
들어가며
척척학사는 사용자가 학교 학사 포털 계정을 연결하면, 스크래핑 워커가 포털 데이터를 가져오고 백엔드가 이를 정제해 서비스 DB에 반영하는 시스템입니다.
처음 백엔드는 EC2 서버를 전제로 동작하던 구조였습니다. 이후 운영 비용과 배포 단순화를 위해 백엔드 실행 환경을 Lambda로 옮기면서, 기존 서버형 애플리케이션에서 자연스럽게 사용하던 몇 가지 전제가 깨졌습니다.
다만 이 글에서 직접 다루는 문제는 EC2에서 운영하던 기존 구조 자체가 아닙니다.
EC2 기반 운영 구조는 별도로 존재했고, 여기서 장애를 분석한 대상은 백엔드를 Lambda로 옮긴 뒤 서버형 애플리케이션에서 사용하던 실행 방식을 일부 그대로 가져온 초기 구조입니다. 이하에서는 이를 초기 Lambda 구조라고 부르겠습니다.
핵심 문제는 Lambda가 항상 떠 있는 서버가 아니라는 점이었습니다.
- 요청이 끝난 뒤 내부 thread가 계속 실행된다고 보장할 수 없습니다.
@Async,TaskExecutor,afterCommit,@Scheduled같은 in-memory 실행을 보장된 처리 경로로 두기 어렵습니다.- API Gateway와 Lambda timeout 안에서 요청 경계를 명확히 해야 합니다.
- DB transaction 안에서 네트워크 I/O나 sleep을 오래 수행하면 connection과 lock이 오래 잡힐 수 있습니다.
이 글은 포털 연동 과정에서 실행 경계, transaction 경계, 비동기 처리 경계를 Lambda 실행 모델에 맞게 다시 정의한 과정을 정리한 기록입니다.
1. 최종 구조 요약
최종적으로 스크래핑 요청 흐름은 아래처럼 정리했습니다.
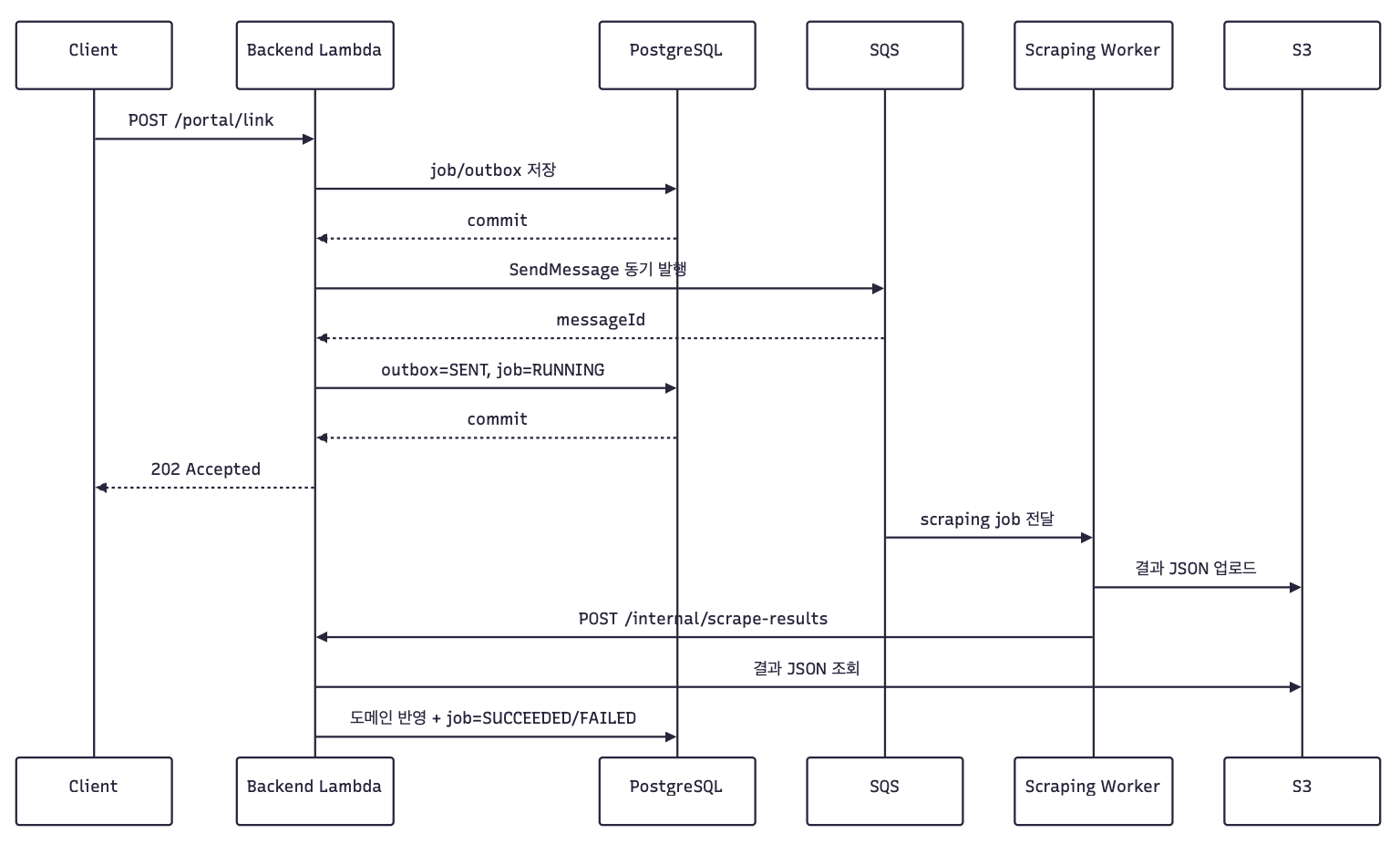
설계 기준은 단순했습니다.
Lambda 요청 이후에도 내부 작업이 계속 실행될 것이라고 기대하지 않습니다. 요청 안에서 끝내야 하는 일은 동기로 끝내고, 주기 작업은 외부의 명시적인 실행 트리거로 옮깁니다.
2. 포털 연동 방식이 어떻게 바뀌었는가
초기 Lambda 구조는 서버 내부에서 다음 작업이 이어서 실행된다는 전제를 일부 그대로 가져온 형태였습니다.
사용자 요청
-> 백엔드가 job 생성
-> afterCommit / 내부 executor를 통해 SQS 발행 시도
-> 스크래핑 워커 실행
-> 워커가 결과 payload 전체를 백엔드 콜백으로 전달
-> 백엔드가 콜백 안에서 후처리
-> 일부 복구/정리 작업은 Lambda 내부 scheduler에 의존최종 구조에서는 SQS, S3, DB 상태처럼 유실되지 않는 경계와 명시적인 상태 전이로 각 단계를 나누었습니다.
사용자 요청
-> 백엔드가 job/outbox 저장
-> 요청 안에서 SQS 발행 성공 여부 확정
-> 워커가 SQS 기반으로 실행
-> 워커는 결과 전체를 S3에 저장
-> 콜백에는 result_s3_key만 전달
-> 백엔드는 S3에서 결과를 조회해 DB 반영
-> 주기 복구 작업은 EventBridge Scheduler가 Lambda를 직접 호출| 구분 | 초기 Lambda 구조 | 최종 구조 |
|---|---|---|
| 작업 시작 | afterCommit / 내부 executor 기반 SQS 발행 | 요청 안에서 SQS 발행 확정 |
| 결과 전달 | 콜백 body에 전체 payload 전달 | S3 저장 후 result_s3_key 전달 |
| 후처리 | 콜백 내부에 무거운 처리와 긴 transaction 경계가 섞임 | S3 조회 후 짧은 transaction 단위로 명시적 상태 반영 |
| 주기 작업 | Spring @Scheduled | EventBridge Scheduler 직접 호출 |
| 실패 관측 | Lambda 내부 실행 뒤에 숨어 원인 분리가 어려움 | SQS, S3, DB 상태, Scheduler 로그로 실패 지점 분리 |
정리하면 포털 연동은 서버 내부에서 이어서 처리되는 작업에서 SQS, S3, DB 상태 같은 유실되지 않는 경계를 거쳐 단계별로 확정되는 작업으로 바뀌었습니다.
3. 콜백 후처리 경계를 다시 나눈 이유
초기 콜백 구조에서는 스크래핑 워커가 백엔드 서버로 결과 payload를 직접 전달했습니다.
백엔드는 이 payload를 받아 데이터를 정제하고 DB에 반영했습니다.
초기 콜백 경로에는 아래 작업이 섞여 있었습니다.
- 콜백 payload 수신
- 포털 데이터 정제
- DB 반영
- job 상태 변경
- 중복 콜백 처리
이 구조는 콜백 요청 자체가 무거워질 수 있었습니다. 그래서 초기 구조를 기준으로 콜백 후처리 분리, transaction 경계 분리, 중복 방지, 콜백 성공 판정 정리 등을 진행했습니다.
하지만 이 과정에서 중요한 판단을 하게 됐습니다.
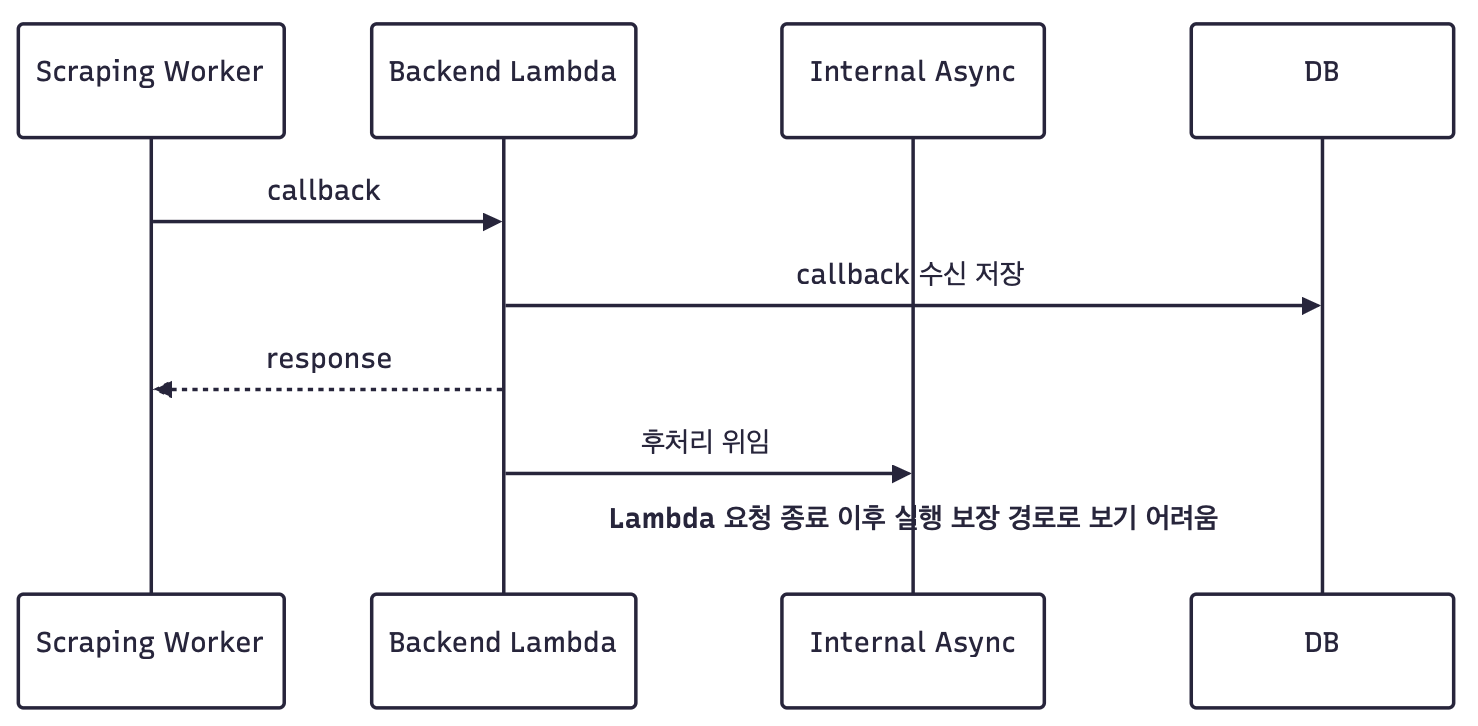
EC2처럼 프로세스가 상시 실행되는 환경에서는 내부 async worker를 운영 모델 안에 둘 수 있습니다. 하지만 Lambda에서는 컨테이너 재사용이 최적화일 뿐, 요청 이후 내부 thread 실행을 보장하는 모델이 아닙니다.
따라서 요청 이후 실행되어야 하는 핵심 처리는 Lambda 내부 async에 맡기지 않고, 영속적인 trigger나 요청 경계 안으로 옮겨야 했습니다.
4. 결과 payload를 S3로 분리한 이유
다음 문제는 콜백 payload 자체가 무겁다는 점이었습니다. 워커가 결과 전체를 백엔드 콜백 body로 보내면, 콜백 endpoint가 결과 전송과 후처리까지 모두 부담하게 됩니다.
그래서 워커는 결과 JSON을 S3에 업로드하고, 백엔드 콜백에는 job_id, attempt, result_s3_key만 보내도록 바꿨습니다.
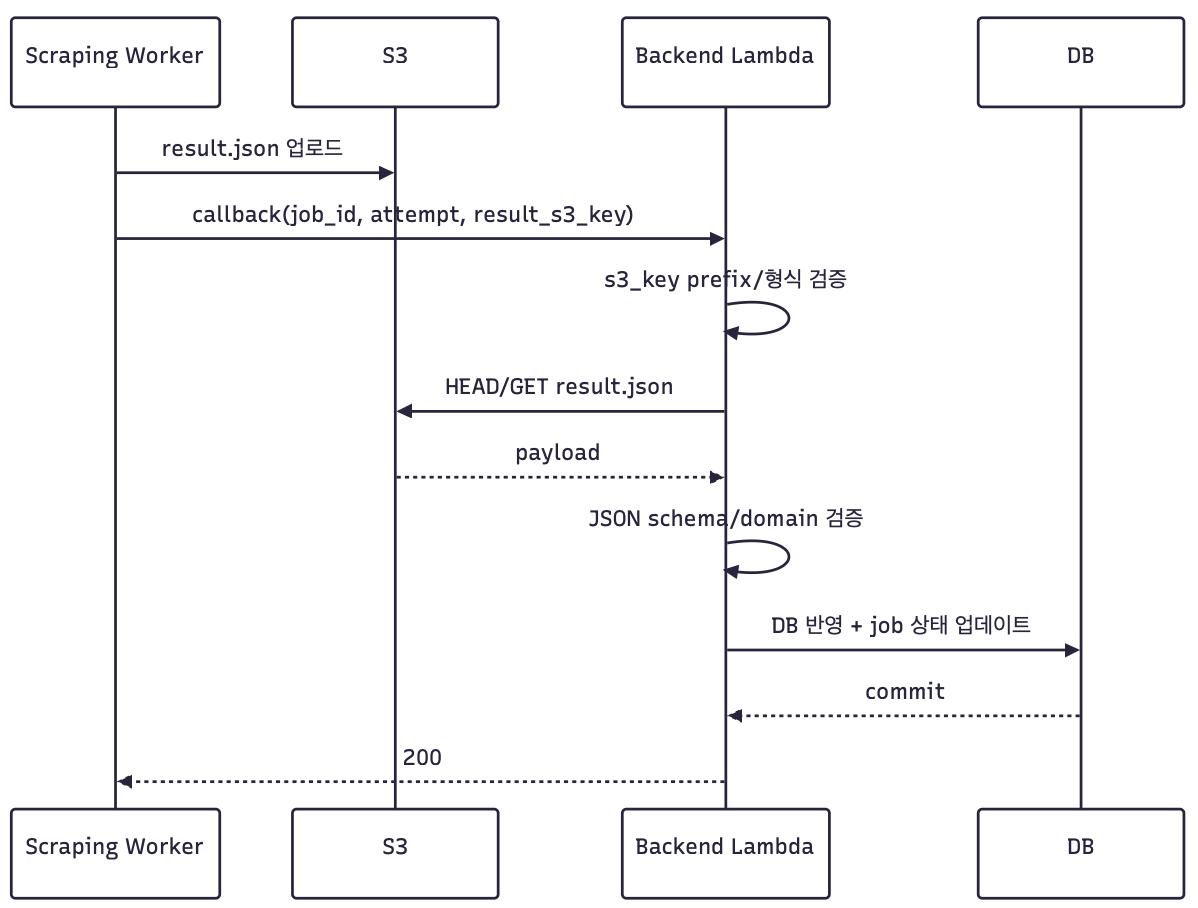
이 판단의 근거는 다음과 같습니다.
- 콜백 요청 body를 작게 유지할 수 있습니다.
- 원본 결과 JSON이 S3에 남아 장애 분석과 재처리에 유리합니다.
- direct payload 수신 방식을 줄이고, API 계약을
result_s3_key중심으로 단순화할 수 있습니다. job_id + attempt기준으로 중복 콜백을 멱등 처리할 수 있습니다.
다만 이 시점에 또 다른 문제가 드러났습니다. 콜백 전체를 하나의 긴 transaction으로 묶으면 S3 read, JSON parse, DB 반영까지 모두 같은 connection과 lock 경계 안에 들어갑니다.
실제 장애 로그에서는 콜백 요청을 처리하던 Lambda invocation이 postprocess.start 이후 완료되지 못했고, Lambda timeout에 걸렸습니다.
관측값은 아래와 같았습니다.
| 항목 | 값 |
|---|---|
| Lambda timeout 설정 | 30초 |
| API Gateway integration timeout | 30,000ms |
| 실패 invocation duration | 31,741.97ms |
| 실패 메시지 | Task timed out after 31.74 seconds |
| 종료 로그 | postprocess.success, scrape.job.succeeded 미출력 |
이후 transaction 경계를 재설계했습니다.
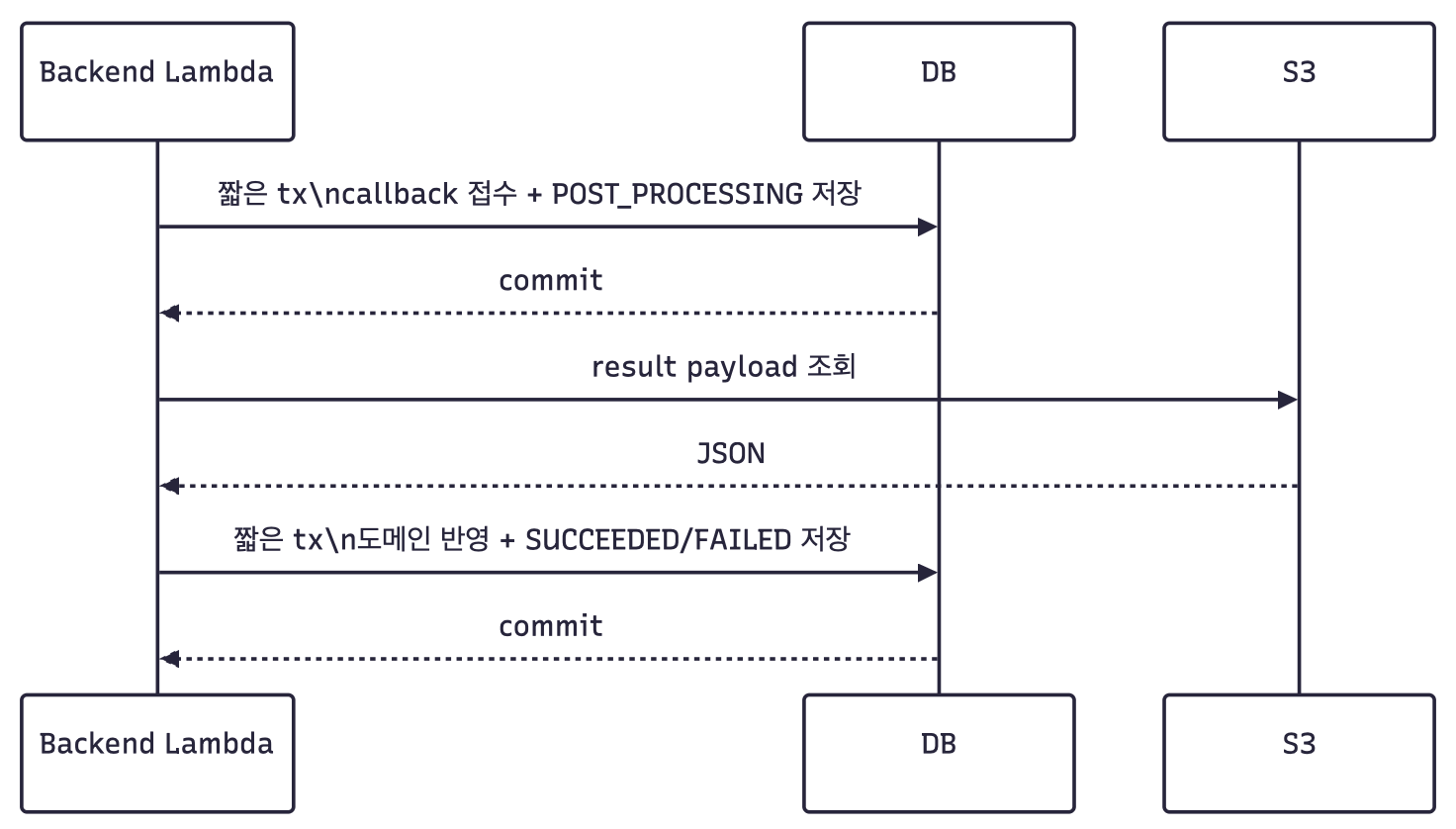
관측된 정상 케이스 기준으로, 최종 구조의 백엔드 콜백 내부 소요 시간은 약 5.193초였습니다.
| 구간 | 소요 시간 |
|---|---|
| 콜백 전체 | 5.193초 |
| 콜백 validated → receipt committed | 2.102초 |
| receipt committed → payload ready | 0.328초 |
| postprocess start → scrape.job.succeeded | 1.277초 |
| scrape.job.succeeded → postprocess success | 1.435초 |
다만 receipt committed까지의 2.102초를 순수 DB write 시간으로 해석하지는 않았습니다. 이 구간에는 요청 검증, 상태 조회, lock 획득, 접수 상태 저장 등이 함께 포함될 수 있고, 핵심은 S3 조회와 JSON 검증을 긴 DB transaction 밖으로 분리했다는 점이었습니다.
30초 timeout 기준으로 보면, 해당 정상 케이스에서 콜백 처리 시간은 약 17.3%를 사용했습니다.
5.193초 / 30초 = 17.3%이 수치만으로 모든 요청의 성능 개선률을 일반화할 수는 없습니다. 하지만 적어도 해당 요청에서는 콜백 처리 시간이 30초 timeout에 근접하지 않았고, S3 조회와 JSON 검증 중에는 DB transaction을 붙잡지 않도록 경계를 나눌 수 있었습니다.
5. SQS 발행을 Lambda 요청 경로 안에서 확정한 이유
다음 문제는 /portal/link 요청 이후 SQS 메시지 발행 경로에서 발생했습니다.
초기 구조는 job과 outbox를 저장한 뒤, afterCommit + TaskExecutor/@Scheduled 기반으로 SQS 발행을 이어가는 방식이었습니다.
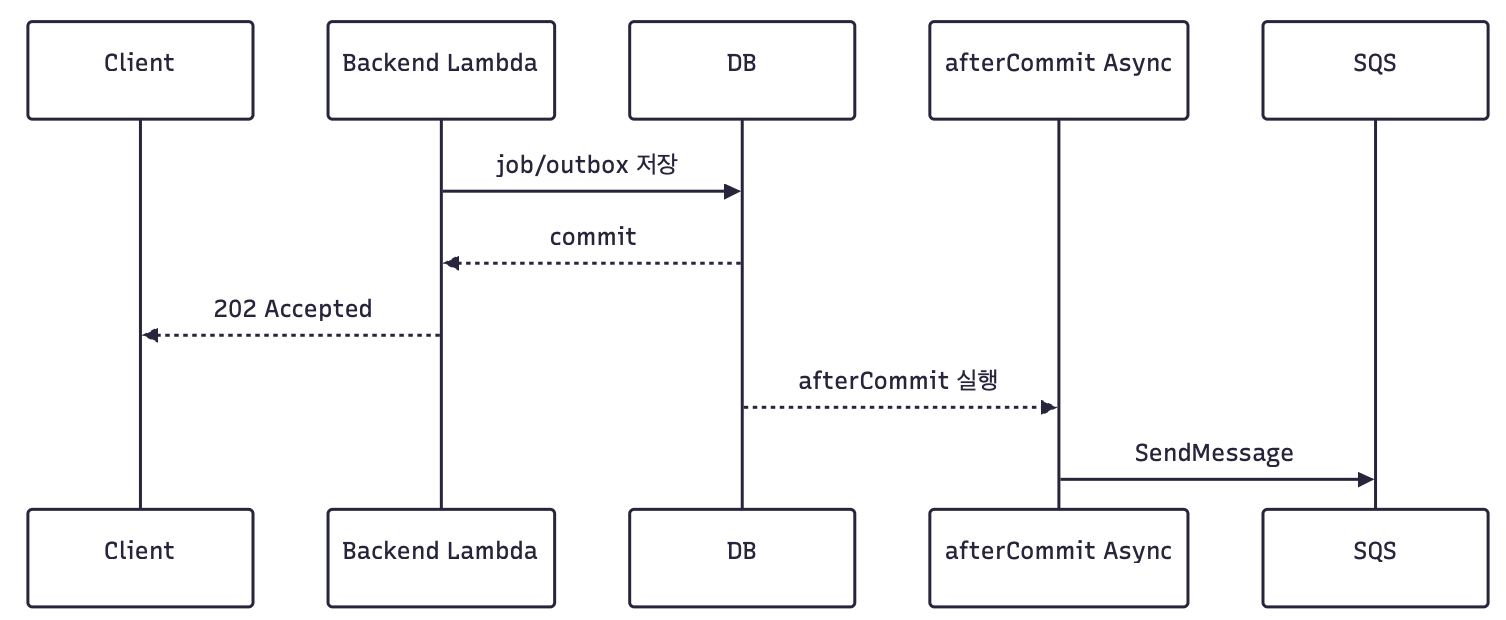
문제는 Lambda에서 이 내부 비동기 실행을 보장된 처리 경로로 둘 수 없다는 점이었습니다.
실제 확인된 사례는 아래와 같았습니다.
| 확인 항목 | 상태 |
|---|---|
scrape.job.accepted 로그 | 존재 |
scrape.outbox.dispatch.after_commit.start 로그 | 존재 |
scrape.outbox.publish.start 로그 | 없음 |
scrape.outbox.sent 로그 | 없음 |
| SQS main queue | 0 |
| SQS DLQ | 0 |
| RUNNING ECS task | 없음 |
| worker 로그 | 없음 |
| DB job 상태 | QUEUED 고착 |
| 고착 관측 시간 | 14분 이상 |
이 사례는 SQS에 메시지가 있는데 worker가 처리하지 못한 상황이 아니었습니다. 요청은 수락됐지만 SQS 발행 단계까지 도달하지 못했고, 그 결과 job 상태가 QUEUED에 남은 상황이었습니다.
그래서 SQS 발행을 요청 경로 안에서 동기로 확인하도록 바꿨습니다.
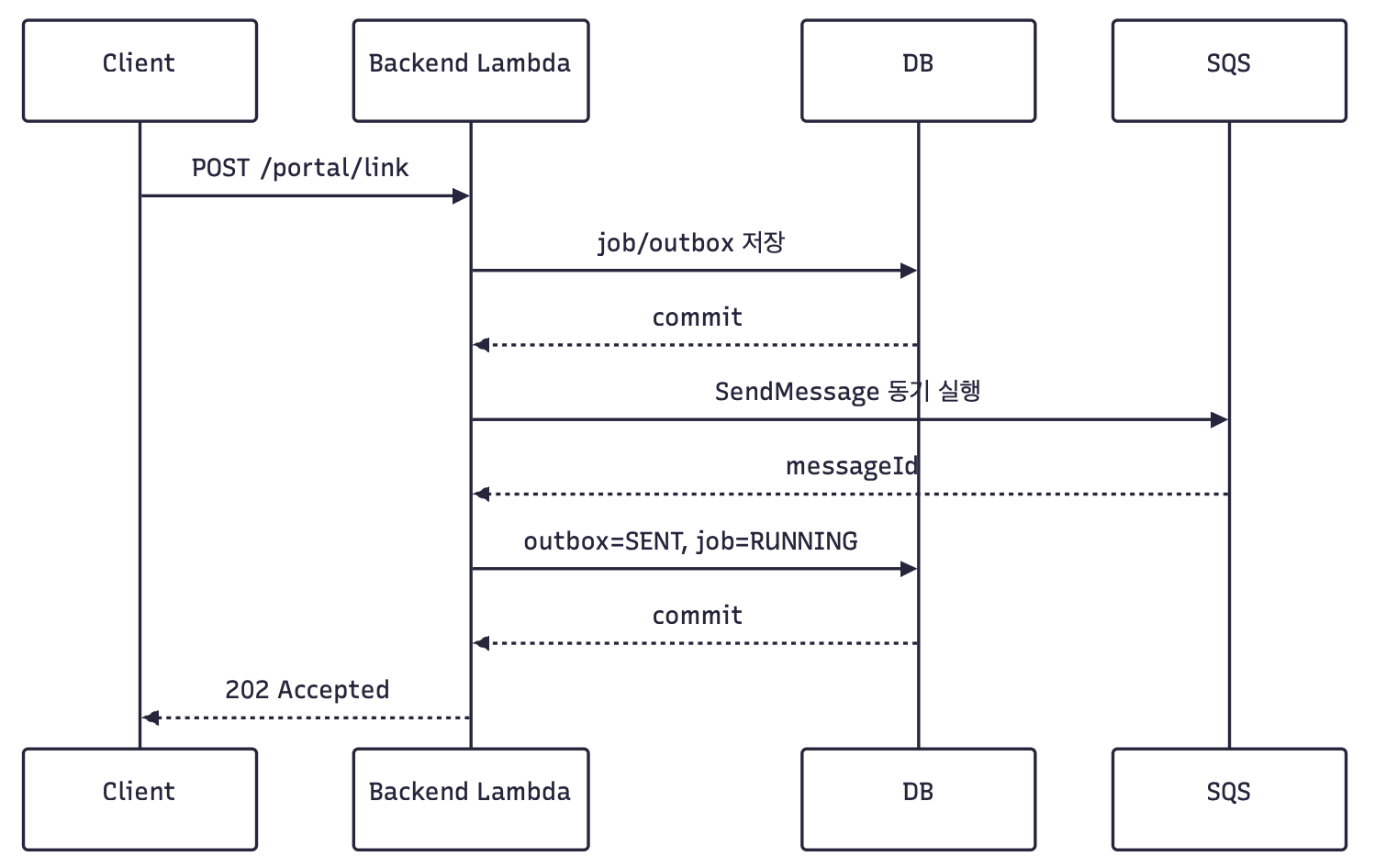
이 결정에는 트레이드오프가 있었습니다.
- 장점: 요청이 성공했다면 적어도 SQS SendMessage 성공 여부는 요청 경로 안에서 확인됩니다.
- 장점: 요청 이후 내부 async 실행에 의존하지 않습니다.
- 단점: 요청 시간이 SQS 발행 시간만큼 늘어납니다.
하지만 이 단점은 수용 가능했습니다. SQS 발행은 일반적으로 짧은 네트워크 호출이고, transient failure에 대해서만 짧은 bounded retry를 적용했습니다.
bounded retry 정책은 다음과 같습니다.
| 항목 | 값 |
|---|---|
| 최초 시도 | 1회 |
| 추가 재시도 | 최대 2회 |
| 재시도 대기 | 200ms, 500ms |
| sleep budget | 최대 700ms |
| 재시도 대상 | transient failure |
| permanent failure | 즉시 실패 |
retry로 추가되는 순수 대기 시간은 최대 700ms입니다.
리뷰 과정에서 한 가지를 더 보완했습니다. 중간 수정안에서는 SQS publish와 retry sleep이 DB transaction 안에서 실행될 수 있었습니다. 그러면 최대 700ms의 sleep과 SQS 네트워크 I/O 동안 DB connection과 row lock을 잡게 됩니다.
그래서 아래처럼 다시 나눴습니다.
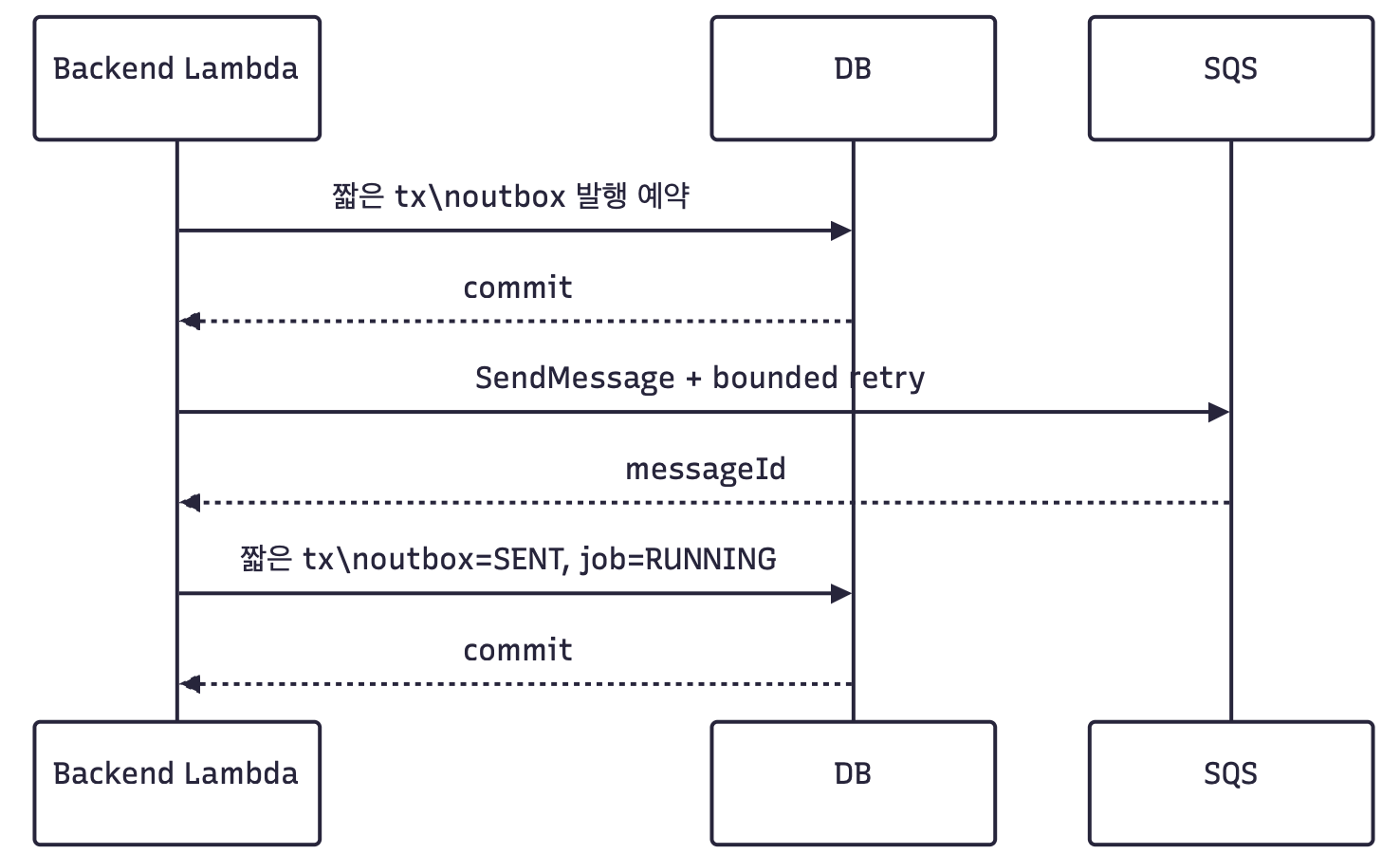
이 변경은 비동기화가 아닙니다. SQS 발행은 여전히 Lambda 요청 안에서 동기로 끝납니다. 달라진 점은 네트워크 I/O와 Thread.sleep을 DB transaction 밖으로 뺐다는 것입니다.
물론 이 구조도 완전한 원자성을 제공하지는 않습니다. DB에 job/outbox를 저장한 뒤 SQS 발행은 성공했지만, 다시 DB에 outbox=SENT, job=RUNNING을 반영하는 단계가 실패할 수 있습니다. 그래서 worker와 콜백 경로에서는 job 상태를 다시 조회하고, attempt와 terminal state 기준으로 중복 처리를 흡수하도록 설계했습니다.
핵심은 실패가 절대 발생하지 않는 구조를 만든 것이 아닙니다. 실패 지점이 Lambda 내부 in-memory 실행 뒤에 숨어 있지 않고, DB 상태, SQS 메시지, 콜백 결과로 관측 가능하고 재처리 가능한 경계로 이동했다는 점입니다.
6. 주기 작업을 EventBridge Scheduler로 옮긴 이유
마지막으로 정리한 것은 내부 스케줄링 작업이었습니다.
백엔드에는 두 가지 주기 작업이 있었습니다.
| 작업 | 목적 |
|---|---|
| stale scrape job reconcile | 오래 RUNNING 상태인 job을 FAILED로 정리 |
| refresh token cleanup | 만료된 refresh token 삭제 |
EC2에서는 Spring @Scheduled가 자연스러운 선택일 수 있습니다. Lambda에서는 그렇지 않습니다. 문제는 이 전제를 Lambda 이전 직후 구조에도 그대로 가져왔다는 점이었습니다.
- Lambda container가 항상 살아있지 않습니다.
- 여러 container가 동시에 떠 있으면 scheduler도 중복 실행될 수 있습니다.
- container freeze 상태에서는 schedule 실행을 기대하기 어렵습니다.
TaskSchedulerbean 구성 문제로 Lambda 부팅 자체가 실패할 수도 있습니다.
따라서 주기 작업을 EventBridge Scheduler로 옮겼습니다.
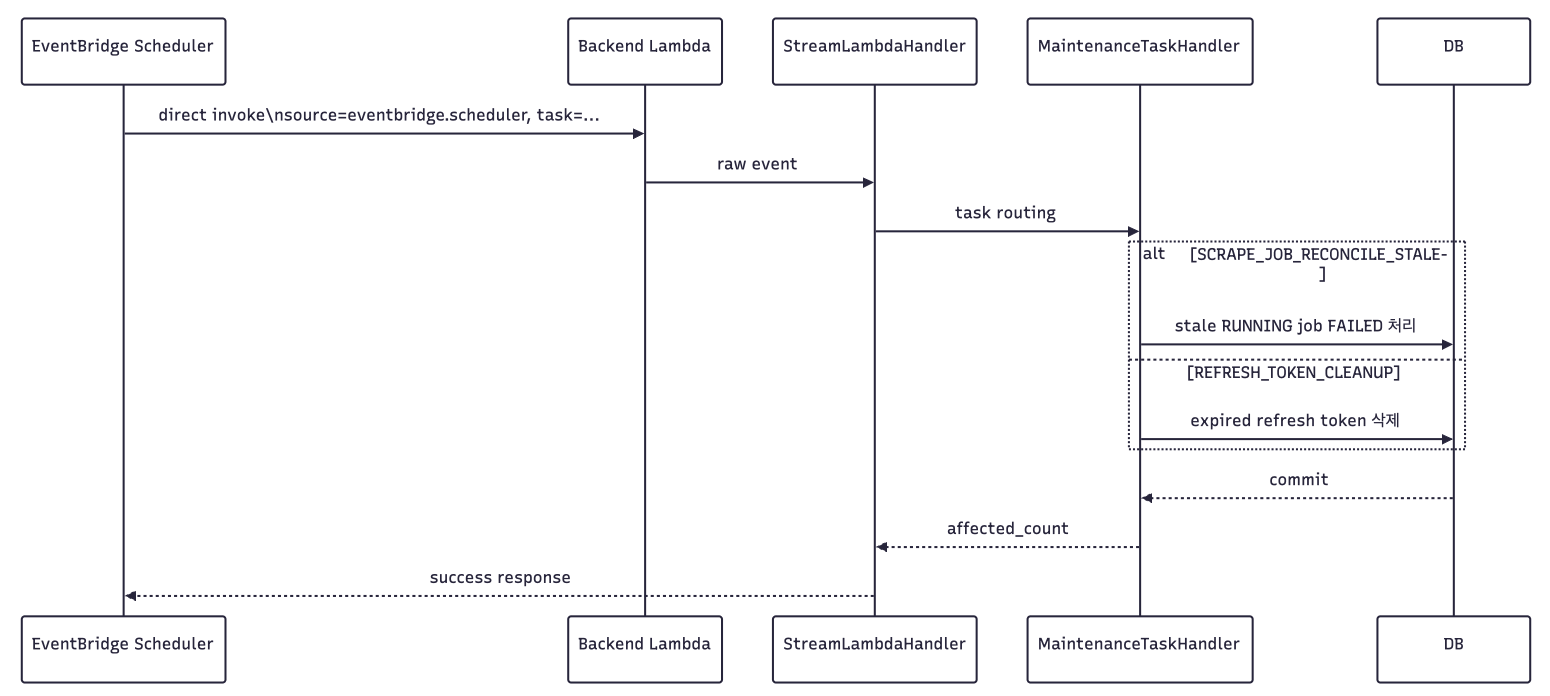
여기서 HTTP endpoint를 추가하지 않았습니다. EventBridge Scheduler가 Backend Lambda를 직접 호출(direct invoke)합니다.
선택하지 않은 방식:
EventBridge -> API Gateway -> /internal/... -> Lambda
선택한 방식:
EventBridge -> Lambda Invoke API -> Backend Lambda이 판단의 근거는 다음과 같습니다.
| 항목 | HTTP 호출 | Lambda 직접 호출 |
|---|---|---|
| 진입점 | API Gateway endpoint | Lambda function ARN |
| 인증 | HMAC/API Key/Authorizer 필요 | IAM lambda:InvokeFunction |
| Controller | 필요 | 불필요 |
| API Gateway timeout | 영향 있음 | API Gateway integration timeout과 분리 |
| 외부 URL 노출 | 있음 | 없음 |
| 적합한 용도 | HTTP API | 운영성 maintenance task |
사용자 요청 API가 아니라 운영성 주기 작업이므로 HTTP를 거칠 이유가 없었습니다.
7. 변경으로 얻은 이점
이번 작업의 효과는 추상적인 구조 개선이 아니라, 실제 장애 지점과 수치로 설명할 수 있습니다. 다만 아래 수치는 관측된 요청과 장애 사례 기준이며, 모든 요청의 성능 개선률로 일반화할 수는 없습니다.
7.1 S3 key 기반 콜백으로 timeout 위험을 줄였습니다
장애 당시 콜백 요청을 처리하던 Lambda invocation은 31,741.97ms 동안 실행되다가 Lambda timeout에 걸렸습니다. 설정 timeout은 30초였습니다.
최종 구조에서 관측된 정상 성공 케이스의 백엔드 콜백 내부 처리 시간은 5.193초였습니다.
30초 timeout 대비 사용률: 5.193 / 30 = 17.3%이 수치만으로 전체 성능 개선률을 일반화할 수는 없습니다. 하지만 적어도 해당 정상 케이스에서는 콜백 처리 경계가 30초 timeout을 대부분 소모하지 않았고, timeout 위험을 만드는 구간을 더 좁게 관측할 수 있었습니다.
7.2 SQS 발행 유실로 인한 QUEUED 고착 지점을 줄였습니다
초기 구조에서는 /portal/link 요청이 성공 응답을 반환한 뒤, 내부 async가 SQS 발행을 이어가야 했습니다. 실제로는 after_commit.start 이후 SQS 발행 로그 없이 job이 QUEUED에 14분 이상 고착된 사례가 있었습니다.
최종 구조에서는 202 응답을 반환하기 전에 SQS 발행 결과를 요청 경로 안에서 확인합니다. 가능한 경우 outbox와 job 상태 반영까지 같은 요청 흐름에서 마무리합니다.
초기 Lambda 구조: accepted 후 SQS 발행 여부가 불확실
최종 구조: 202 응답 전 SQS 발행 성공/실패 확인따라서 요청은 성공했지만 SQS에는 메시지가 없는 상태가 조용히 남지 않도록 바꿨습니다.
7.3 transaction 밖으로 네트워크 I/O와 sleep을 빼 DB 점유 시간을 줄였습니다
SQS bounded retry의 sleep budget은 최대 700ms입니다.
중간 수정안처럼 이 sleep이 transaction 안에 있으면, 실패 한 번마다 DB connection과 row lock을 최대 700ms 더 잡을 수 있습니다. 동시 요청이 늘면 connection pool 고갈 위험으로 이어질 수 있습니다.
최종 구조에서는 SQS publish와 retry sleep을 transaction 밖으로 분리했습니다.
중간 수정안: DB transaction 안에서 SQS I/O + sleep
최종 구조: 짧은 DB tx -> SQS I/O/sleep -> 짧은 DB tx즉, 네트워크 대기 시간과 DB connection 보유 시간을 분리했습니다.
7.4 수치로 다음 병목이 ECS cold start임을 확인했습니다
관측된 정상 성공 케이스에서 전체 소요 시간은 85.837초였지만, 백엔드 콜백은 5.193초였습니다.
큰 병목은 백엔드 콜백이 아니라 ECS task 기동과 image pull 쪽에 더 크게 남아 있었습니다.
| 구간 | 소요 시간 |
|---|---|
| 전체 요청 수락 → worker 종료 | 85.837초 |
| backend 콜백 처리 | 5.193초 |
| outbox sent → worker job.started | 69.773초 |
| ECS image pull | 45.516초 |
이 수치만으로 모든 요청의 성능 개선률을 일반화할 수는 없습니다. 하지만 적어도 이 요청에서는 timeout을 유발하던 구간이 백엔드 콜백 전체가 아니라 ECS task cold start와 image pull 쪽에 더 크게 남아 있음을 확인할 수 있었습니다.
8. 최종 설계 원칙
이번 작업 이후 기준은 세 가지로 정리할 수 있습니다.
8.1 요청 이후에도 반드시 실행되어야 하는 일은 Lambda 내부 async에 맡기지 않습니다
예를 들어 SQS 발행은 afterCommit + TaskExecutor가 아니라 /portal/link 요청 경로 안에서 확정했습니다. 콜백 후처리도 요청 이후 내부 async에 맡기지 않았습니다. S3 key 기반으로 payload 전달을 분리하고, 콜백 경계 안에서 상태를 명시적으로 반영했습니다.
8.2 DB transaction 안에서는 네트워크 I/O와 sleep을 하지 않습니다
S3 조회, SQS SendMessage, bounded retry sleep은 transaction 밖으로 분리했습니다. DB transaction은 상태 조회, 예약, 성공/실패 반영처럼 짧은 DB 작업에만 사용했습니다.
8.3 주기 실행은 container 생명주기가 아니라 외부 scheduler에 맡깁니다
오래 RUNNING인 job 정리와 만료 refresh token cleanup은 Spring @Scheduled가 아니라 EventBridge Scheduler 직접 호출로 실행하도록 바꿨습니다.
9. 마무리
이번 Lambda 전환은 단순히 배포 대상을 EC2에서 Lambda로 바꾸는 작업이 아니었습니다. 실행 환경이 바뀌면서 애플리케이션 내부의 실행 경계, transaction 경계, 비동기 처리 경계를 다시 정의해야 했습니다.
가장 중요한 변화는 세 가지입니다.
- Lambda 내부 비동기 실행을 보장된 처리 경로로 두지 않도록 바꿨습니다.
- DB transaction 안에서 네트워크 I/O와 sleep을 수행하지 않도록 바꿨습니다.
- 주기 작업은 Lambda 내부 scheduler가 아니라 EventBridge Scheduler로 옮겼습니다.
결과적으로 각 단계의 책임이 더 명확해졌습니다.
/portal/link는 SQS 발행까지 책임집니다./internal/scrape-results는 S3 결과 조회와 DB 반영까지 책임집니다.- maintenance 작업은 EventBridge Scheduler가 명시적으로 실행합니다.
Lambda 환경에서는 프로세스가 계속 살아있을 것이라는 전제가 아니라, 어떤 이벤트가 어떤 작업을 언제 실행하는가를 기준으로 설계해야 합니다. 문제는 EC2 구조 자체가 아니라, EC2식 실행 전제를 Lambda 이전 직후 구조에 그대로 가져온 데 있었습니다. 이번 작업의 핵심은 서버를 Lambda로 옮긴 것이 아니라, 서버가 계속 살아 있다는 전제를 제거하고 Lambda 실행 모델에 맞게 경계를 다시 그린 것이었습니다.
