AIffel
1.비전공자의 딥러닝 시작

급격하게 당 떨어진다.난 초보라서 못하는걸 안 들키려고 하는데오히려 코딩 좀 해보신 분들이사명감(?)을 가지고 살신성인 알려주신다개발자들에게 중요한 것은 협업(능력, 노력)그래서 깃허브를 쓴다.고진감래라 했던가.치열한 시행착오 끝에 성공하면눈물나게 기쁘다 ㅠㅠ이번 주,
2.[Python] 회문
a = input('입력된 단어는:')b = a::-1print('뒤집힌 단어는:'+b)def retur_n(a): if a == b: print("입력된 단어는 회문입니다.") else: print('입력된 단어는 회문이 아닙니다.')retur_n(
3.[Python] 람다(lambda)
매개변수: 함수에 입력된 전달된 값을 받는 변수인수: 함수 호출할 때 전달하는 입력값일반함수:7람다로 만든 함수: 7'이탈리아 나폴리'리스트나 튜플에 특별한 처리시 사용하는 함수0, 2, 4 ... 16, 18(0, 2, 4 ... 16, 18)map()는 꼭 리스트o
4.[Python] 라이브러리, 프레임워크
여러 패키지, 모듈을 모아둔 집합ex) 파이토치(PyTorch), 텐서플로우(TensorFlow)프로그래밍 진행할 때 필수적인코드, 알고리즘 등과 같은기반구조(뼈대)를 제공하는 도구라이브러리는 주로 프로그래머가 호출하여 사용하는 도구프레임워크는 주로 프로그래머가 들어가
5.[Python] import로 패키지 가져오기
import 패키지 import 패키지.모듈 import 패키지.모듈1, 패키지.모듈2 패키지.모듈.변수 패키지.모듈.함수() 패키지.모듈.클래스() os.path.join() 패키지 > 모듈 > 함수() : OS패키지의 path모듈은 경로를 다룰 때 유용함 그
6.[Python] import로 모듈가져오기
확장자 파일로써 변수/함수/클래스 등을 저장할 수 있으며, 자체 실행도 가능함모듈 여러 개 묶음 : 패키지모듈 및 패키지 모음 : 라이브러리import 모듈 (as 변경할 변수): 0~1 사이의 난수를 출력하는 random 모듈의 함수for i range(5): pri
7.[실습] 2. N-gram
코드 실현하기 전에생각을 해서주석으로 뭐 부터 할지 순서를 먼저 쓰고 시작하기.
8.[실습] 1. 햄버거 갯수 출력
9.[python] 구문오류 / 예외
구문 오류 (Syntax Error) 프로그램 실행 전, 문법에 맞지 않아서 오류가 나는 것. > EOL (Error Of Line) 런타임 오류 = 예외 프로그램 실행 후 나온 에러 예외 처리 방법 조건문 속도가 빠르나 모두 예측하여 조건문 처리 해야함 t
10.[Python] 클로저
전역 변수: 전체에서 접근 가능한 변수전역 범위: 그 변수에 접근가능한 범위지역변수: 함수 내에서 만든 변수지역범위: 그 변수에 접근가능한 범위hi python!aiffelhi python!pythonhey 푸린!푸린hello 아이펠!\*nonlocal who 를 주석
11.[Python] 일급 객체
1) 변수/자료구조 안에 객체 할당 가능2) 매개변수로 전달 가능3) 리턴값으로 사용 가능 (중첩함수 가능)\*파이썬에서는 함수도 일급 객체객체: 변수(속성)와 함수(행동)를 가지고 있는 대상객체지향 프로그래밍: 프로그램을 구성하는 요소들을 객체로 표현& 객체
12.[Python] 리스트
append: 요소 하나를 추가10, 20, 30, 500\[10, 20, 30, 500, 600]len(a)4extend: 여러개 추가할 때, 리스트를 연결하여 확장10, 20, 30, 500, 600len(a)5insert: 특정 인덱스에 요소 추가insert(0,
13.[Python] 클래스
클래스를 사용하려면 객체를 만들어야 한다.객체를 초기화해주는 생성자(매직)메소드는 init 이다.생성자(매직)메소드의 매개변수에는 self(자신)과 name(속성값)이 들어간다.생성자(매직메소드)의 명령블록에는 self.new = name 이 들어있다.클래스(Class
14.[실습] 4. 사각형 넓이
클래스 만들기
15.[실습] 5. 키오스크(cafe)

'americano', 'latte', 'mocha', 'yuza_tea', 'green_tea', 'choco_latte'def menu_select(self): n = int(input("음료번호 입력 : ")) self.price_sum = self.pric
16.[머신러닝] 1. 기초
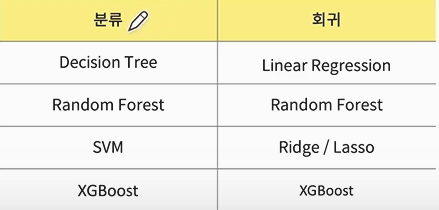
머신러닝 > (1) 지도 학습 (분류, 회귀(예측)) (2) 비지도 학습 (군집화, 차원축소) (3) 강화 학습지도학습정답이 있는 데이터를 가지고 학습을 해서 예측비지도학습정답이 없는 데이터로 예측강화학습알파고의 사례처럼, 환경을 만들어주고 그 환
17.[머신러닝] 2. 데이터 핸들링(1)
: 판다스(pandas)는 파이썬(python)을 기반으로 한 쉽고 강력한 데이터 분석 도구.파이썬 코드를 이용해서 엑셀과 같은 기능을 판다스에서 활용해 볼 수 있다.:행과 열이 있는 표 형태 구조시리즈(하나의 열(column, 세로))가 2개 이상일 때
18.[머신러닝] 2. 데이터 핸들링(2)
기존의 인덱스명을 살릴 때index_col='Unnamed: 0'데이터 불러올 때df = pd.read_csv('new_modudak.csv')변수 = df.copy()axis=1:열방향(컬럼)axis=0:행방향data = data.drop('Unnamed: 0', a
19.[머신러닝] 3. 전처리(범주형데이터)
사이킷런 활용 사이킷런이란? • 파이썬을 활용한 머신러닝도구 • 데이터분석(예측)을 위한 간단하고 효율적인 도구 • 누구나쉽게 다양한 상황에서 활용가능 • 오픈소스 > 사이킷런으로할수있는것 -분류(ex.스팸메일) -회귀(ex.가격) -클러스터링(ex.고객세그먼트)
20.[머신러닝] 4. 전처리(수치형데이터)
표준화(StandardScaler)와 정규화(MinMaxScaler)는 둘 다 데이터 스케일링의 방법 중 하나입니다. 스케일링은 데이터의 크기(scale)를 조정하는 것으로, 일반적으로 모델의 성능을 향상시키는 데 도움이 됩니다.표준화(StandardScaler)는 평
21.[머신러닝] 사이킷런 data실습
• dataset.feature_names• dataset.target• dataset.data:2\* 2세트만 확인시변수명= pd.DataFrame(data=dataset.data , columns=dataset.feature_names)• cancer_df'targ
22.[머신러닝] 5. 사이킷런 머신러닝
\-사이킷런의 train_test_split 라이브러리를 활용하면 쉽게 train set(학습데이터셋)과 test set(테스트셋)을 랜덤하게 나누어 준다.\-학습용으로 70%를 두고 30% 데이터는 테스트용으로 둔다.\-모델이 좋아서 성능이 좋은 건지 알기 위해
23.[머신러닝] 6. 지도학습(분류): 의사결정나무
의사결정 나무모델• 지도학습 알고리즘 (분류, 회귀)• 직관적인 알고리즘 (이해 쉬움)• 과대적합되기 쉬운 알고리즘 (트리 깊이 제한 필요)• 필요한 라이브러리를 가져오고, sklearn 라이브러리에 내장된 데이터를 불러옵니다• 지도학습(분류)에서 가장 유용하게 사용되
24.[머신러닝] 6. 지도학습(분류): 랜덤 포레스트
앙상블 방법\-배깅: 같은 알고리즘으로 여러 모델을 만들어 분류함(랜덤포레스트)\-부스팅: 학습과 예측을 하면서 가중치 반영 (xgboost)여러개의 의사결정 트리로 구성앙상블 방법 중 배깅(bagging) 방식부트스트랩 샘플링 (데이터셋 중복 허용)최종 다수결 투표과
25.[머신러닝] 6. 지도학습(분류): XGboost
XGBoost 모델 더 알아보기트리 앙상블 중 성능이 좋은 알고리즘eXtreme Gradient Boosting를 줄여서 XGBoost라고 한다.약한 학습기가 계속해서 업데이트를 하며 좋은 모델을 만들어 간다.부스팅(앙상블) 기반의 알고리즘캐글(글로벌 AI 경진대회)에
26.[머신러닝] 6. 지도학습(분류): 교차검증
일반적으로 모델을 학습시킬 때 데이터를 train set과 test set으로 나누어 train set을 가지고 학습을 수행합니다.교차검증이란 여기서 train set을 다시 train set과 validation set으로 나누어 학습 중 검증과 수정을 수행하는 것을
27.[머신러닝] 7. 지도학습(회귀): 선형회귀
• 단순 선형회귀와 다중 선형회귀가 있지만 흔히 사용하는 것은 다중 선형회귀입니다.• Feature가 한 개인 경우가 드물기 때문에 보통 feature가 두 개 이상인 다중 선형회귀를 만들게 됩니다.단순 선형회귀: 독립변수(피처)가 1개다중 선형회귀: 독립변수(피처)가
28.[머신러닝] 7. 지도학습(회귀): 릿지 회귀
• 오버피팅 문제로 규제(regularization)를 적용한 모델• 규제 방식: L2 규제• 파라미터(alpha) 값을 활용해 조절• alpha 값이 커질수록 회귀 계수 값을 작게 만듦\*규제를 통해서 모델의 성능을 올릴 수 있습니다.
29.[머신러닝] 7. 지도학습(회귀): 라쏘 회귀
• 오버피팅 문제로 규제(regularization)를 적용한 모델• 규제 방식: L1 규제 (중요한 피처만 선택하는 특성)• L2에 비해 회귀 계수를 급격히 감소시켜 중요하다고 생각하는 피처만 선택하고 나머지는 0으로 만듦
30.[머신러닝] 7. 지도학습(회귀): 엘라스틱넷 회귀
• 오버피팅 문제로 규제(regularization)를 적용한 모델• 규제 방식: L2 규제와 L1 규제 (중요한 피처만 선택하는 특성) 결합• 시간이 상대적으로 오래 걸림
31.[머신러닝] 7. 지도학습(회귀): 램덤포레스트 & XGboost
• 여러 개의 의사결정 트리로 구성• 앙상블 방법 중 배깅(bagging) 방식• 부트스트랩 샘플링 (데이터셋 중복 허용)• 최종 다수결 투표• 트리 앙상블 중 성능이 좋은 알고리즘• eXtreme Gradient Boosting을 줄여서 XGBoost라고 한다.약한
32.[머신러닝] 7. 지도학습(회귀): 하이퍼파라미터 튜닝
모델의 성능 향상을 위해 하이퍼파라미터 튜닝을 진행하며 사이킷런의 model_selection에서 제공하는GridSearchCV와RandomizedSearchCV를 이용하여 최적화할 수 있습니다.• grid search를 통해 모두 탐색하여 최적의 하이퍼파라미터를 찾음
33.[머신러닝] 7. 지도학습(분류): 평가
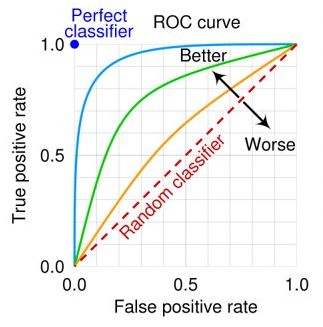
정밀도 precision: 양성이라고 예측한 값 중 실제 양성인 값의 비율 (암이라고 예측 한 값 중 실제 암)재현율 recall: 실제 양성 값 중 양성으로 예측한 값의 비율 (암을 암이라고 판단)F1: 정밀도와 재현율의 조화평균ROC-AUCROC: 참 양성 비율(T
34.[머신러닝] 7. 지도학습(회귀): 평가
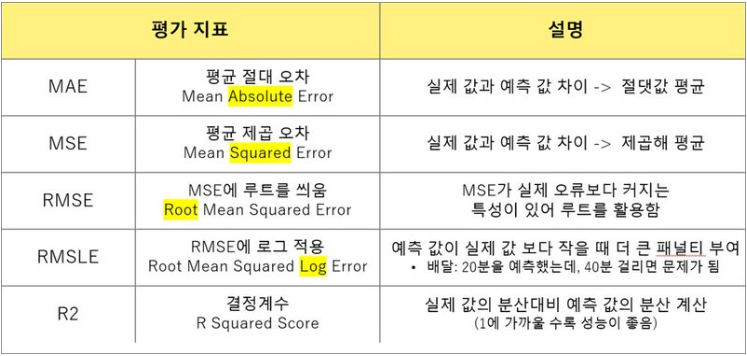
35.[머신러닝] 7. 지도학습(분류)_추가
알파 : 규제의 강도 조절단 목적은 조금 다릅니다.릿지의 알파 : 계수의 크기 제한이 목적랏소의 알파 : 불필요한 변수제거가 목적사례 : 주택 가격 예측, 주식 가격 분석, 수요 예측 이유 : 주택 크기와 가격 사이 관계 분석 등사례 : 다중 공선성(모델 변수간의 상관
36.[머신러닝] 7. 지도학습(회귀)_추가
grid.bestparamsmodel = ElasticNet(model.fit(pred = model.predict(import numpy as np
37.[머신러닝] 8. 비지도학습_PCA(차원축소)
feature가 많을수록 데이터의 차원이 커지게 되는데, 데이터셋의 크기에 비해 feature가 많아질 경우 이를 표현하기 위한 변수가 많아져 모델의 복잡성이 증가되고 과적합 문제가 발생되기도 합니다.이러한 문제를 해결하기 위해 차원 축소 방법이 사용되고 있습니다.\*
38.[머신러닝] 8. 비지도학습_군집(clustering)
군집분석은 유사성이 높은 대상의 집단을 분류하는 분석 방법계층적 군집분석과 비계층적 군집분석 으로 구분함전통적인 계층적 군집분석은 군집의 개수를 나중에 선정함비계층적 군집분석인 K-means는 군집의 수를 가장 먼저 선정함K-mean 군집분석은 초기 중심 값은 임의로
39.[머신러닝] 9. 자연어처리(NLP)
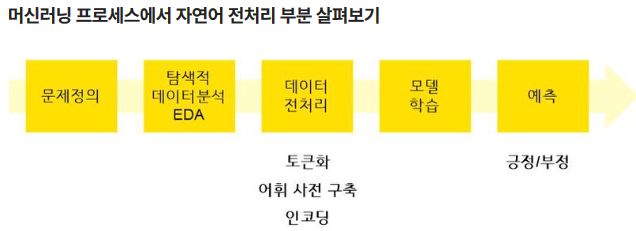
각 문장에서 단어 출현 횟수를 카운팅하는 방법 (BOW, Bag Of Word)리마인드 각 문장에서 단어 출현 횟수를 카운팅하는 방법 (BOW, Bag Of Word)다른 문서보다 특정 문서에 자주 나타나는 단어에 높은 가중치를 주는 방법TF-IDF(Term Frequ
40.[머신러닝] 10. 이미지 처리
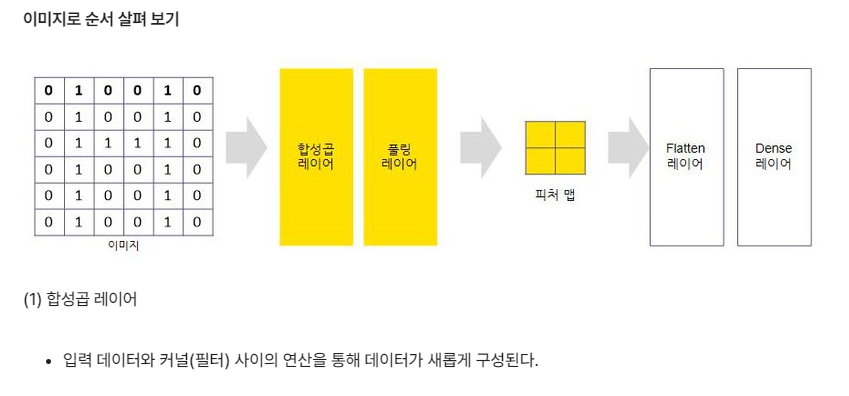
딥러닝 딥러닝 뇌의 뉴런과 유사한 머신러닝 알고리즘 심층 신경망(DNN, Deep Neural Network) 입력층 – 은닉층 – 출력층이 있음 딥러닝의 학습 과정 순전파: 예측값 계산 손실함수: 오차 측정 옵티마이저(최적화): 강사 하강법 역전파: 가중치 조
41.[머신러닝] 실습_Airbnb
미국 NYC Airbnb 목록(2019)프로젝트 목적: 가격 예측(price)제공 데이터(3개): train.csv, test.csv, y_test(최종 채점용)평가 방식: MSE (평균제곱오차/ 실제 값과 예측 값 차이 ->제곱해 평균)<참고> : 6. 지도학습
42.[딥러닝_기초] 1. 강화학습
지도학습 : paired data=로 학습 (label 이 있음)비지도학습 : Unpaired data로 학습 (그룹이 있음)강화학습 : 아무것도 없을 때, 누적 보상을 최대화하는 최적의 정책 학습 에이전트가 환경과 상호작용하며 보상을 최대화하기 위해 시행착오를 통해
43.[딥러닝_기초] 2. 다양한 모델 소개
화이트 노이즈(White Noise)는 주파수 스펙트럼이 균일한 임의의 신호로, 모든 주파수 대역에서 동일한 에너지를 갖는 신호입니다. 이는 모든 주파수를 동등하게 포함하고 있어서 "백색"이라는 용어가 사용됩니다.:정보량이 많이 있는 모든 주파수의 성분을 가지고 있는
44.[딥러닝_기초] 3. CNN
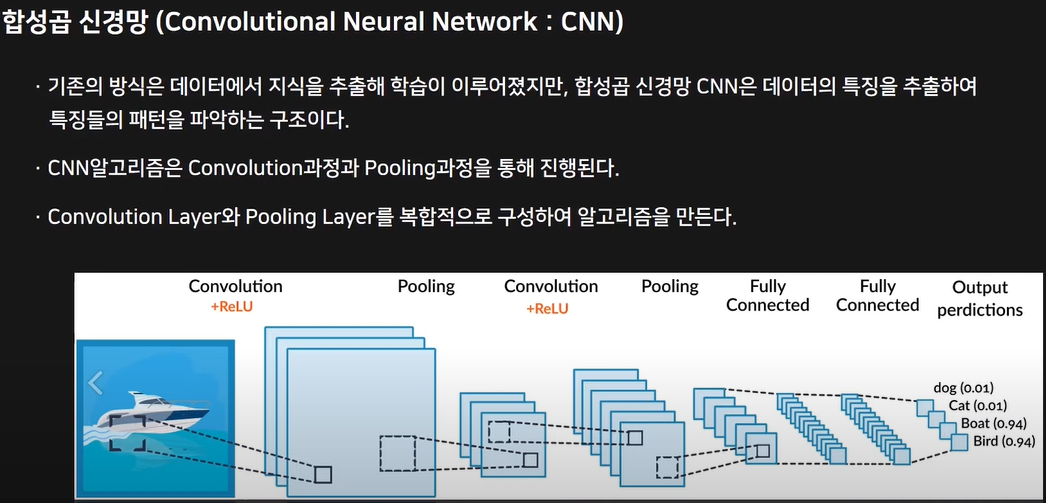
합성곱신경망
45.[딥러닝_기초] 4. RNN, LSTM
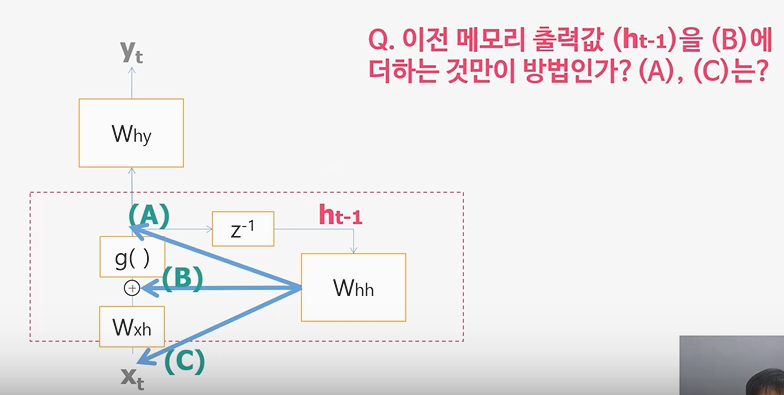
Recurrent Neural Network입력이 한 개가 아니라면? RNN!입력 또는 출력에 시간 순서(Sequence)가 있다면? RNN!어떤 문제를 풀기 위하여 입력이나 출력이 여러 개 일때? RNN!그동안 학습한 인공신경망, 딥러닝, 그리고 CNN이 입력층에서
46.[밑시딥] 2. 퍼셉트론
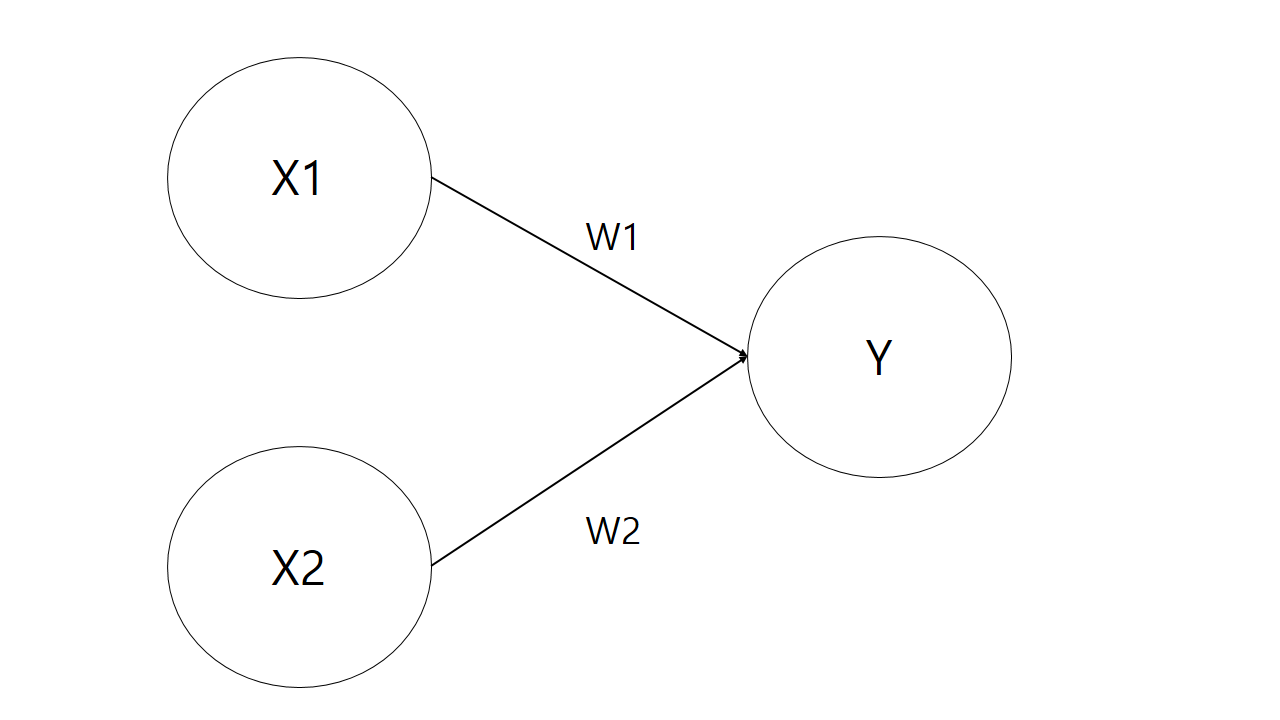
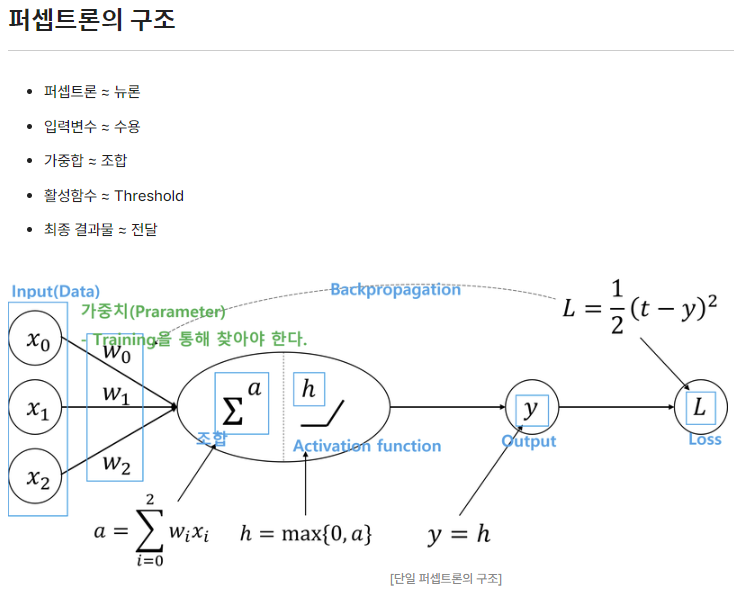
: 신경망(딥러닝)의 기원이 되는 알고리즘. 퍼셉트론의 구조를 배우는 것은 신경망과 딥러닝으로 나아가는데 중요한 아이디어를 배우는 일: 다수의 신호 input, 하나의 신호로 output: 0/1 두 가지 값만을 가짐X1, X2는 입력신호, Y는 출력신호, W1, W2
47.[밑시딥] 3. 신경망
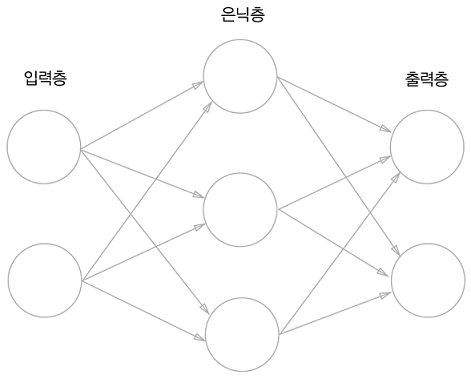
위의 그림 속 신경망은 3층으로 구성되어있지만 가중치를 갖는 층이 2개이기 때문에 2층 신경망 이라고 한다.
48.[밑시딥] 4. 신경망 학습

1. 손실 함수 (1-1) 오차제곱합 (1-2) 교차 엔트로피 오차 (1-3) 미니배치 학습 (1-4) 교차엔트로피 오차 구현 (1-5) 왜? 2. 수치 미분 (2-1) 미분 (2-2) 수치 미분 (2-3) 편미분 3. 기울기 (3-1) 경사 하강법
49.[밑시딥] 3~4장 예상문제
(1) 시그모이드 함수와 소프트맥스 함수의 공통점둘 다 비선형 함수, 활성화 함수둘 다 입력값을 확률값으로 변환하여 출력(2) 시그모이드 함수와 소프트맥스 함수의 차이점가장 큰 차이점은 출력의 개수시그모이드 함수는 단일 뉴런의 출력을 위한 활성화 함수로 주로 이진 분
50.[밑시딥] 5. 오차역전파법
backpropagation: 가중치 매개변수의 기울기를 효율적으로 계산수치 미분은 단순하고 구현하기도 쉽지만계산 시간이 오래 걸린다는 게 단점이다.1) 수식을 통한 것2) 계산 그래프(computational gragh) 를 통한 것그래프는 복수의 노드 node 와
51.[밑시딥] 6. 학습 기술들
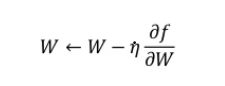
우리는 항상 손실함수의 값을 가능한 낮추는 매개변수를 찾는 것이 목표이고이러한 것을 최적화 라고 한다.앞서 역전파오류법에서 최적의 매개변수 값을 미분을 이용하는 확률적 경사 하강법(SGD)을 이용했다.간단히 말하면, 기울어진 방향으로 일정 거리만큼 가겠다는 방법이다.단
52.[밑시딥] 7. CNN (합성곱 신경망)

CNN에서는 새로운 합성곱 계층과 풀링 계층이 추가된다. CNN 계층은 conc-relu-pooling 흐름으로 연결된다. 여기서 중요한 것은 출력에 가까운 층에서는 affine-relu 구성을 사용할 수 있다.CNN에서는 패딩, 스트라이드 등 CNN 고유의 용어가 등
53.[밑시딥] 7. 예상문제
합성곱 계층과 풀링 계층의 공통점은?합성곱과 풀링은 딥러닝의 합성곱 신경망(Convolutional Neural Network, CNN)에서 주로 사용되는 두 가지 기술입니다.기능적 목적: 둘 다 CNN에서 특징을 추출하고 입력 데이터를 다운샘플링하여 네트워크의 파라미
54.[밑시딥] 8. 딥러닝
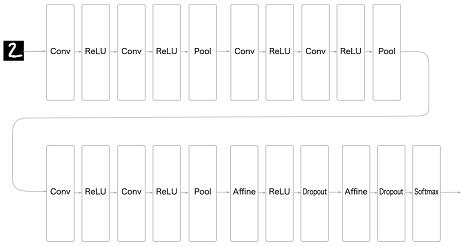
3\*3의 작은 필터를 사용한 합성곱 계층(Conv)활성화 함수(ReLU)풀링 계층 추가해 중간 데이터의 공간 크기를 줄여나감가중치 매개변수 갱신(Adam을 사용해 최적화)가중치 초기값: 'He' 초기값 (ReLU계의 활성화 함수 사용 시 He 초기화 방법이 효율적이
55.[딥.한.끝] 1. 딥러닝이란
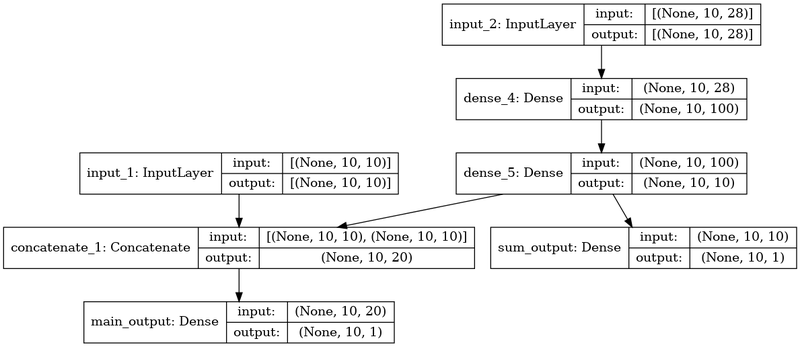
딥러닝의 구조딥러닝의 다양한 모델 학습 방법1\. 가중치 초기화2\. 배치 정규화3\. 규제4\. 드롭아웃과적합 문제 해결의 규제화 기법에 대한 흥미가 생긴다.자연어 중에서는 자주 사용되지 않은 언어라고 해서중요하지 않은 것이 아니기 때문에SNS를 많이 사용하는 젊은
56.[딥.한.끝] 2. 텐서 타입 및 변환

: 데이터 표현과 다양한 수학식을 계산하기 위한 기본 구조로 텐서를 사용해서 표현: 데이터를 담기위한 컨테이너(container) 다차원 배열 또는 리스트 형태와 유사 일반적으로 수치형 데이터를 저장하고, 동적 크기를 가짐 텐서는 형상이 존재하며 데이터의 표
57.[딥.한.끝] 3. 딥러닝 구조와 모델
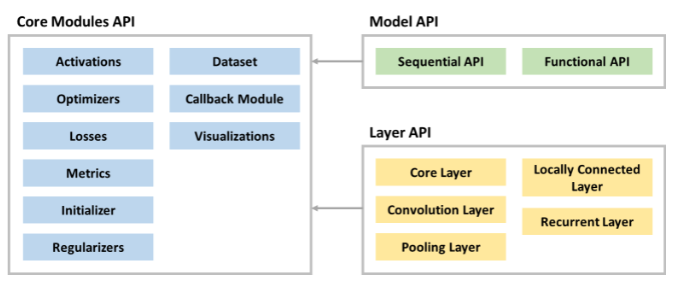
케라스에서 제공하는 API들의 구성도를 살펴보면, 크게 Model API와 Layer API가 있고 필요한 모듈들을 Modules API를 호출해서 사용합니다. 딥러닝 모델은 여러 레이어들로 구성되어 있습니다.먼저 딥러닝을 사용하는데 필요한 라이브러리인 TensorFl
58.[딥.한.끝] 4. 딥러닝 모델 학습
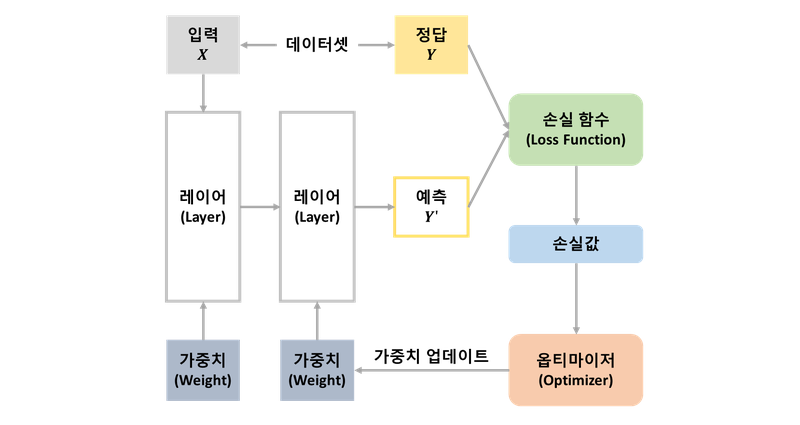
1. 손실 함수 1-1. 평균절대오차 1-2. 평균제곱오차 1-3. 원-핫 인코딩 1-4. 교차 엔트로피 오차 1-5. 교차 크로스 엔트로피 2. 옵티마이저와 지표 2-1. 경사하강법 2-2. 블록함수와 비블록함수 2-3. 안장점 2-4. 학습률
59.[딥.한.끝] 5. 모델 저장과 콜백

학습시킨 모델을 저장하고 관리하는 것은 모델 관리,더 나아가 MLOps(데이터 수집부터 모델 학습, 서비스 배포까지를 포함하는 시스템) 의시작점이라고 할 수 있습니다.: 손으로 쓴 숫자들로 이루어진 이미지 데이터셋딥러닝을 사용하는데 필요한 라이브러리인 Tensorflo
60.[딥.한.끝] 6. 모델 학습 기술
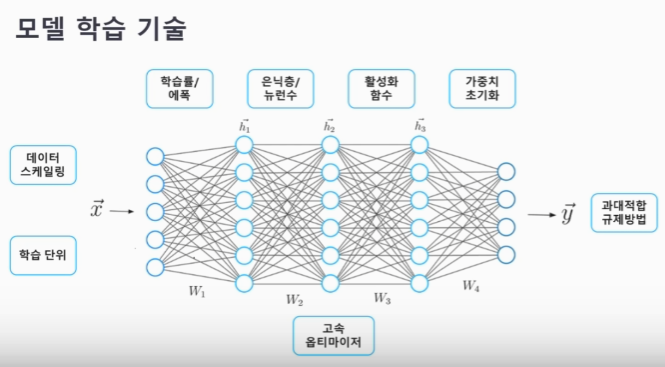
: 모델이 실제값, 예측값 차이를 최소화 하는 역할 수행Q. 모든 데이터를 한 번에 넣고 학습시키는 전체 배치(Full Batch)방식이 있는데 왜 분할하여 넣는 미니 배치(Mini Batch) 방식을 사용하나요?딥러닝은 많은 양의 데이터를 필요로 하고 모든 데이터를
61.[딥.한.끝] 7. 모델 크기 조절과 규제
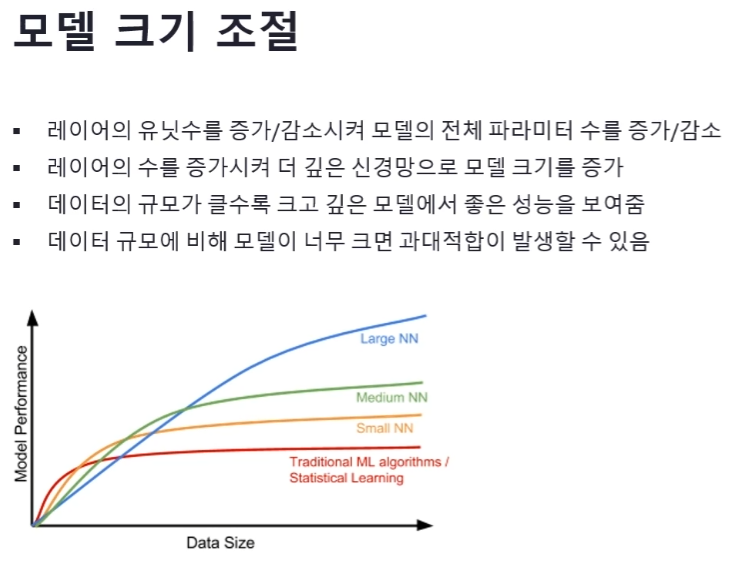
이전에 사용했던 IMDB 딥러닝 모델은 과대적합이 발생하는 문제가 있었습니다. 이 문제를 해결하려면 모델의 크기를 조절해야 합니다.모델 크기를 조절하는 방법은 크게 레이어의 유닛수와 레이어의 수를 조절하는 것이 있습니다.우선 레이어의 유닛수를 증가 또는 감소시켜 모델
62.[딥.한.끝] 8. 가중치 초기화와 배치 정규화
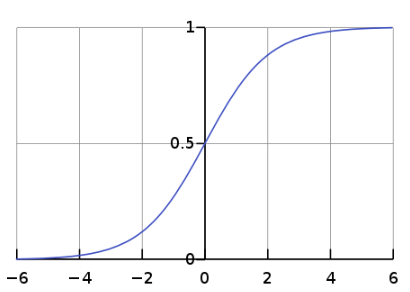
Weights Initialization: 가중치 초기화는 신경망의 성능에 큰 영향을 주는 요소 중 하나.만약 가중치의 값이 일부 값으로 치우치게 되면, 활성화 함수를 통과한 값들도 치우치게 되고, 결국 표현할 수 있는 신경망의 수가 적어지는 문제가 발생합니다. 보통
63.[딥.한.끝] 9. 딥러닝 모델 실습
64.[딥러닝CV] 1. 컴퓨터 비전 태스트
1\. 컴퓨터 비전 태스트 '상상'해 보기2\. 다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기3\. CNN 하나씩 이해하기 (1) 1-Channel Convolution4\. CNN 하나씩 이해하기 (2) 3-Channel Convolution
65.[딥러닝CV] 2. 다층 퍼셉트론
컴퓨터 비전 태스트 '상상'해 보기2\. 다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기
66.[딥러닝CV] 3. 1-Channel Convolution
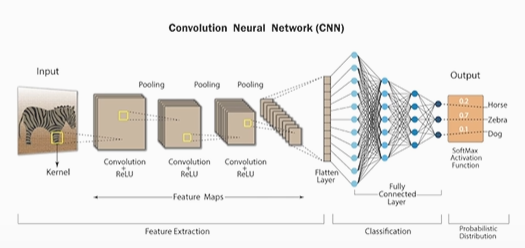
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기3\. CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기
67.[딥러닝CV] 3. 1-Channel Convolution
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기3\. CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기
68.[딥러닝CV] 4. 3-Channel Convolution
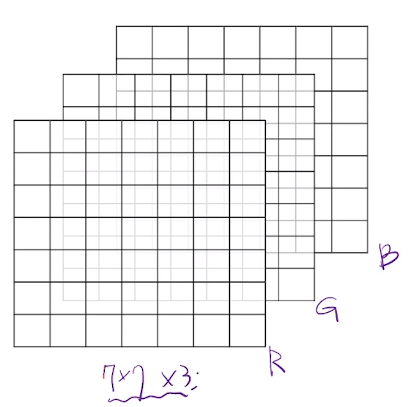
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기CNN 하나씩 이해하기 (1) 1-Channel Convolution4\. CNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기
69.[딥러닝CV] 5. Pooling
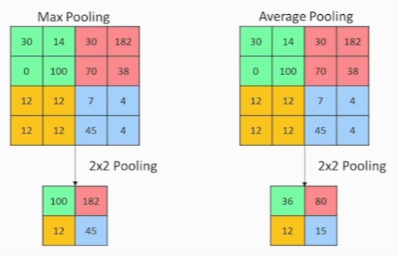
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel Convolution5\. CNN 하나씩 이해하기
70.[딥러닝CV] 6. 심화된 CNN 구조
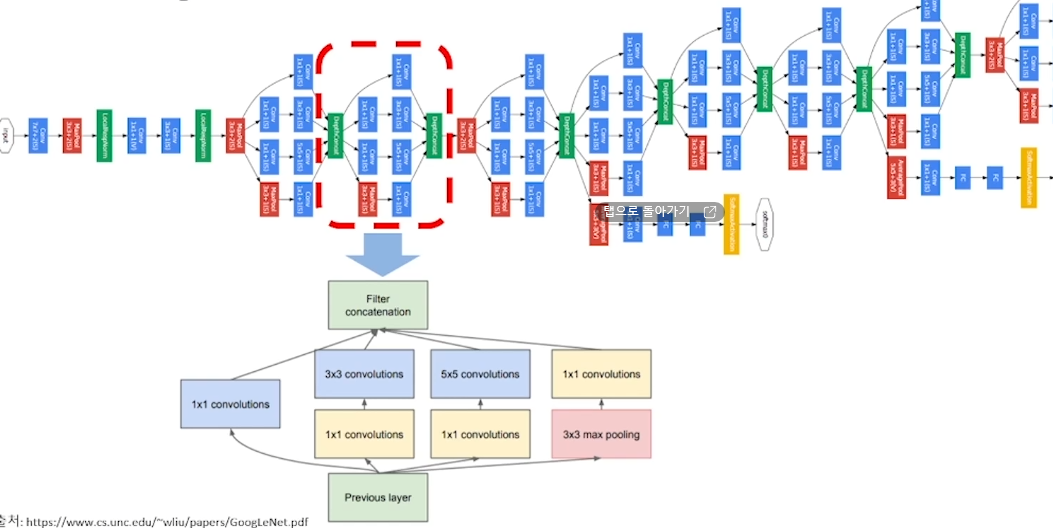
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기 (3)
71.[딥러닝CV] 7. Transfer Learning 이해
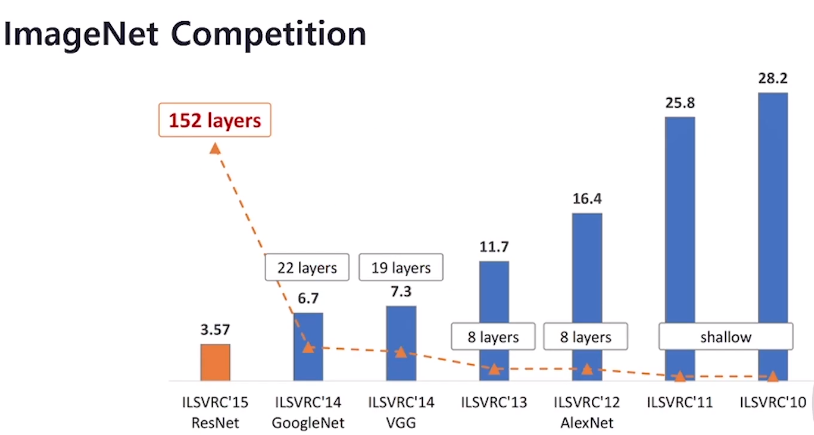
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기 (3)
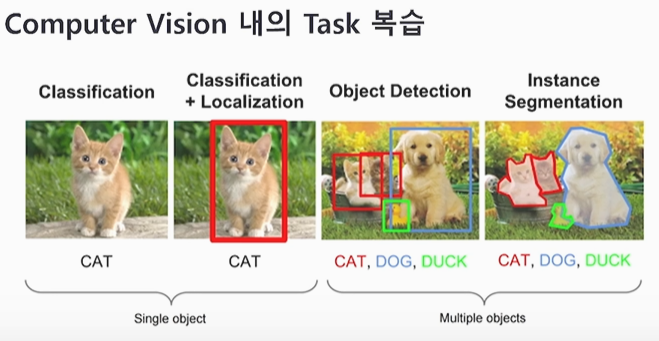
72.[딥러닝CV] 8. Object Detection
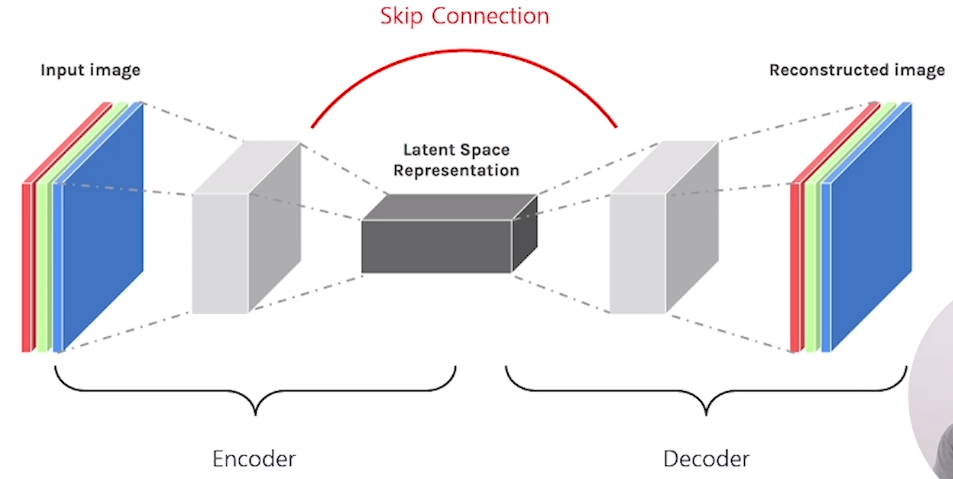
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기 (3)
73.[딥러닝CV] 9. Segmentation
컴퓨터 비전 태스트 '상상'해 보기다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기CNN 하나씩 이해하기 (1) 1-Channel ConvolutionCNN 하나씩 이해하기 (2) 3-Channel ConvolutionCNN 하나씩 이해하기 (3)
74.[딥러닝CV] 예상문제
Q. 컴퓨터 비전의 각 태스크는 어떻게 구분할 수 있나요?컴퓨터 비전의 태스크는 Single Object인지 Multiple Object인지에 따라 구분할 수 있습니다. Single Object를 다루는 태스크에는 Classification과 Localization이
75.뉴스 요약봇 만들기
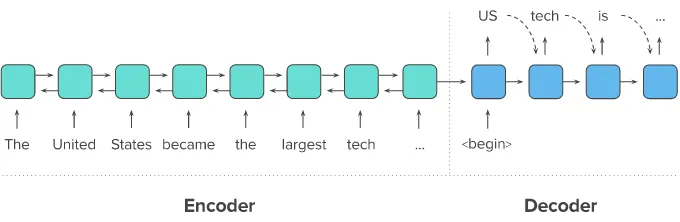
: 원문에서 문장들을 추출해서 요약하는 방식결과로 나온 문장들 간의 호응이 자연스럽지 않을 수 있음딥 러닝보다는 주로 전통적인 머신 러닝 방식에 속하는 텍스트 랭크(TextRank)와 같은 알고리즘을 사용: 원문으로부터 내용이 요약된 새로운 문장을 생성자연어 처리 분야