python 의 request 라이브러리 사용법
직관적이다. node.js 의 express 랑 비슷한 것 같았다.
파이썬을 처음 사용해봤지만 방식이 비슷해서 쉽게 익숙해졌다.
# ! pip install requests
import requests
r = requests.get('url')
# 해당 url 로 get 요청. 그 후 r에 할당
## get, post, put, delete 방식으로 HTTP 요청
## r.response.statue_code 명령어로 응답상태 확인가능
res = r.json()
# get 한 데이터가 json 포멧이라면 dictionary 객체 생성웹 크롤링 기초
파이썬을 처음 다뤄봤지만 문법은 자바스크립트보다 직관적이라서 쉽게 코딩할 수 있었다.
웹 크롤링을 하기 위해서는 일련의 과정이 필요한데,
- requests 라이브러리로 html 요청
- html 내부의 값을 지정 후 가져오기
- beautifulSoup 라이브러리 사용
BS4 관련 명령어 및 설명
HTML 의 해석 트리를 좀 더 쉽게 검색, 변경하기 위한 라이브러리 라고 한다.
!pip install beautifulSoup4
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# 자동으로 크롤링 하는 컴퓨터(프로그램)가 요청 -> 유저(사람)가 요청
data = requests.get('url',headers=headers).text
soup = BeautifulSoup(data, 'html.parser')
# data를 파싱 용이한 상태로 바꿔준다.예를들어,
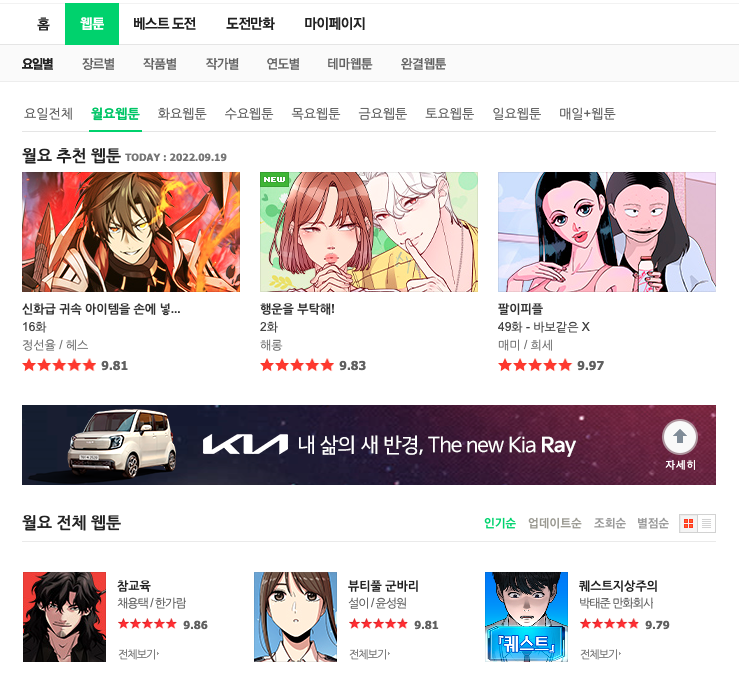
[’월요일 웹툰’] 의 [’참교육’] 이라는 웹툰의 제목을 찾고싶다면
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://comic.naver.com/webtoon/weekdayList?week=mon',headers=headers)
# url 에 월요일 웹툰
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('#content > div.list_area.daily_img > ul > li:nth-child(1) > dl > dt > a')
# ['참교육'] 의 위치를 select_one 으로 찾아 'title' 변수에 저장 (Copy Selector)
# select 명령어로 여러개의 값을 찾아오는 것도 가능하다.
# 이때의 값은 list 형태로 저장되므로, 반복문으로 가공하면 된다.
# 해당되는 요소의 값은,
# <a href="/webtoon/list?titleId=758037&weekday=mon" title="참교육">참교육</a>
print(title['title'])
# title 항목을 가져온다.
print(title['href'])
# href 항목을 가져온다.구글링 한 결과에 find 명령어도 많이 나와있어서
사용해봤는데 직접 사용했을때에는 차이점이 명확하게 느껴지지 않았다.
그래서 찾아봤다.
BeautifulSoup 모듈 find와 select의 차이점 - 복잡한 웹을 간단하게
요점은,
find - 원하는 태그(이름, 속성, 속성값) 찾기
select - CSS selector 로 태그 찾기
어떤 태그를 찾는다는 목적은 같지만 방식이 다르다.
select가 자바스크립트의 querySelector 와 비슷한 개념인 것 같다.
더 다양한 조건과 직관적인 방법으로 태그를 찾을 수 있으며
수행시간도 빠르고 메모리 소모량도 적다고 한다.
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}이 부분에 대한 추가설명
왜 컴퓨터의 요청을 유저의 요청으로 바꿔주어야 할까 ? 궁금했다.
크롤링) 접속 차단되었을때 User-Agent지정(header)
요점은
마치 게임사에서 게임가드 등으로 자동사냥 봇, 핵 등을 차단하듯,
웹페이지에 위험을 초래할 수 있는 기계적인 요청 혹은 비정상적인 움직임 의 경우
최소한의 보호를 위해 차단한다. 라는 의미이다.
크롤링을 할 때 자주 발생하는 문제라고 한다.
크롤링을 할 때 자주 발생하는 문제가 하나 더 있는데,
BS4 만으로 모든 정보를 크롤링 할 수 없다.
예를들어,
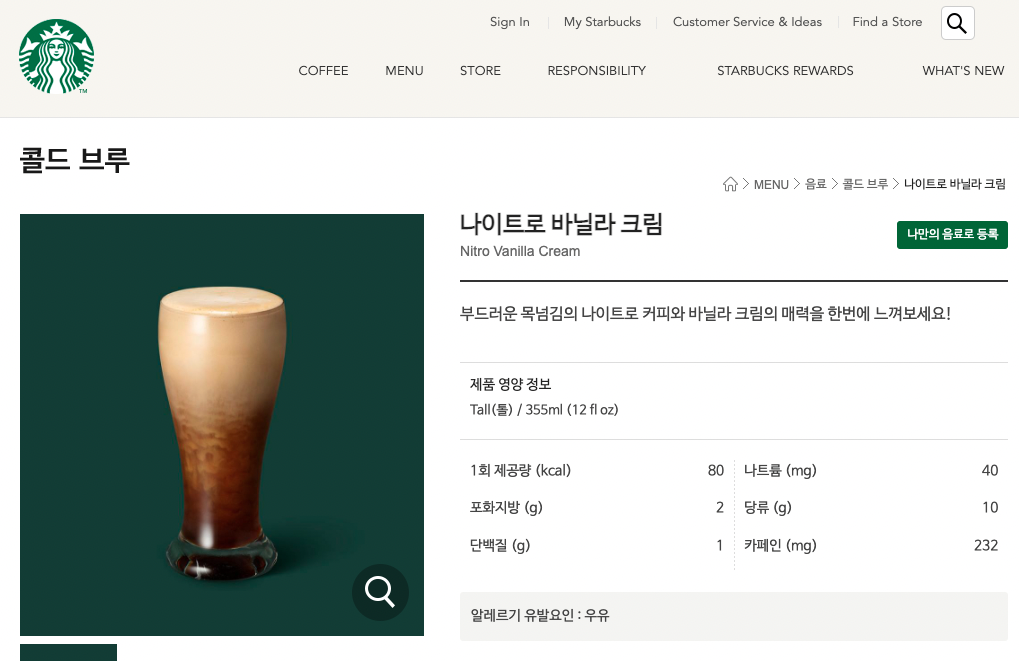
나이트로 바닐라 크림을 크롤링 하기 위해 Copy Selector 로
#container > div.content02 > div.product_view_wrap1 > div.product_view_detail > div.myAssignZone > h4값을 가져온 후, BS4 로 크롤링 한 결과
starbucks = requests.get('https://www.starbucks.co.kr/menu/drink_view.do?product_cd=9200000002487',headers=headers)
coffee = BeautifulSoup(starbucks.text, 'html.parser')
coldbrew = coffee.select_one('#container > div.content02 > div.product_view_wrap1 > div.product_view_detail > div.myAssignZone > h4')
print(coldbrew)
print(coldbrew.text)
# 종료 코드 0(으)로 완료된 프로세스값이 제대로 나오지 않는다.
왜 그럴까 ?
Python 웹 크롤링 시작하기: 스타벅스 메뉴 정보 크롤링
초기 html 에 작성된 데이터가 아닌, 자바스크립트로 동적으로 생성되는 내용은
BS4 만으로 해당내용을 크롤링 할 수 없다.
Selenium 라이브러리를 사용해 자바스크립트가 실행된 이후의 페이지를 가져와야 크롤링이 가능하다.
요즘은 거의 대부분의 코드가 자바스크립트를 이용해 동적으로 생성되니까,
이런 방법을 익히는게 중요할 것 같다.
Database 연동
데이터베이스는 왜 사용하는가 ?
→ 다수의 사용자가 사용하는 데이터들의 공유와 운영을 위해서
그럼 저장공간에 데이터 마구마구 쑤셔넣으면 되는데 왜 굳이 형식을 따라서 만들까 ?
→ 저장된 데이터를 식별하고 선별하여 검색 및 유지보수에 용이
여러가지 dbms가 있지만 그중 mongoDB 를 사용한다.
NoSql(관계형 데이터베이스 뿐만 아니라 다른 데이터베이스도 사용)로써
테이블같은 스키마가 고정된 구조 대신 JSON 형태의 스키마형 문서를 사용함.
데이터 일관성이 거의 없어서 속도가 굉장히 빠르지만,
일관성이 매우 중요한 작업에는 쓰기 힘들다고 한다.
mongoDB를 파이썬에서 사용하기 위해서는
pymongo, dnspython 이라는 라이브러리가 필요하다.
기본적인 사용방법
from pymongo import MongoClient
client = MongoClient('mongodb+srv://${설정한 유저네임}:${설정한 패스워드}@cluster0.2gpcrki.mongodb.net/?retryWrites=true&w=majority')
db = client.${데이터베이스 Collections의 이름}
doc = {
${db에 저장할 자료}
}
# 저장 - 예시
# 예시의 users 가 해당 collections의 카테고리 이름이 된다.
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
# 찾는 조건을 다양하게 설정해줄 수 있다.
# _id 값은 mongoDB 가 자체적으로 생성하는 고유ID 이므로 대부분의 경우 필요가 없다.
user = db.users.find_one({'name':'bobby'})
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})예를들어,
커피의 이미지url, 이름, 카페인함량을 cafe collections 에 coffee 라는 카테고리로 저장하고 싶다면
db = client.cafe
data = {
'coffee':'icdamericano',
'url':'#',
'caffeine':'100'
}
db.coffee.insert_one(data)이런식으로 코딩하면,
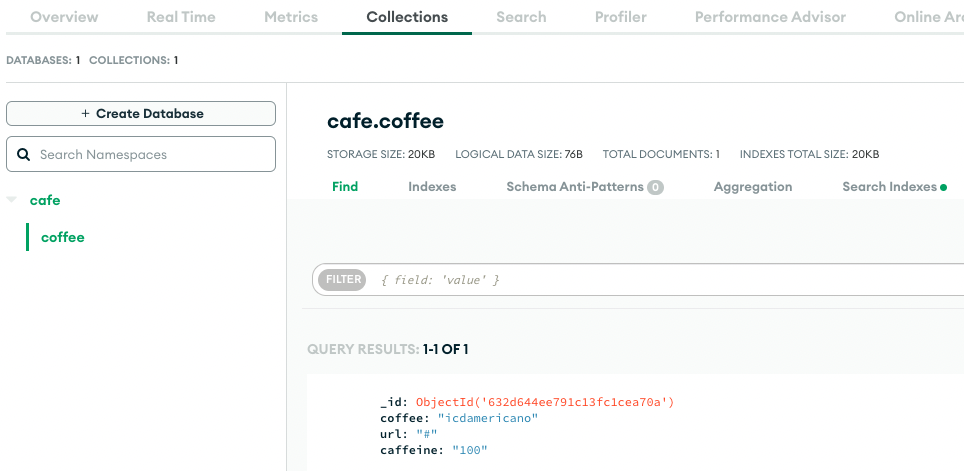
이렇게 DB에 저장된다.
저장된 목록을 보고싶다면,
menu = list(db.coffee.find({}))
print(menu)
//
[{'_id': ObjectId('632d644ee791c13fc1cea70a'), 'coffee': 'icdamericano', 'url': '#', 'caffeine': '100'}]
종료 코드 0(으)로 완료된 프로세스
# update 명령어로 수정도 해줄 수 있는데,
db.coffee.update_one({'coffee':'icdamericano'},{'$set':{'coffee':'ice_americano'}})이런식으로 오타도 수정해줄 수 있다.

오타가 잘 수정된 모습
총평
개인적으로 강의를 들을 때 설명함에 있어서
어떠한 부분은 어떤 파라미터 값을 가지고~ 하는 식의 동작원리를 설명해주는 강의를 좋아한다.
이 코드를 복사 & 붙혀넣기 하면, 혹은 이건 이렇게 하면 됩니다~ 하는 식의 강의는
별로 좋아하지 않는다.
짧은 강의에서 보다 깊은 내용을 담기는 어렵지만
원리에 대한 적절한 설명 없이 복사해서 붙혀넣기만 하는 코딩은 오히려 더 어렵다.
성격상, 잘 모르는데 그냥 하라는대로 하는 식의 일처리는 좀 많이 어렵다.
코딩이라는게 비록, 모든 명령어를 다 외우고 모든 기능을 전부 외우고 하는게 아니겠지만..
아니면 내가 이해를 잘 못하는걸지도 모르겠다.
