문제1(링크)
# 코드 1
DELETE a
FROM Person a
JOIN Person b
ON a.id > b.id
AND a.email = b.email
# 코드 2
WITH a AS(
SELECT
id
, ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) r_num
FROM Person
)
DELETE FROM Person
WHERE id IN (SELECT
id
FROM a
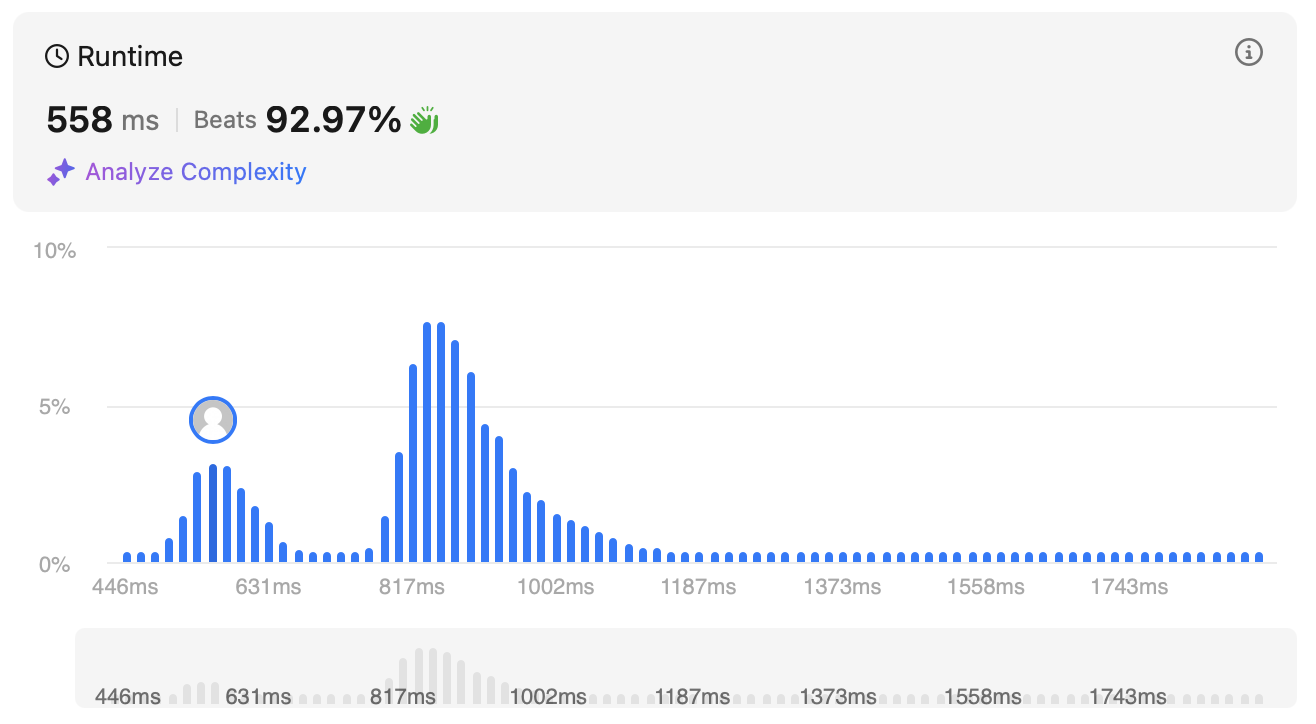
WHERE r_num > 1)비고 : 원래 정규분포처럼 하나의 봉우리로 되어 있는데 이번에 처음으로 두 봉우리를 봐서 눌렀는데 복잡한 코드가 더 최적화된 코드인 걸 보고 이질감이 느껴졌다. 알아보니 join의 경우 복잡도가 행이 많아질수록 높아진다. 아래 코드처럼 짜야 확장성이 좋다고 한다.
문제2(링크)
WITH a AS(
SELECT
*
, LAG(temperature) OVER (ORDER BY recordDate) y_tem
, LAG(recordDate) OVER (ORDER BY recordDate) y_date
FROM Weather
)
SELECT
id
FROM a
WHERE y_tem < temperature
AND DATEDIFF(recordDate,y_date) = 1비고 : 문제를 잘 읽자. 문제에 어제라는 걸 못봐서 y_date를 뒤늦게 작성했다.

안녕하세요 오정수입니다