
이제부터는 모델링을 수행할 것이다.
d. 콘텐츠 기반 필터링
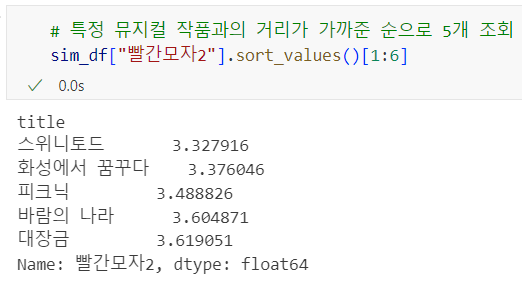
- 줄거리를 기반으로 유사도가 높은 순으로 (유클리드 거리가 가까운 순서) 작품 추천
[참고] musical_data_vector2.csv 데이터 사용
- 모든 행의 doc2vec_vec 컬럼(줄거리를 벡터로 전환한 값을 다시 문자열로 저장한 컬럼)을 numpy 배열로 변환해서 doc2vec_numpy 컬럼에 대입
#모든행의 doc2vec_vec 컬럼을 출력
musical_data.loc[: ,"doc2vec_vec"]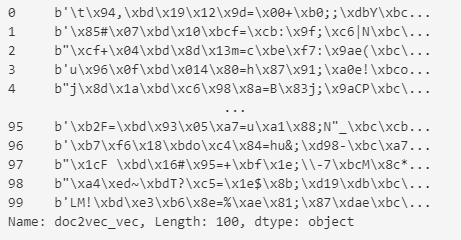
##모든행의 doc2vec_vec 컬럼을 numpy 배열로 변환
musical_data.loc[: ,"doc2vec_vec"].apply(lambda x: np.fromstring(x,dtype="float32") )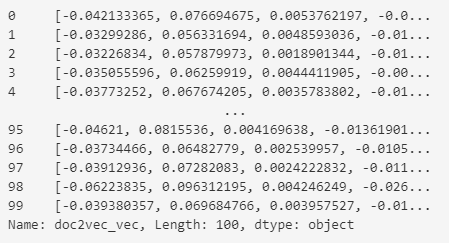
##모든행의 doc2vec_vec 컬럼을 numpy 배열로 변환해서 doc2vec_numpy 컬럼에 대입
musical_data.loc[: ,"doc2vec_numpy"] = musical_data.loc[: ,"doc2vec_vec"].apply(lambda x: np.fromstring(x,dtype="float32") )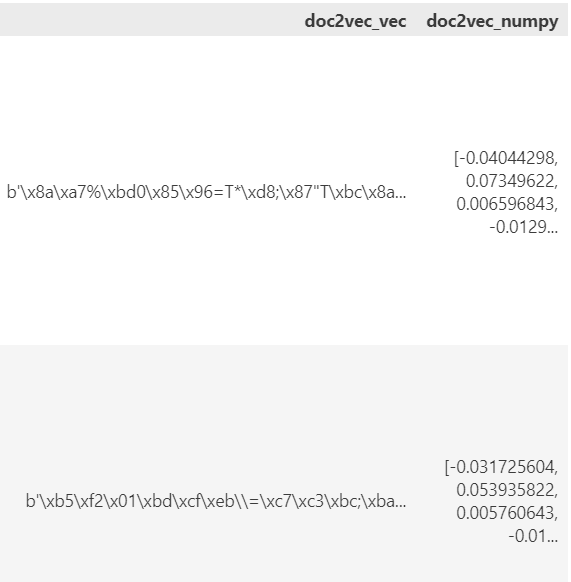
2. StandardScaler객체 적용 및 리스트변환 후 doc2vec_numpy_scale 컬럼에 대입
from sklearn.preprocessing import StandardScaler
#데이터의 각 열의 평균을 뺀 다음 표준편차로 나눠서 평균을 0로 표준편차를 1로 변환하는 StandardScaler 객체 생성
scaler = StandardScaler()
# doc2vec_numpy 배열의 값을 리스트로 변환 한 값을 numpy 배열로 변환하는 각 열의 평균 표준편차 계산
scaler.fit(np.array(musical_data["doc2vec_numpy"].tolist() ))
#각 열의 평균
scaler.mean_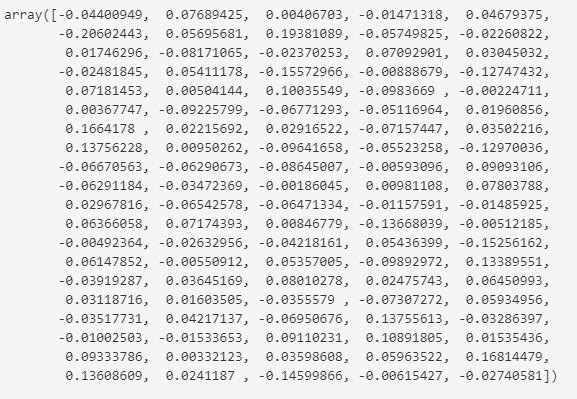
#각 열의 분산
scaler.var_
#데이터의 각 열의 평균을 뺀 다음 표준편차로 나눠서 평균을 0로 표준편차를 1로 변환 한 후 리스트로 변환해서 doc2vec_numpy_scale 컬럼에 대입
musical_data["doc2vec_numpy_scale"] = scaler.transform(np.array(musical_data["doc2vec_numpy"].tolist() )).tolist()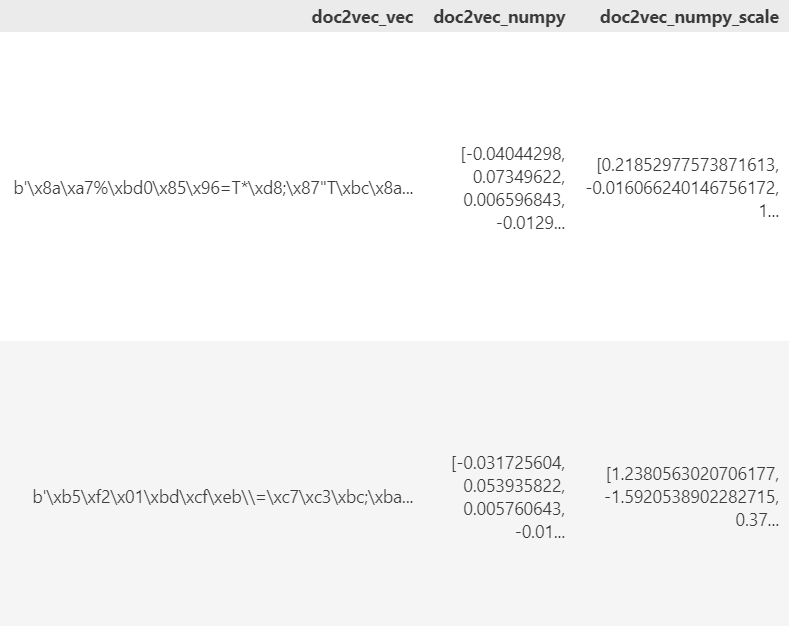
3. doc2vec_numpy_scale 컬럼의 유클리드 거리를 계산 → sim_df
from sklearn.metrics.pairwise import euclidean_distances
# doc2vec_numpy_scale 컬럼의 유클리드 거리를 계산
sim_score = euclidean_distances(musical_data["doc2vec_numpy_scale"].tolist(),musical_data["doc2vec_numpy_scale"].tolist())
# sim_score (synopsys_vector_numpy_scale 컬럼의 유클리드 거리) DataFrame 으로 변환
sim_df = pd.DataFrame(data=sim_score)
#sin_df의 인덱스에 영화 제목 대입
sim_df.index = musical_data["title"]
sim_df.columns = musical_data["title"]
sim_df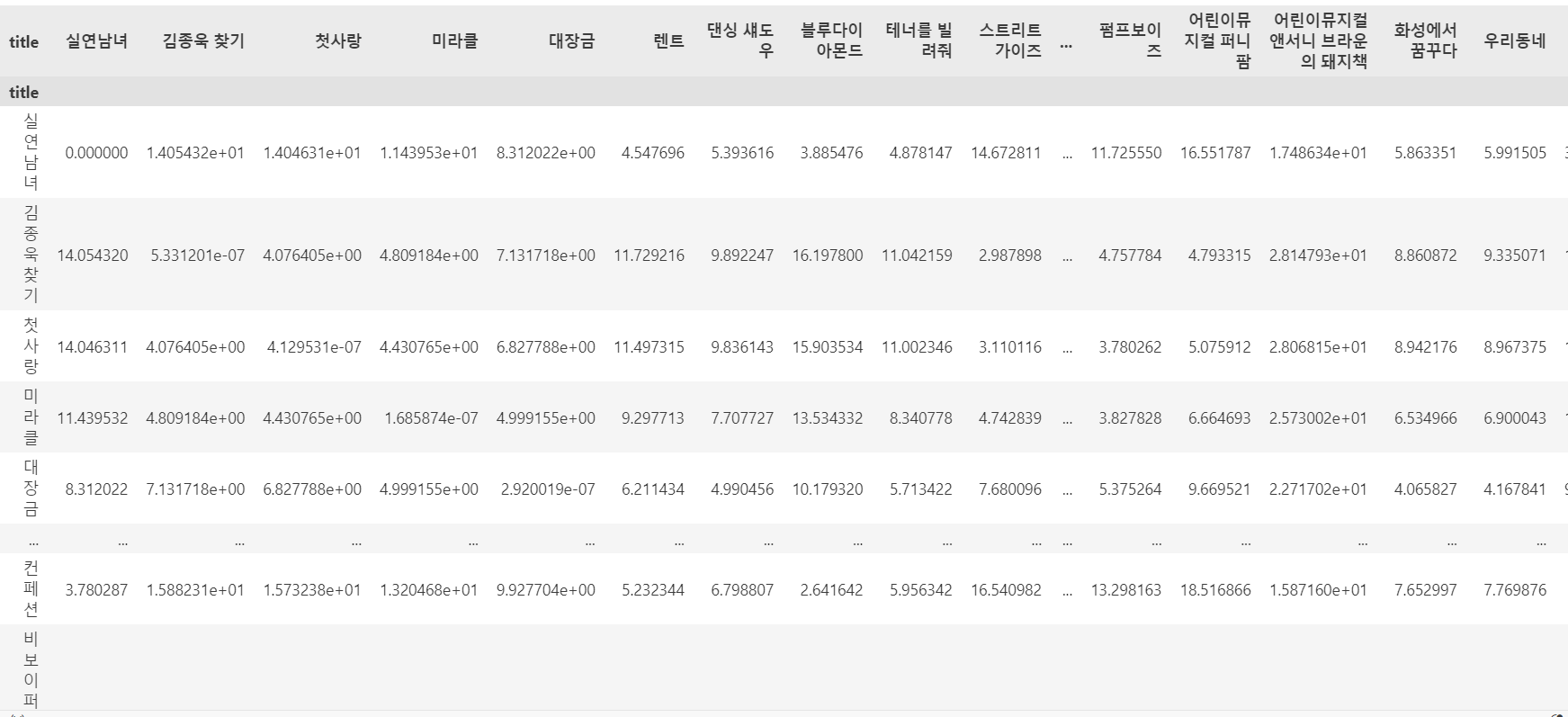
결과
해당코드는 branch 0.0.3/work2vec_test → Model_test/Content_mock.ipynb 있습니다.
branch: 0.0.3/work2vec에 내용에 해당하는 코드파일이 포함되어있으니 참고바랍니다.
tmi: branch명을 word2vec로 한다는걸 너무 자연스럼게 work2vec로 하고 너무 많은일들을 해서 그냥..흐린눈하기로 했다..^^ 다음부터는 정신차리고 제대로 생성하기!!
프로젝트 관련 코드는 아래의 주소에서 확인할 수 있습니다
i-Five

Hi