재현율(Recall)이 중요한 예시:
의료 진단 - 감염병 탐지:
상황: 감염병 진단 모델
설명: 재현율이 중요한 경우, 거짓 음성(FN)을 최소화하여 실제 감염된 환자를 놓치지 않고 적극적으로 식별하고자 함.
화재 예측:
상황: 화재 발생 예측 모델
설명: 재현율이 중요한 경우, 거짓 음성(FN)을 최소화하여 실제로 화재가 발생할 경우를 미리 감지하고자 함. 화재를 빠르게 예측하여 조치를 취하는 것이 중요.
긴급 상황 문자 알림:
상황: 긴급 상황 문자 알림 시스템
설명: 재현율이 중요한 경우, 거짓 음성(FN)을 최소화하여 실제로 긴급 상황이 발생했을 때 빠르게 경고 메시지를 보내고자 함. 사용자의 안전을 최우선으로 고려.
- 정밀도: 아닌걸 맞다고 예측할때 문제가 되는 케이스
Positive 예측 정확도에 중점을 둔다!- 재현율 : 맞는걸 아니라고 예측하면 문제가 발생하는 케이스
평가 (분류 모델)
정확도 accuracy:
실제 값과 예측값이 일치하는 비율
(올바른 예측 수) / (전체 예측 수)
의사가 모든 환자들을 진단하고 정확하게 암 환자와 정상 환자를 구분한 비율이야. 예를 들어 100명의 환자 중 90명을 정확하게 분류했다면 정확도는 90%가 되겠지.
정밀도 precision:
모델이 양성으로 예측한 것 중에서 실제로 양성인 비율을 의미합니다.
정밀도는 거짓 양성(FP)을 줄이는 것에 초점을 맞춥니다.
양성이라고 예측한 값 중 실제 양성인 값의 비율 (암이라고 예측 한 값 중 실제 암)
의사가 암이라고 진단한 환자 중 실제로 암인 환자들의 비율이야. 만약 의사가 20명을 암 환자로 진단했는데, 실제로 15명만 암 환자였다면, 정밀도는 15/20, 즉 75%가 될 거야.
재현율 recall:
실제 양성 중에서 모델이 양성으로 예측한 것의 비율을 말합니다.
재현율은 거짓 음성(FN)을 줄이는 것에 초점을 맞춥니다.
실제 양성 값 중 양성으로 예측한 값의 비율 (암을 암이라고 판단)
(True Positives) / (True Positives + False Negatives)
실제로 암인 환자 중에서 의사가 암이라고 정확하게 예측한 비율이야. 예를 들어 100명 중에서 30명이 암인데, 의사가 25명을 암 환자로 진단했다면, 재현율은 25/30, 약 83%가 될 거야.
F1:
분류 모델의 평가 지표 중 하나로, 정밀도(precision)와 재현율(recall)의 조화평균
불균형한 클래스 크기나 데이터 불균형 상황에서 모델의 성능을 정확하게 평가하는 데 유용합니다.
높은 F1 점수는 정확도와 재현율이 모두 높은 경우를 의미하며, 이는 모델이 양성 클래스를 정확하게 식별하면서도 거짓 양성과 거짓 음성을 최소화한다는 것을 나타냅니다.
(True Positives) / (True Positives + False Positives)
F1 점수는 정밀도와 재현율의 조화 평균이라고 했지? 이를 통해 정밀도와 재현율이 균형있게 잘 수행되고 있는지를 보여줘.
F1 점수 = 2 (정밀도 재현율) / (정밀도 + 재현율)
장점: F1 점수는 불균형한 클래스 분포에서도 모델의 성능을 잘 측정할 수 있습니다. 클래스 간의 밸런스를 고려하여 정밀도와 재현율을 동시에 고려하기 때문입니다.
F1 적용사례)
신용카드 정상거래는 차단하고 사기거래는 허용하는 신용카드 거래에 대한 사기탐지시스템을 만들때 사용하면 효과적!
===> precision, recall 사이에서 적절한 절충점을 찾아서 각각의 False 결과값을 최소화하도록 만든다
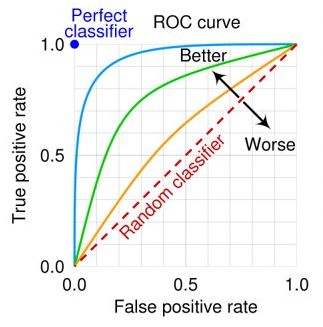
ROC-AUC
ROC: 참 양성 비율(True Positive Rate)에 대한 거짓 양성 비율(False Positive Rate) 곡선
AUC: ROC곡선 면적 아래 (완벽하게 분류되면 AUC가 1임)
# 정확도
from sklearn.metrics import accuracy_score
accuracy_score(y_test, pred)
# 정밀도
from sklearn.metrics import precision_score
precision_score(y_test, pred)
# 재현율
from sklearn.metrics import recall_score
recall_score(y_test, pred)
# f1
from sklearn.metrics import f1_score
f1_score(y_test, pred)
# roc_auc
from sklearn.metrics import roc_auc_score
model = XGBClassifier(random_state=0, use_label_encoder=False, eval_metric='logloss')
model.fit(X_train, y_train)
pred = model.predict_proba(X_test)
roc_auc_score(y_test, pred[:,1])정확도(accuracy) = (TP + TN) / (TP + FP + FN + TN)
정밀도(precision) = TP / (TP + FP)
재현율(recall) = TP / (TP + FN)
F1 = 2 (정밀도 재현율) / (정밀도 + 재현율)
랜덤 포레스트(Random Forest):
복잡한 전처리가 필요 없는 경우: 랜덤 포레스트는 결측치나 이상치에 대해 강건하며, 데이터의 스케일링이나 정규화가 필요 없습니다.
모델의 설명력이 중요한 경우: 랜덤 포레스트는 특성 중요도를 제공하므로, 어떤 특성이 예측에 큰 영향을 미치는지 파악하기 쉽습니다.
과적합을 피하고 싶은 경우: 랜덤 포레스트는 여러 개의 의사결정나무를 조합하여 과적합을 줄이고, 안정적인 예측 성능을 제공합니다.
의료: 병의 진단, 환자의 재입원 가능성 예측 등에 사용됩니다.
금융: 부도 예측, 신용 점수 예측 등에 활용됩니다.
생태학: 종의 분포 예측, 다양한 환경 요인에 따른 생태계 변화 예측 등에 사용됩니다.
XGBoost:
추천 시스템: 사용자의 선호도를 예측하여 개인화된 추천을 제공하는데 사용됩니다.
생물학: 유전자 표현의 패턴을 분석하여 병의 원인을 찾는데 활용됩니다.
경제: 경제 지표 예측, 주가 예측 등에 사용됩니다.
이와 같이 랜덤 포레스트와 XGBoost는 예측력이 중요한 많은 문제에서 활용됩니다. 그러나 이들 알고리즘은 모든 문제에 대한 최적의 해결책이 아니며, 각 문제의 특성에 따라 적절한 모델과 파라미터를 선택해야 합니다.
XGBoost:
높은 예측 성능이 필요한 경우: XGBoost는 Gradient Boosting 알고리즘을 최적화하여 높은 예측 성능을 보여줍니다. 따라서, 성능이 우선적인 경우에 사용하면 좋습니다.
적은 데이터로도 좋은 성능을 내야 하는 경우: XGBoost는 적은 데이터로도 높은 성능을 내는 능력이 있습니다.
복수의 하이퍼파라미터를 튜닝할 여유와 능력이 있는 경우: XGBoost는 다양한 하이퍼파라미터를 조절할 수 있어, 세부적인 조정을 통해 최적의 성능을 낼 수 있습니다.
