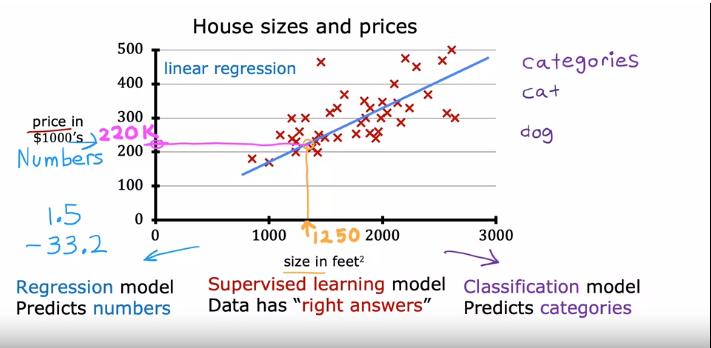
Linear regression is one example of a regression model.
- Regression model : Predicts numbers
- Classification model : Predicts discrete categories or classes
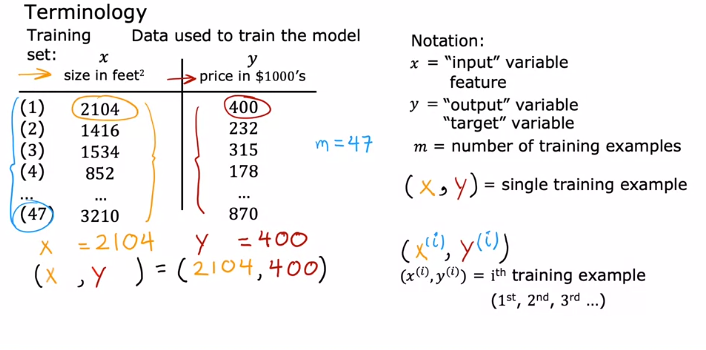
x = "input" variable
y = "output" variable
m = number of training examples
(x,y) = single training example
(x^i,y^i) = ith training example
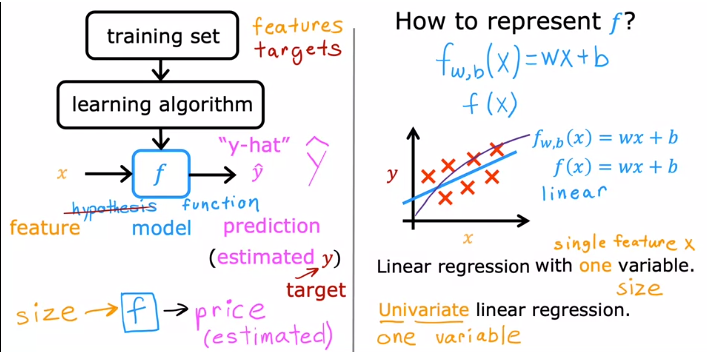
Training set: The dataset used to train the model, where each row represents a training example with input features 'x' and corresponding output 'y'.
To train the model, we feed the training set, which includes both input features and output targets, to the learning algorithm. The supervised learning algorithm generates a function. Historically, this function used to be called a hypothesis.
In machine learning, 'y-hat' conventionally represents the estimated or predicted value of 'y'.
'f_w, b(x) = wx + b', where 'w' and 'b' are numbers whose values will determine the prediction 'y-hat' based on the input feature 'x'.
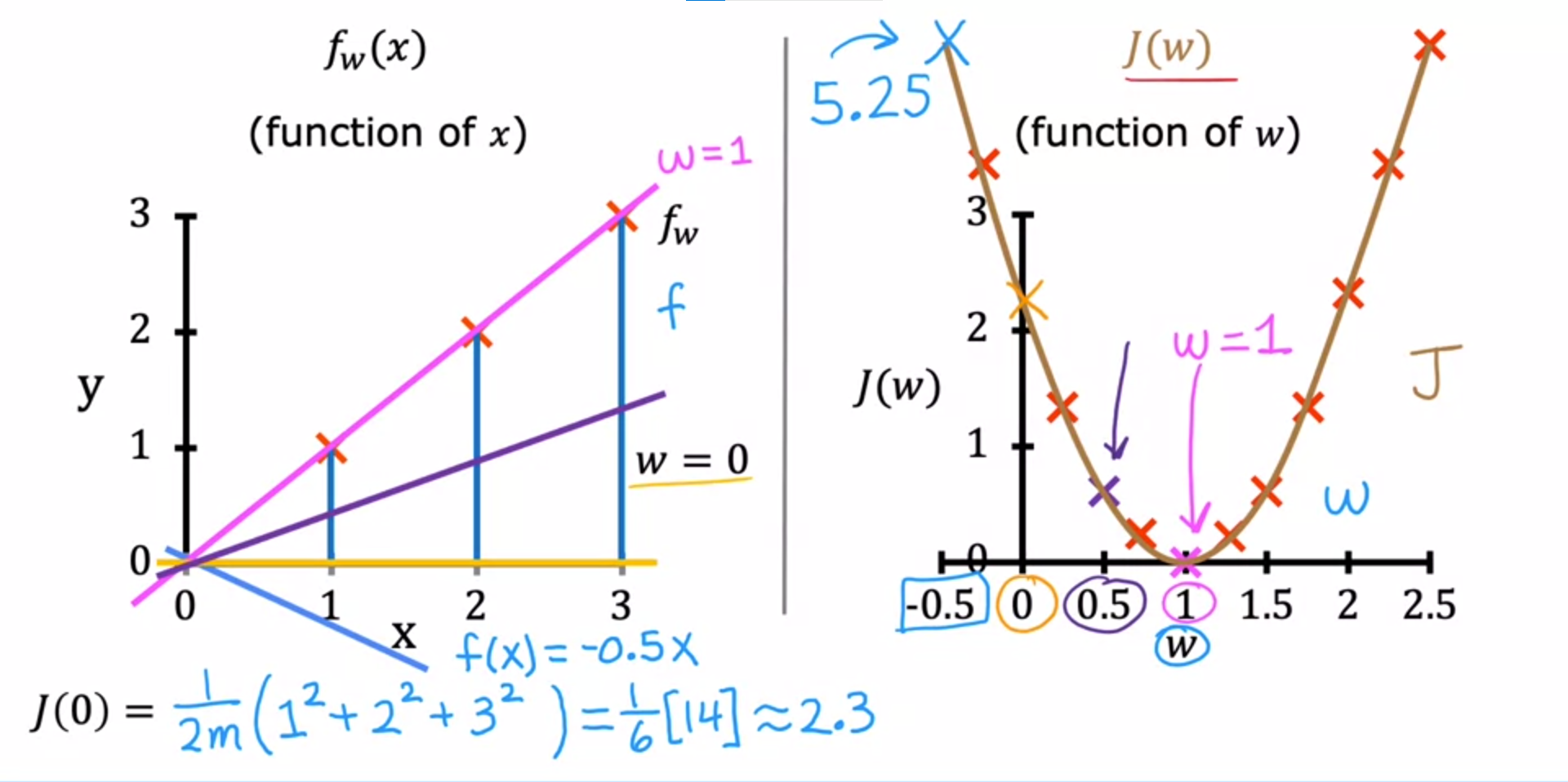
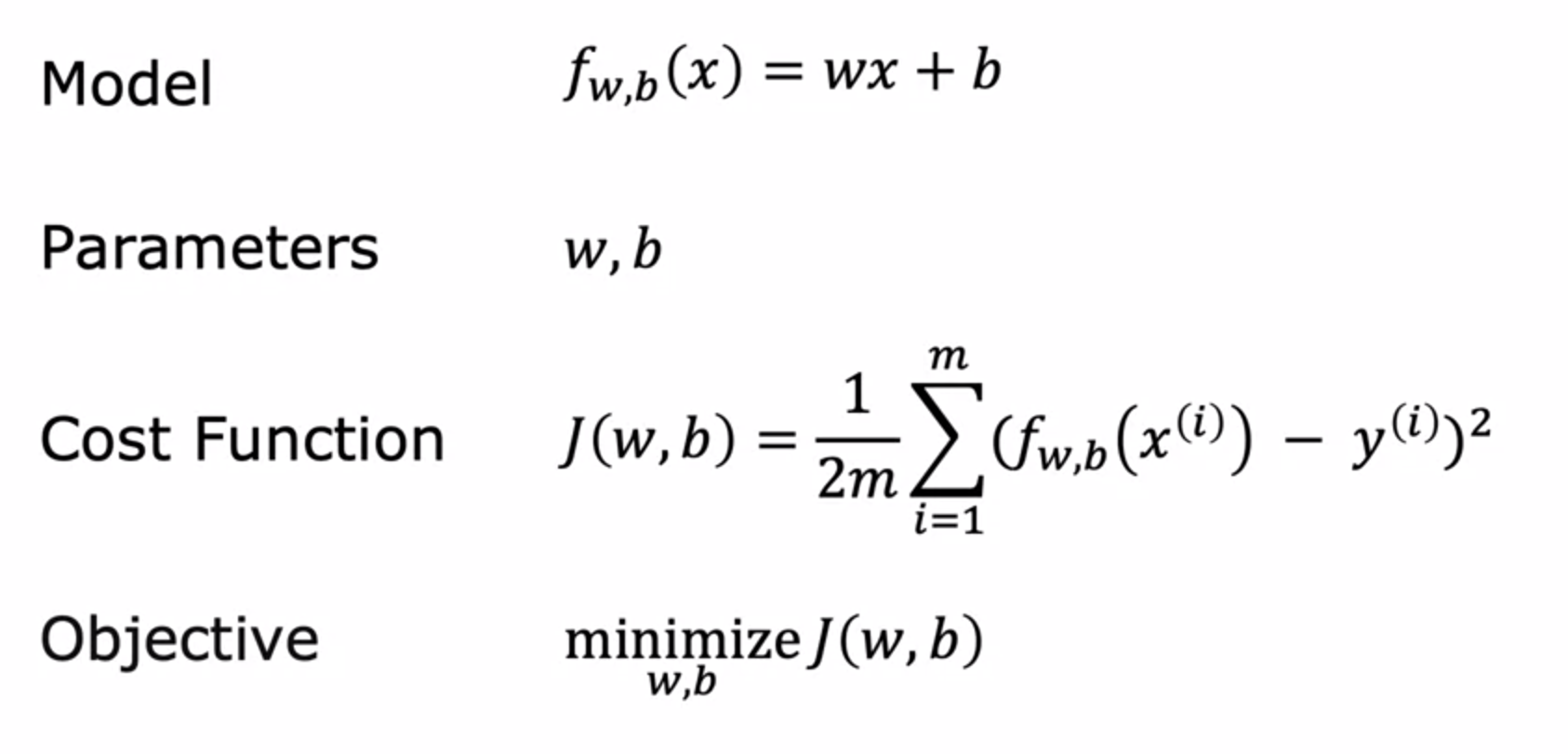
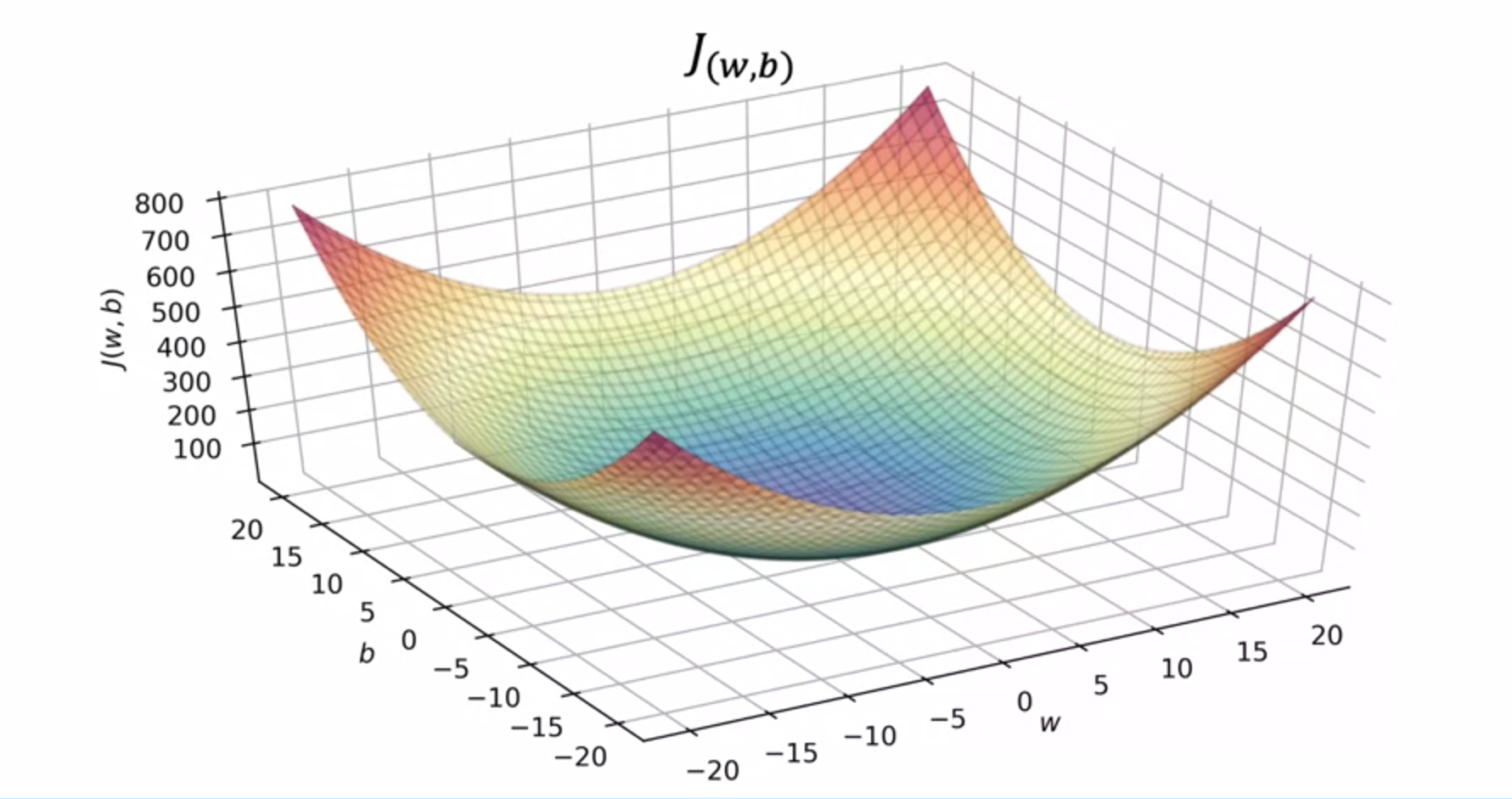
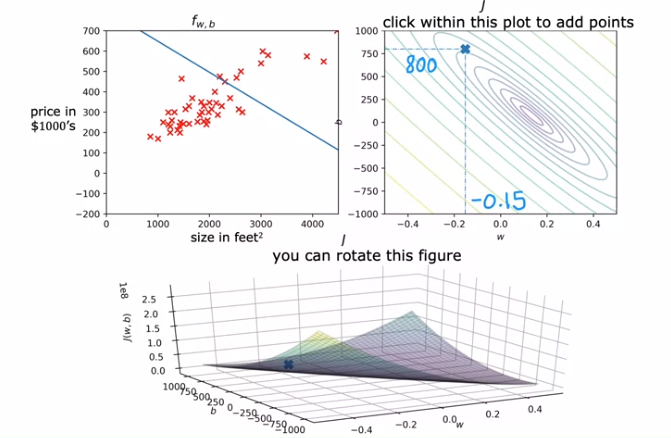
The final cost function is denoted as 'J(w, b)' and is also called the squared error cost function. It quantifies the overall error of the model's predictions. The goal in linear regression is to find values of 'w' and 'b' that minimize this cost function, which means finding the line that best fits the training data. the cost function is a fundamental tool in linear regression that helps us evaluate the performance of the model and find the best parameters 'w' and 'b' to fit the data.