
내용
- subquery
- outer query
- IN 키워드와 함께 subquery 사용하기
- correlated subquery
- EXISTS 키워드와 함께 subquery 사용하기
- ANY 키워드와 함께 subquery 사용하기
- ALL 키워드와 함께 subquery 사용하기
📌 시작 전 사전 지식
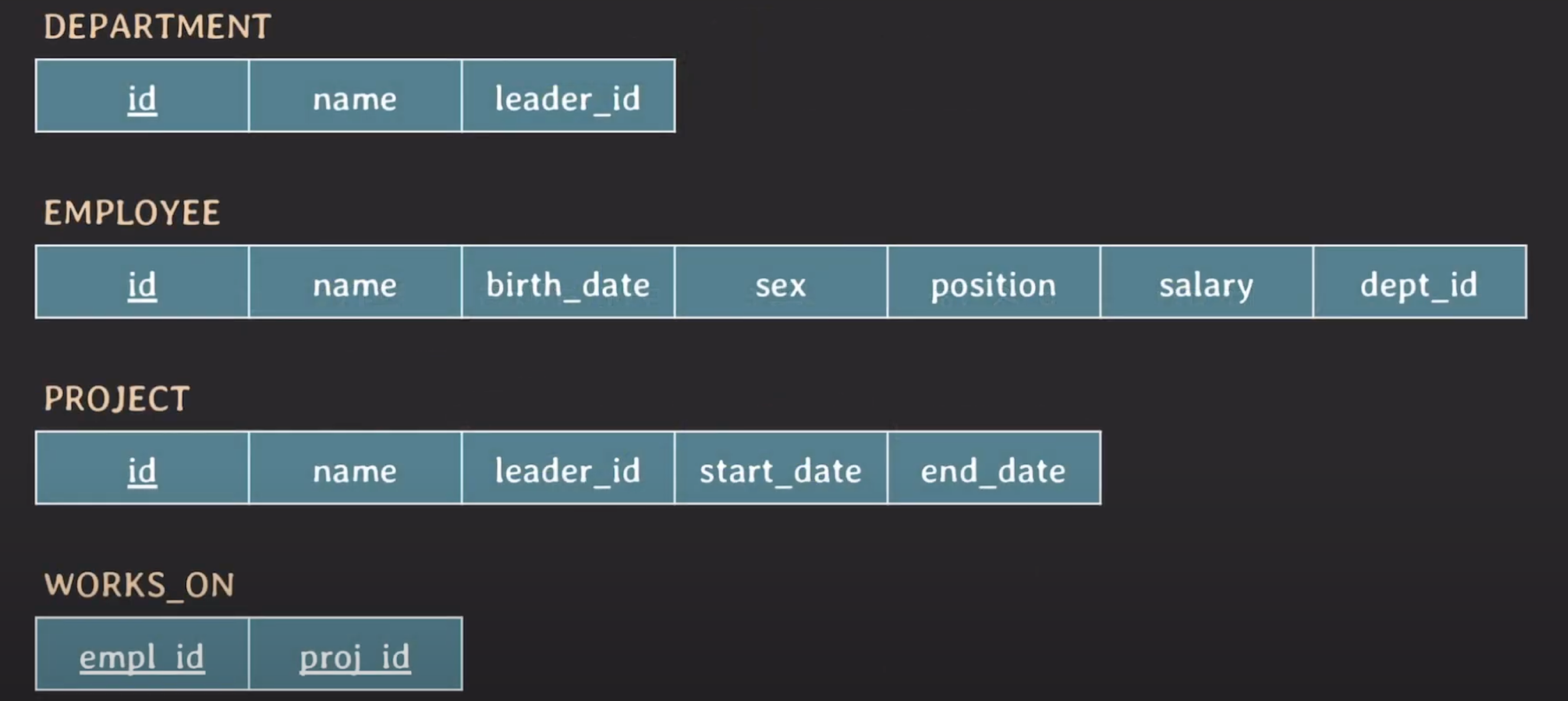
위 사진은 설명 이전에 이전까지 진행한 내용들에서 사용한 DB 테이블 구조입니다.
앞으로의 내용에서 해당 구조를 기반으로 설명합니다.
⭐️ Subquery
ID가 14인 임직원보다 생일이 빠른 임직원의 ID, 이름, 생일을 알고 싶다고 가정합니다.
이때 쿼리는 어떻게 작성할까요?
조건에서 ID가 14인 임직원보다 생일이 빠른 임직원의 정보를 원합니다. 그렇다면 우선 ID가 14인 임직원의 생일 정보를 찾습니다.
SELECT birch_date FROM employee WHERE id = 14;해당 쿼리의 결과로 1992-08-04 가 나왔다고 하겠습니다.
ID가 14인 임직원보다 생일이 빠른 임직원의 ID, 이름, 생일 정보 가져오기
SELECT id, name, birth_data FROM employee
WHERE birth_date < '1992-08-04';물론 위의 과정처럼 2단계로 나눠서 할수도 있습니다. 그러나 두 쿼리를 한 번에 할 수는 없는걸까요?
당연히 가능합니다! 이때 사용된 subquery입니다.
subquery 사용
SELECT id, name, birth_date FROM employee
WHERE bitrh_date < (
SELECT birch_data FROM employee WHERE id = 14
);subquery: SELECT, INSERT, UPDATE, DELETE에 포함된 query
- subquery는 ()안에 기술된다.
또 다른 예시
SELECT id, name, position
FROM employee
WHERE(dept_id, sex) = (
SELECT dept_id, sex
FROM employee
WHERE id = 1
);📌 IN 사용
ID가 5인 임직원과 같은 프로젝트에 참여한 임직원들의 ID를 알고 싶다.
우선 ID가 5인 임직원이 참여한 프로젝트를 알아봅시다.
SELECT proj_id FROM works_on WHERE empl_id =5;이 결과로 프로젝트 id가 2001, 2002인 프로젝트가 나왔다고 가정하겠습니다.
SELECT DISTINCT empl_id FROM works_on
WHERE empl_id != 5 AND (proj = 2001 OR proj_id = 2002);조건에 맞춰 작성을 한다면 위처럼 쿼리문을 작성할 것입니다. 그러나 IN을 사용한다면 더 편하게 작성할 수 있습니다.
IN: 괄호 안의 값 중에 하나와 값이 같다면 TRUE를 return 한다.
- NOT IN도 가능하다.
IN 사용
SELECT DISTINCT empl_id FROM works_on
WHERE empl_id != 5 AND proj_id In (2001, 2002;여기까지 작성을 해서 요구사함에 맞는 쿼리를 짰습니다. 이때 이전에 배운 subquery를 기억하시나요? subquery를 통해서 두 쿼리문을 합쳐주겠습니다.
subquery로 단축
SELECT DISTINCT empl_id FROM works_on
WHERE empl_id != 5 AND proj_id IN (
SELECT proj_id FROM works_on WHERE empl_id = 5
);위 예시처럼 unqualified attribute가 참조하는 table은 해당 attribute가 사용된 query를 포함하여 그 query의 바깥쪽으로 존재하는 모든 queries 중에 해당 attribute 이름을 가지는 가장 가까이에 있는 table을 참조한다.
subquery로 단축시킨 쿼리문은 ID가 5인 임직원이 참여한 프로젝트에 참여한 임직원들의 ID를 결과로 줍니다.
만약 여기서 이 임직원들의 id, name을 알고싶다면 어떻게 할까요?
id, name
SELECE id, name
FROM employee
WHERE id In (
SELECT DISTINCT empl_id FROM works_on
WHERE empl_id != 5 AND proj_id IN (
SELECT proj_id
FROM works_on
WHERE empl_id = 5
);네 바로 이렇게 작성하면 됩니다. 본래는 WHERE empl_id != 5 ~ 부분이 subquery였지만 새롭게 작성한 쿼리에서는
SELECT DISTINCT empl_id FROM works_on
WHERE empl_id != 5 AND proj_id IN (
SELECT proj_id
FROM works_on
WHERE empl_id = 5
);이 부분이 모두 subquery가 됩니다. 이해가 되시나요?
📌 EXISTS
새로운 예제를 생각해보겠습니다.
'ID가 7 혹은 12인 임직원이 참여한 프로젝트의 ID와 이름을 알고 싶다'
SELECT P.id, P.name
FROM project P
WHERE EXISTS (
SELECT *
FROM works_on W
WHERE W.proj_id = P.id AND W.empl_id IN (7, 12)
);EXISTS는 결과로 TRUE, FALSE를 리턴합니다.
subquery를 보면 works_on의 id와 project의 id가 일치하고, works_on의 empl_id가 7 또는 12 중 하나라도 일치한다면 EXISTS는 TRUE를 리턴합니다.
EXISTS: subquery의 결과가 최소 하나의 row라도 있다면 TRUE를 반환
- NOT EXISTS도 가능
📌 ANY
새로운 예시를 들겠습니다.
'리더보다 높은 연봉을 받는 부서원을 가진 리더의 ID와 이름과 연봉을 알고 싶다'
SELECT E.id, E.name, E.salary
FROm department D, employee E
WHERE D.leader_id = E.id ANd E.salary < ANY (
SELECT salary
FROM employee
WHERE id <> D.leader_id AND dept_id = E.dept_id
);ANY: subquery가 반환한 결과들 중에 단 하나라도 v 와의 비교 연산이 TRUE라면 TRUE를 반환한다.
📌 ALL
'ID가 13인 임직원과 한번도 같은 프로젝트에 참여하지 못한 임직원들의 ID, 이름, 직군을 알고 싶다.
SELECT DISTINCT E.id, E.name, E.position
FROM employee E, wroks_on W
WHEREE.id = W.empl_id AND W.proj_id <> ALL (
SELECT proj_id
FROM works_on
WHERE empl_id = 13
);v comparison_operator ALL: subquery가 반환한 결과들과 v와의 비교 연산이 모두 TRUE라면 TRUE를 반환한다.
⭐️ 참고 사항
- 성능 비교: IN vs EXISTS
- RDBMS의 종류와 버전에 따라 다르며 최근 버전은 많은 개선이 이루어져서 IN과 EXISTS의 성능 차이가 거의 없는 것으로 알고 있습니다.
- 해당 내용은 MYSQL 기준입니다. 다른 RDBMS와는 다른 점이 존재할수도 있습니다.
출처
글에 사용된 내용 및 사진은 모두 아래 영상의 자료입니다.
유튜브-쉬운코드
시니어 백엔드 개발자가 알려주는 데이터베이스 개론 & SQL
