데이터 불러오기/만들기
데이터 불러올 때
pd.read_csv('new_modudak.csv')
기존의 인덱스명을 살릴 때
pd.read_csv('new_modudak.csv', index_col='Unnamed: 0')
# '노드2. 데이터 핸들링1'에서 마지막에 만든 new_modudak.csv 다시 만들기
import pandas as pd
import numpy as np
df = pd.DataFrame({
'Unnamed: 0': [0,1,2,3,4,5,6,'new',10],
'메뉴': ['황금후라이드','승일양념치킨','간장치킨','마늘치킨','파닭','닭강정','양념반후라이드반','[인기]아이펠치킨','[베스트]풀잎치킨'],
'가격': [12000,13000,14000,14000,14000,15000,13000,16000,9900],
'호수' : ['10호','10호','9호','9호','11호','12호','10호','11호','10호'],
'칼로리' : [1000.0,1400.0,1600.0,1800.0,1300.0,1500.0,1300.0,1200.0,np.nan],
'할인율' : [0.2,0.2,0.2,0.2,0.2,0.2,0.2,0.5,np.nan],
'할인가' : [9600.0,10400.0,11200.0,11200.0,11200.0,12000.0,10400.0,8000.0,np.nan],
'원산지' : ['국내산',np.nan,np.nan,np.nan,'브라질','브라질',np.nan,'국내산',np.nan]
})
df.to_csv('new_modudak.csv', index=False)
df
# 데이터 불러오기 (index_col 파라미터로 인덱스 column 지정)
pd.read_csv('new_modudak.csv', index_col='Unnamed: 0')데이터(행/열) 삭제
1. 데이터 프레임의 사본 만들기
변수 = df.copy()
2. 데이터 삭제 방향
axis=0:행방향
axis=1:열방향(컬럼)
3. 데이터 열 삭제
data = data.drop('Unnamed: 0', axis=1)
data = data.drop(columns=['Unnamed: 0'])
4. 데이터 행 삭제
data = data.drop(인덱스명, axis=0)
data.drop(인덱스명, axis=0, inplace=True)
in-place(제자리 연산)
Inplace는 아직 가동은 하지 않고 제자리에서 준비만 하는 것을 의미하는데
이것을 가동시키기 위해서는 inplace=True로 바꿔 주면 됩니다.
inplace=False : 저장 안 함. inplace=True : 저장함.
(Inplace는 열 삭제(axis=1)일 때도 사용 가능합니다.)
컬럼(열) 삭제
# 데이터프레임 복사
data = df.copy()
data
# 데이터 삭제 (컬럼(열): Unnamed: 0') drop(axis=1)
# axis=1:열방향(컬럼) / axis=0:행방향
data = data.drop('Unnamed: 0', axis=1)
data
# 데이터 삭제 (컬럼(열): Unnamed: 0') drop(columns=[])
data = df.copy()
data = data.drop(columns=['Unnamed: 0'])
data
# 데이터 복사(data -> df)
df = data.copy()
df
행 삭제
# 행 삭제 (파닭: 인덱스4, 행표기)
data = data.drop(4,axis=0)
data
# 행 삭제 (양반후반: 인덱스6, inplace=True <-이거 쓰면 대입 필요 X)
data.drop(6,axis=0, inplace=True)
data
# 행 삭제 (조건: 가격 >= 14000)
cond = data['가격'] >= 14000
data[cond].index
# 행 삭제 (해당 인덱스 명)
data.drop(data[cond].index, axis=0, inplace=True)
dataQ. 다음 df 변수의 데이터에서 'Unnamed: 0' 컬럼을 삭제하고, 가격이 15000이상인 메뉴를 삭제해주세요.
df = pd.read_csv('new_modudak.csv')
data = df.drop('Unnamed: 0', axis=1)
cond = data['가격'] >= 15000
data.drop(data[cond].index, axis=0, inplace=True)
data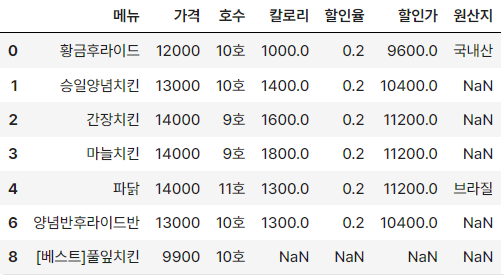
결측지 처리
1. 결측치가 있는 행 삭제
data.dropna(axis=0)
2. 결측치가 있는 열(컬럼) 삭제
data.dropna(axis=1)
3. 결측치가 있는 열(컬럼) 확인
df.isnull()
True = 결측치가 맞다.
False=결측치가 아니다.
4. 결측치가 있는 열(컬럼) 합계
df.isnull().sum()
True = 1로 계산
False= 0로 계산
5. 결측값 채우기
df['결측치가 있는 컬럼명'].fillna('결측값에 채울 값')
결측치 삭제
# 데이터프레임 복사
data = df.copy()
data
# 결측치가 있는 행 모두 삭제
data.dropna(axis=0)
# 결측치가 있는 컬럼 모두 삭제
data.dropna(axis=1)결측치 채우기
# 컬럼별 결측치 확인
df.isnull() # 갯수 확인
df.isnull().sum() # T/F 로 위치 확인
# 결측값 채우기
# 원산지 -> '알수없음'으로 채우기
df['원산지'].fillna('알수없음')
# 원산지 최빈값으로 채우기
df['원산지'].fillna('국내산')
# 원산지 채우기 실행
df['원산지'] = df['원산지'].fillna('국내산')
df
#칼로리 컬럼 결측치에 최소값 결측치 채우기
df['칼로리'].fillna(df['칼로리'].min())정렬
1. 인덱스 오름차순 기준
오름차순 : 작은 값에서 뒤로 갈수록 값이 커짐
df.sort_index()
df.sort_index(ascending=True)
2. 인덱스 내림차순 기준
내림차순 : 큰값에서 뒤로 갈수록 값이 작아짐
df.sort_index(ascending=False)
3. 기준이 1개일때 정렬
df.sort_values('컬럼명', ascending=False)
4. 기준이 다중일때 정렬
기준을 리스트 형태로 넣어준다.
df = df.sort_values(['컬럼명1', '컬럼명2'] , ascending=[False, True])
5. 인덱스 새로 만들기
정렬후 엉망이된 인덱스 값 수정하기
df.reset_index() # 기존 index 값 유지
df.reset_index(drop=True) # 기존 index 값 삭제
# 데이터 확인
df
# 인덱스 기준 (기본값 ascending=True) : df.sort_index()
df.sort_index(ascending=False)
# 값 기준 (기본값 ascending=True)
# 가격 기준 정렬
df.sort_values('가격', ascending=False)
# 가격과 원산지 기준 정렬
df = df.sort_values(['가격', '원산지'], ascending=[False, True])
df
# 인덱스 새로 만들기 drop=True
df = df.reset_index(drop=True)
df자료형 변환
1. type확인
• df.info()
2. object(문자열)을 int64(정수) 으로 변경하기
• df['컬럼명'] = df['컬럼명'].str.replace('변경전 문자열' , '')
• replace는 문자열에 변경할 문자열을 입력하지 않을 경우 문자열을 삭제한다.
• df['컬럼명'] = df['컬럼명'].astype(int)
[리마인드]replace
• 문자열을 변경하는 함수이다.
• df = df.replace('변경전 메뉴명', '변경후 메뉴명')
판다스
-object(문자열) : 예) '호수'
-int64(정수) : 예) 10
-float64(실수) : 예) 12.12
파이썬
-string(문자열) : 예) '호수'
-int(정수) : 예) 10
-float(실수) : 예) 12.12
# type확인
df.info()
# 호 단어 삭제(str, replace 활용)
df['호수'] = df['호수'].str.replace('호','')
df
# 자료형 변환 / astype / object -> int
df['호수'] = df['호수'].astype(int)
df['호수']
# 자료형 확인
df.info()
# 호수 평균
df['호수'].mean()
# 호수 표준편차
df['호수'].std()데이터 탐색
1. 데이터 프레임 크기 (row, column)
괄호 없음에 유의
df.shape
2. 데이터 샘플 확인 (head)
df.head()
3. 컬럼 형태 (type)
df.info()
4. 기초 통계
• 숫자 타입만 확인 할 수 있다.
df.describe()
5. 기초 통계 (object(문자열))
• 문자 타입만 확인 할 수 있다.
df.describe(include='O') # 대문자 O 사용에 유의
6. 상관관계
df.corr()
7. 항목 종류 수
- 각 몇 가지씩 있는지
df.nunique()
8. 항목 종류
df['컬럼명'].unique()
9. 항목별 개수
• 카운트까지 같이 보여주므로 추천
df['컬럼명'].value_counts()
내장함수
1. 컬럼 기준 데이터의 숫자 세기
-결측치가 있는 데이터는 카운터 함수에서는 체크 되지 않는다.
df.count() # 기본값 : axis=0
예 : 할인율 컬럼을 기준으로 행단위로 카운트를 진행할때 NaN의 결측치 1개를 제외하여 count 값은 8이다.
예 : 할인가 컬럼을 기준으로 행단위로 카운트를 진행할때 NaN의 결측치 1개를 제외하여 count 값은 8이다.
2. 행 기준으로 데이터 숫자 세기
-결측치가 있는 데이터는 카운터 함수에서는 체크 되지 않는다.
df.count(axis=1)
예: 인덱스 1 행을 열단위로 카운트를 진행할때 NaN의 결측치 1개를 제외하여 count 값은 7이다.
예: 인덱스 8 행을 열단위로 카운트를 진행할때 NaN의 결측치 2개를 제외하여 count 값은 5이다.
3. 데이터수 확인
len(df) # 행의 개수
df.shape # 행, 열
df.shape[0] # 행:0 , 열:1
*행의 개수, 또는 열의 개수만 찾을 때는 대괄호[ ] 사용
4. 다양한 내장함수
• 최대값 확인: df['컬럼명'].max()
• 최소값 확인: df['컬럼명'].min()
• 평균 확인 : df['컬럼명'].mean()
• 중앙 값 확인 : df['컬럼명'].median()
• 합계 확인 : df['컬럼명'].sum()
• 표준편차 확인 : df['컬럼명'].std()
• 분산 확인 : df['컬럼명'].var()
• 백분위수 확인 : df['가격'].describe()
*describe : 데이터 컬럼별 통계량을 요약하는 메서드
5. 하위 25% 지점 확인
• df['컬럼명'].quantile(.25)
0.25에서 .25만 써도 되고, 0은 생략 가능
• 판다스의 quantile는 0과 1사이의 값을 입력한다.
• quantile(사분위수)는 데이터 분포의 작은 수부터 큰수로 나열하여 4등분하는 관측값이다.
6. 상위 25% 지점 확인
• 상위 max 기준으로 25%인 75% 지점인 14000.0를 입력한다.
• df['컬럼명'].quantile(.75)
7. 하위 25% 작은 데이터 확인
• cond = df['컬럼명'].quantile(.25) > df['컬럼명']
• df[cond]
8. 상위 25% 큰 데이터 확인
• cond = df['컬럼명'].quantile(.75) < df['컬럼명']
• df[cond]
9. 특정 컬럼 최빈값 구하기
• df['컬럼명'].mode()[0]*첫번째 값 0
10.행과 열 바꾸기 (transpose)
• df.T
그룹핑
1. 1개 컬럼 기준, 평균값 확인
• df.groupby('기준 컬럼명').mean()
2. 다수 컬럼 기준, 평균값 확인
• df.groupby(['기준 컬럼명1', '기준 컬럼명 2']).mean()
3. 원산지와 할인율 기준, 가격 평균 ->[시리즈 형태]
• df.groupby(['기준 컬럼명1', '기준 컬럼명2'])['구하려는 컬럼'].mean()
4. 원산지와 할인율 기준, 가격 평균 ->[데이터프레임 형태1]
• pd.DataFrame(df.groupby(['기준 컬럼명1', '기준 컬럼명2'])['구하려는 컬럼'].mean())
5.원산지와 할인율 기준, 가격 평균 ->[데이터프레임 형태2]
• df.groupby(['기준 컬럼명1', '기준 컬럼명2'])[['구하려는 컬럼']].mean()
6. 원산지와 할인율 기준 최대값 확인
• df.groupby(['기준 컬럼명1', '기준 컬럼명2']).max()
7. 1개의 인덱스 형태로 리셋
• df.groupby(['기준 컬럼명1', '기준 컬럼명2']).max().reset_index()
apply 함수
1. apply() 메서드
-판다스 객체(pandas.DataFame.apply, pandas.Series.apply)에 열 혹은 행에 대해 함수를 적용
2.람다(Lambda) 표현식
-람다 표현식은 (때로 람다 형식(lambda forms)이라고 불립니다) 이름 없는 함수를 만드는 데 사용
# 데이터 확인
df
# apply 예시 (칼로리가 1300 보다 큰 값과 작은 값)
def cal(x):
if x >= 1300:
return "yes"
else:
return "no"
df['칼로리'].apply(cal)
# apply 적용해서 새로운 컬럼 생성 (칼로리 컬럼 활용)
df['살찔까요'] = df['칼로리'].apply(cal)
df
# lambda, apply 활용
df['고민'] = df['칼로리'].apply(lambda x: '먹지말자' if x >= 1300 else '무조건먹자')
df
# df 저장 (final_modudak.csv)
df.to_csv('final_modudak.csv', index=False)
pd.read_csv('final_modudak.csv')
