딥러닝
딥러닝의 구조
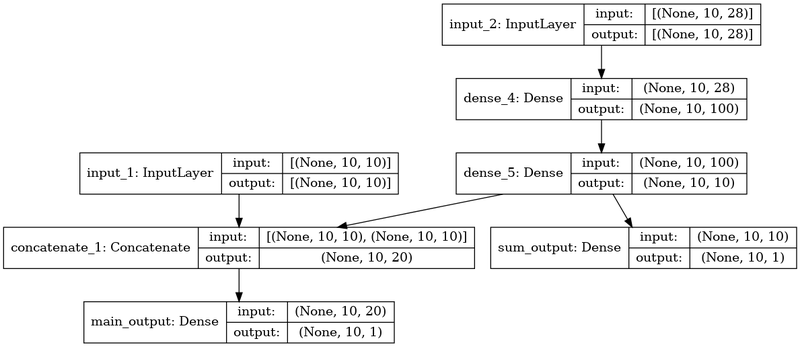
딥러닝의 다양한 모델 학습 방법
1. 가중치 초기화
2. 배치 정규화
3. 규제
4. 드롭아웃
퍼셉트론

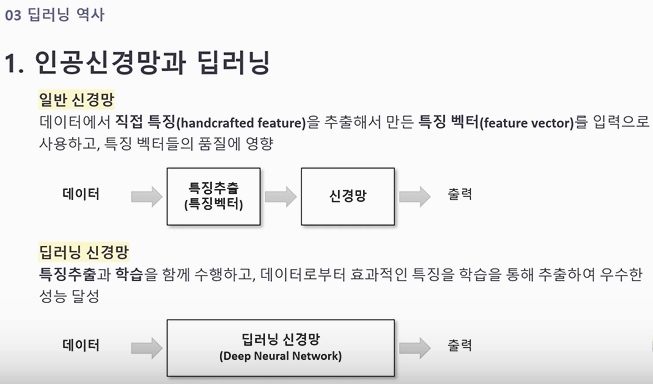
과적합 방지의 예

과적합 문제 해결의 규제화 기법에 대한 흥미가 생긴다.
자연어 중에서는 자주 사용되지 않은 언어라고 해서
중요하지 않은 것이 아니기 때문에
SNS를 많이 사용하는 젊은 층이 사용하는 은어를 집중으로
학습된다면 딥러닝으로 객관적인 모델이 만들어 질 수 있을까?
이에 대해 규제화 기법이 어느 정도 효과가 있을지
인간이 파악한 것은 객관적일까?
빈도 수를 규제한 방법이 놓치는 부분은 무엇일까?
문제해결은 어떻게 할 수 있을까?
고민해보고 싶다.
딥러닝 프레임워크

딥러닝의 발전


Fantivation