
내용
- select
- project attributes
- selection condition
- join condition - 차후에 더 자세히 소개 예정입니다.
- AS로 별칭짓기
- DISTINCT 키워드
- LIKE로 조회하기
- *(asterisk) 사용하기
- where절 없는 select
⭐️ SELECT
데이터 조회하기
SELECT (projection attributes) FROM (조회 테이블 이름) WHERE (selection condition)데이터 조회 예시
SELECT name, position FROM employee WHERE id = 9📌 SELECT Statement 정리
- SELECT attribute(s)
- FROM table(s)
- [ WHERE condition(s) ];
하나의 상황을 가정해보겠습니다.
empolyee 테이블과 project 테이블이 있습니다. employee 테이블에는 직원들의 정보가 있고, project 테이블에는 현재 진행하고 있는 프로젝트의 정보들이 있습니다.
이때 employee 테이블의 튜플은 project 테이블의 PK에 대한 FK를 가지고 있다고 합니다.
이때 PK가 2002인 프로젝트에 참여하고 있는 직원의 ID와 이름과 직군이 알고 싶을 때 어떻게 해야할까요?
PK가 2002인 프로젝트에 참여하고 있는 직원의 ID, 이름, 직군 조회
SELECT employee.id, employee.name, posion
FROM project, employee
WHERE project.id = 2002 and project.leader_id = employee.id위 코드의 구조는 아래와 같습니다.
SELECT (조회하고 싶은 attribute(s))
FROM (조회에 사용될 테이블 이름)
WHERE (selection condition) and (join condition)이때 예시로 든 코드에서 의문점이 있습니다.
조회하고 싶은 attribute를 적을 때 employee.id처럼 왜 앞에 employee라고 테이블 이름을 적어주는 걸까? 번거로운데 그냥 id만 작성하면 안되는건가? 라는 의문이 듭니다.
마지막에 있는 employee.id를 id로 변경하고 실행해보겠습니다.
SELECT employee.id, employee.name, posion
FROM project, employee
WHERE project.id = 2002 and project.leader_id = id실행 결과
ERROR 1052 (23000): Column 'id' in where clause is ambiguous에러가 발생했습니다. 에러문을 읽어보니 Where 절의 id가 모호하다고 합니다.
에러의 원인은 간단합니다.
employee와 project 모두 id라는 attribute를 가지고 있기 때문에 둘 중 어떤 테이블의 id를 호출하는지 모호하다는 것입니다.
명확히 명시해주기 위해서 겹치는 attribute는 앞에 테이블 명을 작성해주는 것입니다.
📌 SELECT 키워드: AS
- AS는 테이블이나 attribute에 별칭(alias)를 붙일 때 사용한다.
- AS는 생략 가능
앞에서 사용한 예시를 통해서 설명하겠습니다.
앞에서 설명한 예시
SELECT employee.id, employee.name, posion
FROM project, employee
WHERE project.id = 2002 and project.leader_id = employee.id예시를 보니 attribute 앞에 계속 테이블 명을 적어주는 것도 귀찮고 코드도 길어져서 가독성 또한 떨어집니다. 테이블 명을 간단하게 작성하지는 못할까요? 이때 사용하는 것이 AS 입니다.
별칭 사용
SELECT E.id, E.name, posion
FROM project AS P, employee AS E
WHERE p.id = 2002 and P.leader_id = E.idFROM project AS P, employee AS E: AS를 이용해서 project의 별칭 P를 설정하고 employee의 별칭 E를 설정했습니다. 코드가 훨씬 짧아지고 보기 편안해졌습니다.
📌 SELECT 키워드: DISTINCT
설명에 사용할 테이블 구조
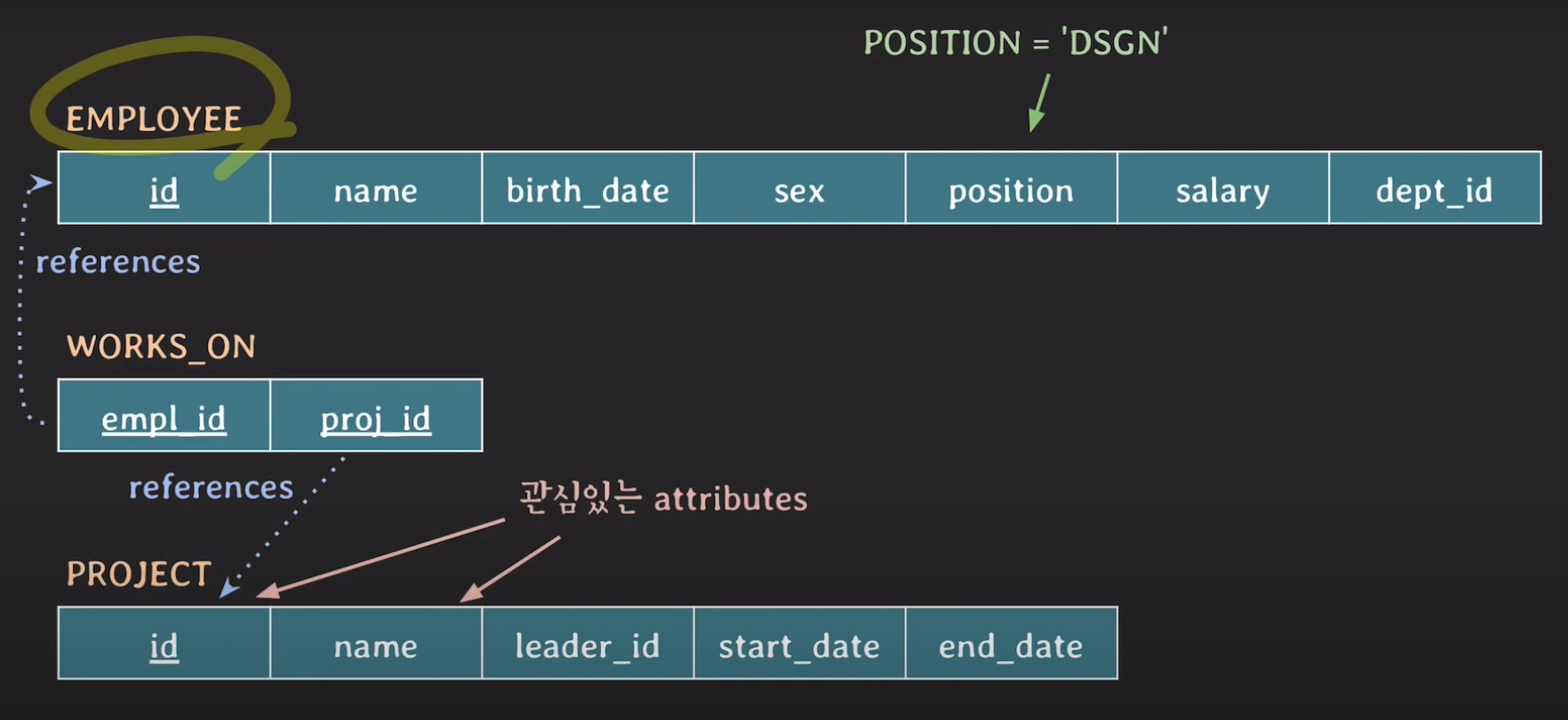
WROKS_ON 테이블은 EMPLOYEE 테이블과 PROJECT 테이블을 연결하는 고리 역할을 합니다.
DSGN은 디자이너를 의미합니다.
SELECT P.id, P.name
FROm employee AS E, works_on AS W, project AS P
WHERE E.position = 'DSGN' and
E.id = W.empl_id and W.proj_id = P.id이제 슬슬 위의 쿼리문이 이해가 되시나요?
직원의 포지션이 디자이너이고, 직원의 ID와 Works_on의 empl_id가 같고 프로젝트의 ID와 Work_on의 proj_id가 같은 Project 테이블의 ID와 NAME Attribute 값들을 가져오라는 쿼리입니다.
결과 예시

위 사진은 예시로 생성한 결과입니다. 이때 중복된 데이터에 존재하는데 이 중복을 제거하는 키워드가 DISTINCT 키워드입니다.
DISTINCT 사용
SELECT DISTINCT P.id, P.name
FROm employee AS E, works_on AS W, project AS P
WHERE E.position = 'DSGN' and
E.id = W.empl_id and W.proj_id = P.id결과

DISTINCT를 사용하니 중복이 사라진 것을 확인할 수 있습니다.
결론
DISTINCT는 SELECT 결과에서 중복되는 tuples은 제외하고 싶을 때 사용한다.
📌 SELECT 키워드: LIKE
이름이 N으로 시작하거나 N으로 끝나는 직원들의 이름을 알고 싶다고 가정하겠습니다.
SELECT name
FROM employee
WHERE name LIKE 'N%' or name LIKE '%N';여기서 %는 0개 이상의 의미를 가지는 문자를 의미합니다.
즉, employee 테이블의 name attribute 중 name이 N으로 시작하거나 N으로 끝나는 name들을 조회하는 것입니다.
SELECT (조회할 attribute)
FROM (조회할 테이블 이름)
WHERE name LIKE '(조건 문법)';또 다른 예시를 들겠습니다. 이름이 J로 시작하는, 총 네 글자의 이름을 가지는 직원들의 이름을 알고 싶다고 하겠습니다. 쿼리를 어떻게 작성해야 할까요?
SELECT name FROM employee WHERE name LIKE 'J___';%로 시작하거나 _로 끝나는 프로젝트의 이름을 찾고 싶다면?
SELECT name FROM project WHERE name LIKE '\%%' or name LIKE '%\_'
📌 SELECT 키워드: *(asterisk)
ID가 9인 직원의 모든 attributes를 앞고 싶다고 가정하겠습니다.
SELECT * FROM employee WHERE id = 9;본래 *의 자리는 attribute의 자리입니다. 그러나 모든 attribute를 알고 싶다면 위 예시처럼 asterisk를 작성해주면 됩니다.
결론
*(asterisk)는 선택된 tuples의 모든 attributes를 보여주고 싶을 때 사용한다.
📌 SELECT without WHERE
모든 임직원의 이름과 생일을 알고 싶다고 합시다. 아마 쿼리가 어떻게 작성될지 예상이 되시나요?
SELECT name, bitch_data
FROM employee간단합니다. WHERE 문을 빼준다면 조건이 사라지고 지정한 모든 속성이 결과로 나올 것입니다.
⭐️ 주의 사항
-
SELECT로 조회할 때 조건들을 포함해서 조회를 한다면 이 조건들과 관련된 attributes에 index가 걸려있어야 합니다. 그렇지 않다면 데이터가 많아질수록 조회 속도가 느려집니다.
i.g. SELECT * FROM employee WHERE position = 'dev_back'; -
해당 내용은 MYSQL 기준입니다. 다른 RDBMS의 SQL 문법은 조금씩 다를 수 있습니다.
출처
글에 사용된 내용 및 사진은 모두 아래 영상의 자료입니다.
유튜브-쉬운코드
시니어 백엔드 개발자가 알려주는 데이터베이스 개론 & SQL
