딥러닝에서 이용하는 라이브러리 설치
- 아나콘다 프롬프트열기
- 내가 설치할 가상환경으로 이동
=> conda activate 가상환경이름
- pip install tensorflow
⇒ 실행하는 가상환경마다 설치해야한다. - cd 사용하는 폴더경로
- jupyter notebook
하면 이제 학습준비가 되었다.
딥러닝(Deep Learning)
-
딥러닝은 머신러닝 알고리즘 중 하나로, 인공신경망을 기반으로 하는 머신러닝의 한 분야이다. 비정형의 대용량 데이터 학습에 뛰어난 성능을 나타내며, 이로 인해 작은 양의 데이터를 학습하면 오버피팅(Overfitting)이 발생할 확률이 높다.
-
정형 데이터와 비정형 데이터
-
정형 데이터: 정형 데이터는 명확한 속성과 구조에 따라 정리되어 있는 데이터
-
비정형 데이터: 규칙적인 구조가 없거나 복잡한 형태의 데이터 ex) 이미지, 자연어,음성
-
딥러닝은 이러한 비정형 데이터에 성능이 뛰어납니다.
- 비정형 데이터 학습의 원리
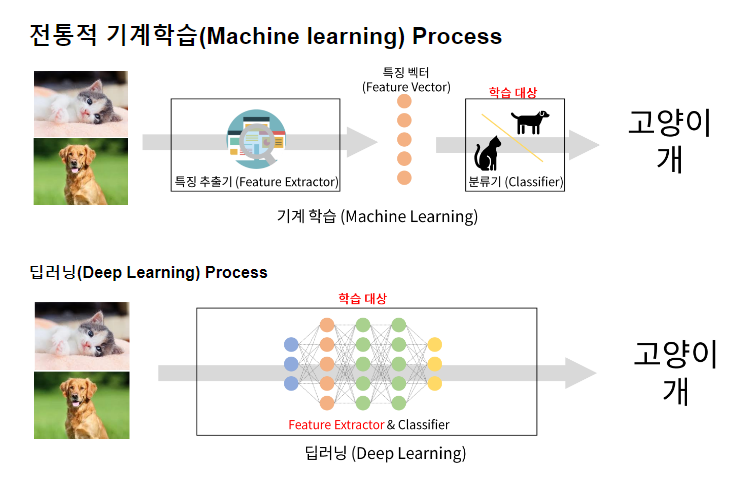
비정형 데이터를 학습시키기 전에 특징 추출기를 만들어 데이터의 각 특징을 추출하고, 추출한 특징을 특징 벡터로 만들어 학습을 진행한다. 특징 분류는 눈으로 보기에는 쉬워보이지만, 실제로 이를 찾아내기는 어렵다. 이 과정에서 특징 추출과 학습을 묶어 주는 것이 딥러닝이다. 딥러닝은 이러한 작업을 처리하는데 속도가 느릴 수 있다.
but
딥러닝의 속도는 일반적으로 학습시간이 오래 걸릴 수 있지만, 최근 다양한 최적화 기법 및 효율적인 라이브러리들이 개발되어 속도 문제가 점차 개선되고 있다.
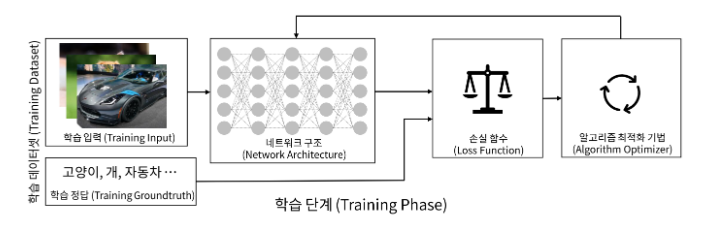
- 딥러닝 과정(Process)
- 학습단계
- 추론단계
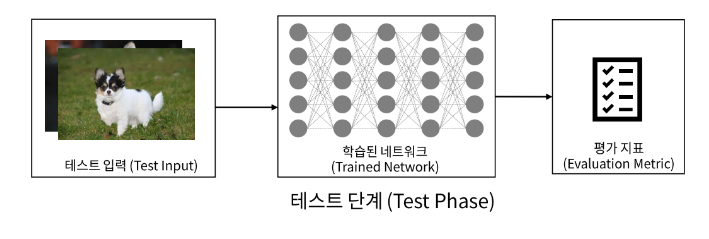
- 학습단계
- 사용 라이브러리
- 머신러닝에서는 scikit-learn 라이브러리를 사용하며,
딥러닝에서는 Tensorflow, Pytorch 등을 사용 - Tensorflow의 함수들을 모아서 Keras를 만들었으며, Keras는 고수준의 딥러닝 API로써, Tensorflow와 함께 사용되어 더 쉽게 딥러닝 모델을 구축할 수 있는 인터페이스를 제공한다.
=> Keras는 Tensorflow의 기능을 활용하는 것이다. - Tensorflow 2.0부터 Keras가 Tensorflow에 포함되어 있기 때문에, Tensorflow만 설치하면 사용할 수 있습니다.
- 머신러닝에서는 scikit-learn 라이브러리를 사용하며,
첫 번째 딥러닝 - MLP(Multi-Layer Perceptron) 구현
- MLP(Multi-Layer Perceptron)
- MLP는 다층 퍼셉트론의 약자로, 인공신경망의 한 종류입니다. MLP 구현은 여러 층으로 구성된 인공신경망을 만들고 학습하는 과정을 포함한다.
- 주요 과정은 데이터 준비, 모델 정의, 학습 및 평가, 테스트로 나눌 수 있다.
- Keras 개발 프로세스와 함께하는 MLP 구현
- 데이터 준비: 딥러닝 모델에 사용할 입력 데이터(X)와 목표 출력 데이터(y)를 준비
- 입력과 출력을 연결하는 Layer(층)으로 이뤄진 MLP 모델 정의: 여러 층을 사용하여 신경망 구조를 정의합니다. 이 때 입력층, 은닉층 그리고 출력층을 포함해야 한다.
- 모델 정의하는 방식
- Sequential 방식: 순서대로 쌓아올린 네트워크로 이뤄진 모델을 생성하는 방식
- Functional API 방식: 다양한 구조의 네트워크로 이뤄진 모델을 생성하는 방식
- Subclass 방식: 네트워크를 정의하는 클래스를 구현
- 모델 컴파일: 모델을 학습 실행 가능한 상태로 만든다.
=> 이때 사용할 손실 함수(Loss Function), 최적화 기법(Optimizer), 모니터링할 평가 지표(Metrics)를 설정 - 모델 훈련: 훈련 데이터셋을 이용해 모델을 학습시킨다.
- 테스트: 학습된 모델을 테스트 데이터셋에 대해 평가하고, 이를 통해 모델의 성능과 일반화 능력을 확인
<정리>
첫 번째 딥러닝 - MLP 구현을 위해 준비한 데이터를 사용하고 Keras를 사용하여 모델을 정의하고 컴파일 한 다음, 훈련 시키고 평가하는 작업을 수행한다. 이 과정에서 Sequential 방식, Functional API 방식, Subclass 방식 등 다양한 방식을 활용하여 모델을 구축할 수 있다. 마지막으로 손실 함수, 최적화 기법, 평가 지표 등을 설정하여 모델을 컴파일하고 학습시킨다. 이렇게 생성된 모델은 테스트 데이터셋을 사용하여 일반화 능력을 평가할 수 있다.
<예제를 살펴보자>
MNIST 이미지 분류 데이터셋
- MNIST(Modified National Institute of Standards and Technology) 데이터베이스는 흑백 손글씨 숫자 이미지 데이터셋으로, 기계 학습 및 딥러닝의 기초 테스트에 널리 사용되고 있다.
- 숫자 범주: 0부터 9까지 총 10개의 범주로 구성
- 이미지 크기: 28 x 28 픽셀
- 데이터 구성: 60,000개의 훈련 이미지와 10,000개의 테스트 이미지
MNIST 이미지 분류를 위한 딥러닝 모델 구현 절차
- MNIST 이미지 분류를 위해서는 다음과 같은 과정을 거쳐서 딥러닝 모델을 구성하고 학습시킬 수 있다.
- 데이터 준비: MNIST 데이터를 불러온다. -> 데이터는 각 픽셀 값을 0에서 1 사이로 정규화해야 한다. -> 또한, 레이블(타겟 값)은 분류에 속하므로 원-핫 인코딩으로 변환한다.
import numpy as np
import tensorflow as tf
from tensorflow import keras
# 데이터 로드 및 정규화
(train_images, train_labels), (test_images, test_labels) = keras.datasets.mnist.load_data()
X_train = train_images.astype('float32') / 255
X_test = test_images.astype('float32') / 255
# 원-핫 인코딩
y_train = keras.utils.to_categorical(train_labels)
y_test = keras.utils.to_categorical(test_labels)2.모델 구성: 적절한 모델(예: MLP, CNN)를 선택하고, 주요 하이퍼파라미터를 설정하여 모델을 구성한다. 입력층, 은닉층 그리고 출력층을 포함한 딥러닝 모델을 구축하는 것이다.
model = keras.Sequential([
keras.layers.InputLayer((28, 28)),
keras.layers.Flatten(),
keras.layers.Dense(256, activation='relu'),
keras.layers.Dropout(0.3),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.3),
keras.layers.Dense(10, activation='softmax')
])- 모델 컴파일: 손실 함수, 최적화 기법, 평가 지표를 선택하고 모델을 컴파일한다.
=> 예를 들어, 손실 함수로는 'categorical_crossentropy', 최적화 기법으로는 'adam'을 사용할 수 있으며, 평가 지표로는 'accuracy'를 사용한다.
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])- 모델 학습: 훈련 데이터셋에 대하여 모델을 학습시키고, 검증 데이터셋을 사용하여 중간 성능을 확인
history = model.fit(X_train, y_train, epochs=10, batch_size=100,
validation_split=0.3)
- 모델 평가 및 테스트: 학습된 모델의 성능과 일반화 능력을 테스트 데이터셋에 대해 평가
test_loss, test_accuracy = model.evaluate(X_test, y_test)마지막
- 새로운 데이터 추론
- 새로운 데이터를 추론하기 전에 학습 데이터에 했던 전처리 과정을 동일하게 적용한 뒤 추론할 수 있다.
- 분류문제일때 predict() 결과에서 class label 출력하기
import numpy as np
# 새로운 샘플데이터
sample_data = X_test[:5]
# 이진 분류(binary classification)
binary_prediction = np.where(model.predict(sample_data) > 0.5, 1, 0).astype("int32")
# 다중클래스 분류(multi-class classification)
multi_class_prediction = np.argmax(model.predict(sample_data), axis=1)
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
# TensorFlow 버전 확인
print(tf.__version__)2.13.0
# 시드 값 설정
np.random.seed(0)
tf.random.set_seed(0)
random.seed(0)
# 데이터셋 로드 및 분할
(train_image, train_label), (test_image, test_label) = keras.datasets.mnist.load_data()
# 훈련 및 테스트 데이터셋 형태
train_image.shape, train_label.shape, test_image.shape, test_label.shape((60000, 28, 28), (60000,), (10000, 28, 28), (10000,))
# 데이터셋 정규화 및 전처리
X_train = train_image.astype("float32")/255
X_test = test_image.astype('float32')/255
# 레이블 원-핫 인코딩
y_train = keras.utils.to_categorical(train_label, num_classes=10)
y_test = keras.utils.to_categorical(test_label)
# Sequential 모델 정의
model = keras.Sequential([
keras.layers.InputLayer((28,28)),
keras.layers.Flatten(),
keras.layers.Dense(256),
keras.layers.ReLU(),
keras.layers.Dense(units=128),
keras.layers.ReLU(),
keras.layers.Dense(10),
keras.layers.Softmax()
])
# 모델 컴파일
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 모델 훈련
history = model.fit(X_train, y_train,
epochs=10,
batch_size=100,
validation_split=0.3)
# 테스트 데이터셋을 사용하여 모델 평가
result = model.evaluate(X_test, y_test)
# 새 데이터에 대한 예측 수행
X_new = X_test[:3]
pred = model.predict(X_new)