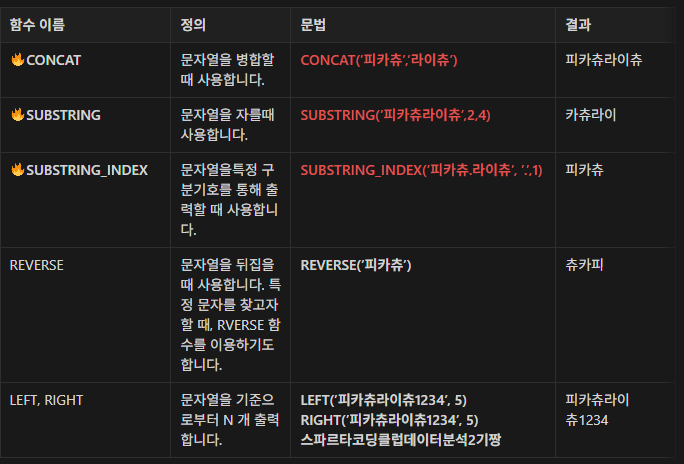
정의 : 행과 행 간의 관계를 정의하기 위해 제공역할 : 순위, 합계, 평균, 행 위치 등 조작 가능특징 : 1\. GROUP BY 구문과 병행하여 사용할 수 없다.2\. 결과 건수가 줄어들지 않는다. (집계 제외)3\. GROUP BY 구문은 둘 다 파티션을 분할한다
28.TIL - 250112
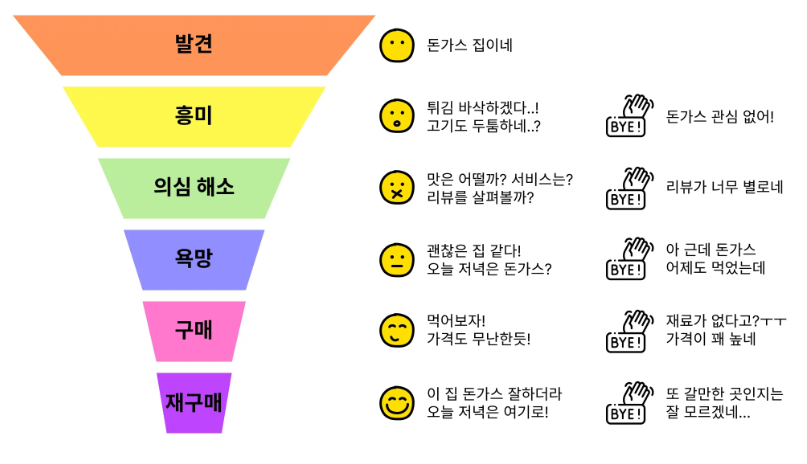
우리가 원하는 것 = 고객이 퍼널을 끝까지 통과하는 것 = 전환 (Conversion)소비자의 행동을 우리가 원하는 지점까지 유도하기 위해 행동을 여러 단계로 나누고, 이를 세그먼트 등으로 비교하여 이탈의 원인을 분석하고 해결하는 데에 주 목적이 있다.따라서 서비스에
29.TIL - 250122
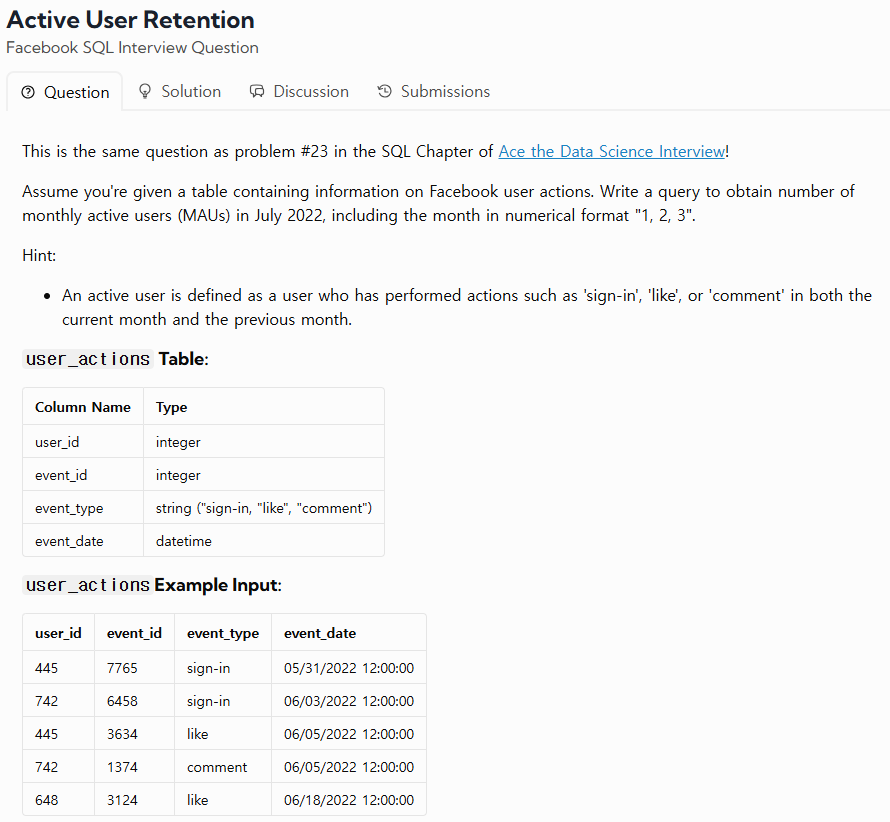
URL : https://datalemur.com/questions/user-retention
30.TIL - 250123
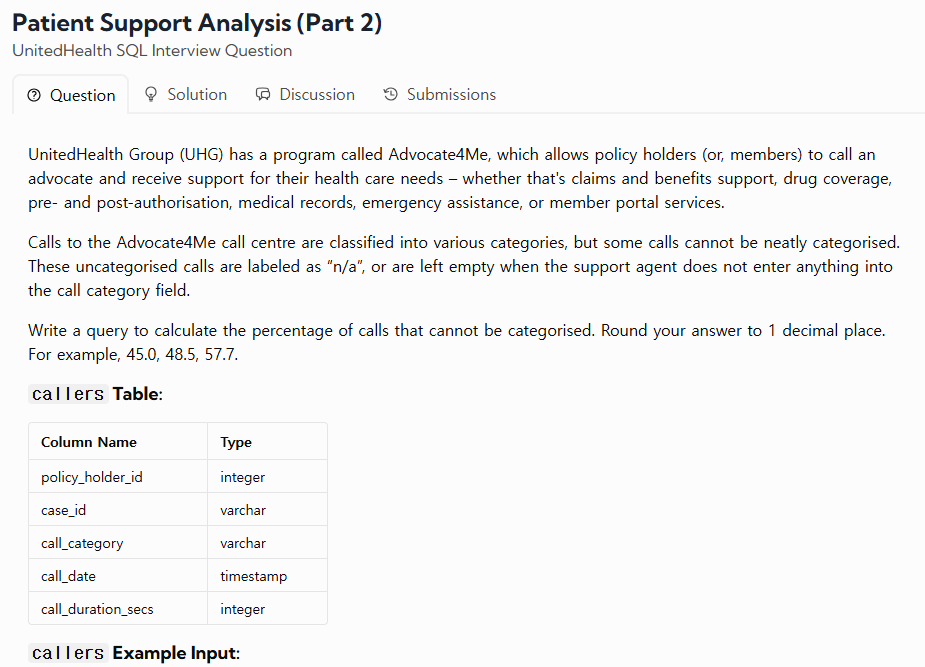
URL : https://datalemur.com/questions/uncategorized-calls-percentage
31.TIL - 250124
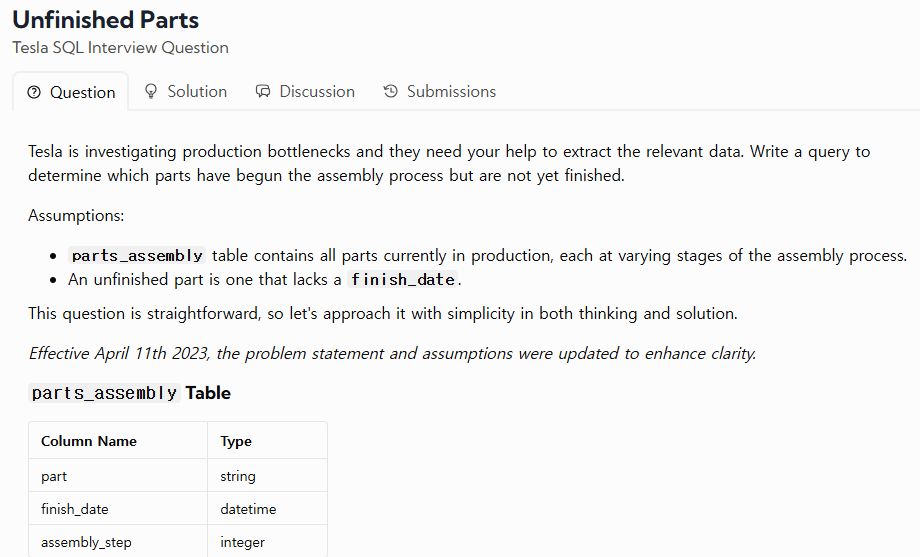
URL : https://datalemur.com/questions/tesla-unfinished-partsURL : https://datalemur.com/questions/sql-page-with-no-likes
32.TIL - 250125
URL : https://datalemur.com/questions/tesla-unfinished-parts
33.TIL - 250126
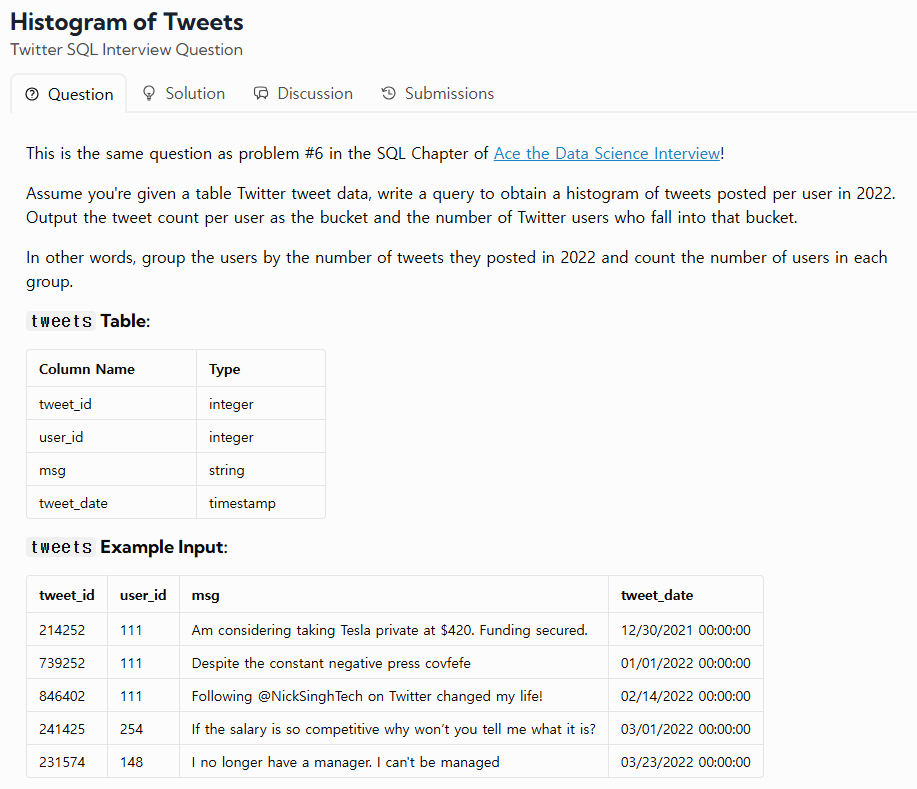
URL : https://datalemur.com/questions/sql-histogram-tweetsURL : https://datalemur.com/questions/matching-skills
34.TIL - 250127
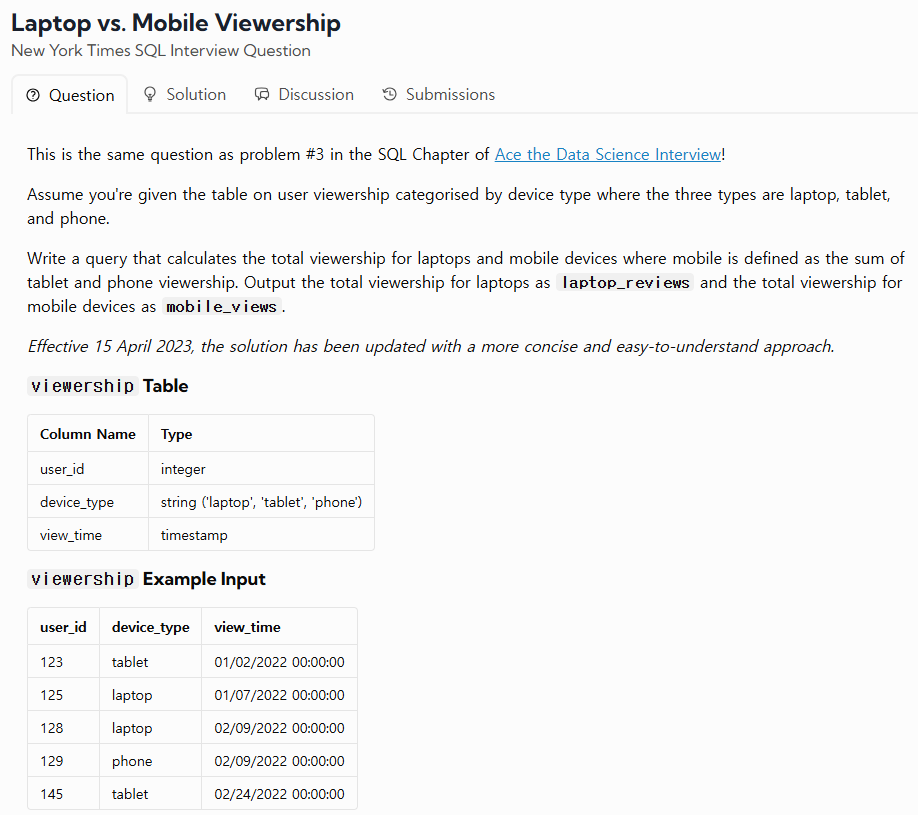
URL : https://datalemur.com/questions/laptop-mobile-viewershipSELECT만 사용할 수 있다.처음 알았다.다른 방법도 있다.
35.TIL - 250128
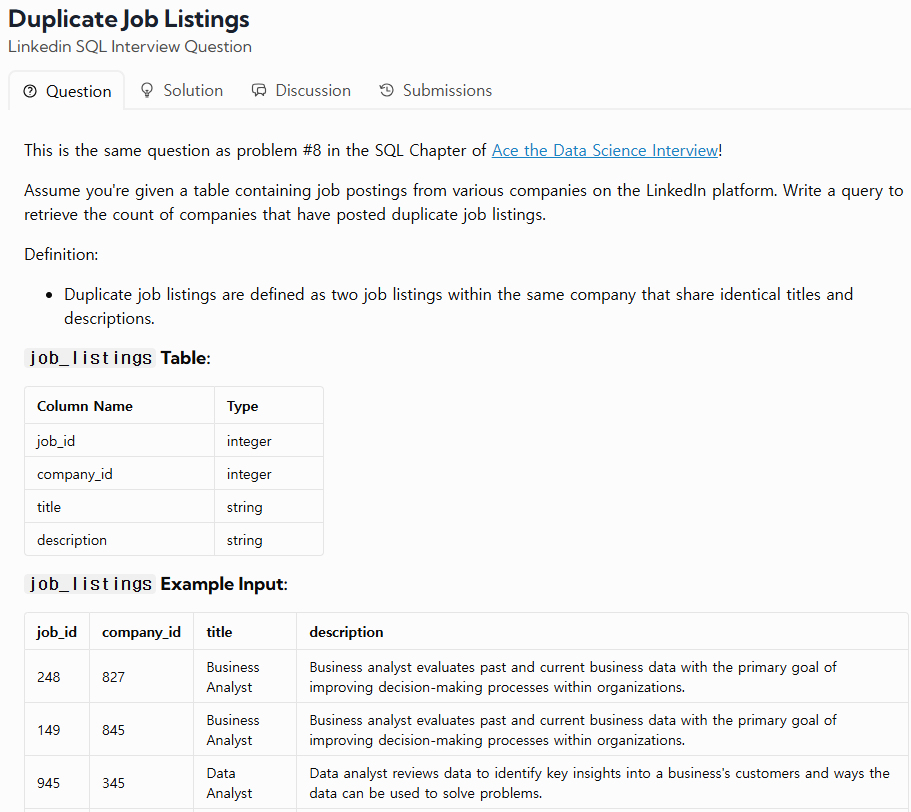
URL : https://datalemur.com/questions/duplicate-job-listings다른 경우로 풀 수도 있다.URL : https://datalemur.com/questions/teams-power-users
36.TIL - 250129
URL : https://datalemur.com/questions/sql-average-post-hiatus-1 URL : https://datalemur.com/questions/completed-trades
37.TIL - 250131
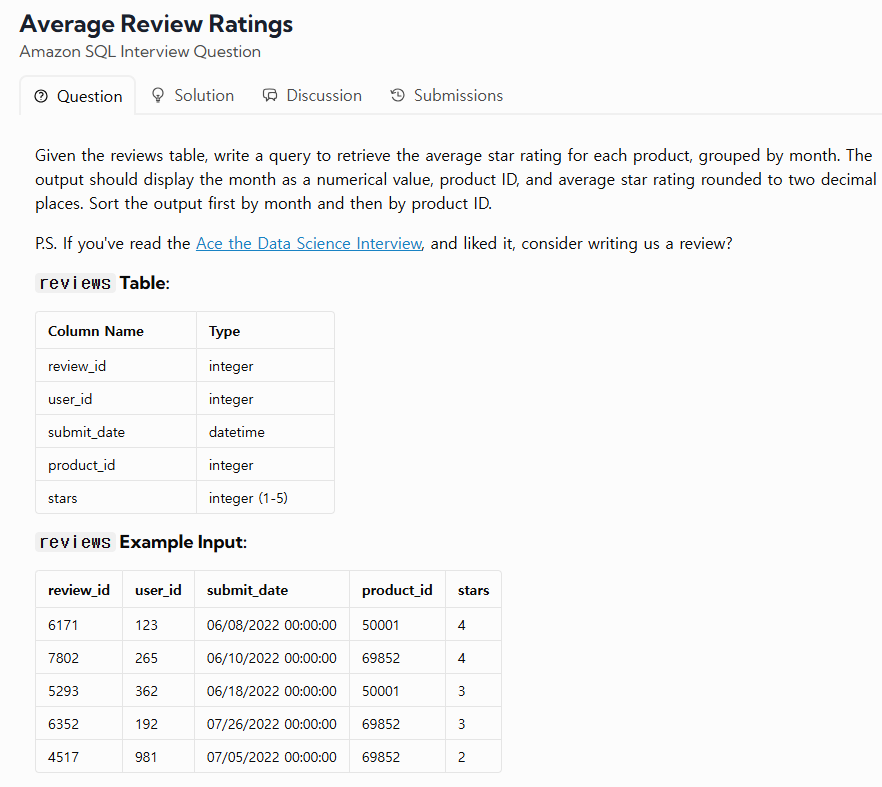
30일 약속으로 못한 만큼 오늘 더 함URL : https://datalemur.com/questions/sql-avg-review-ratingsURL : https://datalemur.com/questions/sql-well-paid-employe
38.TIL - 250202
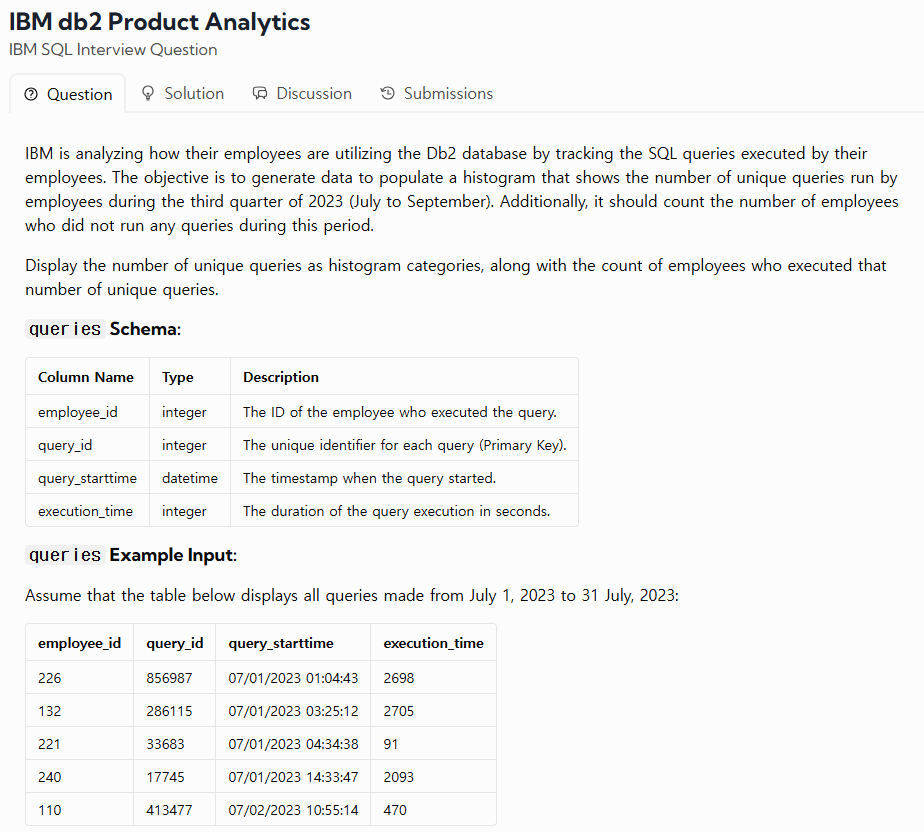
리뷰 : WHERE절에 넣을지 ON절에 넣을지 잘 생각해자.URL : https://datalemur.com/questions/sql-ibm-db2-product-analytics
39.TIL - 250203
오늘 아파서 하나밖에 못 할 거 같다.빨리 낫고 내일 더 하겠다.URL : https://datalemur.com/questions/cards-issued-difference
40.TIL - 250204
리뷰 : ROUND가 무슨 이유에서인지 되지가 않았다. 1.0을 곱해도 에러가 나서 CAST로 DECIMAL 형식으로 바꿨다. DECIMAL에 대해 조금 알게 되었다. DECIMAL(m, d) m은 정수 자리수, d는 소수 자리수를 정하는 것이다. URL : http
41.TIL - 250205
리뷰 : 윈도우 함수를 다시 재검토하는 시간을 가졌다. 추가로 LIMIT와 함께 쓰이는 OFFSET에 대해 알게 되었다. URL : https://datalemur.com/questions/total-drugs-sales URL : https://datalemur.
42.TIL - 250206
리뷰 : 윈도우 함수를 기억하는 하루URL : https://datalemur.com/questions/frequent-callersURL : https://datalemur.com/questions/sql-third-transaction
43.TIL - 250207
리뷰 : case when을 활용하면 유용하다URL : https://datalemur.com/questions/time-spent-snaps
44.TIL - 250208
리뷰 : 행의 범위를 지정할 때 PRECEDING, CURRENT ROW, FOLLOWING을 잘 활용하자. UNBOUNDED는 무한하다는 뜻. 그리고 두번째 문제에서는 상관이 없지만 알아두면 좋은 것 : RANK() => 값이 같으면 같은 순위DENSE_RANK()
45.TIL - 250210
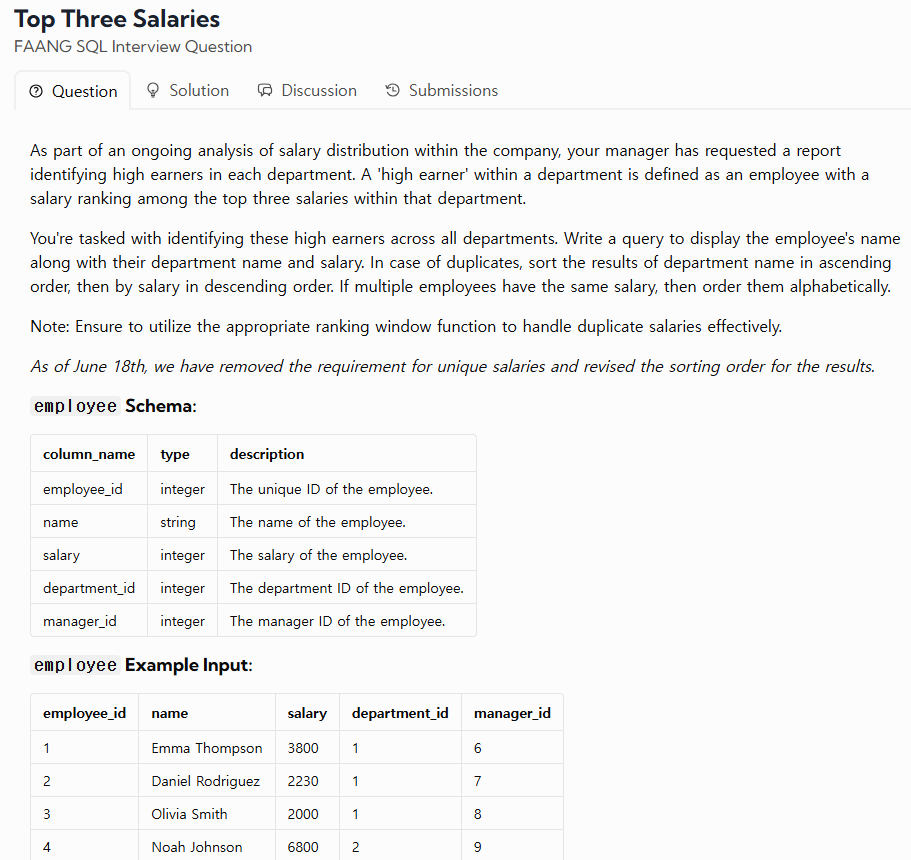
리뷰 : 윈도우 함수 적응 중, 집계함수가 아닌 경우 HAVING에서도 적용되지 않는다.(2번 문제)URL : https://datalemur.com/questions/sql-top-three-salariesURL : https://datalemur.
46.TIL - 250211
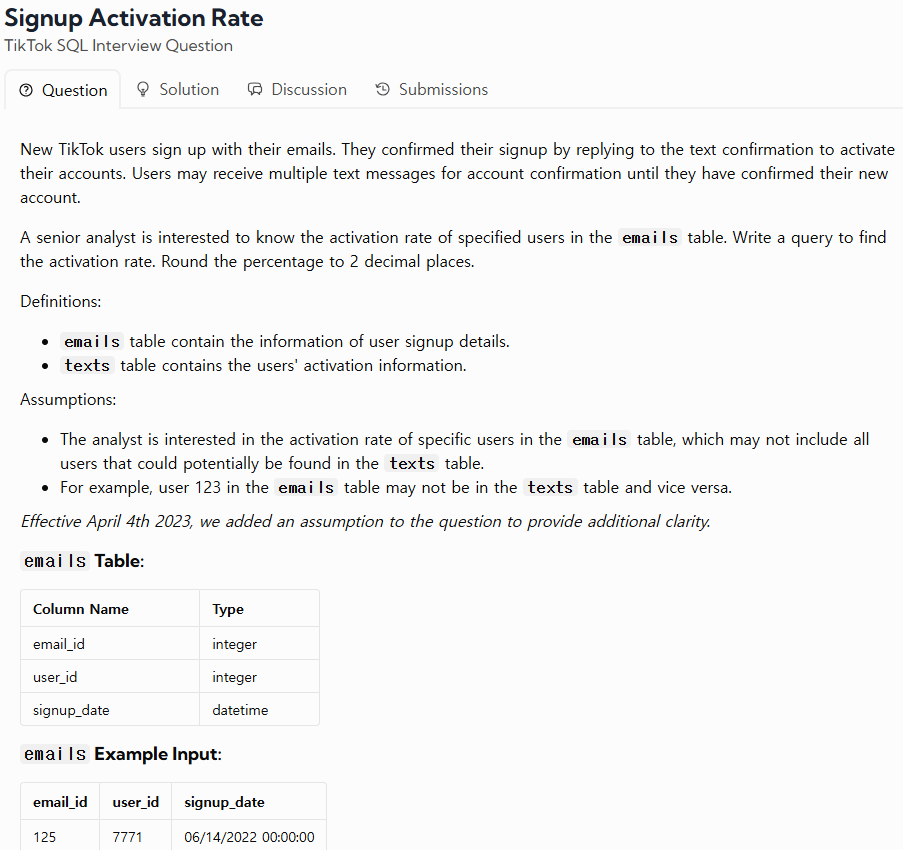
리뷰 : 오늘 datalemar 오류가 있는 거 같다. 정답 확인을 하려고 하면 missing FROM-clause entry for table "emails")라고 하면서 결과가 나오지 않는다. 다른 사람 코드를 보고 정답임을 알았다. 다른 문제는 틀렸는데 감이 안
47.TIL - 250212
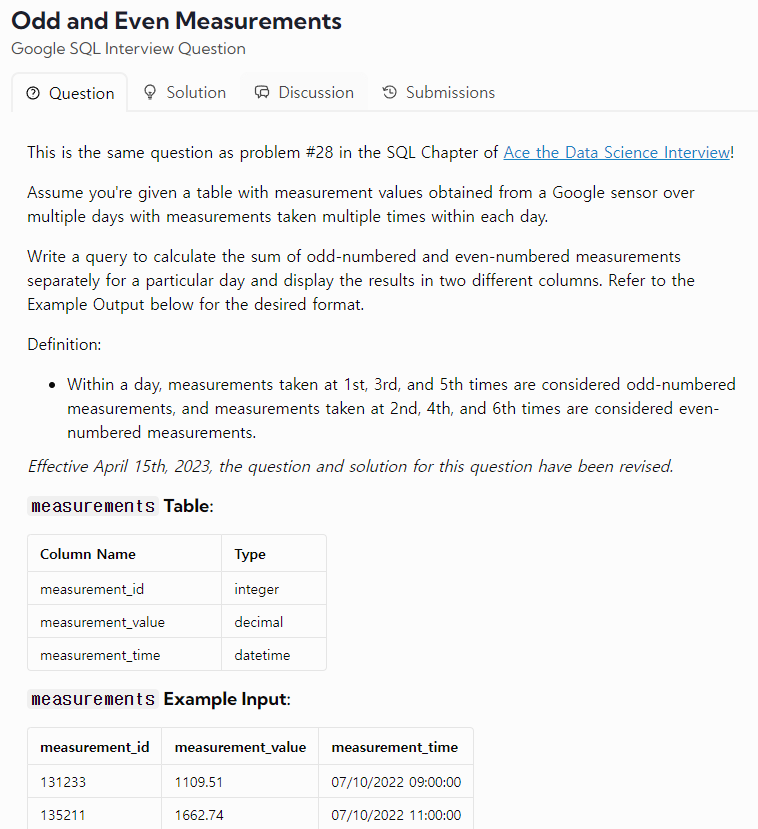
어제 오류들은 datalemur의 문제인 걸로 보인다. 모든 문제가 그런 게 아니라 특정 문제만 그래서 오류가 없는 문제들만 풀어봤다.리뷰 1 : 난이도가 역대급으로 어려웠다. &를 활용하면 짝수 홀수를 구분할 수 있다. &는 비트 연산으로 숫자 & 1의 의미는 이진법
48.TIL - 250213
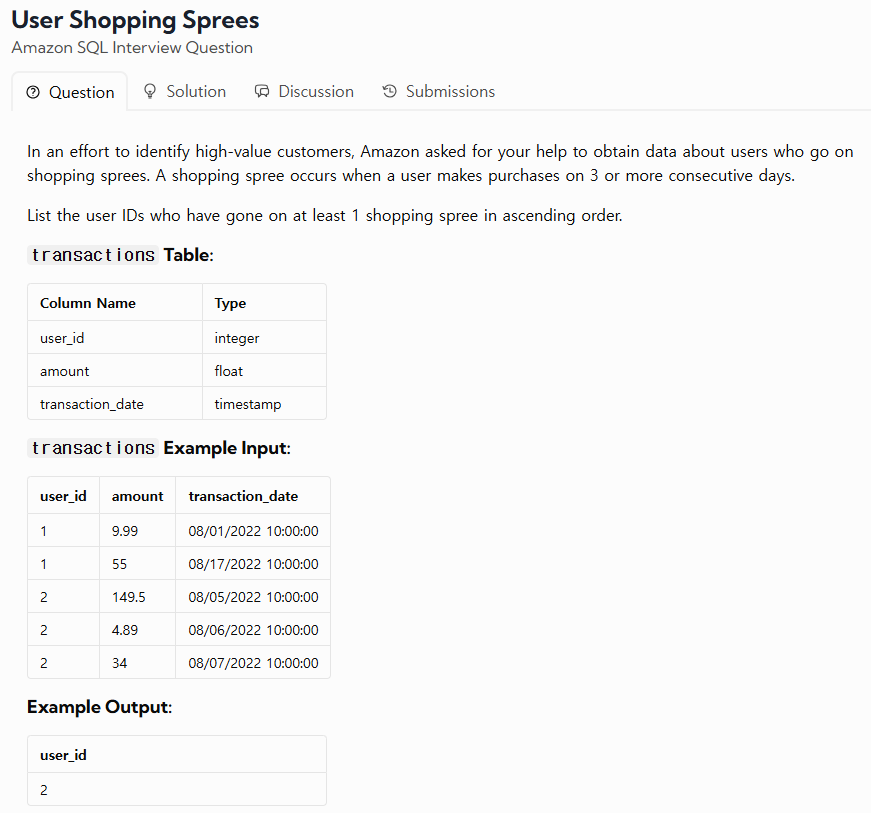
리뷰1 : lag()에 대해 간만에 상기시킨 날이다. lag()는 이전의 값을 반환할 수 있다. 반대로 lead()는 이후의 값을 반환한다.리뷰2 : cte를 활용해서 문제를 풀었는데 다른 사람은 더 쉽게 풀더라. 그래서 그 방식으로 다시 풀어봤다. 생각을 조금 더 하
49.TIL - 250214
요즘 과제를 열심히 하고 있다.1개월 단기 인턴을 신청해서 1차 합격이 되어 2차 합격으로 가기 위해 과제를 하고 있다.코드만 간단하게 소개하겠다.이건 기간 내에 있던 유저가 1번 이상 한 인원이기에 DISTINCT로 중복 제거를 했다.요거는 두 가지의 방법으로 했었는
50.TIL - 250216
15일과 16일은 과제를 하느라 패턴이 살짝 꼬였다.리뷰하기 힘드니까 제출한 노션을 공유하겠다.과제를 MySQL로 한 번, Python으로 한 번 풀었다.다 풀고 다른 과제들도 제출하니 뿌듯했다.오늘부터 다시 생활패턴을 고쳐야지.URL : https://www
51.TIL - 250218
https://www.youtube.com/watch?v=gmMaH5mMJ9M&list=PLNsNSwihNQrfFimQexetKXjLEthvNw8uq&index=2https://www.youtube.com/watch?v=mKCQLJCwZ_8&list=
52.TIL - 250219
리뷰 : 오랜만에 SQL 실습을 한 거 같다. 재밌다. 첫번째 코드엔 1.0을 곱해야 값이 제대로 나온다. 이유는 잘 모른다..리뷰 2 : 두번쨰는 문제를 잘못 이해해서 골머리가 아팠다. 결국 해결했다. product_category 종류를 모두 산 사람을 고르는 문제
53.TIL - 250220
리뷰 : 코드가 꽤나 길어서 다른 사람들의 코드를 봤는데 엄청 짧다. JOIN을 두 번 할 수도 있다는 걸 알게 되었다. 그래서 나도 JOIN을 두 번 넣어서 코드를 다시 짰다. 그랬더니 훨씬 짧게 간단하게 나왔다.리뷰 2 : EXTRACT를 사용해서 날짜만 뺄 수 있
54.TIL - 250221

와 여태 난이도가 쉬움이랑 중간이었는데 어제부터 "Hard"로 들어왔다. 어젠 Hard도 별게 없네. 쉽다~ 이러면서 했는데 오늘 하는데 죽을 거 같다. 문제도 제대로 이해가 안 되고 어렵다. 근데 붙잡고 풀었을 때 희열감은 이루 말할 수 없다.리뷰 1 : 이걸 문제부
55.TIL - 250222
리뷰 : 간단하게 각 상태별 변화를 CASE WHEN을 통해서 변경해주면 된다. 단, 여기서 중요한 것은 FULL OUTER JOIN으로 테이블을 병합해야 한다는 것. 오늘 처음 OUTER JOIN을 썼다. RIGHT OUTER JOIN, LEFT OUTER JOIN,
56.TIL - 250410_(SQL_datalemur_7개)
SQL을 요즘 안 다뤄서 감을 잡기 위해 이전에 풀었던 SQL을 빠르게 복습할 것이다. 문제 1 (링크) 코드 비고 : GROUP BY에 대해 까먹었다. 다시 알게 되어 기쁘다. 문제2 (링크) 비고 : 위에 코드로 짰는데 이전에 짠 코드가 훨씬 잘 된 거 같
57.TIL - 250411_(SQL_datalemur_7개)
비고 : 위에 코드처럼 짰는데 아래 코드로도 짤 수 있는 걸 알게 되었다. 간단하게 작성하는 것이 좋은 거 같다.비고 : JOIN 절에 ON에 여러 조건을 넣을 수 있다.비고 : 100으로 곱하면 정수 \* 정수 형태이기 때문에 실수를 계산하지 않는다. 소수점을 원하
58.TIL - 250412_(SQL_datalemur_7개)
문제1 (링크) 문제2 (링크) 문제3 (링크) 문제4 (링크) 문제5 (링크) 문제6 (링크) 문제7 (링크)
59.TIL - 250413_(SQL_datalemur_7개)
문제1 (링크)
60.TIL - 250415_(SQL_datalemur_7개)
문제1 (링크) 문제2 (링크) 문제3 (링크) 문제4 (링크) 문제5 (링크) 문제6 (링크) 문제7 ([링크](https://datalemur.com/questions/car
61.TIL - 250416_(SQL_datalemur_4개)
문제1 (링크) 문제2 (링크) 문제3 (링크) 문제4 (링크) 비고 : LAG와 윈도우 함수를 사용하여 쉽게 전년도 데이터를 뽑을 수 있다.
62.TIL - 250417_(SQL_datalemur_2개)
#### 문제1 ([링크](https://datalemur.com/questions/sql-ibm-db2-product-analytics)) ``` WITH a AS ( SELECT * FROM queries WHERE EXTRACT(YEAR FROM quer
63.TIL - 250418_(SQL_datalemur_1개)
#### 문제1 ([링크](https://datalemur.com/questions/median-search-freq)) ``` WITH a AS ( SELECT * , SUM(num_users) OVER (ORDER BY searches) n_su
64.TIL - 250429_(SQL_datalemur_2개)
#### 문제1 ([링크](https://datalemur.com/questions/updated-status)) ``` WITH a AS ( SELECT * FROM advertiser LEFT JOIN daily_pay USING (user_id)
65.TIL - 250430_(SQL_datalemur_2개)
비고 : 마지막 조건에 나는 EXTRACT(MINUTE FROM ~)를 사용했었다. 정답이 아니어서 고민을 하다 깨달았다. 나처럼 코드를 쓰면 65분 차이도 5분으로 추출하여 오류가 발생한다는 것..!65분은 1시간 5분인데 분만 추출하니 5만 나오는 것이다. 그래서
66.TIL - 250502_(SQL_datalemur_1개)
비고 : 콜론 두 개(::)를 사용하면 CAST와 같은 기능을 한다. 하지만 PostgreSQL에서만 가능하다. MySQL에서는 불가능.
67.TIL - 250512(SQL_leetcode_3개)
비고 : 나는 JOIN을 할 때 컬럼명이 같다는 전제하에 USING을 사용하는데 leetcode에서 runtime을 알려줘서 조금 더 최적화를 하기 좋은 코드를 찾기 좋은 거 같다. USING보다 ON이 더 runtime을 줄일 수 있다. 비고 : 첫번째 쿼리로 문제를
68.TIL - 250513(SQL_leetcode_3개)
비고 : 함수명이랑 같은 컬럼명을 쓰고 싶으면 '\`'를 잘 활용하자.\`비고 : LAG()는 이전 값, LEAD()는 이후 값. 헷갈릴 수 있으니 잘 기억하자.비고 : 코드1은 윈도우 함수를 이용해서 한 건데 너무 복잡했다. 코드2처럼 간단하게 할 수 있는 건 간단하
69.TIL - 250515(SQL_leetcode_3개)
비고 : 코드 2로도 할 수 있다. 조금 더 최적화된 코드인 거 같다.비고 : 서브쿼리보다 cte가 더 효율적인 거 같다.비고 : 예전에 정리한 쿼리 구조로 보기 편해진 거 같아 기분이 좋다.
70.TIL - 250516(SQL_leetcode_2개)
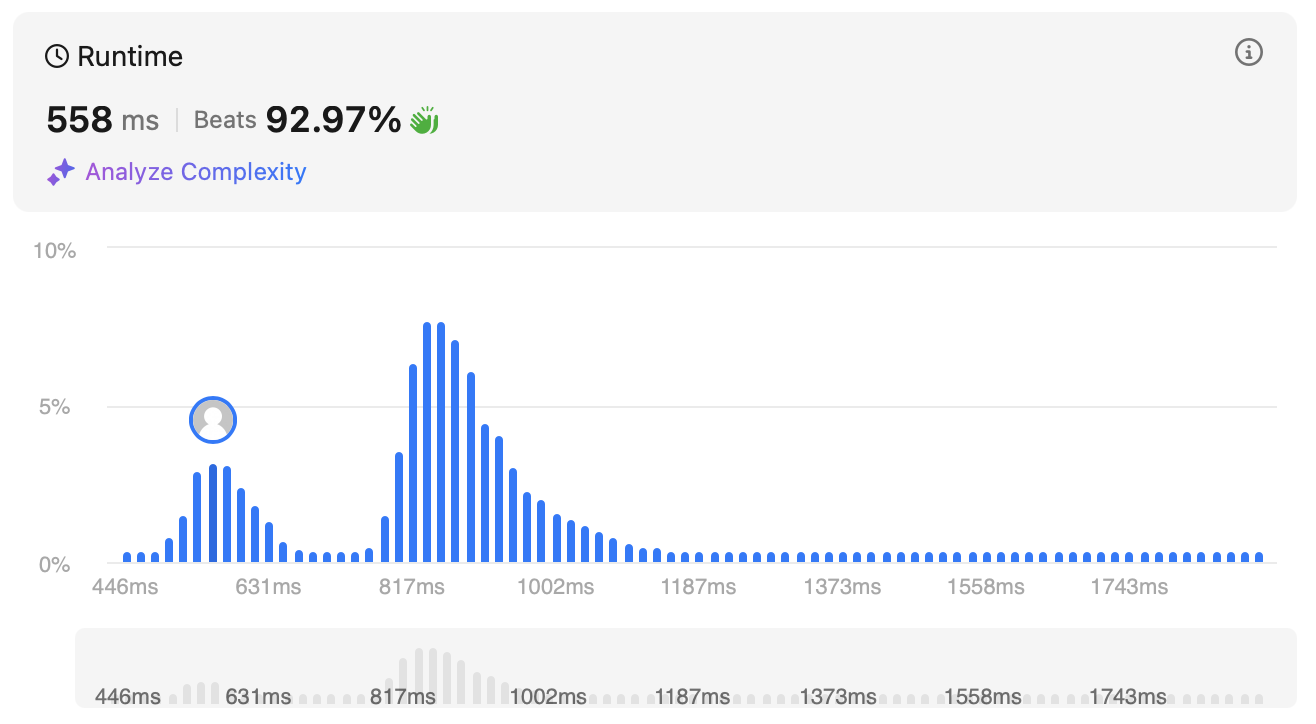
비고 : 원래 정규분포처럼 하나의 봉우리로 되어 있는데 이번에 처음으로 두 봉우리를 봐서 눌렀는데 복잡한 코드가 더 최적화된 코드인 걸 보고 이질감이 느껴졌다. 알아보니 join의 경우 복잡도가 행이 많아질수록 높아진다. 아래 코드처럼 짜야 확장성이 좋다고 한다.비고
71.TIL - 250517(SQL_leetcode_3개)

문제1(링크) 문제2(링크) 문제3(링크)
72.TIL - 250523(SQL_leetcode_3개)
비고 : 나름 코드가 길어서 쿼리 처리 속도가 느릴 줄 알았는데 빨라서 기분이 좋았다.처음엔 좌표를 각각 중복을 체크했다. 그러면 오류가 있더라. 그래서 좌표를 합쳤다. 데이터 예시만 보고 좌표가 소수점이 아닌 점을 바탕으로 CONCAT()을 하고 위에 CAST(00
73.TIL - 250524(leetcode_3개)
비고 : 코드 1처럼 풀면 간단하게 해결이 되지만 확장성이 부족하고 동률일 경우 처리가 불가능하기에 코드 2를 짰다.
74.TIL - 250608(leetcode_1개)
비고 : LEAD() 함수와 LAG() 함수를 사용해서 이전 데이터들을 추출한 후 100보다 큰 3회 이상을 추출하는 것을 만들었다. 두번째 코드가 더 좋은 이유는 그루핑을 만든 것이다. HAVING절만 수정하면 조건에 쉽게 변동을 줄 수 있고 id - ROW_NUMB
75.TIL - 250609(leetcode_1개)
문제 1(링크)
76.TIL - 250610(leetcode_1개)
비고 : NOT IN이 가능할 줄 몰랐는데 썼는데 됐다. 알아두자.
77.TIL - 250611(leetcode_2개)
비고 : 삼각형의 특징 중 하나인 두 변의 길이의 합은 나머지 한 변의 길이보다 크다이다. 까먹었다가 감으로 풀었다. 기억하자.
78.TIL - 250617(leetcode_1개)
비고 : 코드 1처럼 cte를 썼는데 그렇게 하지 않아도 되는 것을 깨달았다.