기존의 룰베이스 방식은 사람이 직접 규칙정의 후 판단을 내리지만
머신러닝은
AI > 머신러닝 > 딥러닝
머신러닝 > (1) 지도 학습 (분류, 회귀(예측))
(2) 비지도 학습 (군집화, 차원축소)
(3) 강화 학습
- 지도학습
정답이 있는 데이터를 가지고 학습을 해서 예측 - 비지도학습
정답이 없는 데이터로 예측 - 강화학습
알파고의 사례처럼, 환경을 만들어주고 그 환경 속에서 보상을 통해서 학습해 나가는 과정
분류는 사과와 딸기로 카테고리화 (분류) 하는 것을 뜻함
회귀는 연속된 값(집값, 수요)을 예측하는 것을 뜻함
회귀(regression, 지도학습)
과소적합(underfitting), 과대적합(overfitting) 되지 않고
최적의 회귀모델 머신러닝을 찾아야 한다.
- underfitting: 데이터가 작을 때 이런 현상들이 많이 벌어진다.
- overfitting: 현재 데이터에 너무 최적화되어 있어서 새로운 데이터가 들어왔을 때 예측 성능이 떨어지는 것을 말한다.
머신러닝 프로세스
1단계 문제 정의
무엇을 예측할지 문제를 정의하여
분류인지 회귀인지 (e.g. 마감여부는 분류(정확도), 신청인원 예측은 회귀)
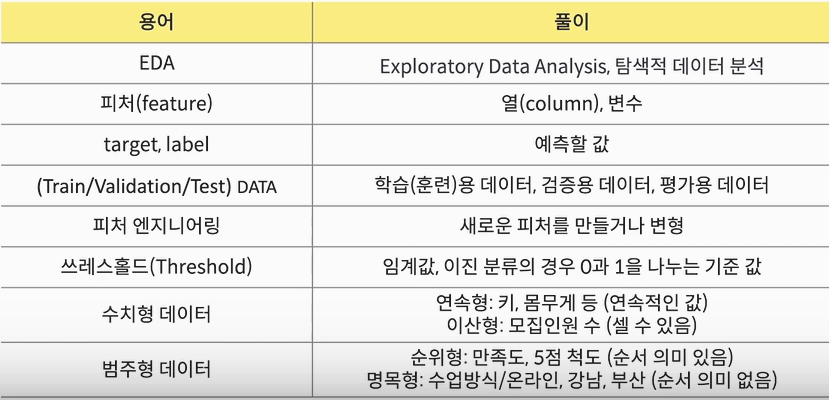
2단계 탐색적 데이터 분석(EDA)
1) 데이터 크기(컬럼의 수)
2) 결측치(너무많으면 채우거나 삭제)
분류(target or label 비율이 50:50이면 좋은 모델이 만들어 짐)
*이때 target/label은 마감 여부가 될 수 있음
3) 컬럼(피처) 타입 (강좌명, 요일, 시간대, 수준, 기수 등등)
4) 수치형(숫자: 기수)/범주형(카테고리: 온/오프라인) 데이터 등
3단계 데이터 전처리
1) 데이터를 판단하여 결측치 및 이상치 처리
- 이상치 처리시: IQR(3Q-1Q = 75%-25%) 구한 후
3Q+1.5IQR 이상 , 1Q-1.5IQR 이하를 이상치 라고 함
(단, 데이터마다 이상치는 달라질 수 있으므로 눈으로 확인해보는 작업 필수)
2) 수치형(numerical) 데이터의 전처리
(4단계 모델학습하기 전에는 모든 데이터를 수치화 해주어야 한다)
(수치형 데이터라고 하더라도 모델학습에 용이한 데이터로 변경작업 필요)
- 민맥스 스케일(min-max scaling)
: 최저값을0, 최고값을1 로 변환시키는 것 (즉, 모든 값이 0~1 사이로 분포)
3) 범주형(categorical) 데이터의 전처리
컬럼삭제 or 변환 필수
e.g.
(i) 레이블 인코딩 : 온/오프라인 여부를 1,2,3 등으로 변환
(ii) 원핫 인코딩 : 카테고리 수만큼 컬럼을 만들어 0,1 두 개로만 표현
4단계 모델학습
1) Train(학습용) / Validation(검증용) 데이터 분리 (7:3~8:2 비율로)
2) (분류/회귀 모델여부에 따라) 머신러닝 모델 선택
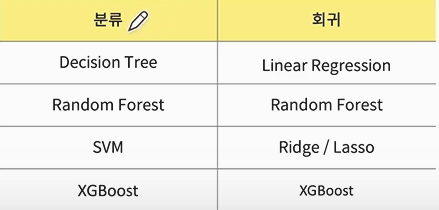
분류모델
(1) Decision Tree
(2) Random Forest
(3) SVM
(4) XGBoost
회귀모델
(1) Linear Regression
(2) Random Forest
(3) Ridge / Lasso
(4) XGBoost
[사이킷런]
model = 모델선택
model.fit()
model.predict()
(3) Train 데이터로 학습(훈련)
(4) Validation(검증용) 데이터로 예측
*평가 후 성능이 좋지 않으면 모델 변경을 하고 2단계부터 다시 진행
5단계 예측
4단계까지 작업한 알고리즘을 가지고 테스트 데이터를 적용해 예측