[딥러닝CV] 목차
- 컴퓨터 비전 태스트 '상상'해 보기
- 다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기
- CNN 하나씩 이해하기 (1) 1-Channel Convolution
- CNN 하나씩 이해하기 (2) 3-Channel Convolution
- CNN 하나씩 이해하기 (3) Pooling
- 심화된 CNN 구조
- Transfer Learning 이해하기
- Object Detection
9. Segmentation
1. Semantic Segmentation vs. Instance Segmentation
Q. Segmentation는 어떤 task 인지 설명해 보세요.
segmentation은 이미지를 픽셀 단위로 나누어서 특정 픽셀이 무엇을 지칭하는지를 파악하는 task 입니다.
Q. Segmentation의 종류는 Semantic Segmentation과 Instance Segmentation으로 나눌 수 있습니다. 어떤 차이가 있는지 각 개념을 설명해 보세요.
Semantic : 하나의 이미지 내의 객체의 종류를 픽셀 단위로 찾는 것
Instance : 하나의 이미지 내의 객체의 개체를 픽셀 단위로 찾는 것
어떤 Segmentation 종류이든 이미지 데이터를 segmentation 모델 학습에 사용하기 위해서는
픽셀 하나하나 labeling을 해줘야 하기 때문에 데이터셋 구축이 어렵고,
따라서 data augmentation이 매우 중요합니다.
2. U-Net 모델을 통해 Semantic Segmentation 이해하기
Q. 앞에서 Segmentation의 종류 2가지를 배웠습니다. 그중에서 Semantic segmentation의 목표는 무엇인지 설명해 보세요.
Semantic segmentation의 목표는 이미지가 주어졌을 때, 픽셀 단위로 Classification을 수행하여 이미지와 동일한 높이와 너비를 가진 Segmentation map을 생성하는 것입니다.
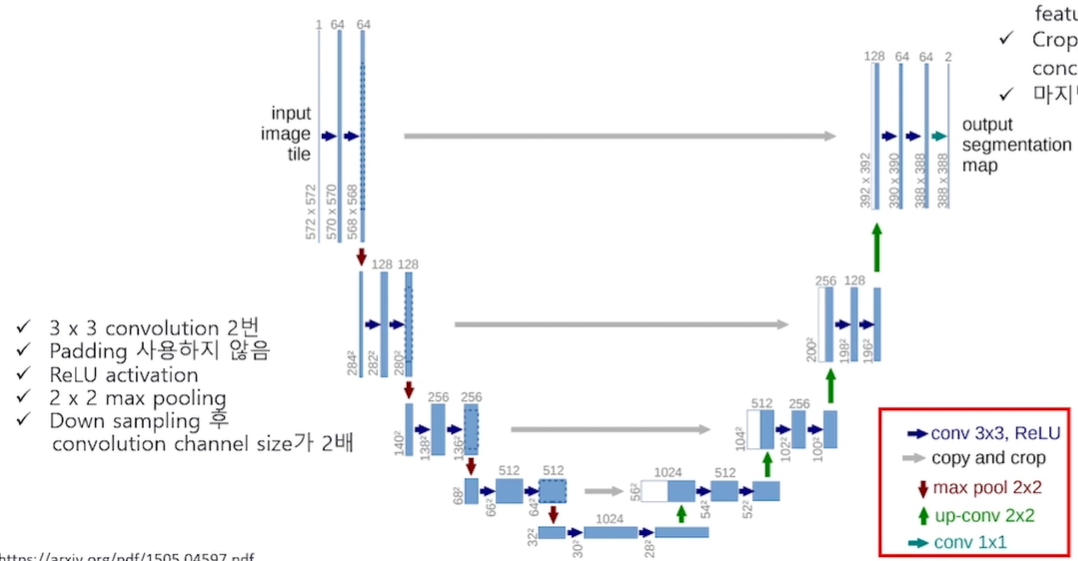
Q. U-Net 모델은 Encoder-Decoder 모델에 skip connection을 추가한 모델이라고 할 수 있습니다. U-Net 모델 구조 중 Encoder에 해당하는 Contracting path 부분의 특징을 설명해 보세요.
convolution 연산으로 이루어진 부분이며 CNN 구조와 유사하다는 특징이 있습니다. 또한 3x3 kernel을 사용하는 VGG 모델과 매우 유사하며 입력 이미지가 가지고 있는 context 정보를 추출합니다. U-Net 모델 구조 중 Encoder에 해당하며 convolution 연산을 하기 때문에 이미지의 위치에 대한 정보가 차츰 사라집니다.
Q. U-Net 모델 구조 중 Decoder에 해당하는 Expanding (Expansive) path 부분의 특징을 설명해 보세요.
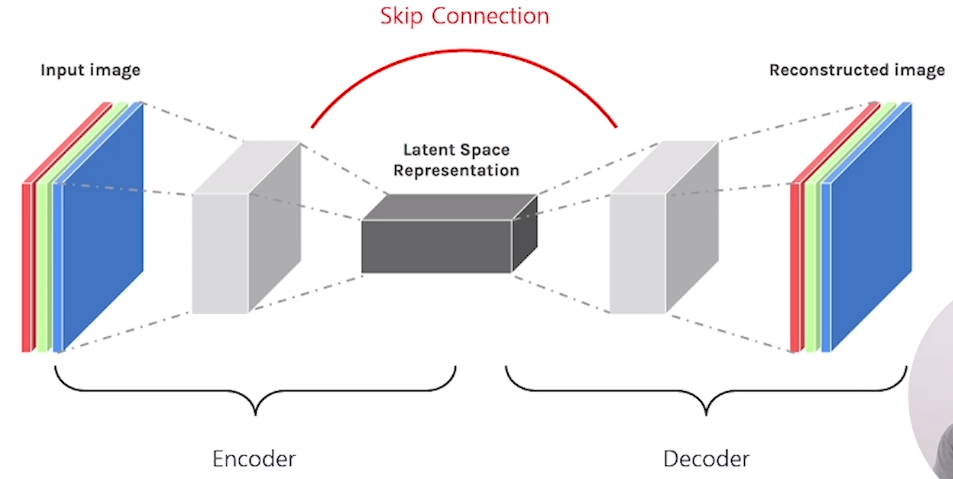
up-convolution 연산으로 이루어진 부분이며 low resolution의 latent representation을 high resolution으로 변형합니다. 또한 Encoder 부분인 contracting path에서 만들어진 feature map을 cropping 한 결과물이 concatenation 됩니다. U-Net 모델 구조 중 Decoder에 해당하며 up-convolution 연산을 하기 때문에 원본 이미지가 가지고 있었던 위치 정보가 복원됩니다.
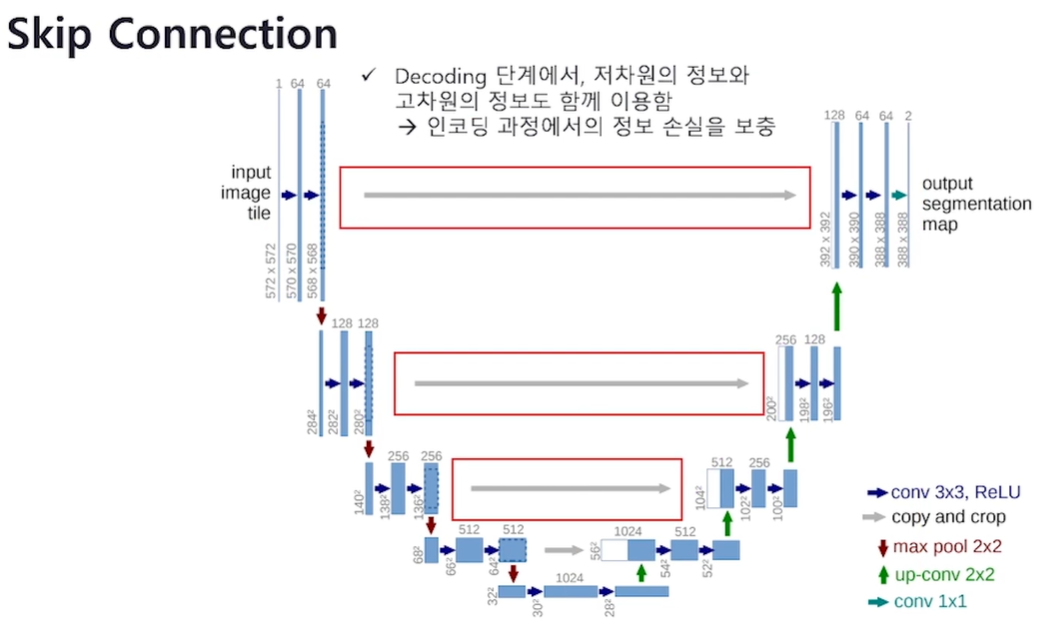
Q. U-Net 모델은 Encoding 부분에서 이미지를 압축하며 정보의 손실이 발생합니다. 이를 보완하기 위해 어떤 방법을 사용하는지, 그 방법의 특징은 무엇인 설명해 보세요.

Encoding 과정에서의 정보 손실을 보충하기 위해 skip connection을 사용합니다. 이것은 Decoding 단계에서, 저차원의 정보와 고차원의 정보도 함께 이용하기 위한 방법입니다.
3. U-Net 코드를 통해서 이해 다지기
