RNN(Recurrent Neural Network)과 LSTM(Long Short-Term Memory)은 모두 시퀀스 데이터를 처리하는데 사용되는 딥러닝 모델입니다. 하지만 LSTM은 RNN의 한계점을 극복하기 위해 설계된 특수한 종류의 RNN입니다. 아래는 RNN과 LSTM의 주요 장단점에 대한 개요입니다.
RNN(순환 신경망)의 장단점:
장점:
간단하고 이해하기 쉽다: RNN은 간단한 구조를 가지고 있어 이해하기 쉽습니다.
작은 데이터셋에 효과적: 작은 규모의 데이터셋에서도 상대적으로 잘 동작할 수 있습니다.
단점:
장기 의존성 처리 어려움: 긴 시퀀스에서 발생하는 장기 의존성(Long-Term Dependencies)을 처리하는 데 어려움이 있습니다.
그라디언트 소실/폭발: 역전파 과정에서 그라디언트가 긴 시퀀스에서 소실 또는 폭발하는 문제가 발생할 수 있습니다.
LSTM(Long Short-Term Memory)의 장단점:
장점:
장기 의존성 처리: LSTM은 메모리 셀을 사용하여 장기 의존성을 효과적으로 학습할 수 있습니다.
그라디언트 관리: 그라디언트 소실 또는 폭발 문제를 해결하기 위한 게이트 메커니즘이 포함되어 있어 학습이 안정적입니다.
단점:
계산 비용 증가: LSTM은 복잡한 구조를 가지고 있어 계산 비용이 더 높을 수 있습니다.
데이터 양에 따라 성능 차이: 작은 데이터셋에서는 성능이 크게 향상되지 않을 수 있습니다.
RNN(순환신경망)
Recurrent Neural Network
입력이 한 개가 아니라면? RNN!
입력 또는 출력에 시간 순서(Sequence)가 있다면? RNN!
어떤 문제를 풀기 위하여 입력이나 출력이 여러 개 일때? RNN!
그동안 학습한 인공신경망, 딥러닝, 그리고 CNN이 입력층에서 출력층의 한 방향으로만
데이터가 전달되는 구조였다면
RNN은 작동 구조를 살펴보면 출력층의 데이터를 다시 입력받는 순환 구조를 가지고 있습니다.
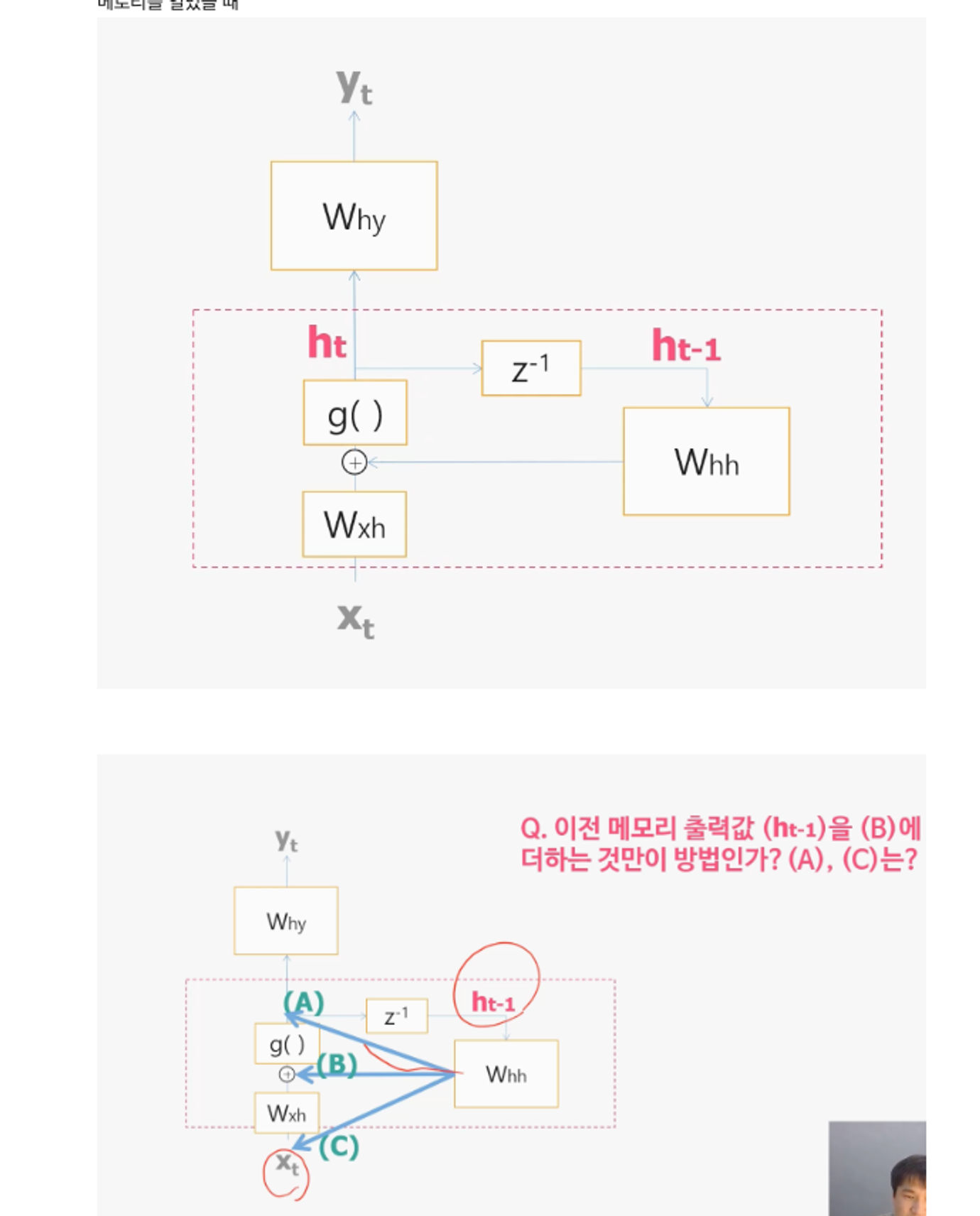
세종류의 가중치
Wxh = 입력계층과 은닉계층 연결 가중치
Whh = 은닉 계층의 피드백 연결에 대한 가중치
Why = 은닉 계층과 출력 계층을 연결하는 가중치
one to many : 이미지를 입력하면 이미지에 대한 설명을 출력하는 image-captioning 모델 , 하나의 음표를 입력하면 음악을 만들어 내는 음악생성 모델, 분자구조 이미지를 입력하면 smiles 분자식을 내뱉는 모델 등
many to one : 트위터나, 구매평 등을 입력하여 긍정, 부정을 분류하는 감성분석, 이전 주가 및 외부정보를 활용한 특정 시점의 주식 가격 예측 등
many to many: 한국어 문장을 영어 문장으로 번역하는 기계번역 모델 , 어떤 단어를 보고 그 단어가 어떤 유형인지를 인식하는 개체명 인식 모델
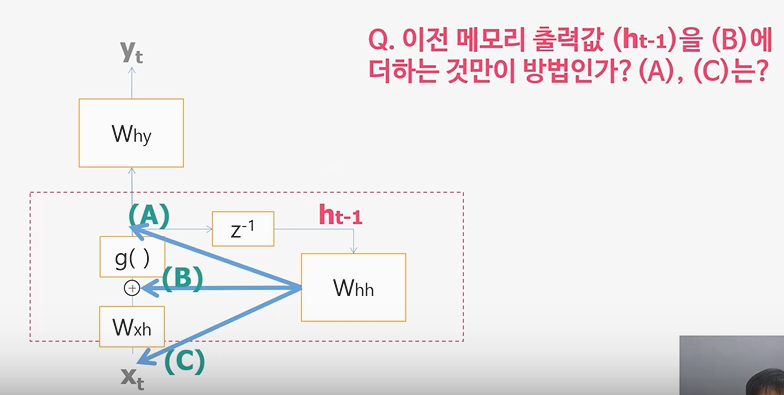
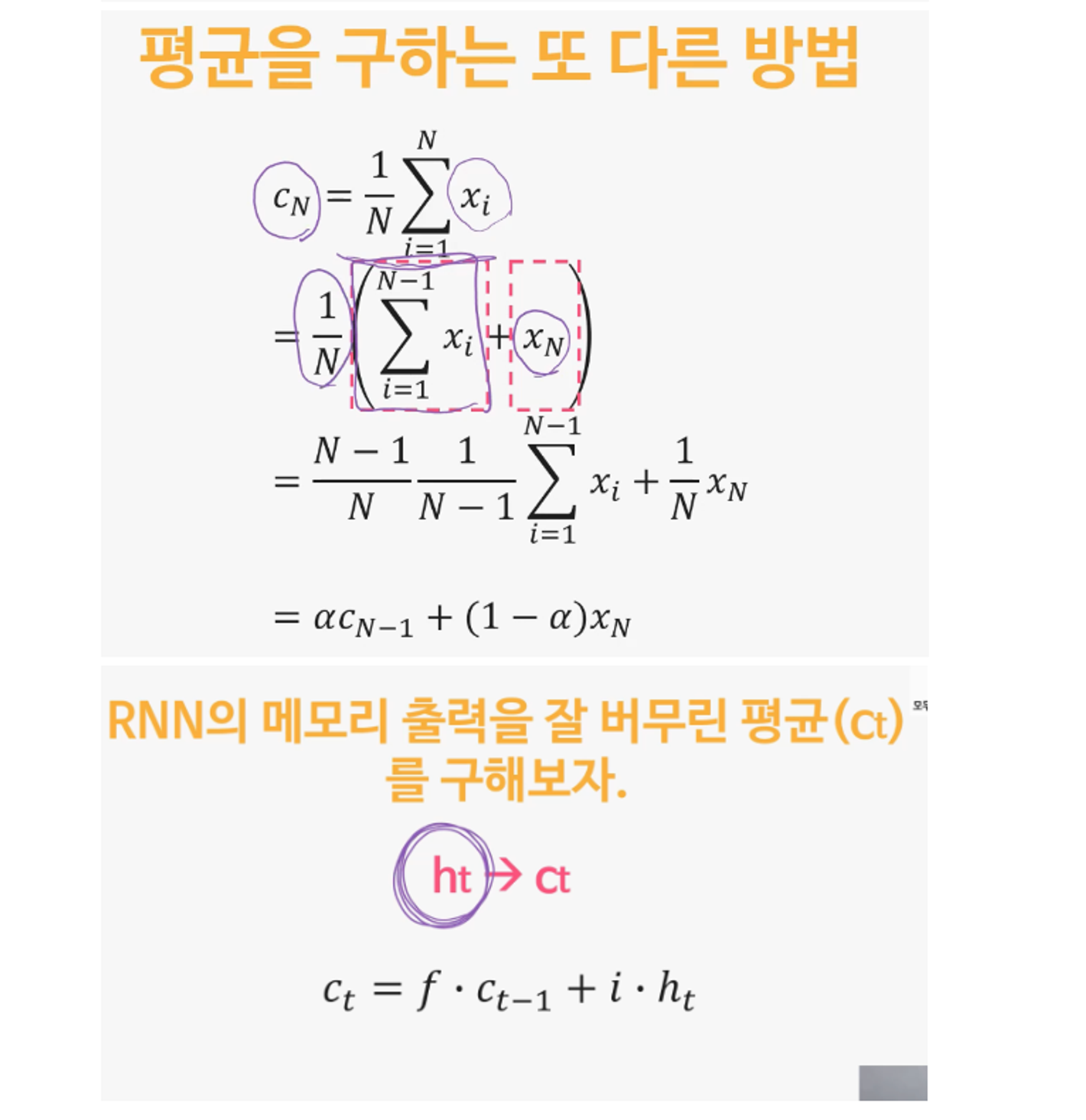
Q. 노래 한곡과 같은 긴 Sequence를 모두 neural network에 입력으로 넣어주게 되면 네트워크 사이즈가 너무 커지게 됩니다. RNN은 어떤 방법을 이용하여 입력사이즈를 일정하게 유지하고 과거의 입력값들을 반영할 수 있게 하나요?
A. RNN은 Sequence를 모두 입력으로 주지 않고
'잘 저장해 놓을 수 있는 메모리(Neural Memory)' h를 새로 만든 후에
이것 만을 네트워크의 입력으로 준다.

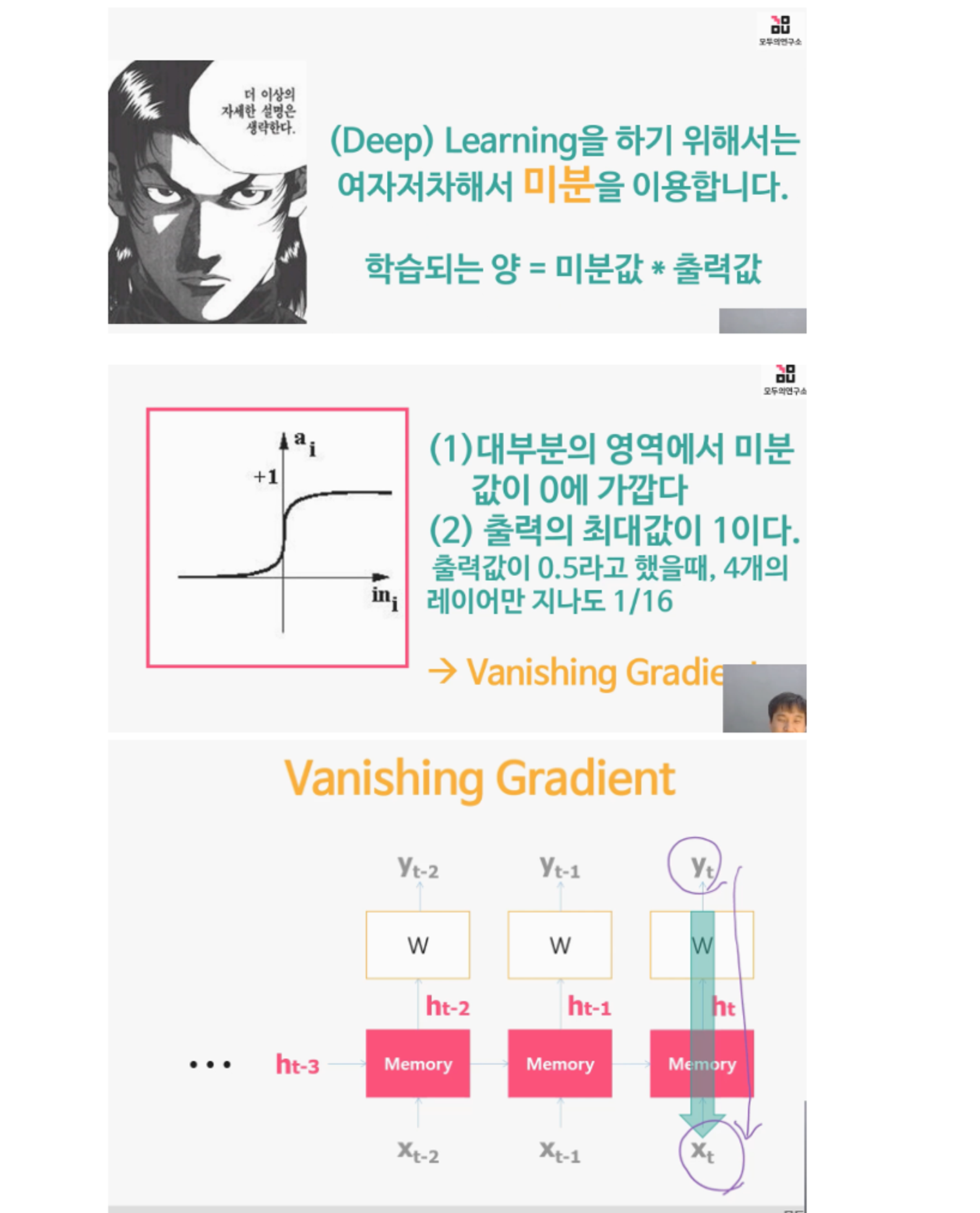
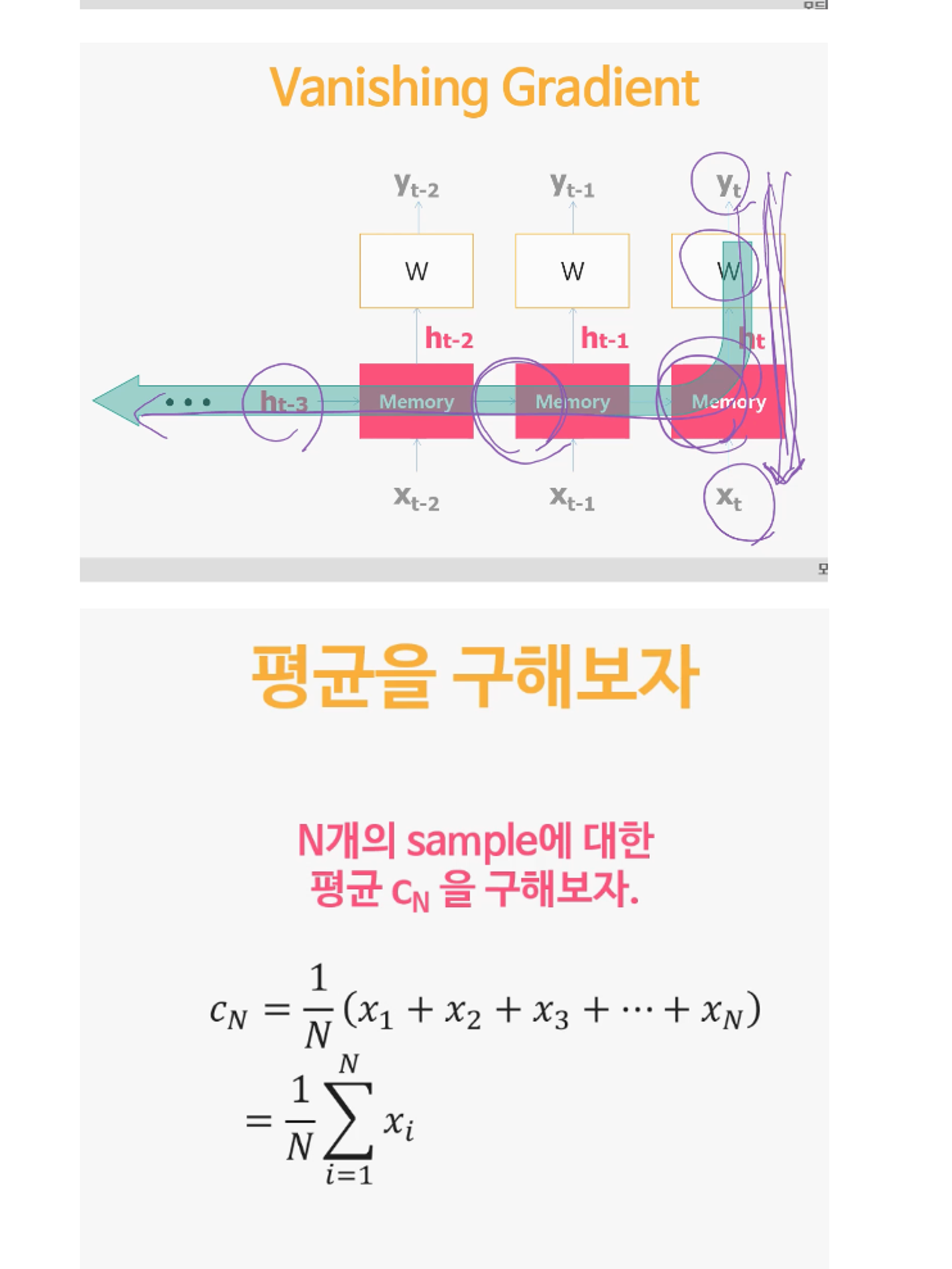

RNN의 문제
: vanishing gradient problem (경사소멸문제)
: 장기 기억 불가능
어떤 문제냐
신경망(딥러닝)에서 발생하는 "vanishing gradient problem(소멸하는 기울기 문제)" 은 역전파 알고리즘에서 일어나는 현상입니다. 이 문제는 심층 신경망이 깊어질수록 역전파 과정에서 기울기가 사라져서(소멸하여) 하위 레이어로 전파되지 않는 문제를 가리킵니다.
언제 발생하냐
기울기는 역전파 알고리즘에서 출력층에서 입력층으로 오차를 다시 전파할 때 사용됩니다. 그러나 네트워크가 깊어질수록 역전파 과정에서 기울기가 너무 작아지거나 사라지는 경우가 발생합니다. 이는 특히 활성화 함수의 미분 값이 0에 가까운 경우에 발생할 수 있습니다.
이 문제는 특히 "Sigmoid" 나 "Tanh" 와 같은 활성화 함수를 사용하고, 매우 깊은 신경망을 구축할 때 더 자주 발생합니다. 이 함수들의 미분 값이 특정 범위에서 매우 작기 때문에, 그래디언트가 하위 레이어로 전파되지 않고 소멸하는 문제가 발생할 수 있습니다.
해결법
이를 해결하기 위해 ReLU(Rectified Linear Unit) 와 같은 활성화 함수들이 도입되었습니다. ReLU는 미분 가능하면서도 기울기가 0보다 작아지는 문제를 해결 하여, 기울기 소멸 문제를 완화하는 데 도움을 줍니다. 또한, 초기화 방법, 배치 정규화(Batch Normalization) 등의 기술도 기울기 소멸 문제를 완화하는 데 도움이 됩니다.
LSTM
바닐라 RNN(기본 RNN은 이전 시간 단계의 출력을 현재 시간 단계의 입력으로 사용하여 순차적인 데이터를 처리하는 모델로 (이전 정보를 현재 상태에 반영함으로써) 시간적인 의존성을 학습)
의 한계를 극복하기 위해 등장한
LSTM(Long Short-Term Memory, 장단기 메모리)
중요하지 않은건 잊고, 중요한건 기억한다!
기억 셀이라는 것을 추가해서 경사소멸문제 해결
기본 형태의 RNN은 순환(recurrent) 의 구조로 순서가 있는 데이터, 시계열 데이터 등을 처리할 수 있지만
은닉층(layer)이 많아질수록 기울기가 상실되는 문제가 발생하여 정확한 출력값을 도출하지 못하는 문제가 발생합니다.
이를 보완하기 위해 등장한 딥러닝 알고리즘이 바로 LSTM(Long Short-Term Memory) 입니다.
LSTM(Long Short-Term Memory)이 vanishing gradient 문제에 강한 주요 이유는 그 구조가 오래된 시그널을 장시간 동안 유지할 수 있도록 설계되었기 때문입니다. LSTM은 cell state라는 컨셉을 도입하여, 정보를 장기간 동안 기억하고 전달하는 데 사용합니다.
LSTM의 cell state는 네트워크를 통해 직선적인 경로로 전달되며, 게이트들을 통해 정보를 업데이트합니다. 이러한 구조는 gradient가 효과적으로 역전파되게 하여 학습 과정에서 gradient가 급격히 감소하는 vanishing gradient 문제를 완화합니다.
더 구체적으로, LSTM의 핵심은 forget gate와 input gate입니다. forget gate는 어떤 정보를 잊을 것인지 결정하고, input gate는 새로운 정보를 얼마나 받아들일 것인지 결정합니다. 이 두 게이트는 sigmoid 함수를 통해 0과 1 사이의 값을 출력하여, 각각의 정보가 얼마나 cell state에 영향을 미칠지를 결정합니다. 이를 통해 LSTM은 기울기 소실 문제 없이 장기 의존성을 학습할 수 있습니다.
Q. LSTM의 Input Gate와 Forget Gate에서는 왜 relu를 쓰지 않고 sigmoid activation function을 사용할까요?
게이트에서 필요한 것은 정보의 흐름을 제어하는 것이기 때문에 0과 1 사이의 값으로 조절하는 시그모이드 함수가 더 적합
α와 1-α 가 0~1 사이의 값 이여야 한다는 사실을 만족 시키기 위해서 입니다. sigmoid함수의 출력은 항상 0~1사이의 값을 가지기 때문에 이를 만족시킵니다.
Q. LSTM이 vanishing gradient problem(경사소멸문제)에 강한 이유는 무엇인가요
곱셈이 아니라 덧셈이기 때문에 그 어떤? 영향이 줄어들기 떄문에
vanishing gradient problem을 확실히 줄여나갈 수 있다.
LSTM(Long Short-Term Memory)은 RNN(Recurrent Neural Network)의 한 종류로, 장기 의존성 문제와 vanishing gradient 문제를 완화하는 데 도움이 되는 몇 가지 메커니즘을 도입했습니다. 이러한 메커니즘들은 LSTM을 vanishing gradient 문제에 더 강하게 만드는 데 도움이 됩니다.
LSTM 메커니즘
게이트 메커니즘(Gate Mechanism):
LSTM은 게이트라고 불리는 요소들을 사용하여 정보의 흐름을 조절합니다. 이 게이트들은 시그모이드 활성화 함수를 사용하여 정보의 흐름을 0과 1 사이로 조절하며, 이를 통해 역전파 과정에서 기울기가 소멸되는 것을 방지합니다. Forget 게이트와 Input 게이트는 정보를 선택적으로 보존하거나 업데이트함으로써 장기적인 의존성을 유지하면서도 gradient가 소실되는 것을 방지합니다.
Long-Term Memory Cells (장기 기억 셀):
LSTM은 장기적인 의존성을 관리하기 위해 기존 RNN보다 더 긴 기억을 유지할 수 있는 메커니즘을 가지고 있습니다. 이 메커니즘은 게이트들을 사용하여 장기적인 의존성을 필요한 만큼 유지하고 기존 정보를 잊지 않고 저장할 수 있도록 도와줍니다.
LSTM 셀의 구조:
LSTM은 기본적으로 입력, 출력 및 장기 상태(long-term state)로 구성되어 있습니다. 이 구조는 정보를 업데이트하고 보존하는 데 도움이 되며, vanishing gradient 문제를 완화하는 데 기여합니다.
이러한 메커니즘들은 LSTM이 장기적인 의존성을 관리하면서도 역전파 과정에서 기울기 소실 문제를 완화하는 데 도움이 되는 것으로 알려져 있습니다. 이는 LSTM이 더 긴 시퀀스를 처리하고 시간에 따라 정보를 보존할 수 있게 도와줍니다.
LSTM 게이트 종류
LSTM(Long Short-Term Memory)은 순환 신경망(RNN)의 한 종류로, 시퀀스 데이터의 장기 의존성을 관리하기 위해 설계되었습니다. LSTM은 기억을 관리하기 위해 여러 게이트(gate)를 사용하는데, 이 게이트들은 정보를 조절하고 제어하는 역할을 합니다.
Forget Gate (잊어버리기 게이트):
Forget 게이트는 이전 상태의 정보 중에서 어떤 정보를 잊을지를 결정합니다. 이전 상태의 정보와 현재 입력에 기반하여 어떤 정보를 보존할지를 결정합니다. 이 게이트는 시그모이드 활성화 함수를 사용하여 0과 1 사이의 값을 출력하여 각 정보의 중요도를 결정합니다. 1에 가까울수록 정보를 보존하고, 0에 가까울수록 해당 정보를 잊게 됩니다.
Input Gate (입력 게이트):
Input 게이트는 새로운 정보를 받아들일 비율을 결정합니다. 새로운 정보가 이전 상태의 정보에 얼마나 추가될지를 제어합니다. 이 게이트는 시그모이드 활성화 함수와 tanh 활성화 함수를 사용하여 두 가지 결정을 내립니다. 시그모이드는 어떤 정보를 업데이트할지를 결정하고, tanh는 업데이트할 정보의 양을 결정합니다.
LSTM에서 왜 시그모이드 활성화 함수가 사용되는가에 대한 이유는 게이트의 출력을 0과 1 사이로 제한하여 정보를 관리하고 조절하기 위함입니다. 시그모이드 함수는 출력값을 0과 1 사이의 값으로 조정하여 게이트가 특정 정보를 얼마나 통과시킬지를 결정할 수 있도록 합니다.
ReLU(Rectified Linear Unit)은 0보다 작은 값을 0으로 처리하는 함수이며, 이러한 비선형성으로 인해 LSTM 게이트에서 사용되지 않습니다. 게이트에서 필요한 것은 정보의 흐름을 제어하는 것이기 때문에 0과 1 사이의 값으로 조절하는 시그모이드 함수가 더 적합합니다.
RNN의 종류
기본적인 RNN(Recurrent Neural Network):
RNN은 순차적 데이터 처리에 주로 사용됩니다. 이전 단계의 출력이 다음 단계의 입력으로 사용됩니다. 하지만 장기 의존성 문제로 인해 멀리 떨어진 정보를 잘 기억하지 못하는 문제가 있습니다.
LSTM(Long Short-Term Memory):
LSTM은 RNN의 한 종류로, 기본 RNN의 장기 의존성 문제를 해결하기 위해 고안되었습니다. 기억 게이트와 삭제 게이트 등의 매커니즘을 사용하여 긴 시퀀스에서 정보를 더 오래 유지할 수 있도록 도와줍니다.
GRU(Gated Recurrent Unit):
GRU도 LSTM과 마찬가지로 장기 의존성 문제를 해결하기 위한 RNN의 변형입니다. LSTM보다 더 간단한 구조를 가지고 있으며, 리셋 게이트와 업데이트 게이트를 사용하여 정보를 제어합니다.
Bidirectional RNN:
양방향 RNN은 입력 시퀀스를 앞뒤 양쪽 방향으로 처리하여 미래와 과거의 정보 모두를 활용하는 모델입니다. 이는 감정 분석이나 기계 번역과 같이 문맥을 이해해야 하는 작업에 유용합니다.
